
FEB 13, 2026|10 min read

Agentic AI services turn natural-language intent into actions by planning, invoking tools and iterating across multiple turns to reach a correct outcome. Within these agentic loops, decoding latency becomes a primary bottleneck and can compound across steps. Today’s best LLMs mostly decode autoregressively from left to right, which gives great quality but is slow. Agentic systems for applications like text2SQL coding that interact with databases make serial decoding incurs even higher latency: They run in multistep loops for planning, tool calling and refinement, and each step can require long generations. With standard autoregressive (AR) decoding, latency scales almost linearly with output length.
Decoding can be sped up in two ways: speculative decoding (i.e., a small “draft” model proposes tokens that a larger model verifies) or diffusion-style decoding (i.e., the model predicts many tokens in parallel). Speculative decoding requires coordinating proposal-verification and sometimes serving a second model, increasing system complexity and overhead. Diffusion-style decoding avoids the second model and offers more direct tokens-per-forward gains, but most diffusion LLMs are non-causal and require training from scratch or heavy adaptation from AR checkpoints; this mismatch can hurt quality and is less compatible with KV-cache optimizations built for strict left-to-right generation.
This blog introduces Jacobi Forcing, a training technique that turns a standard AR transformer into a causal parallel decoder: It still respects the AR objective and advances left-to-right, but it learns to generate correctly under imperfect context. At inference time, we perform Jacobi-style parallel decoding over blocks and predict future tokens while conditioning on partially non-converged (noisy) tokens, committing multiple tokens at once.
Overall, Jacobi Forcing delivers near-AR quality with much higher throughput and yields up to 4.5x higher tokens-per-forward. On A100, Jacobi Forcing (MR) reaches 4x speedup on HumanEval (83.5 pass@1) and 3.7x speedup on GSM8K (91.4 solve rate). The method preserves efficient KV-cache reuse and avoids the extra drafting-verification stack required by speculative decoding.
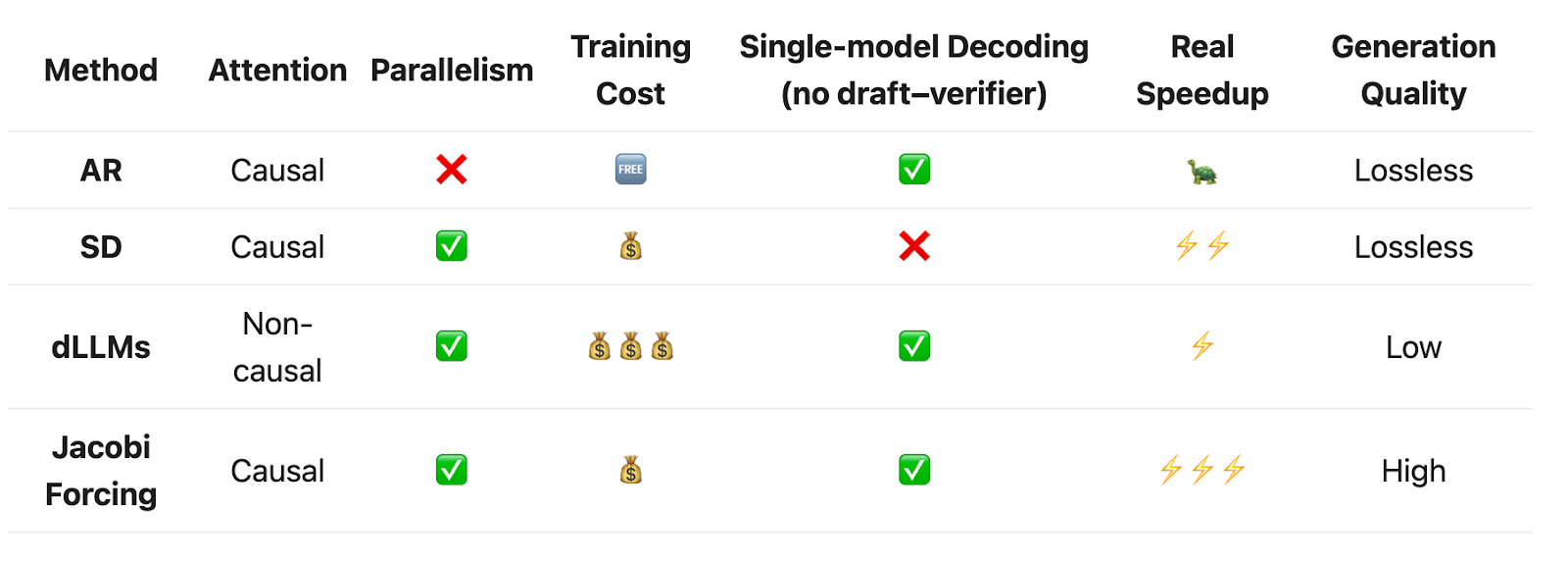
Existing work on faster decoding falls into two families: (1) diffusion-style LLMs (dLLMs), which denoise token blocks with non-causal attention, and (2) speculative decoding (SD), which keeps causal AR decoding but verifies draft proposals in chunks.
