
NOV 04, 2025|8 min read

This release is co-authored by Debu Sinha. We thank him for his contribution both integrating TruLens scorers into MLflow and co-authoring the blog.
As we move from chatbots to autonomous agents, evaluation has become both more critical and more complex. It’s no longer enough to judge an agent by its final response. An agent might provide the right answer but reach it through "hallucinated" tool calls or redundant, inefficient steps that won't survive a production environment.
To build reliable agents, we need to look inside the black box of the execution trace. This is why we have partnered with the MLflow community to integrate TruLens trace-aware evaluation directly into the MLflow ecosystem.
The core of this integration is the application of the Agent GPA (Goal-Plan-Action) scorers to MLflow. Rather than a single pass/fail grade, Agent GPA evaluates the agent’s entire reasoning loop.

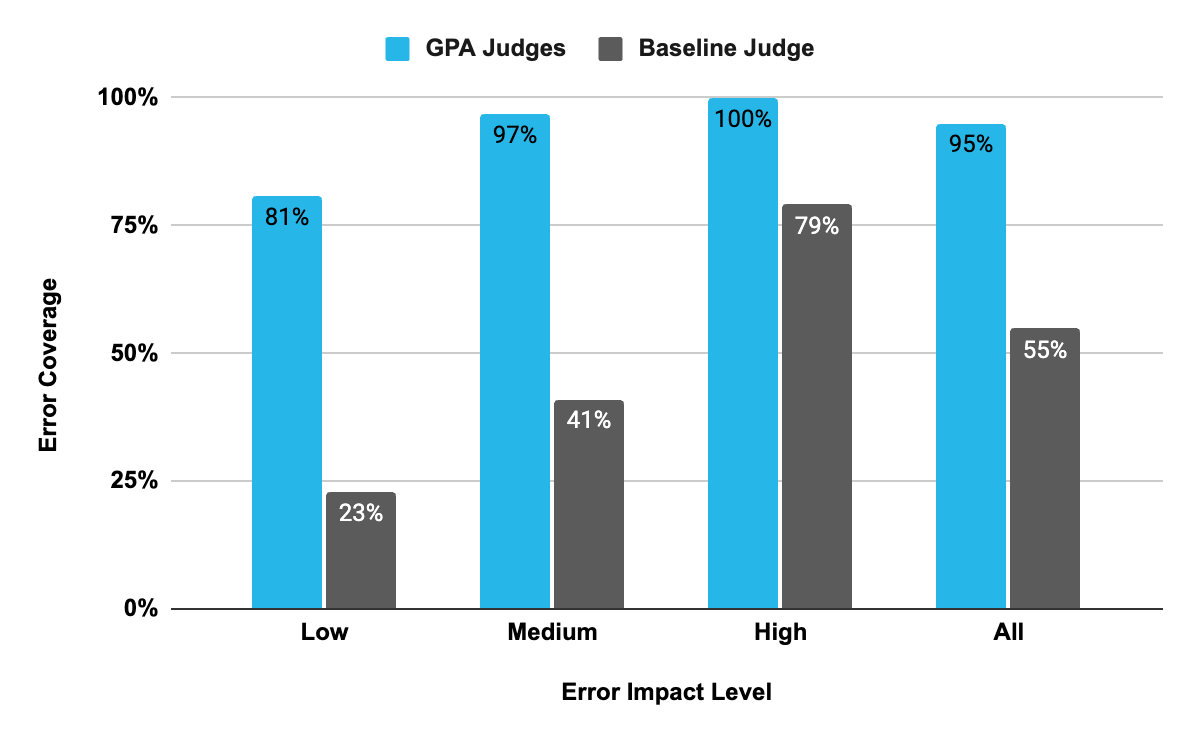
In benchmark testing against the TRAIL/GAIA data sets, the GPA framework showed higher error-detection and localization scores (as measured in the paper) when compared to the baseline judge (Figure 1).
