
DEC 11, 2025|7 min read

The data landscape is undergoing a fundamental shift as organizations adopt open lakehouse architectures built on Apache Iceberg™. The promise is compelling: Bring engines to your data rather than data to your engines. This translates into “write data once” with your tool of choice; query it with Snowflake; and process it with Spark, using a shared catalog and metadata layer. However, when we built Snowflake Horizon Catalog’s catalog-linked database feature, which enables seamless integration with external Iceberg REST catalogs, we encountered a deceptively simple yet critical engineering challenge: identifier case sensitivity.
This isn't just about uppercase versus lowercase. It's about the fact that different compute engines have fundamentally incompatible rules for how they normalize and resolve table names, schema names and column names. A table created by Spark might be invisible to Trino, or queryable in Flink only with awkward quoting syntax, even though all three engines are reading from the same Iceberg catalog. These subtle incompatibilities threaten the core lakehouse vision of seamless multiengine interoperability and significantly increase the complexity data teams have to manage.
This post builds on our earlier engineering deep dives covering the following areas:
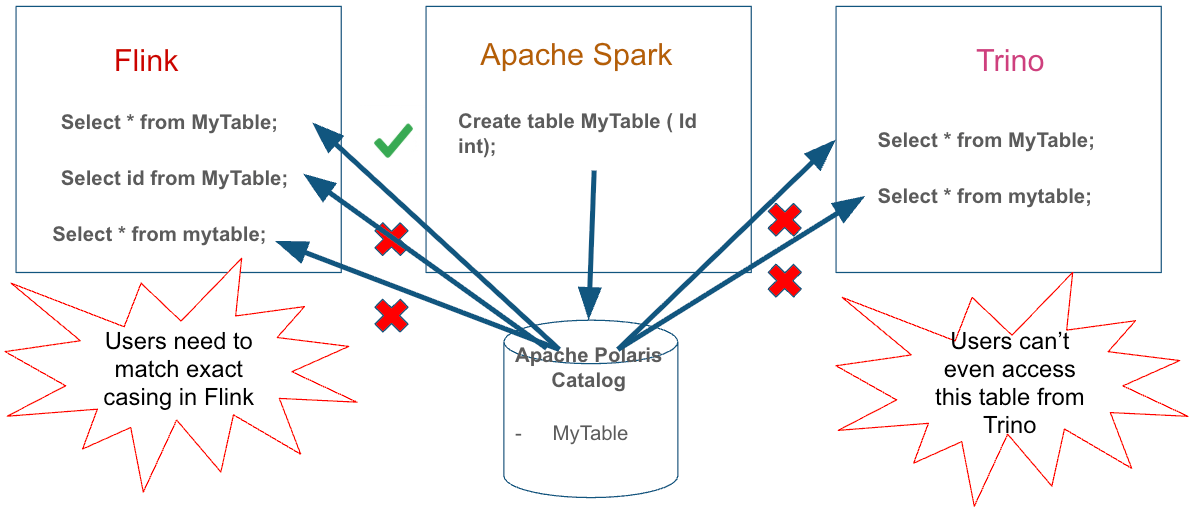
Consider a scenario that illustrates the problem. A data engineer working in Apache Spark connected to Apache PolarisTM creates a table:
CREATE TABLE my_lakehouse.MyTable (id INT, value STRING);Spark persists this table name in the Iceberg catalog metadata exactly as written: MyTable with mixed case.
Later, a business analyst attempts to query this table from Apache Flink:
SELECT * FROM my_lakehouse.mytable;This query will fail with a “table not found” error from both the engines. Flink preserves identifiers exactly as typed, so when the analyst writes mytable, Flink sends mytable to the catalog, which has the table stored as MyTable. If the catalog performs a case-sensitive lookup, the table is not found.
Now a data scientist tries the same query from Trino:
SELECT * FROM my_lakehouse.MyTable;This will also fail since Trino normalizes unquoted identifiers to lowercase (mytable), which will not match a mixed-case MyTable entry in a case-sensitive lookup.
