
JAN 16, 2025|10 min read

The demand for specialized AI has never been higher. While foundation models like GPT, Claude and Llama excel at general tasks, enterprises are often finding off-the-shelf LLMs insufficient for domain-specific work or cost prohibitive for production scenarios.
Fine-tuning addresses this gap. By continuing to train a pretrained model on your proprietary data, you can adapt a generalist into a specialist: healthcare organizations generating clinical documentation, financial institutions parsing regulatory language, legal teams extracting key contract clauses. In many domain-specific evaluations, teams have observed higher task accuracy from fine-tuned models than from prompting alone, and in some cases lower inference cost, depending on model size, workload, and deployment configuration.
The challenge is that fine-tuning LLMs is operationally complex. This article explores how Snowflake ML Jobs and ArcticTraining work together to simplify the process, letting you fine-tune LLMs directly inside Snowflake without worrying about infrastructure management or data governance.
Traditional fine-tuning workflows require you to extract and move sensitive data from your data warehouse to external training infrastructure, raising potential security and compliance concerns. You have to provision and manage GPU clusters, dealing with availability, cost optimization and infrastructure sprawl. You need to orchestrate multistep pipelines spanning data preparation, training, checkpointing and evaluation across disconnected systems. And you have to manually track experiments and model versions across different storage systems.
For enterprises with strict data governance requirements, the prospect of copying medical records, financial transactions or customer data to third-party compute environments is often a nonstarter. Even when it's technically feasible, the operational overhead of maintaining separate training infrastructure can delay projects by months.
What if you could fine-tune LLMs directly where your data already lives?