The testing showed:
Near-human error detection: On the TRAIL/GAIA test split, GPA LLM judges identify 95% (267/281) of human-labeled errors, compared with 55% (154/281) for the baseline TRAIL LLM judge.
Targeted debugging: GPA judges achieved 86% localization accuracy, to identify the exact span where an internal agent error occurred, compared to just 49% for baseline judges.
To take advantage of the power of these new LLM judges, they need to be applied to agent traces. The traces will be the input to the LLM judge.
This release adds TruLens-based scorers to MLflow’s GenAI evaluation API so teams can evaluate:
RAG outputs and intermediate steps: Groundedness, Context Relevance, Answer Relevance
Agent traces: Logical Consistency, Execution Efficiency, Plan Adherence, Plan Quality, Tool Selection, Tool Calling
Agent outputs: Coherence
These new scorers can be used for both batch evaluation and trace-aware evaluation through mlflow.genai.evaluate(...).
Under the hood, the integration:
Exposes TruLens scorers through MLflow’s scorer interface
Supports batch evaluation via mlflow.genai.evaluate(...)
Enables trace-aware scoring by consuming MLflow trace artifacts
Includes tests/compatibility constraints to keep existing evaluation workflows stable
Implementation details and review discussion are public in the upstream PR(s), linked in the references.
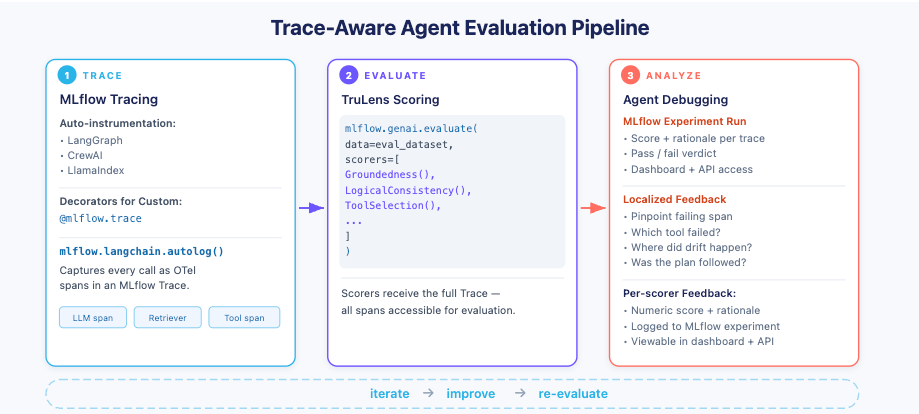
The integration includes a trace-adaptation layer inside MLflow (see Figure 2) that maps MLflow spans into the schema expected by TruLens’ GPA scorers. TruLens scorers can then evaluate quality using either:
Outputs/intermediate results/expectations (classic RAG scoring)
The trace itself (agent GPA scoring)
Figure 2 shows the end-to-end trace-aware evaluation flow: Capture an agent trace in MLflow, run mlflow.genai.evaluate() with TruLens scorers, and get trace-localized feedback for debugging.
The integration makes this possible by:
Adapting MLflow traces into scorer inputs: Maps MLflow trace spans (e.g., tool calls, intermediate messages, retrieved context) to the schema expected by trace-aware scorers.
Wrapping TruLens scorers in MLflow’s scorer interface: Exposes TruLens Scorers through the MLflow interface so they can be used consistently alongside other MLflow scorers and in mlflow.genai.evaluate(...).
Returning structured feedback for debugging: Includes metadata that points to where the trace diverged from the plan (e.g., incorrect tool choice, invalid call or unsupported reasoning step).
With the integration, developers now have a standardized way to access TruLens scorers directly through MLflow using the scorer interface, allowing them to evaluate individual traces or batch evaluate an entire experiment with minimal setup.
