Strengthening Snowflake’s Distributed Query Lifecycle with Execution Anchors


Snowflake's architecture separates storage, compute and cloud services. The cloud services layer, also called Global Services (GS), coordinates query execution across a fleet of instances.
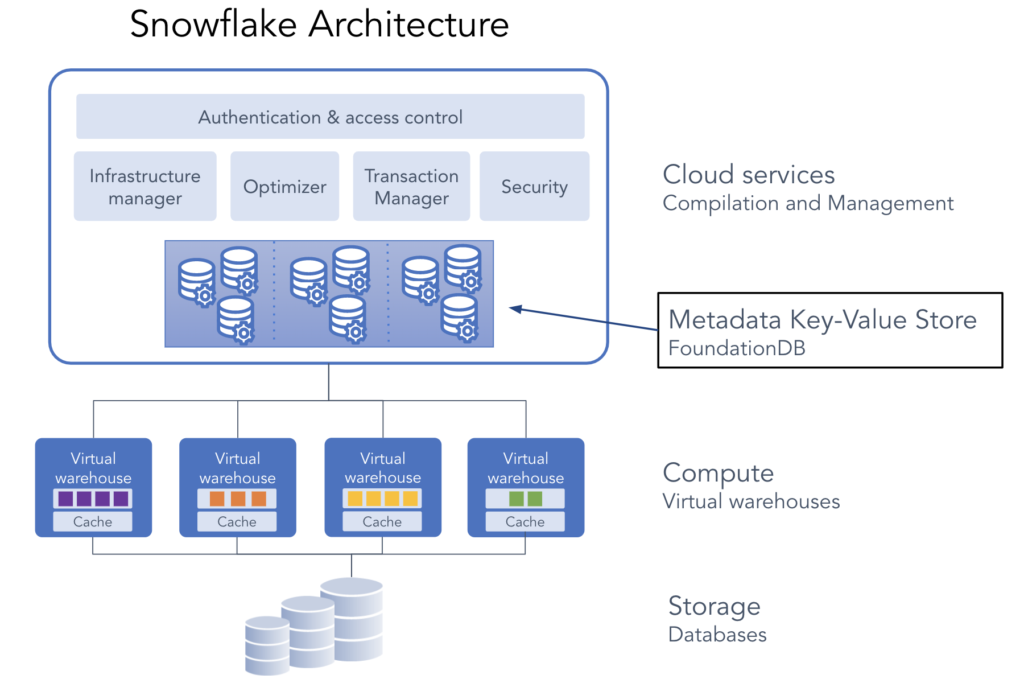
At Snowflake's scale, serving billions of queries per day across three major cloud providers and dozens of regions, this coordination must be precise. FoundationDB (FDB) is the distributed key-value store that serves as Snowflake's metadata backbone; it durably records the state of every query, table, partition and transaction in the system. For any given query, exactly one GS instance should be committing metadata transactions to FDB at any point in time. This preserves the transactional semantics of each query even as queries are retried across instances or recovered after failures.
Snowflake has long enforced this principle through distributed tracking, heartbeat-based health monitoring and instance lifecycle management. These mechanisms have served the platform reliably. As the platform grew (with automated query retries, crash recovery and asynchronous finalization adding more participants to a query's lifecycle), we saw an opportunity to take these guarantees further: from implicit, convention-based coordination to explicit, transaction-level enforcement. The goal was to harden the system's foundations in proportion to its growing complexity.
In this post, we describe how we designed and deployed the execution anchor, a mechanism that binds each query to exactly one GS instance throughout its lifecycle, and how we rolled it out across all production deployments without a single incident.
The problem
To understand why this matters, it helps to be precise about what we were hardening against.
All persistent state changes for a query (metadata writes, result registration, finalization records) flow through FDB transactions. The core invariant is: At most one GS instance should ever be committing FDB transactions for a given query at a time. Violating this could cause query finalization to be attempted concurrently by two instances, which risks inconsistent metadata, duplicate writes or conflicting state: subtle correctness problems that are difficult to detect and harder to recover from.
