Turbocharging parse_json() in Snowflake: 2x Faster Performance Without Changing a Line of Code

Semi-structured data has become a first-class citizen in modern data platforms, and at Snowflake, parse_json() sits at the heart of how customers ingest, transform and analyze JSON data at scale.
Today, we're excited to share a major milestone: With nearly 200 million queries a day using the JSON parsing functionality, parse_json() is now significantly faster — on average a 2x improvement1 for JSON parsing time in workloads — while maintaining 100% backward compatibility. No query rewrites. No behavior changes. Just faster execution.
This update is now generally available (GA) for all Snowflake customer accounts.
Why parse_json() matters
When parse_json() was first introduced, it was one of Snowflake's earliest built-in functions. At the time, no one anticipated just how heavily it would be used.
Fast forward to today:
- JSON and semi-structured data are everywhere.
parse_json()is executed daily across countless production workloads.- Even small efficiency gains can have massive system-wide impact.
However, that early implementation came with a challenge: Over the years, Snowflake added many Snowflake-specific JSON behaviors that customers came to rely on. These behaviors have subtle differences from today's standard JSON parsing and are deeply embedded in real-world workloads.
The challenge: Performance without breaking anything
Like many long-lived systems, parse_json() accumulated a rich set of edge-case behaviors over time. These behaviors are:
- Heavily relied upon by customer workloads
- Not always aligned with off-the-shelf JSON parsers
- Critical to maintaining long-term query correctness
It is critical to maintain the existing product behavior without impacting customers' workloads. At the same time, customer demand for faster semi-structured data processing continued to grow, making evolution inevitable.
The solution: simdjson with full compatibility
To unlock meaningful performance improvements, Snowflake adopted simdjson, a high-performance JSON parser that leverages SIMD instructions for exceptional speed.
However, using simdjson "out of the box" was not optimal. Snowflake's parse_json() supports a number of behaviors that differ from standard JSON parsing semantics and that customers depend on.
To address this, the new implementation:
- Carefully analyzes all behavioral differences between the existing
parse_json()implementation and simdjson - Applies targeted compatibility for each identified difference
- Preserves all Snowflake-specific parsing semantics
The result is a hybrid implementation that uses simdjson for the fast performance while maintaining 100% backward compatibility.
The results: Faster queries at scale
The impact of this optimization is substantial:
- ~2x faster execution for the
parse_json()portion of queries (on average) - Customers see an average 5.7% latency improvement for queries using parse_json()
For a function this widely used, these improvements offer meaningful performance benefits across a broad range of customer workloads.
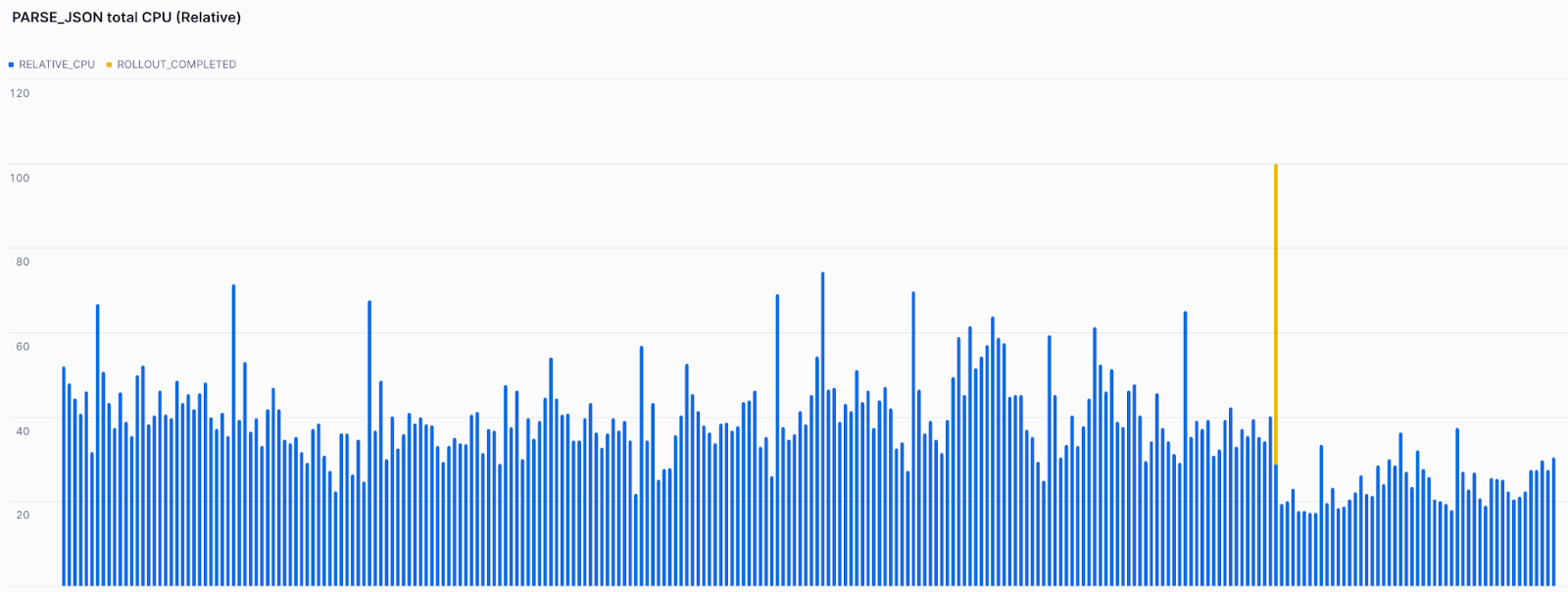
Figure 1 shows production metrics collected during the rollout (from December 2025 - January 2026), highlighting the reduction in CPU usage after the new implementation was deployed. The blue bars show that relative CPU was lower than before the start of the gradual rollout. The yellow bar signifies when the change was enabled on all accounts.
