1.7B > 235B: Training a David to Outperform a Goliath with Reinforcement Learning


The bigger-is-better assumption is wrong for enterprise AI
The language model scaling race has trained us to think in one direction: more parameters, more data, more compute. Frontier models now routinely exceed 100 billion parameters, and the default enterprise playbook is to call the biggest available API and hope for the best. For many general-purpose tasks, this works.
But for the narrow, structured, high-stakes tasks that define real enterprise workflows, scale alone is a blunt instrument. Consider clinical documentation: Every day, physicians spend hours converting patient conversations into structured SOAP (Subjective, Objective, Assessment and Plan) notes. These notes must follow strict formatting rules, contain no hallucinated facts and categorize clinical data with precision. A general-purpose 235B-parameter model can attempt this task, but it was never specifically trained for it. It treats structured clinical output the same way it treats writing poetry or summarizing news, as just another prompt to complete.
The result is predictable: expensive inference costs, high latency and output that is good but not reliable enough for production healthcare systems. What if we could train a model to do this single job better, and it also happens to be 140x smaller? Let me explain how Snowflake ML makes that possible.
Teaching a small model to think like a clinician
We set out to prove that targeted reinforcement learning from AI feedback (RLAIF) could enable a 1.7B-parameter model to outperform a 235B-parameter model on structured SOAP note generation, using Snowflake ML Jobs as our training infrastructure.