Before this work, the platform enforced this through careful convention: coordination protocols, timeouts and lifecycle tracking across every code path that touched query execution. This worked reliably. But as the query lifecycle grew more complex (with retries triggered automatically at significant daily volume, recovery logic handling crashed instances and background flushers operating asynchronously), there were more code paths to reason about and more surface area over which enforcement had to hold.
The right engineering response was to make this guarantee structural: enforced at the transaction level and verifiable at any point, rather than dependent on every code path following conventions correctly.
The core idea: An execution anchor
The anchor contract is simple: Query-to-instance assignment is tracked explicitly in FDB as a small record: a single key mapping each query ID to the identity of the GS instance responsible for it. Before every FDB transaction, an in-process guard validates that the current instance holds the anchor for that query. If it does not, the transaction is rejected.
Because all globally visible side effects of a query flow through FDB transactions, controlling who can commit those transactions means controlling who can produce any durable change on behalf of that query. The guard provides this control continuously, not as a point-in-time check, but as an invariant enforced at every commit throughout the query's full lifecycle.
The anchor is essentially a distributed lock customized for Snowflake architecture to reduce the performance overhead while maintaining the correctness. Unlike a leased token, the anchor is not time-bounded: It is held for the exact duration of work and transferred through explicit, verifiable protocol steps rather than via expiry. This makes it a stronger and more deterministic mechanism for the query execution context.
Three scenarios
The anchor operates across three distinct scenarios, each with its own protocol.
1. Normal execution: No transfer needed