ArcticTraining is Snowflake's open source framework, purpose-built for LLM post-training. It provides declarative YAML configurations for reproducible training runs and integrates with Hugging Face and DeepSpeed for easy, efficient distributed training. ArcticTraining also hosts Snowflake research innovations like Arctic Long Sequence Training, which boosts the maximum trainable sequence length by 16×, 116×, and 469× compared with standard Hugging Face pipelines, and SwiftKV, which reduces LLM inference cost by up to 75%. ArcticTraining is deeply integrated with the Snowflake ecosystem including built-in Snowflake data connectors and Container Runtime aware hooks. To learn more about ArcticTraining's design and capabilities, see our introductory blog post.
Snowflake ML Jobs lets you run containerized Python workloads on Snowflake managed GPU compute pools. Your training code runs inside Snowflake's secure perimeter, with direct access to your tables and stages. No data extraction. No external infrastructure to manage. Just submit your job and let Snowflake handle the rest. By using ArcticTraining with ML Jobs, you have a streamlined, low-code config definition to set up your fine tuning workflow that helps you easily and securely develop LLM customization workflows directly using your production data.
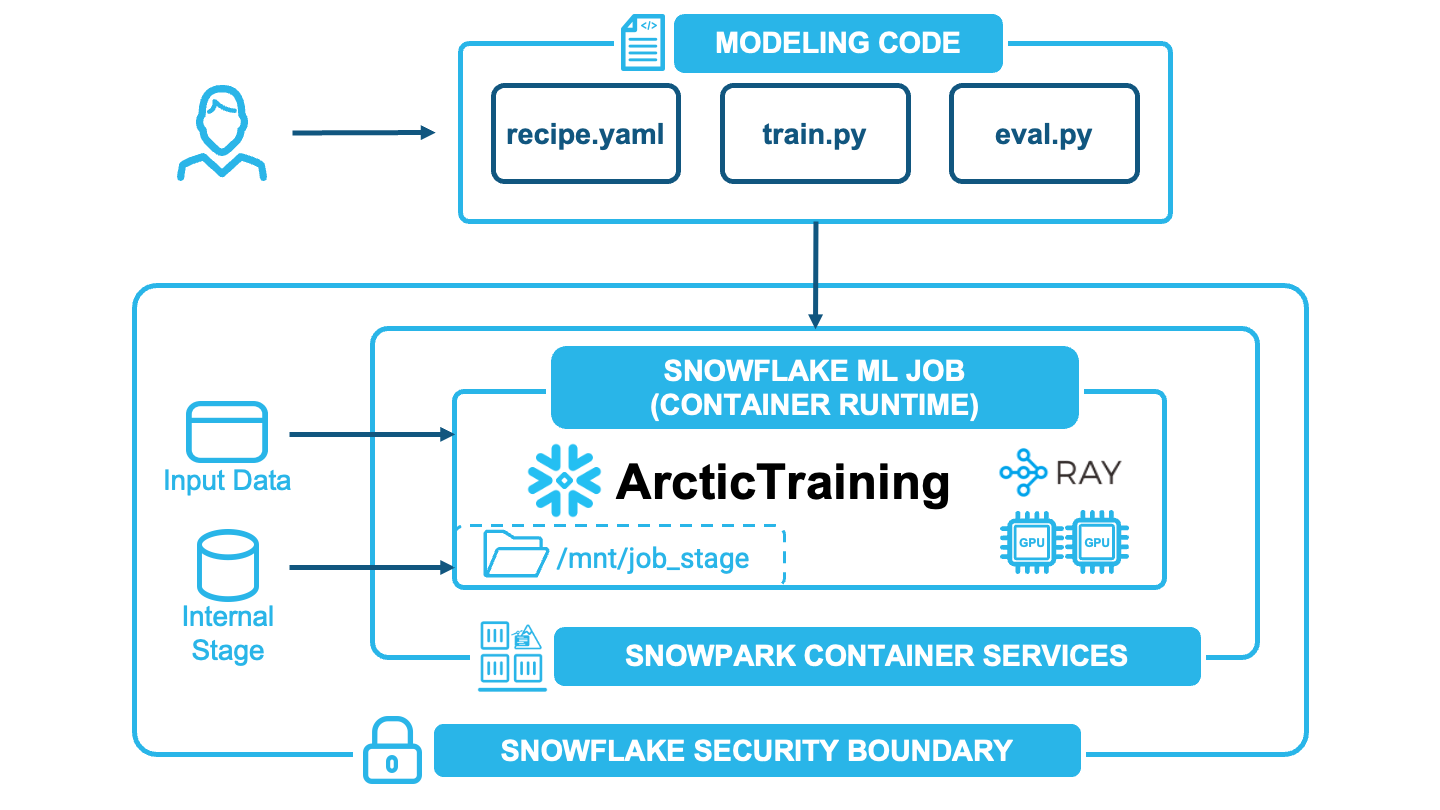
Together, they enable a streamlined workflow:
Data stays in place: ArcticTraining reads directly from Snowflake tables using native connectors. No CSV exports or cloud storage staging.
Training runs serverlessly: Submit jobs to GPU compute pools; Snowflake handles provisioning, scaling and teardown.
Checkpoints persist automatically: Model weights save directly to the ML Job’s mounted Snowflake stage, ready for evaluation or deployment.
Distributed training: Distribute across multi-GPU and multinode GPU clusters for larger models that don't fit on a single GPU.
Submitting a fine-tuning job takes just a few lines of code:
from snowflake.ml import jobs
job = jobs.submit_directory(
"src/",
entrypoint=["arctic_training", "Qwen3-1.7B-LoRA-config.yaml"],
compute_pool="GPU_POOL",
stage_name="payload_stage",
external_access_integrations=["PYPI_HF_EAI"],
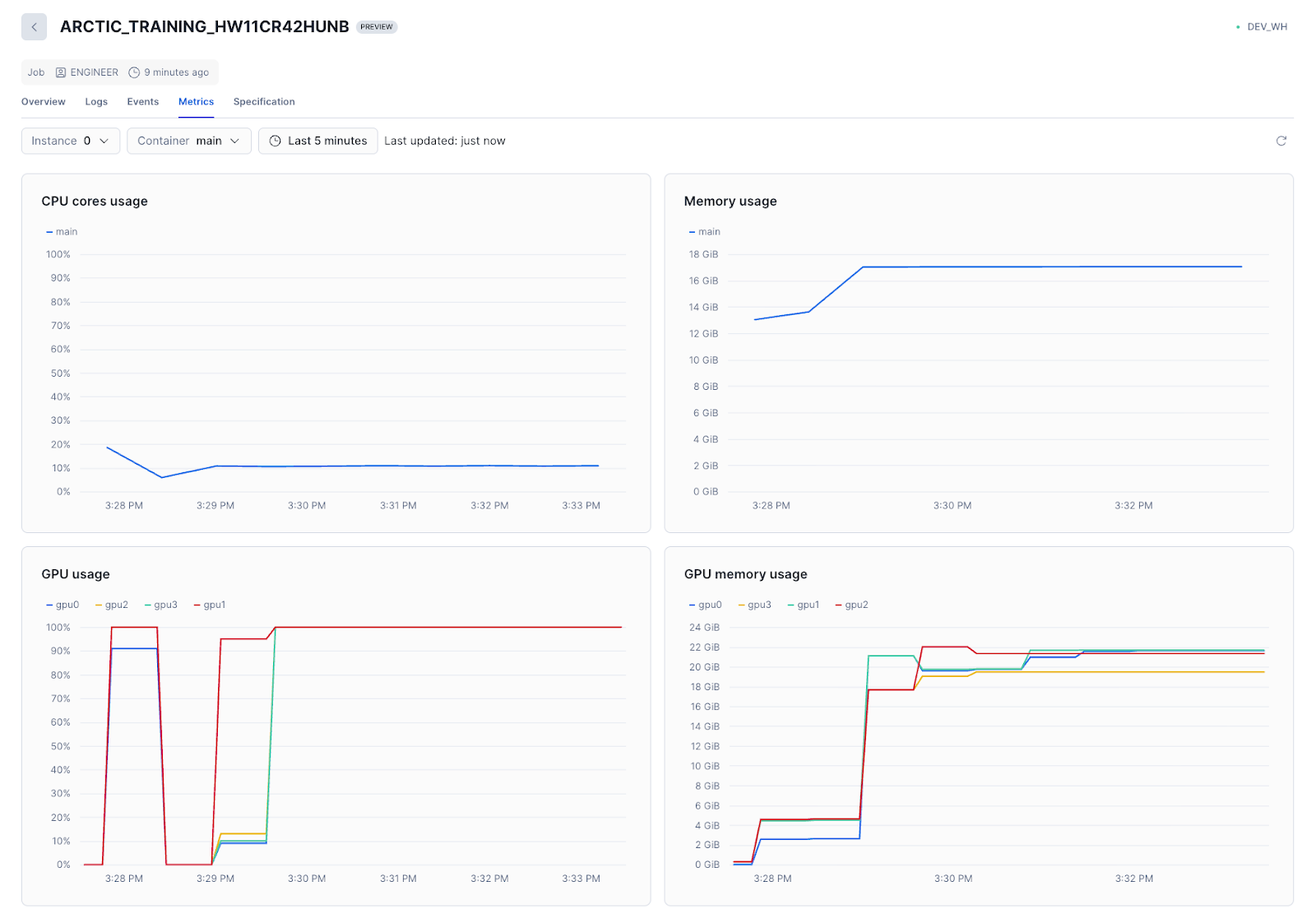
)ArcticTraining's YAML config handles the rest: model architecture, data sources, optimizer settings and checkpoint management. You can then monitor the training job directly in Snowsight, including viewing logs and system metrics.