Table 1 summarizes the trade-offs: dLLMs offer parallelism but require costly non-causal post-training and custom infrastructure; SD is lossless but adds draft overhead and serving complexity.
Diffusion-style dLLMs iteratively denoise entire token blocks with variants of bidirectional attention. At each step, the model sees a globally noisy sequence and tries to predict a cleaner one, updating many positions in parallel. This offers a natural form of parallel decoding, but comes with several trade-offs.
Most work therefore starts from an AR checkpoint and post-trains it with a denoising objective, which creates two mismatches:
objective mismatch (clean prefixes vs. globally noised sequences), which can hurt AR-level quality; and
attention/infrastructure mismatch (switching to non-causal attention), which breaks KV-cache reuse and complicates production batching/scheduling.
In practice, these models often need substantial extra post-training and still lag strong AR baselines in accuracy and/or realize limited wall-clock speedups (Figure 5).
Speculative decoding (SD) keeps the causal AR backbone and its lossless quality, but introduces an additional draft stage. A draft model (or draft head) proposes multiple future tokens. The target model (the main AR backbone) then verifies these proposals and accepts or rejects them in parallel.
In the ideal case, SD yields multiple tokens per target forward pass without quality loss, but real systems pay overheads: (1) draft compute/memory/latency, and (ii) serving complexity (two-stage orchestration, drafting-length heuristics, and more complex batching/scheduling).
As a result, end-to-end speedups often plateau around ~2–3× even when acceptance length per step looks high.
Table 1 summarizes the trade-offs of all decoding methods discussed above:
Standard AR decoding: Simple, high quality, but strictly serial.
SD: Keeps AR quality but adds draft overhead and system complexity.
dLLMs: Strongly parallel but require expensive non-causal post-training and custom infrastructure.
This leads to the central question:
Can we build a native causal parallel decoder that (i) runs fast like diffusion-style methods, (ii) preserves AR-level quality, and (iii) fits naturally into existing KV-cache-based serving systems without extra models or heavy architectural changes?
With Jacobi Forcing, the answer is "yes."
Jacobi Forcing builds on Jacobi decoding, a causal parallel procedure that iteratively refines a token block until it matches the greedy AR fixed point, while preserving causal attention (and KV-cache compatibility).
Prior CLLM work showed that fine-tuning on Jacobi trajectories can shorten convergence, but it did not fully address hardware utilization or long-horizon noisy context.
Jacobi Forcing pushes this further with noise-conditioned training plus an inference algorithm that reuses stable draft n-grams. It turns a standard AR checkpoint into an efficient causal-parallel decoder with AR-like quality (Table 1).
Jacobi Forcing starts by collecting Jacobi trajectories from a base AR model. The key intuition is to treat intermediate Jacobi states as “noisy views” of the final fixed point. Unlike diffusion LLMs, this noise comes from causal, model-generated states rather than global random corruption, preserving AR structure and KV-cache compatibility.
To make learning stable at large block sizes, without switching to non-causal denoising as in diffusion models, Jacobi Forcing uses a progressive noise schedule within each packed training sequence:
Split the response into blocks and assign each block a target noise level.
For each block, pick the Jacobi intermediate state whose “how unconverged it is” best matches that target noise level.
Pack blocks so that noise levels cycle from easy to hard, instead of creating long stretches of fully corrupted tokens.
This keeps denoising learnable while covering a range of noise levels per sequence (Figure 1).