More than 99% of queries complete without any retry or crash-recovery path being invoked, so a single GS instance handles execution from start to finish. The instance acquires the anchor atomically as part of initiating the query, piggybacking on the first FDB transaction so no extra round-trip is needed. It holds the anchor through execution, finalization and asynchronous flush (a background phase where additional query metadata is durably persisted to FDB after execution completes), then releases it once all work is done.

The guard in this path is a fast in-memory set lookup: no network round-trip, no additional FDB I/O. A typical query involves only a handful of FDB transactions. The guard adds negligible overhead to each, making the performance cost of maintaining this guarantee effectively zero on the common path.
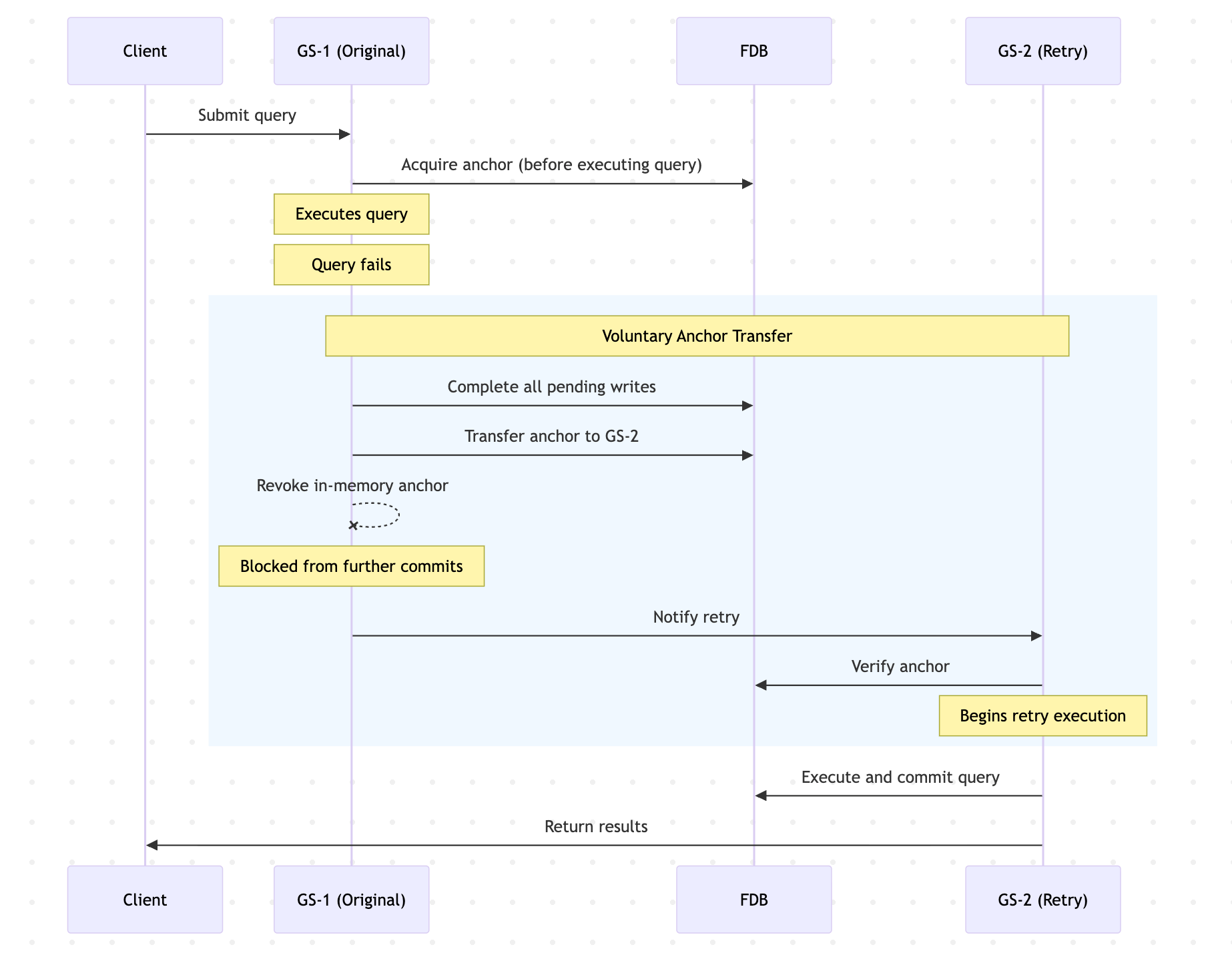
2. Voluntary transfer: Query retry
When a query fails and is retried on a different instance, the anchor must be handed off. The original instance orchestrates this through a strict, ordered sequence:
- Complete pending writes: All FDB writes initiated by the current execution attempt (meaning writes that have been submitted but not yet acknowledged) are given a bounded timeout to either commit or abort. This ensures no in-flight work is left dangling before the handoff proceeds.
- Transfer the anchor: The anchor record in FDB is updated atomically to point to GS-2, and simultaneously revoked from GS-1's in-memory set. From this point forward, any FDB commit attempted by GS-1 for this query is rejected by the guard, including background threads such as async flushers that may arrive after the transfer. These rejections are intentional and safe: By the time they occur, the query is being retried on GS-2, and any late-arriving writes from GS-1 are superseded. Those rejected threads log the rejection and exit cleanly without surfacing an error to the query.
- Handoff: GS-1 notifies GS-2 via the standard retry dispatch mechanism. GS-2 reads the anchor record in FDB, confirms it holds ownership and begins re-executing the query from scratch.
This creates a clean cutoff: There is no window during which two instances could both commit transactions for the same query. Previously, this property was maintained by coding conventions; now it is enforced structurally by the anchor.
