Create an LLM-generated Data Catalog using Data Crawler
Jason Summer
Overview
The Data Crawler is an LLM-powered utility that prompts a Cortex Large Language Model (LLM) to generate a natural language description of each table and view contained in a Snowflake database and/or schema. The output of the utility is a catalog table containing natural language summaries of tables’ contents which can be easily reviewed, searched, and revised by team members. The utility can also update table/view comments directly.
Examples of where one might want to use the Data Crawler include:
- Understand the enterprise data landscape
- Survey enterprise data availability based on semantics
- Update table/view comments at scale
Solution Architecture: LLM-Generated Data Catalog using Data Crawler
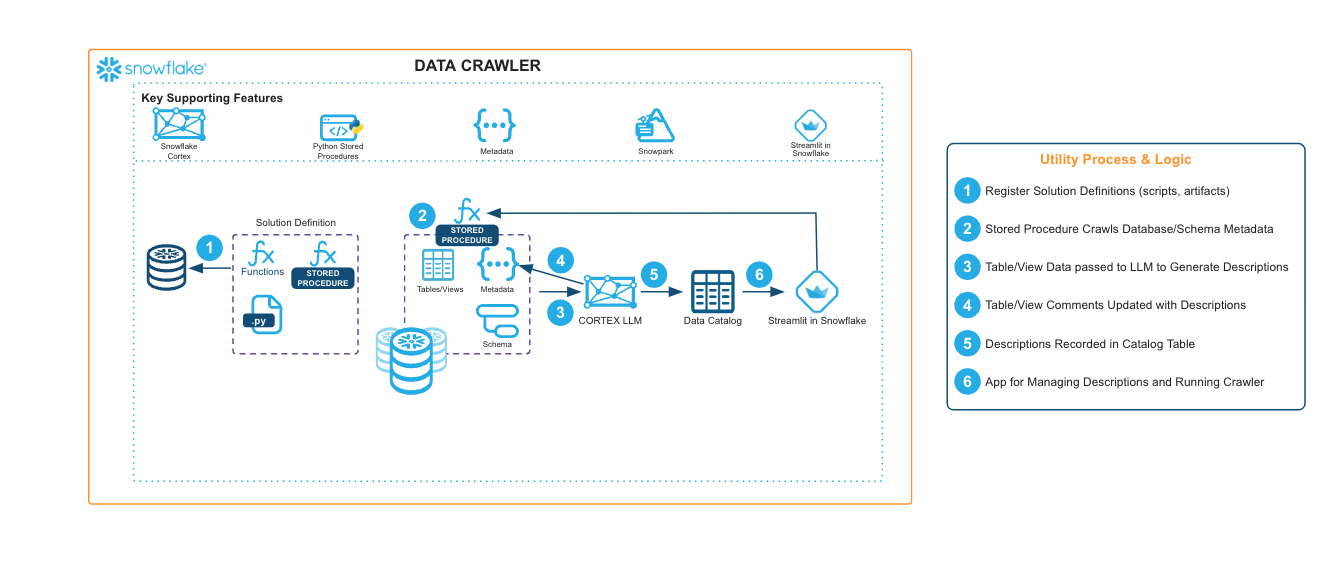
- For this utility, we create a Snowpark for Python stored procedure to crawl any database or schema to catalog tables and views using Cortex Large Language Model (LLMs).
- The Data Crawler will execute an asynchronous stored procedure for each table/view to infer data contents and relationships based on metadata, sample data, and neighbor table/views in the same schema.
- A Streamlit in Snowflake app enables users to execute the Data Crawler, search the generated data catalog, and make modifications to descriptions.
Get Started
Updated 2026-04-28
This content is provided as is, and is not maintained on an ongoing basis. It may be out of date with current Snowflake instances