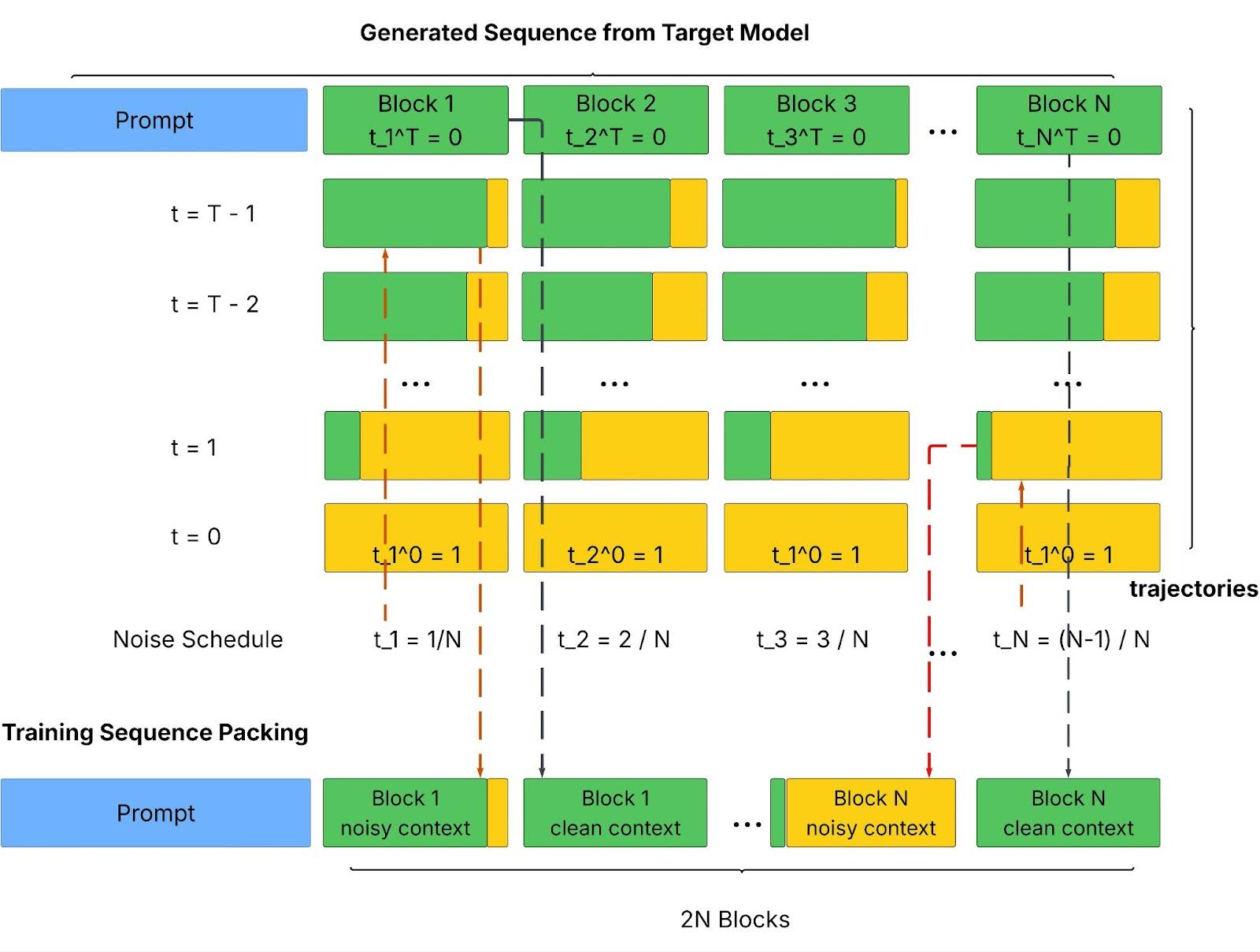
Jacobi Forcing packs unconverged noisy blocks and their clean fixed-point targets into one long sequence, then Jacobi Forcing uses a noise-conditioned causal attention mask so the model can:
Distinguish noisy blocks from their fix-point counterparts for each block
Make each noisy block see the prompt and earlier blocks at their assigned noise levels
Expose the clean blocks needed to compute a teacher distribution
This allows a single AR model to learn both drafting and verification internally as a native parallel decoder, avoiding the extra draft model and orchestration required by speculative decoding.
Compared to clean-context-only training, one forward/backward pass covers many blocks and noise levels (Figure 2). The objective combines:
Progressive consistency distillation (map noisy blocks into clean targets under noisy context)
AR loss (anchor to greedy AR outputs)
Together, the final objective is therefore:
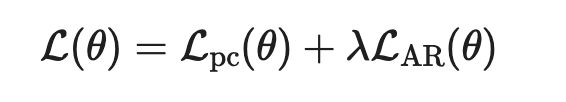
where lambda > 0 balances progressive consistency and AR fidelity.