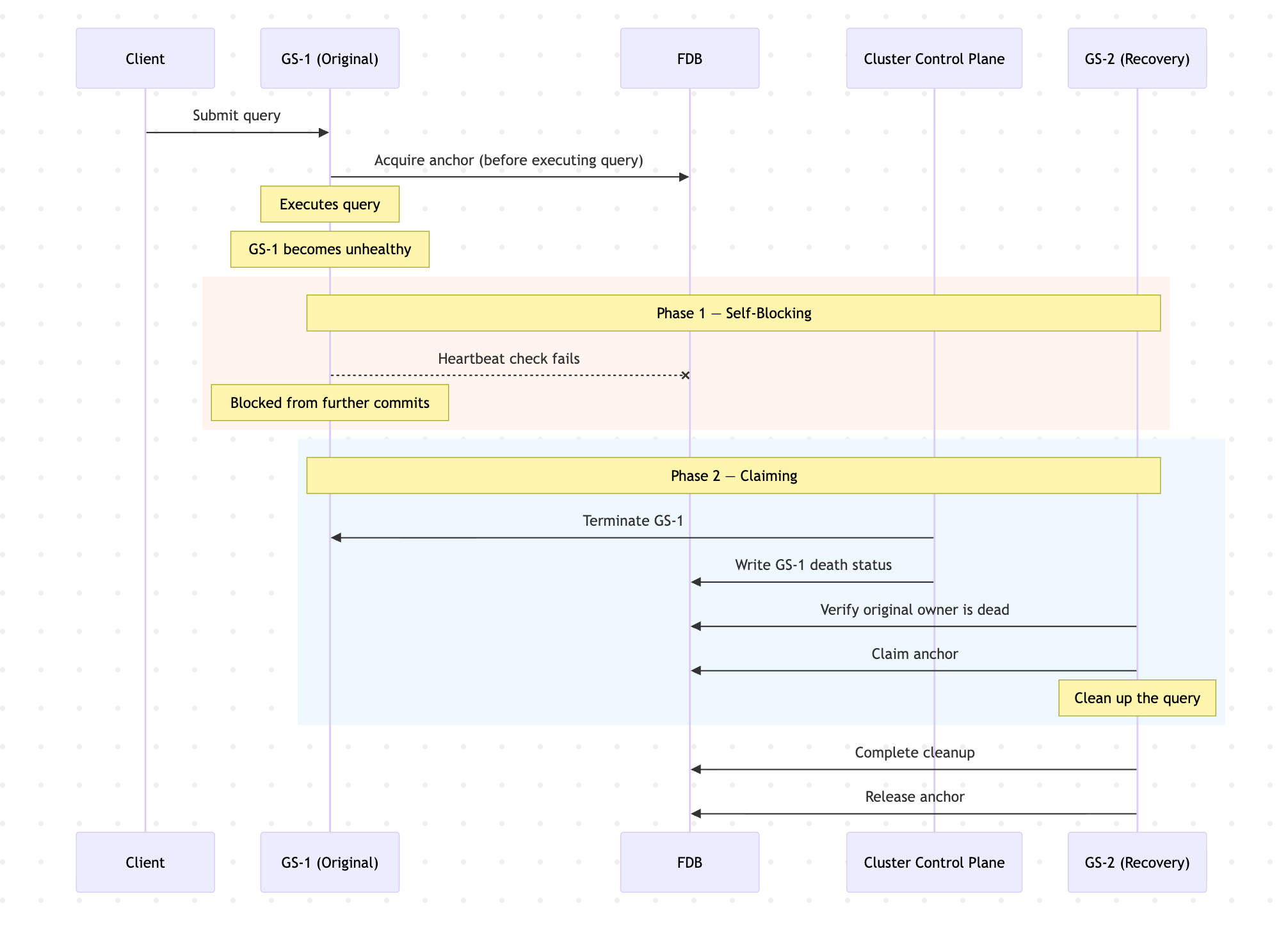
3. Involuntary transfer: Crash recovery
When a GS instance crashes mid-query, no voluntary handoff is possible. The system handles this through a two-phase protocol whose safety is grounded in FDB's transactional semantics rather than in timing assumptions.
Phase 1: Self-blocking. Every FDB transaction submitted by a GS instance includes an embedded heartbeat check: If the instance has begun missing heartbeats, the check fails and the transaction is blocked before it can commit, even before the cluster control plane is aware of the problem. This means the unhealthy instance effectively blocks itself from committing further, independently of any external observer.