The same table, created once, is now queryable in three different ways (or not queryable at all) depending on which engine you use. This isn't a bug in any single system; it's a fundamental mismatch in identifier normalization conventions that have evolved independently across different data ecosystems.
The problem compounds when you consider column names, partition specifications and schema names. This can result in inconsistencies, incorrect governance and workload failures that are hard to understand. For example, in the above workflow, if we start by creating the table from Trino (lowercase name) it can be successfully queried (although by paying quoting tax) across different engines by using their identifier conventions.
The core issue stems from many different identifier conventions that can very broadly (with many variations) classified as:
MyTable → mytable), lookups are case-insensitive, and the catalog stores only lowercase identifiers. This pattern emerged from the Hadoop ecosystem and Hive Metastore.MyTable → MYTABLE), quoted identifiers preserve exact case, and lookups are case-sensitive. This is the ANSI SQL-92 standard.Different Iceberg REST catalogs also have different capabilities. AWS Glue and Unity Catalog only accept lowercase identifiers and will reject or convert uppercase names to lowercase. Polaris supports any casing and can store tables that differ only in case.
The solution requires adapting Snowflake's behavior to match both the conventions and the capabilities of each specific external catalog.
When we designed Snowflake's catalog-linked database (CLD) to integrate with external Iceberg REST catalogs, we ran into a core reality of lakehouses: There is no single “correct” identifier dialect.
Some catalogs and engines come from the Hadoop lineage (lowercase, case-insensitive). Others follow ANSI SQL conventions (uppercase-by-default, case-sensitive when quoted). And crucially, catalogs differ in what they permit: Some only allow lowercase; others allow any casing and can even treat names that differ only by case as distinct objects.
So rather than trying to “guess” the right behavior per statement (which inevitably breaks one engine or another), we made a deliberate engineering choice: Make the identifier contract explicit at the catalog-linked database boundary.
That contract is configured once at database creation time using CATALOG_CASE_SENSITIVITY. This tells Snowflake how it should normalize and resolve identifiers in that CLD so that tables you create and query in Snowflake line up with the expectations of the other engines sharing the same catalog metadata. The detailed identifier rules are documented under Requirements for identifier resolution in catalog-linked databases.
Importantly, the default value is CASE_INSENSITIVE, reflecting the reality that many lakehouse deployments are anchored on Hadoop-style catalogs (and conventions), such as Glue and Unity. Snowflake also provides CASE_SENSITIVE as an explicit opt-in for catalogs that permit all casings (such as Polaris, Lakekeeper, etc.) and for environments where existing database engines and tools expect ANSI SQL identifier behavior.
This choice is scoped to the CLD boundary. You can configure different catalog-linked databases with different case sensitivity contracts (i.e., one CLD pointing to Glue with CASE_INSENSITIVE and another CLD pointing to Polaris with CASE_SENSITIVE). Outside of those CLDs, the rest of your Snowflake account continues to follow standard ANSI SQL identifier behavior.
When you're working with catalogs that only permit lowercase identifiers (for example, AWS Glue or Databricks Unity Catalog) or use Apache Polaris as lowercase only catalog, you want Snowflake to participate using Hadoop-style conventions:
CREATE DATABASE my_glue_linked_db
LINKED_CATALOG = (
CATALOG = 'my_glue_catalog_integration',
ALLOWED_NAMESPACES = ('analytics')
)
CATALOG_CASE_SENSITIVITY = CASE_INSENSITIVE; -- default value (can be omitted)Now, if you create a schema and an Iceberg table in that database, Snowflake will normalize identifiers in a way that matches what those catalogs (and engines like Spark) expect:
USE DATABASE my_glue_linked_db;
CREATE SCHEMA Analytics; -- normalized to analytics
CREATE ICEBERG TABLE CustomerOrders ( -- normalized to customerorders
OrderID INT, -- normalized to orderid
CustomerName STRING, -- normalized to customername
OrderDate DATE -- normalized to orderdate
) PARTITION BY (OrderDate); -- normalized to orderdateThe practical result is the behavior you want in a shared lakehouse: A Spark job that expects lowercase identifiers from Glue sees the same names that Snowflake wrote, without brittle, engine-specific workarounds.
