

Prospective customers frequently ask how Snowflake compares to other technologies. In previous blogs, we compared Snowflake to both on-premises distributed processing data warehousing approaches and cloud-migrated versions of the same technologies, both of which require a great deal of hands-on management.
In this blog, we compare Snowflake, at a platform-architecture level, to serverless query services or query engines. Similar to Snowflake, serverless query engines require no infrastructure management to run queries.
Architecture
For serverless query engines, the cloud provider deploys and manages the entire architecture infrastructure (Figure 1). These are multi-tenant platforms, so users load data, launch queries, and share a slice of massive infrastructure with other users. The infrastructure may contain hundreds of thousands of disks and thousands of CPUs and CPU cores.
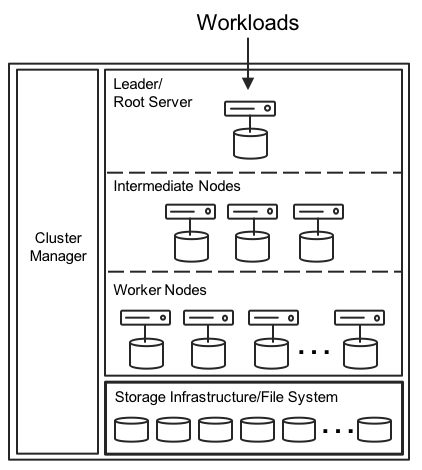
Transparent to the user, an infrastructure-wide cluster manager balances the workload. A root server rewrites queries and passes them to a tree structure of intermediate servers and worker nodes. To boost performance, new varieties of query engines may include dynamic query optimizations, with data shards and in-memory shuffling of shards across stages. MPP query engines excel with extremely large table and log file scans.
Nevertheless, fast performance for large scans is not enough for users and environments requiring a robust cloud data warehouse. It’s important to consider overall data warehouse functionality, workload isolation capabilities, complex schema support, and resource and pricing controls to enable data warehouse managers to meet SLAs with confidence.
Whether the need is to support a few users or thousands of users, Snowflake’s cloud-built data warehouse architecture (Figure 2) eliminates the manual work required by other cloud and on-premises solutions.
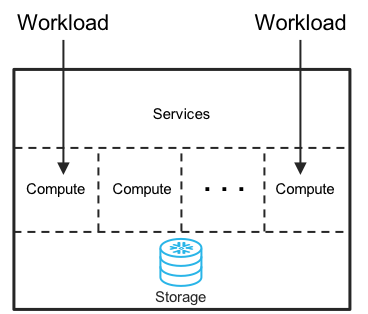
Snowflake executes queries within individual virtual warehouses, which can be thought of as compute engines. Compute engines are sized from XSmall to 4XLarge. Data warehouse managers can instantly create as many compute engines of any size as desired. Compute engines are completely isolated from one another. Thus, there’s never a fight for resources or impact from the activities of another user. With isolated workloads, data scientists may run monster jobs concurrently, and in parallel with business analysts or executive dashboards—and with no queuing or workload bumping.
This level of workload isolation and resource control separates the capabilities of Snowflake from serverless query engines. By sizing Snowflake compute engines to the specific needs of the business, data warehouse managers avoid price premiums for noncritical workloads while maintaining the flexibility to add more resources during peak demand. All of this occurs within the boundaries of a single Snowflake instance.
Data Warehouse
When evaluating the differences between Snowflake and query engines, consider the origins of the platforms. This provides an indication of how your data warehouse requirements are met today and how the platforms will evolve into the future.
Snowflake’s origins as a data warehouse specifically engineered and built for the cloud means that features such as 90-day data retention, Zero-Copy Cloning, recovery of deleted tables or databases (DROP and UNDROP), ACID compliance, multi-statement transaction support, and support for complex DML are all built in.
Since Snowflake’s first release, for example, Snowflake users employ Zero-Copy Cloning to enable test and development organizations to operate on production data, without risk to the data. With a simple UNDROP command, users instantly recover databases and tables mistakenly deleted. Data engineers rely on multi-statement transactions to execute complex inserts with high integrity. Without cumbersome data prepping, data scientists and business analysts can easily ingest JSON data and join with corporate data, enabling deeper insights to their businesses and 360-degree views of customers.
Pricing
The pricing for query engine services typically is around $5 per TB of data scanned for compute resources and from $20 to $25 per TB, per month uncompressed, for storage resources.
Snowflake charges by the second for compute resources, with one minute of compute as the minimum time granularity and $.00056 per second thereafter as the beginning price point with a Snowflake Standard Edition sized to an XSmall. Storage costs for Snowflake run $23 per TB per month (compressed) with an annual commitment and $40 per TB per month (compressed) on a month-to-month basis.
To complete a query, Snowflake and most query engines scan data by columns from a table, which is more performant for analytic workloads compared to scanning by rows as is typical for transactional databases.
In addition, by utilizing data pruning, Snowflake scans only the data needed from any column to complete a query. Data pruning, along with storage compression, speeds up queries and drives down the cost of ownership compared to any platform alternative that does not employ data pruning and compression. Conservatively estimating a compression ratio of 4:1 for Snowflake, a 5-TB uncompressed database will cost as little as $28.75 per month with Snowflake compared to $100 per month with a query engine that operates with uncompressed storage.
Performance
Many variables go into evaluating performance. No two environments are alike and it’s best for users to measure performance with their own queries against their own data. Users can take advantage of Snowflake’s free trial or engage in a complete proof of concept.
Determining your needs
Although great performance is important, it is rarely the only requirement among our 1,400+ customers. You should measure the end-to-end management effort across all activities required to support your environment. To ascertain your specific needs, ask these important questions. Do you:
- Support a small or large groups of users?
- Anticipate growth in business or data operations?
- Manage and execute SLAs?
- Have limited staff to operate and manage a data warehouse?
- Require test and development support against production data?
- Have complex queries?
- Require a mechanism to isolate workloads and allocate by department?
If you answered yes to any of these questions, your data warehouse requirements are more than just performance. Therefore, in addition to achieving fast performance for your queries, make sure you plan for a data warehouse that provides the flexibility to control the resources and scalability necessary to match the needs of your environment.
Summary
Snowflake gives you the power and control to size your implementation for small and large organizations and easily control how much you pay. You also have the flexibility to employ Snowflake as a high performance compute engine just to run queries and pay by the second only for what you use. Or, you can deploy Snowflake as a robust data warehouse to handle organization-wide data analytics needs and workload separation at extremely large scale.