Phase 2: Claiming. Only after the cluster control plane has formally declared the original instance dead (meaning it has been fully terminated and its identity will never be reused) can a recovery instance claim the anchor to perform cleanup. "Terminal declaration" here is precise: The cluster control plane writes a durable death-status record to FDB. This record is the proof the recovery instance must verify before claiming. The anchor claim is a conditional write in FDB: It only succeeds if the death-status record exists and the anchor still names the original instance. If either condition is false, the claim fails atomically.
This means the two phases are separated by a strict logical ordering, not a timing assumption: Self-blocking fires as soon as heartbeats are missed, well before terminal declaration. By the time any recovering instance is permitted to claim the anchor, the original instance has been provably unable to commit transactions for some time. Queries that were running on the crashed instance are recovered through Snowflake's automated retry mechanism.
Correctness guarantees
The anchor strengthens three concrete guarantees:
- Clean cutoff during retries: When a query is retried on a new instance, the original instance is provably unable to commit further transactions after the handoff, enforced by the guard, not by convention.
- No concurrent recovery: A recovery instance must explicitly claim the anchor before performing any cleanup, preventing scenarios where recovery and a late-arriving execution thread could produce conflicting state.
- Transaction-level enforcement: Every FDB commit is guarded, providing a continuous and verifiable invariant throughout the query's full lifecycle, not just at entry and exit points.
These guarantees add virtually zero overhead to normal execution: Anchor acquisition and release piggyback on existing FDB transactions, and the in-memory guard is a single set lookup. Additional FDB operations are only required during retries and crash recovery, both rare events relative to total query volume.
Rolling out seamlessly
The entire rollout completed across all production deployments without a single customer-impacting incident. We achieved this through three phases, each backed by dedicated dashboards and zero-tolerance alerting.
In Phase 1 (~3 weeks), we enforced anchoring during crash recovery, monitoring anchor failures and stuck recoveries. In Phase 2 (~3 weeks), we enforced the voluntary transfer protocol during retries, tracking transfer success rates and acquisition latency. In Phase 3 (~6 weeks), we enabled the FDB transaction guard, alerting on any rejected transaction due to a missing anchor.
Each phase followed the same pattern: first a dry-run period where violations were logged and investigated without impacting real queries, then enforcement after all flagged cases were resolved. At multiple points, dry-run observations led us to pause and harden the implementation before resuming.
Rollback posture: The guard, transfer protocol and anchor enforcement are all independently feature-flagged. Any phase could be disabled without a code deployment. This gave us a credible rollback path at each stage.
Operational readiness: Before the rollout began, we defined and instrumented the full set of production signals: anchor acquisition rate, transfer latency, guard rejection rate (expected zero during steady-state), stuck-recovery detection and per-region anchor health dashboards. These dashboards ran continuously through the rollout and remain in production monitoring today.
Conclusion
By making query-to-instance assignment explicit, globally visible and enforced at the transaction level, we strengthened a foundational correctness property of Snowflake's distributed query execution: Every query is managed by exactly one healthy instance at any point in time. The phased dry-run rollout let us validate against real production traffic, surfacing and resolving edge cases before any of them could become incidents.
The execution anchor is now a reliable foundation that the platform builds on.
Looking ahead
With query ownership searchable and verifiable, the anchor opens up several directions: more sophisticated retry strategies that can reason about anchor state, finer-grained recovery that can resume partially completed work and new distributed execution models. It also continues to reduce the cognitive overhead of building on top of query lifecycle management. With anchoring rules explicitly codified, the correctness contract is clear for every team that follows.

Cross-Region AI Inference, Data Residency and Sovereignty: How Snowflake Is Designed to Earn Your Trust

Simpler, Safer URLs: Introducing Per-Account Hostnames for Snowflake App Services

What's New in Apache Polaris™ 1.6