The conventional approach would be supervised fine-tuning (SFT): Train the small model to imitate the outputs of the model that generated the synthetic data, token by token. But SFT has two fundamental limits. First, it treats every token equally; a wrong diagnosis and a rephrased sentence incur the same loss. Second, the student can never surpass the teacher; SFT's ceiling is the quality of the synthetic data it was trained on.
Reinforcement learning removes both limits. Instead of imitating a reference, the model generates candidates and receives a reward signal that directly encodes what matters: format validity, factual grounding and clinical completeness. And because RL optimizes against a reward function rather than copying a teacher, there is no ceiling: The student can discover strategies the teacher never used.
The approach has two phases. First, we created a fully synthetic data set consisting of 19,939 doctor-patient dialogues spanning 30 medical specialties and 400+ conditions. We chose Qwen3-235B-A22B as the generator because data synthesis is the one stage where raw scale pays off: We need the broadest possible medical knowledge to produce diverse, clinically realistic scenarios across hundreds of conditions. This created a diverse, high-quality synthetic data set with zero semantic duplicates.
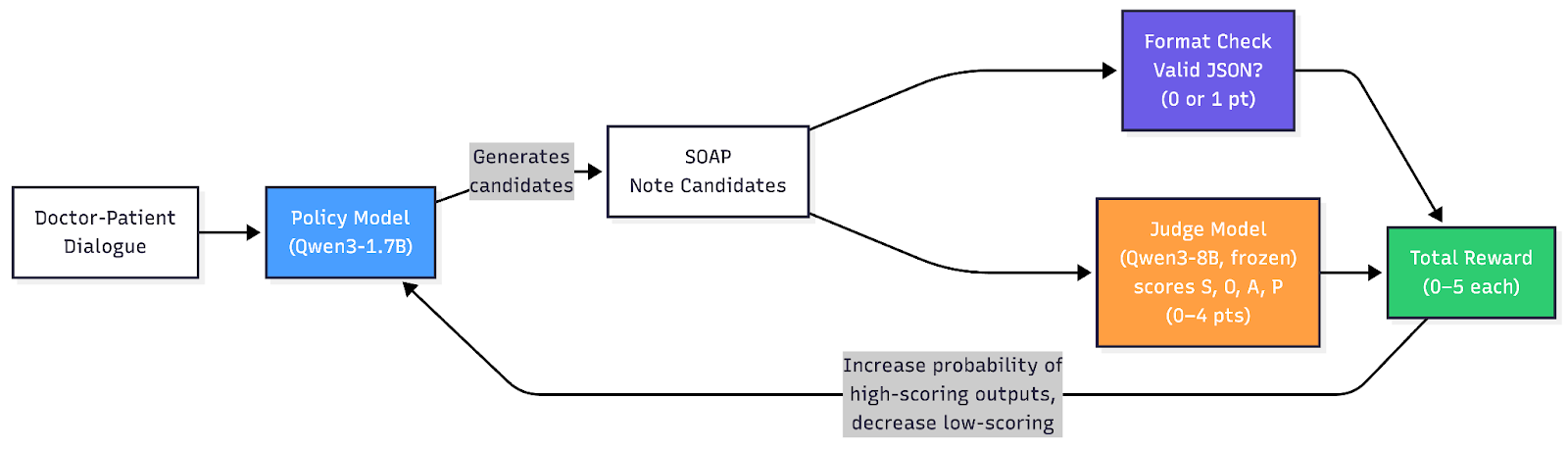
Second, instead of traditional supervised fine-tuning, we used group relative policy optimization (GRPO), a reinforcement learning algorithm that learns by comparing multiple candidate outputs against each other. For each dialogue, our 1.7B policy model generates four candidate SOAP notes. Each candidate is scored on a 0-to-5 scale using two independent checks:
- 1 point from a deterministic code check: Is the output valid JSON with exactly the four required keys (S, O, A, P)? If not, the score is 0, and no further evaluation occurs.
- 4 points from a frozen 8B-parameter judge model that evaluates each section independently for factual accuracy, completeness and clinical appropriateness.