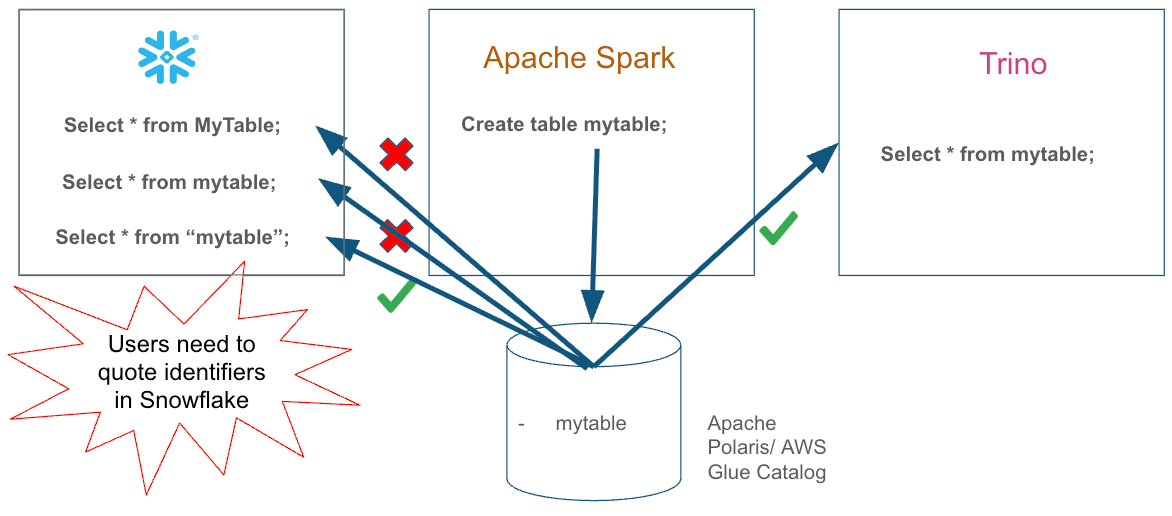
BEFORE
Double-quoted identifiers were required when Snowflake's CLD was linked to Hadoop-compatible catalogs (such as AWS Glue or Unity) or when engines like Trino and Spark utilized catalogs like Apache Polaris in Hadoop-compatible mode.
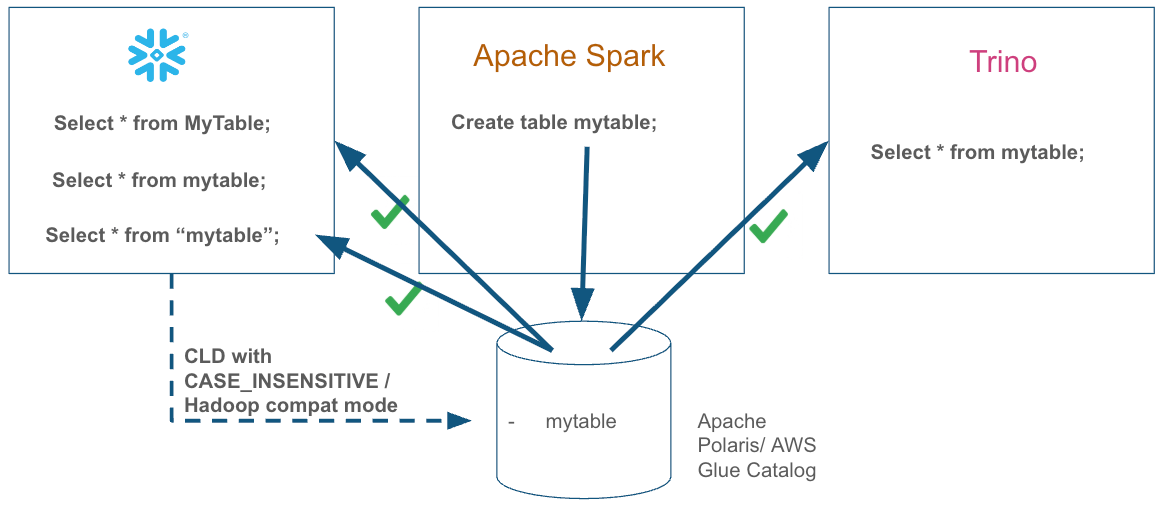
AFTER
New identifier enhancements in Snowflake eliminate the need for users to double-quote identifiers when querying data, simplifying the process of writing new queries and migrating existing workloads to Snowflake from other engines.