Install MLflow with TruLens support, ensuring you are using the latest versions of both:
pip install 'mlflow>=3.10.0' trulens trulens-providers-litellmTruLens scorers can also be used in a variety of ways in MLflow:
TruLens scorers can be called directly on the data for evaluation.
from mlflow.genai.scorers.trulens import Groundedness
scorer = Groundedness(model="openai:/gpt-4o-mini")
feedback = scorer(
outputs="Paris is the capital of France.",
expectations={"context": "France is a country in Europe. Its capital is Paris."},
)
print(feedback.value) # "yes" or "no"
print(feedback.metadata["score"]) # 0.0 to 1.0RAG and output scorers (like Groundedness, Coherence) can be called directly with data as shown above. Agent GPA scorers (ToolSelection, ToolCalling, etc.) require a trace parameter since they evaluate tool usage patterns within the trace spans.
Using an MLflow formatted data set, you can evaluate in batch with TruLens scorers.
import mlflow
from mlflow.genai.scorers.trulens import Groundedness, ContextRelevance, AnswerRelevance
# Static dataset with pre-computed outputs and context in expectations.
# Note: TruLens RAG scorers (Groundedness, ContextRelevance) extract context from
# expectations["context"] when no retrieval spans exist in the trace.
# This works, but for production use, prefer trace-based evaluation (see below).
eval_dataset = [
{
"inputs": {"question": "What is MLflow?"},
"outputs": "MLflow is an open-source platform for ML lifecycle management.",
"expectations": {
"context": "MLflow is an open-source platform for managing the end-to-end machine learning lifecycle."
},
},
]
results = mlflow.genai.evaluate(
data=eval_dataset,
scorers=[
Groundedness(model="openai:/gpt-4o-mini"),
ContextRelevance(model="openai:/gpt-4o-mini"),
AnswerRelevance(model="openai:/gpt-4o-mini"),
],
)
print(results.tables["eval_results"])Static data sets work well for evaluating RAG pipelines with pre-computed context. For agent evaluation with Agent GPA scorers, use predict_fn to generate traces that capture tool selection and execution (see the next example).
You can also use scorers with MLflow tracing through the tight integration with MLflow's tracing infrastructure. This example shows batch evaluation of an agent with tool usage:
import mlflow
from mlflow.genai.scorers.trulens import Groundedness
# autolog instruments all OpenAI SDK calls automatically
mlflow.openai.autolog()
@mlflow.trace
def my_rag_app(question: str) -> str:
# Step 1: Retrieve context (creates a RETRIEVER span)
context = retrieve_context(question) # your retrieval function
# Step 2: Generate answer using retrieved context
response = openai.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": f"Answer based on: {context}"},
{"role": "user", "content": question},
],
)
return response.choices[0].message.content
# 1. Call the function — this generates and logs a trace
result = my_rag_app("What is MLflow?")
# 2. Retrieve the trace object
trace = mlflow.get_last_active_trace()
# 3. Now score it
scorer = Groundedness(model="openai:/gpt-4o-mini")
feedback = scorer(trace=trace)
print(feedback.value) # CategoricalRating.YES or CategoricalRating.NO
print(feedback.metadata) # {'mlflow.scorer.framework': 'trulens', 'score': ..., 'threshold': 0.5}This demonstrates that you can combine RAG scorers (Groundedness), agent scorers (ToolSelection, ToolCalling), and output scorers (Coherence) in a single evaluation pass.
By combining TruLens’ native Agent GPA framework with MLflow’s scale, we are establishing a cross-platform standard for evaluation. Whether your agents are built on Snowflake or elsewhere, you now have a consistent, rigorous way to measure and improve quality.
Ready to improve your agent's GPA? Check out the TruLens documentation to start using the new scorers in MLFlow today.
Thanks to the MLflow maintainers and reviewers for upstream API feedback and stability review, and to the TruLens maintainers for review and validation of scorer semantics and trace-aware evaluation behavior.
The MLflow–TruLens integration was initiated and implemented by Debu Sinha. This work was developed and reviewed in the open across the MLflow and TruLens communities.