ArcticTraining supports a wide range of techniques beyond full fine-tuning, such as LoRA (Low-Rank Adaptation) fine-tuning and Arctic Long Sequence Training. We’ve included recipes for both full fine-tuning and LoRA fine-tuning in our new LLM fine-tuning quickstart guide.
ML Jobs run in the Snowflake Container Runtime, which comes preconfigured with GPU drivers, ML frameworks and Ray. ArcticTraining interfaces with Ray directly for multinode training, coordinating batch distribution and gradient synchronization across workers. ArcticTraining also integrates with the DataConnector API to efficiently stream table data directly to training workers.
Each ML Job mounts a stage volume that exposes an internal Snowflake stage as a filesystem path inside the container. ArcticTraining detects and uses the mounted stage for model checkpoints, persisting the model weights inside Snowflake for retrieval and evaluation.
Full fine-tuning updates all model weights, which for a typical LLM means training tens or even hundreds of billions of parameters. This requires substantial GPU memory and can take hours, even on high-end hardware.
LoRA takes a different approach: It freezes the pretrained model and injects small, trainable low-rank matrices into transformer layers, typically training only 0.1%-1% of the original parameters. The result is faster training, lower memory usage and small adapter files (often tens of megabytes) that can be swapped at inference time. You can train multiple adapters for different tasks and serve them from a single base model.
Evaluating text generation quality is a challenging problem. Traditional text evaluation methods like BLEU and ROUGE fail to account for paraphrasing and synonyms and fail to account for tone and semantic meaning. On the other hand, human evaluation is subjective and prohibitively expensive at scale. State of the art on this is constantly evolving, but the most successful approach today is to use an LLM-as-judge approach where a strong teacher model evaluates generated outputs against ground truth or a predefined grading criteria. This provides more nuanced evaluation than simple text matching while remaining more scalable than human annotation.
We're investing heavily in making advanced ML techniques accessible to every Snowflake customer:
Integrated experiment tracking to compare runs, tune hyperparameters and manage model versions
Seamless deployment from training to production inference within Snowflake
Fine-tuning LLMs on proprietary data shouldn't require a dedicated infrastructure team or risky data exports. With ML Jobs and ArcticTraining, it doesn't.
Ready to try it yourself? We've published a quickstart guide that walks through the complete process, from data preparation to training to evaluation. The patterns apply to any domain with proprietary text and structured output requirements: financial reports, legal documents, customer support and more. Check out the guide.
Our quickstart prioritizes accessibility: It runs on mid-tier GPUs in less than an hour, making it easy to experiment and iterate. For your production fine-tuning workloads, we’ve gathered a list of recommended optimizations to consider for more optimal performance in real-world scenarios:
Larger base models: We used Qwen3-1.7B to keep the training fast and memory-efficient. Scaling up to 8B or 14B parameter models would provide stronger baseline capabilities and likely yield better fine-tuned performance, especially for complex medical reasoning.
More training data: The max_length setting in the training recipe filters out longer dialogues to fit within GPU memory constraints. Increasing this limit (or using gradient checkpointing to handle longer sequences) would retain more training examples and expose the model to a wider variety of clinical scenarios.
Extended training: We trained for just 1-2 epochs to demonstrate the workflow quickly. Longer training runs with learning-rate scheduling and early stopping based on validation metrics would help the model converge more fully.
Hyperparameter tuning: LoRA rank, learning rate and batch size all affect final quality. Systematic experimentation, easily enabled by ML Jobs' reproducible submissions, can yield meaningful gains.
Forward-looking statement: This content contains forward-looking statements, including about future product capabilities. These statements are not commitments to deliver any material, code, or functionality, and actual results may differ.