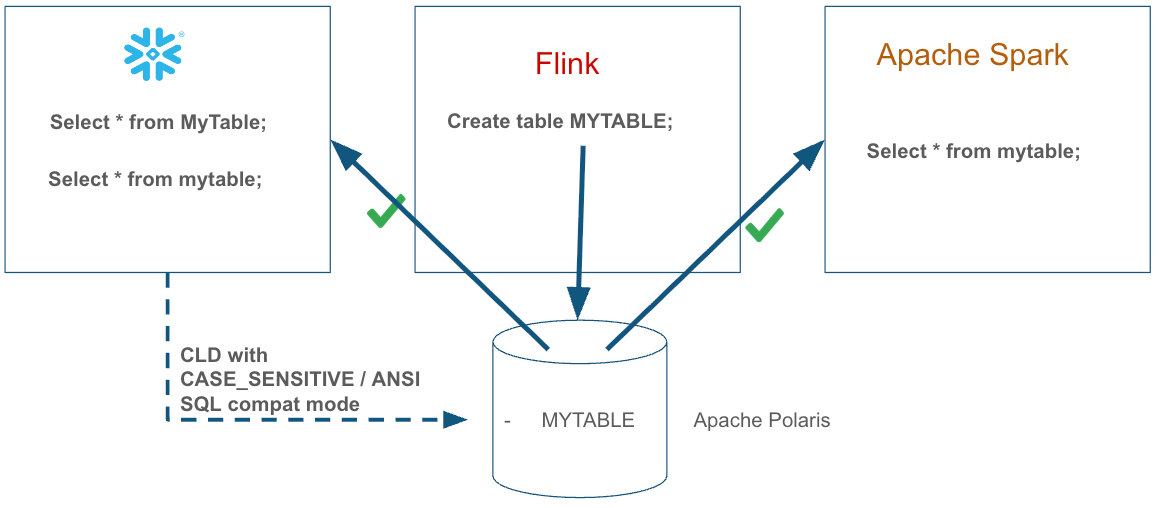
When you're working with catalogs that permit all casings, like Apache Polaris, you can choose to have Snowflake participate using ANSI SQL conventions:
CREATE DATABASE my_polaris_db
LINKED_CATALOG = (
CATALOG = 'my_polaris_catalog_integration'
)
CATALOG_CASE_SENSITIVITY = CASE_SENSITIVE;In this mode, Snowflake normalizes unquoted identifiers to uppercase, just as it does for native Snowflake tables:
USE DATABASE my_polaris_db;
CREATE ICEBERG TABLE SalesData ( -- normalized to SALESDATA
ProductID INT, -- normalized to PRODUCTID
"Revenue" DECIMAL(10,2) --preserves case for delimited identifier "Revenue"
);This writes the table as SALESDATA with columns PRODUCTID and Revenue into Polaris. If other SQL-compliant engines are using the same catalog and the same normalization conventions, the table name resolves naturally without forcing everyone to adopt quoting or engine-specific naming conventions. This is especially useful when working with ANSI SQL compatible databases or data warehouses that produce iceberg tables as CDC output.