The judge evaluates all four sections in parallel, and GRPO uses the relative ranking within each group to push the policy toward better outputs — no absolute reward baseline needed. Note that the 8B judge never generates SOAP notes; it only verifies them against the source dialogue on narrow, well-defined criteria, a task far easier than generation itself.
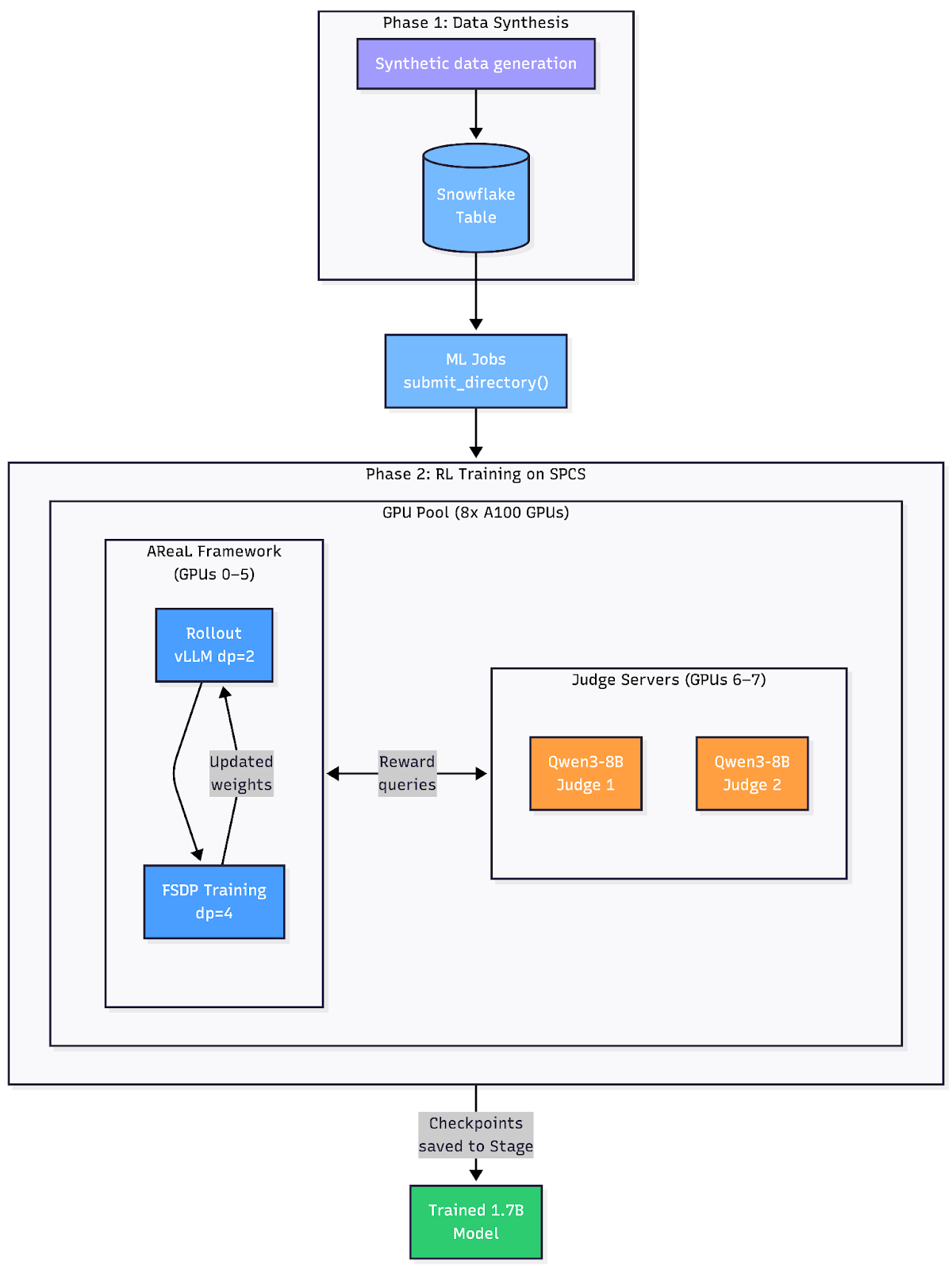
The entire pipeline runs on Snowflake's Snowpark Container Services (SPCS) with dedicated GPU pools: Rollout workers generate candidate notes; the judge server scores them; and fully sharded data parallel (FSDP) training workers update the model — all orchestrated by Ray within a single ML Job submission.
Results
We evaluated all three models: base 1.7B, base 235B and RL-trained 1.7B against a holdout set of 4,028 samples.
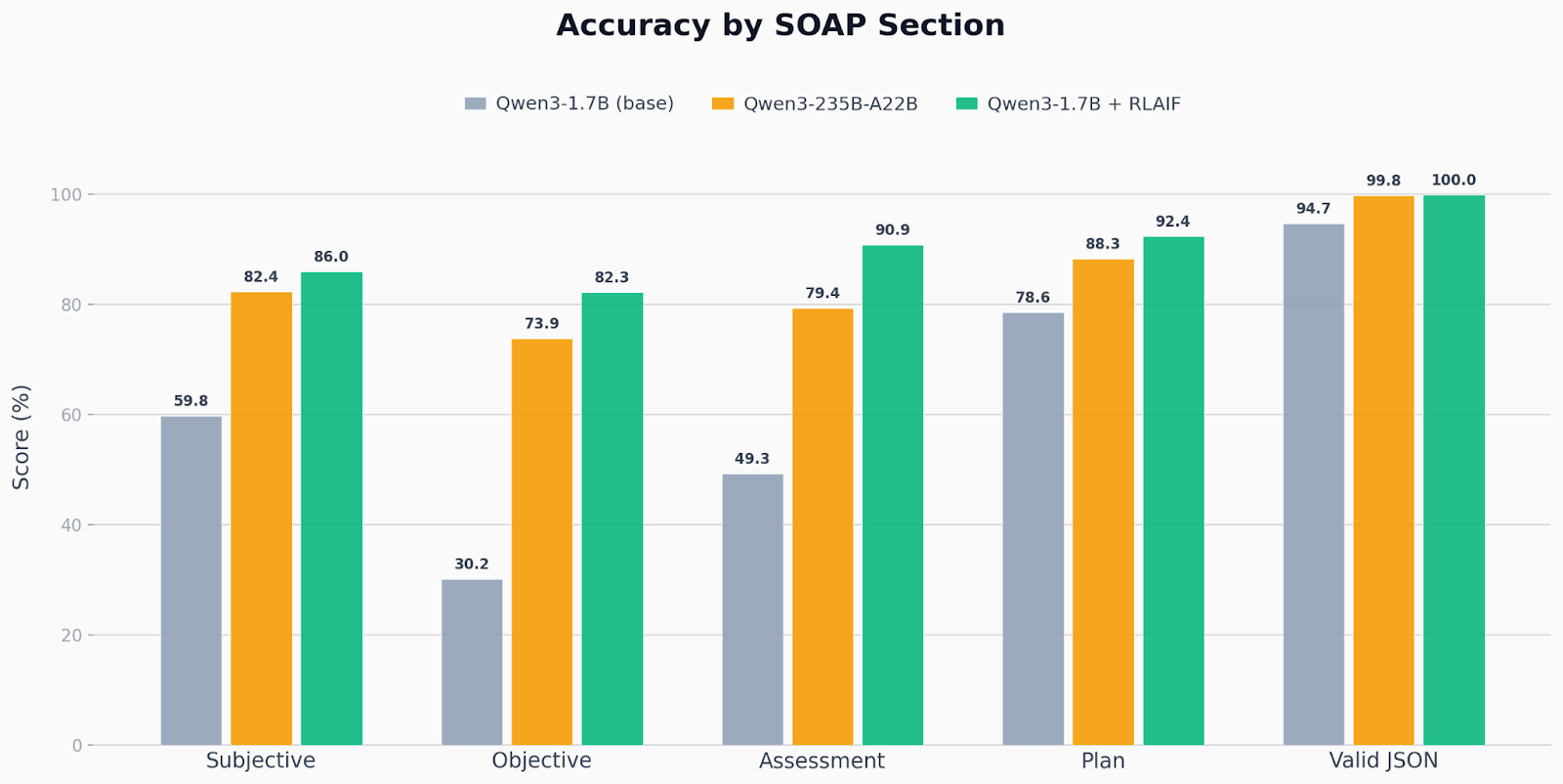
Across every section, the RL-trained 1.7B model matched or exceeded the 235B model, despite being 140x smaller. The improvements were most pronounced in the sections that require the most clinical reasoning (Assessment, Objective), suggesting that RL is especially effective when the task demands structured judgment rather than surface-level fluency. JSON format compliance reached 99.98%, confirming that hard-coded reward components translate directly into reliable model behavior.
A note on evaluation: An LLM judge produces the section-level scores, and any LLM-based evaluation is inherently subjective and model-dependent; a different judge could yield different absolute numbers. We do not claim these scores represent ground-truth clinical quality. What we do claim is more general: Reinforcement learning lets you define a quality signal that captures what you care about, then systematically optimizes a small model against it. The specific judge is a pluggable component. If your organization has stricter criteria, a domain-specific rubric or human reviewers in the loop, GRPO will optimize for those just the same. The takeaway is the method, not the absolute scores.