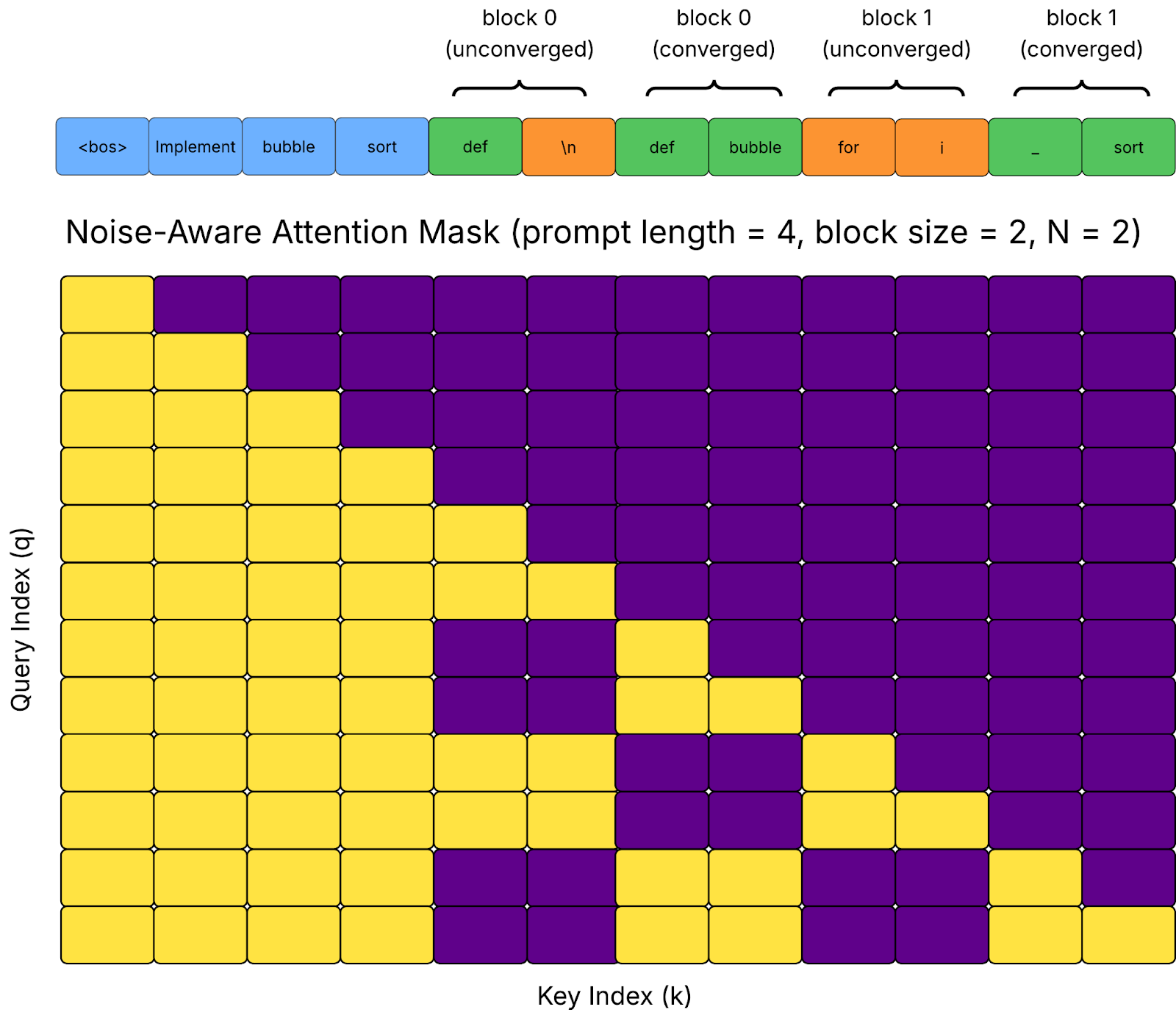
After training, Jacobi Forcing model is still a standard AR checkpoint, but its Jacobi trajectories change qualitatively:
Intermediate Jacobi states now contain long n-grams in the draft that already match the final greedy AR output. Such n-gram tends to stay correct across iterations, despite their positions potentially being wrong.
As a result, we can cache these stable n-grams and reuse them at the right positions in subsequent verification steps for further speedup.

Figure 3: Visualization of Jacobi Forcing model’s trajectory under vanilla Jacobi decoding. The figure shows a partial segment of the trajectory. Blue tokens denote accepted tokens that match the fixed point at their positions. Black tokens denote unconverged noisy tokens, and we highlight them in red if more than three consecutive tokens match the fixed point regardless of position.
To better utilize hardware FLoating-point Operations Per Second (FLOPs) for higher speedup, Jacobi Forcing model employs multiblock Jacobi decoding. Maintain up to K blocks in flight: one real-active block (verified and committed to KV cache) and pseudo-active blocks (iteratively updated but not committed). When the real-active block converges, promote a pseudo-active block and verify again under the updated prefix.
Orthogonally, Jacobi Forcing applies rejection recycling to avoid wasting good drafts (see example in Figure 4): Cache promising draft n-grams in a pool, then verify multiple candidates in parallel and keep the path with the best tokens-per-forward (TPF).