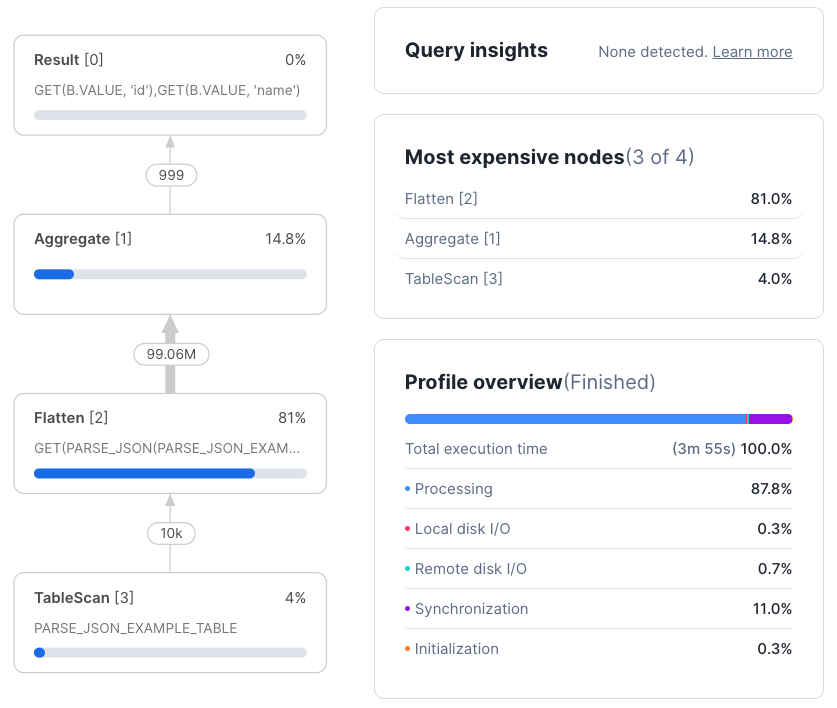
Take, for example, the following sample query:
select distinct flattened.value:id, flattened.value:name
from parse_json_example_table,
lateral flatten(input => parse_json(json_data_raw)) flattened;With optimization enabled (Figure 3), the query finishes significantly faster and spends less time in the Flatten node that the JSON parsing is associated with.
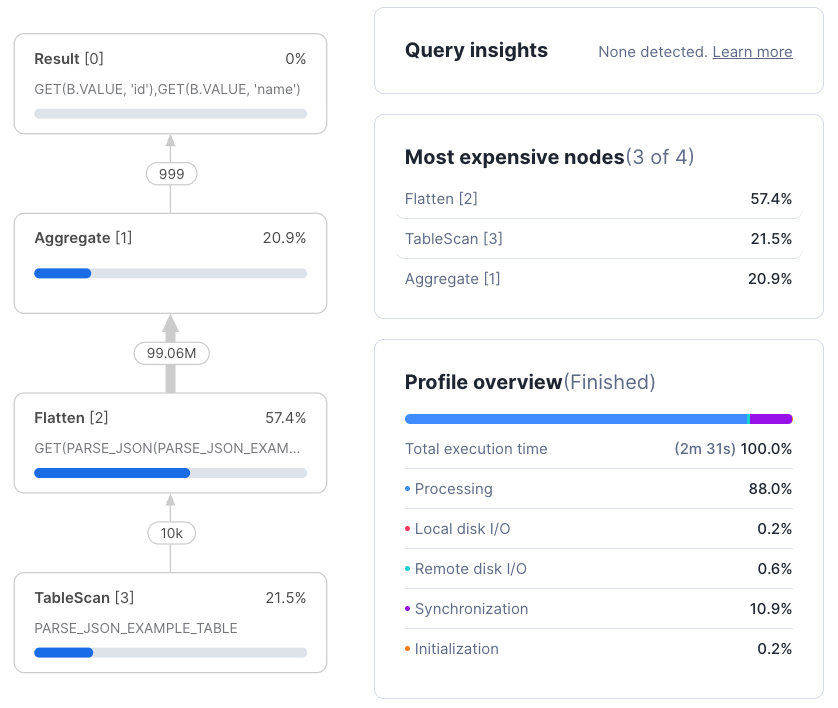
Customers automatically benefit from faster performance without needing to modify queries or workflows.
What this means for customers
- No query changes required.
- No behavior differences to account for.
- Faster JSON parsing by default.
- Improved performance for semi-structured data workloads at scale.
This update reflects Snowflake's ongoing commitment to delivering performance improvements transparently — modernizing internals while preserving reliability and stability.
1 Measured from December 2025 - January 2026, when the feature was rolled out.
Authors