Small, specialized models are the future of enterprise AI
This result is not an anomaly; it reflects a broader shift. For well-defined enterprise tasks with clear success criteria, targeted reinforcement learning consistently outperforms raw scale. The key insight is that RL directly optimizes for the exact metrics that matter — format compliance, factual accuracy and clinical completeness — while a 235B model, no matter how capable, is merely doing zero-shot inference with no task-specific optimization. Scale gives you general competence; RL gives you specialized mastery.
The practical implications are significant: A 1.7B model can run on a single GPU with subsecond latency, at a fraction of the cost of a 235B API call. For healthcare organizations processing thousands of patient encounters daily, this is the difference between a research demo and a production system.
Snowflake's ML Jobs on SPCS made this workflow straightforward. From data synthesis to distributed RL training to model evaluation, everything ran within Snowflake's secure compute environment with no data leaving the platform. As enterprise AI matures, we believe this pattern — synthesize data, train small with RL and deploy cheaply — will become the default for any organization with domain-specific accuracy requirements.
The code and training recipes for this use case are available in the Snowflake sf-samples repository. We encourage you to try adapting this approach to your own structured output tasks in Snowflake ML.
Scaling Agent Reliability: Trace-Aware Evaluation for MLflow

Time-Series Forecasting: Comparing Transform Techniques for Tree-Based Models

Optimize Your Data Pipelines by Augmenting Network Concurrency with Snowpark External Access