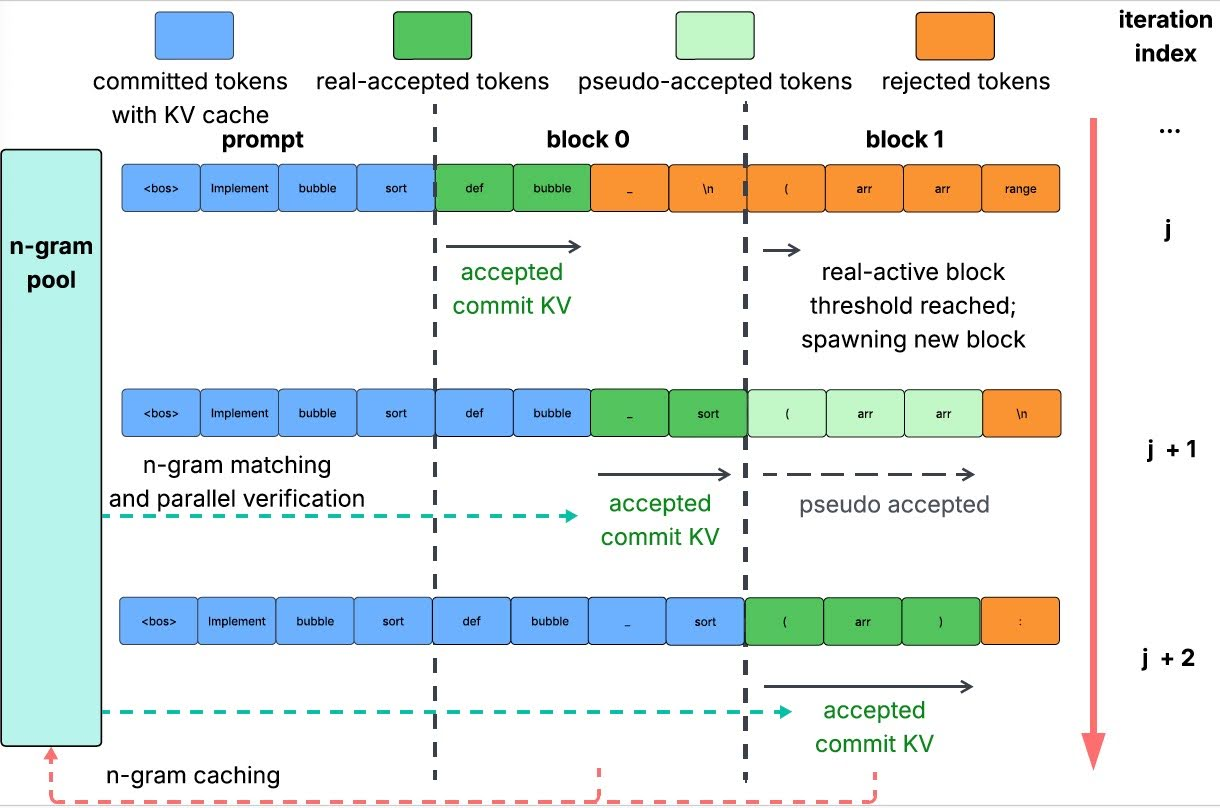
Figure 4: Illustration of multiblock Jacobi decoding with rejection recycling. High-quality n-grams from earlier iterations are reused as drafts. Up to K blocks (here K=2) are maintained: Earlier blocks are real-active and commit tokens to the KV cache, while later pseudo-active blocks run Jacobi updates under noisy context and are only verified and committed after all preceding blocks have been finalized in the KV cache.
Jacobi Forcing works at two levels:
Intra-trajectory (within a block): Train intermediate Jacobi states to map to the fixed point, enabling fast-forwarding over common n-grams.
Inter-trajectory (across blocks): A light-to-heavy noise curriculum across blocks makes long-horizon denoising easier and improves draft quality under noisy futures.
Our ablation-study models, trained on a 10,000-example subset of data, show that linear progressive noise schedule outperforms both random and reverse progressive schedules, where reverse progressive (putting the heaviest noise first) is clearly harmful, leading to the slowest convergence.

Jacobi Forcing is evaluated on:
Coding benchmarks: HumanEval and MBPP with Qwen2.5-Coder-7B-Instruct
Math benchmarks: GSM8K and MATH with Qwen2.5-Math-7B-Instruct
Compared to dLLM baselines at 7B scale, Jacobi Forcing model offers a much better accuracy-to-speed trade-off: On HumanEval, Jacobi Forcing reaches 4.0x speedup at 82.3%, versus D2F at 1.8x and 54.3%. On GSM8K, Jacobi Forcing reaches 3.7x at 91.4%, versus D2F at 2.2x and 77.6%. Similar trends hold on MBPP and MATH.