The following table illustrates the outcomes of various SQL statements across Polaris and Glue when configured with either CASE_INSENSITIVE (Hadoop) or CASE_SENSITIVE (ANSI) settings.
| SQL Statement | Catalog Case Sensitivity | Polaris | Glue |
|---|---|---|---|
CREATE SCHEMA MySchema |
CASE_INSENSITIVE (Hadoop) |
myschema (lowercased) |
myschema(lowercased) |
CREATE SCHEMA MySchema |
CASE_SENSITIVE (ANSI) |
MYSCHEMA (uppercased) |
ERROR 4510 (uppercased and rejected) |
CREATE ICEBERG TABLE OrderData (CustomerID INT) |
CASE_INSENSITIVE (Hadoop) |
Table: orderdata, Column: customerid (all lowercased) |
Table: orderdata, Column: customerid (all lowercased) |
CREATE ICEBERG TABLE OrderData (CustomerID INT) CREATE ICEBERG TABLE orderdata (customerid INT) |
CASE_SENSITIVE (ANSI) |
Table: ORDERDATA, Column: CUSTOMERID (all uppercased - ANSI SQL normalization) |
ERROR 4510 (uppercased/ rejected) |
SELECT col FROM schema.tablename |
CASE_INSENSITIVE (Hadoop) |
Resolves (case-insensitive match) tables with names: TableName, TABLENAME or tablename etc. |
Resolves (case-insensitive match) tables with names: TableName, TABLENAME or tablename etc. |
SELECT col FROM schema.tablename |
CASE_SENSITIVE (ANSI) |
Must match exact stored case (UPPERCASE) | Doesn’t resolve since table name would always be lowercase |
ALTER TABLE t ADD COLUMN NewCol INT |
CASE_INSENSITIVE (Hadoop) |
newcol (lowercased) |
newcol (lowercased) |
ALTER TABLE t ADD COLUMN NewCol INT |
CASE_SENSITIVE (ANSI) |
NEWCOL (uppercased) |
ERROR 4510 (upper-case rejected) |
CREATE ICEBERG TABLE "myTable" ("colName" INT) (quoted mixed-case) |
CASE_INSENSITIVE (Hadoop) |
myTable, colName (quoted identifiers keep casing) |
ERROR 4510 (mixed-case rejected) |
CREATE ICEBERG TABLE "myTable" ("colName" INT) (quoted mixed-case) |
CASE_SENSITIVE (ANSI) |
Stored as myTable, colName (exact quoted case preserved) |
ERROR 4510 (mixed-case chars rejected) |
CREATE ICEBERG TABLE "lowercase" ("col" INT) (quoted lowercase) |
CASE_SENSITIVE (ANSI) |
Stored as lowercase, col (exact case preserved) |
Stored as lowercase, col (SUCCESS - all lowercase) |
The key to avoiding identifier dialect mismatches is consistency:
CASE_INSENSITIVE when your catalog only permits lowercase (Glue, Unity) or when your lakehouse ecosystem is dominated by Hadoop-style conventions. This is the default value for the catalog-linked database.CASE_SENSITIVE when your catalog supports all casings (Polaris) and you want ANSI SQL conventions for consistency with SQL-first environments.This may seem like “just a parameter,” but it’s really a declaration of how Snowflake will interpret and publish names into the shared catalog so other engines can find the same objects.
Defining an explicit identifier contract at the CLD boundary delivers a few practical wins that are tightly coupled to this solution:
At Snowflake, we want to make interoperability simple. To do this, we need to solve not just data storage formats but also identifier resolution to deliver on the lakehouse promise of "write once, query anywhere." Through the CLD’s CATALOG_CASE_SENSITIVITY parameter, Snowflake enables true multi-engine interoperability by giving you explicit control over how identifiers are normalized.
Choose CASE_INSENSITIVE in CLD for Hadoop-convention catalogs (Glue, Unity) to ensure seamless interoperability with Spark and ecosystem tools. Choose CASE_SENSITIVE or CASE_INSENSITIVE in CLD for catalogs like Polaris when you want ANSI SQL conventions or Hadoop compliance, respectively, for consistency with other engines in your lakehouse.
This transforms the lakehouse from a collection of engines with incompatible dialects into a unified data platform where tables created in any engine are immediately accessible to all engines without quoting workarounds or manual metadata synchronization.