Compared to CLLM-style parallel decoders at the same 7B scales, Jacobi Forcing model consistently provides ~1.7x higher throughput at similar or slightly lower accuracy, while keeping the pure AR backbone and KV reuse:
On HumanEval, CLLM achieves 2.5x speedup with 88.0% accuracy, whereas Jacobi Forcing model (MR) achieves 4.0x speedup with 82.3%.
On GSM8K and MATH, CLLM reaches about 2.1x speedup; Jacobi Forcing model (MR) pushes this to 3.7x with negligible accuracy change.
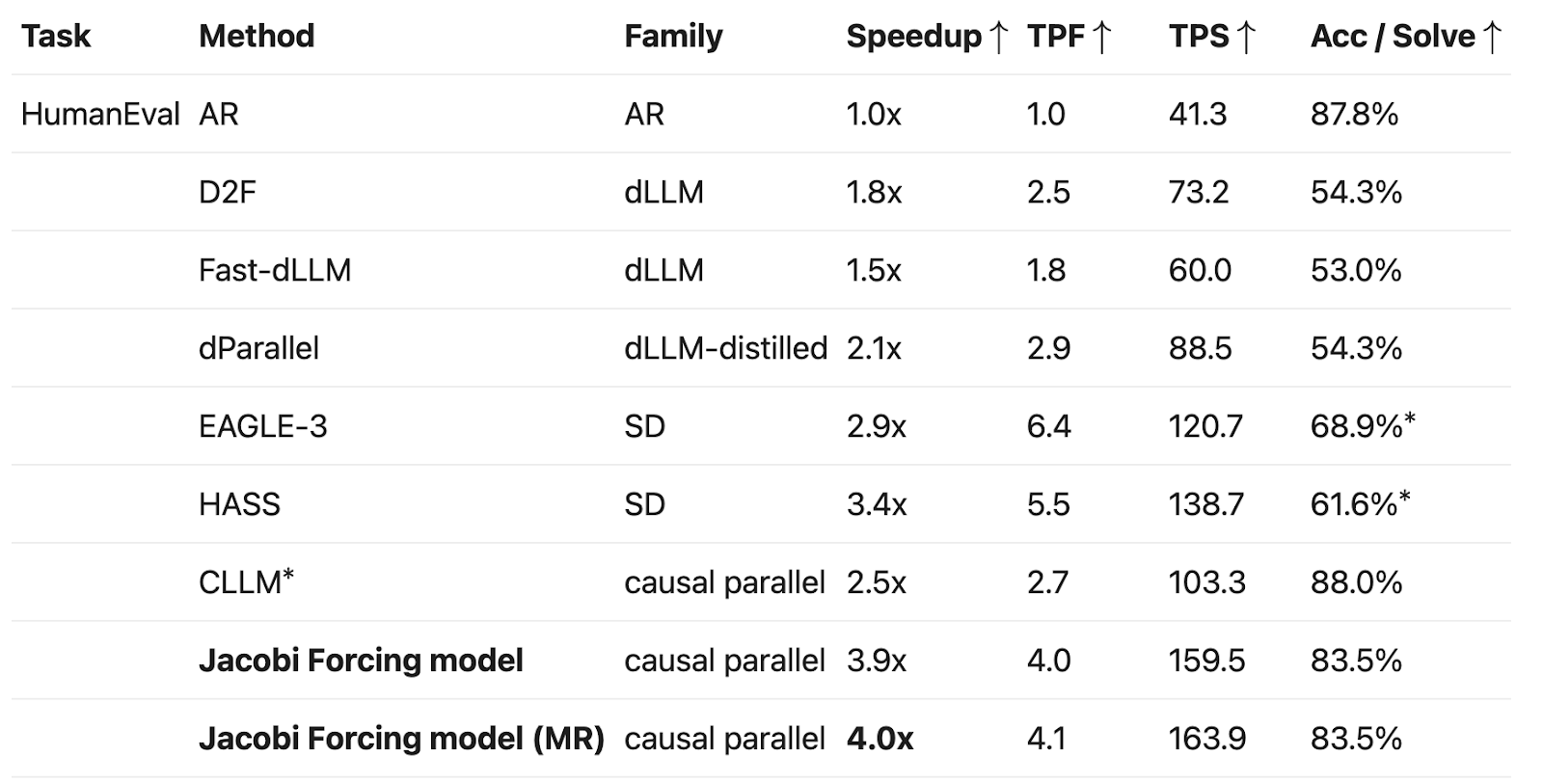
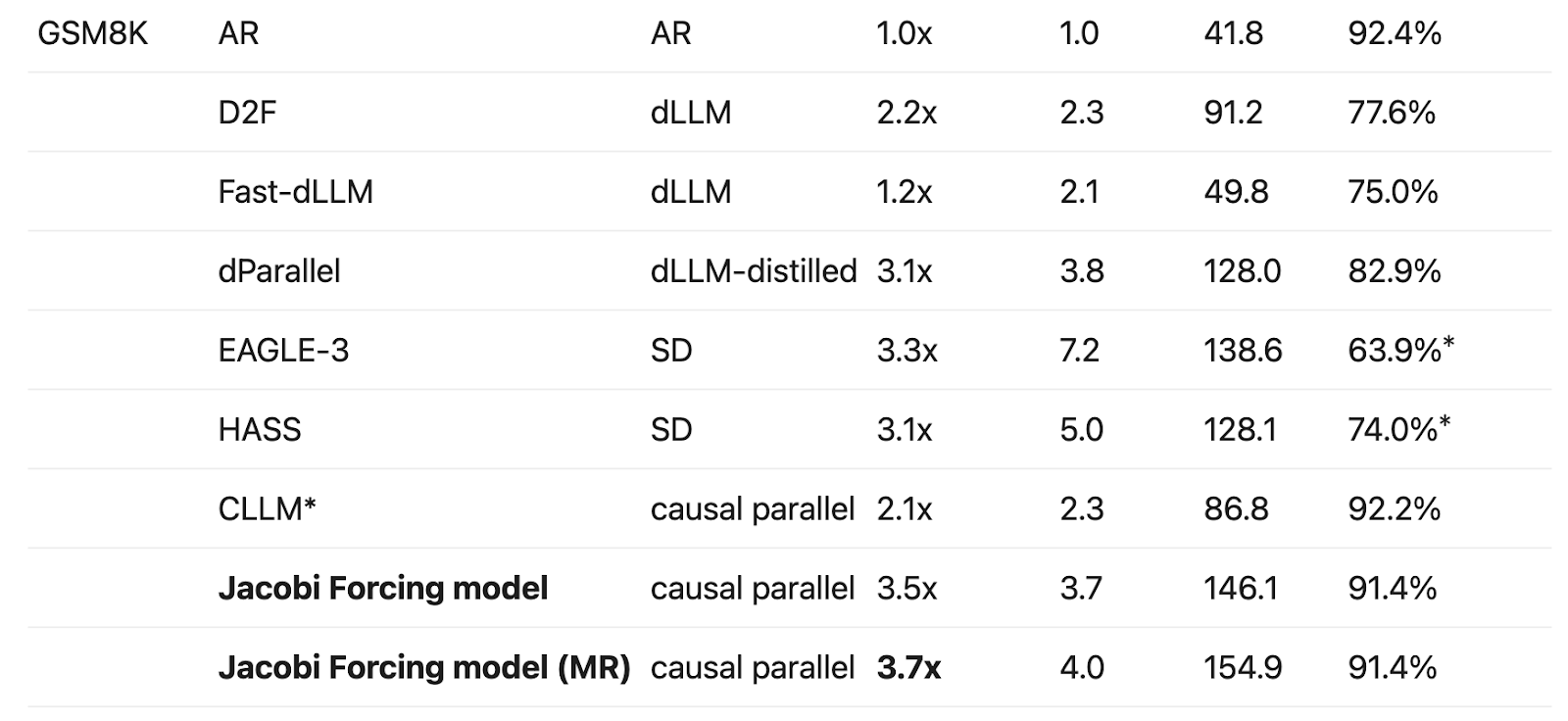
Table 3: Generation quality and efficiency comparison among Jacobi Forcing model, baseline SD and baseline dLLM methods. *Here we report the strongest checkpoints released by the authors; in principle EAGLE-3 and HASS are lossless in comparison with greedy AR checkpoints if they were trained with the Qwen2.5-7B backbone. Note that SD has a worse acceptance length (TPF)-to-TPS conversion ratio due to other overheads in the algorithm such as token drafting using draft head, tree-like verification overhead, feature merging from different layers, etc.
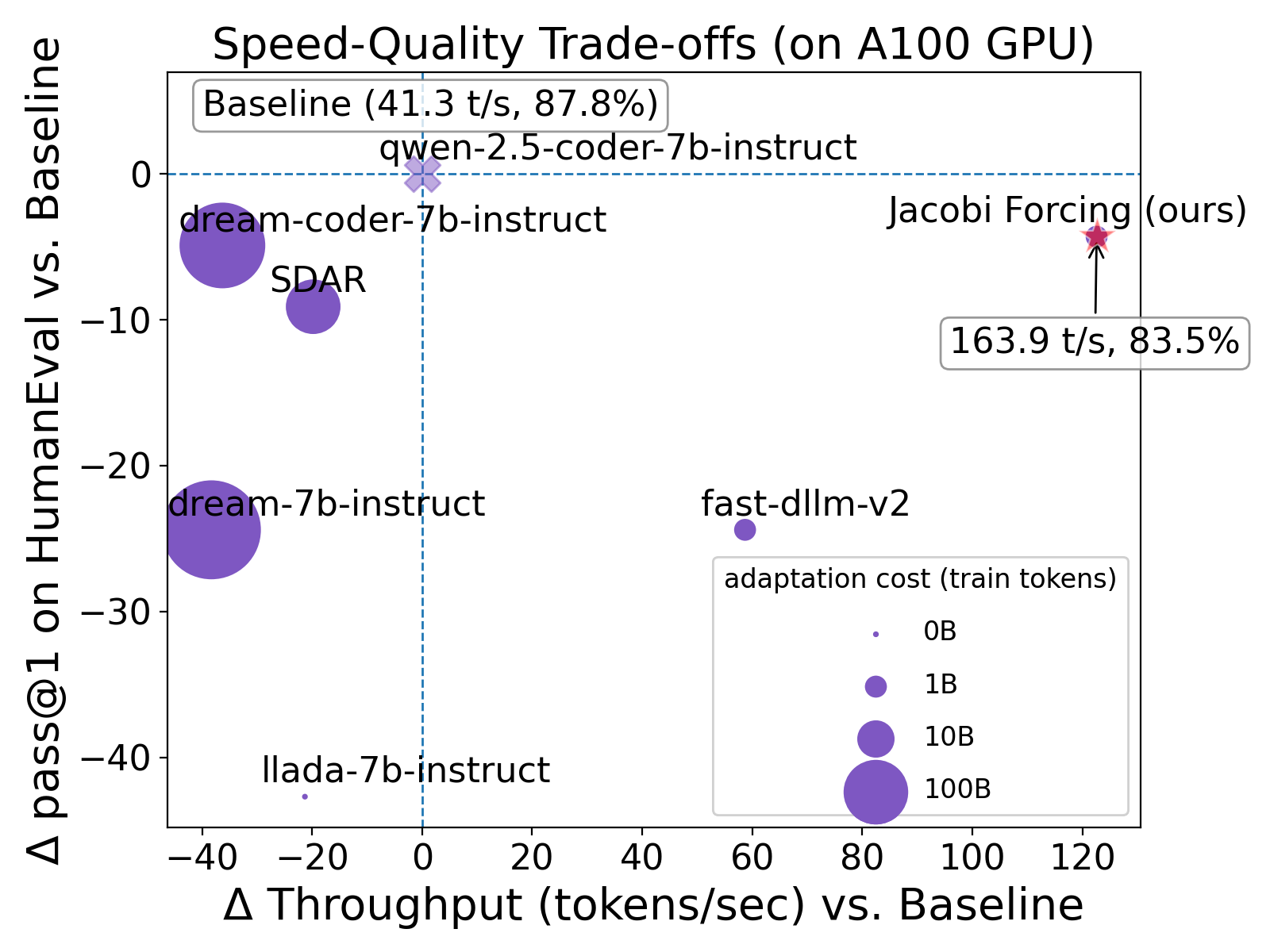
Overall, Jacobi Forcing delivers up to 4x wall-clock speedup with minor accuracy changes, as compared to greedy AR, outperforming dLLMs and prior consistency-based decoders in the accuracy-to-throughput trade-off (Figure 5).
On a single B200 GPU with much higher FLOPs, the same Jacobi Forcing model with multiblock and rejection recycling can achieve an even more significant speedup at around 330 tokens/s (vs. around 80 tokens/s using AR), showing that the design continues to scale on newer accelerators.
Snowflake builds and provides agentic AI services where end-to-end latency is critical for customer experience. At Snowflake AI Research, we actively develop serving and inference optimizations to make these agentic workloads faster and more cost-effective at production scale. Jacobi Forcing serves the same goal, pushing the speed-to-quality frontier for high-concurrency, real-world agent execution.
We invite you to try Jacobi Forcing out of the box. The repository includes an interactive demo, along with evaluation scripts, allowing you to try it firsthand on your own workloads.
- GitHub: https://github.com/hao-ai-lab/Jacobi_Forcing
- Hugging Face: https://huggingface.co/JacobiForcing





