Scaling Streaming at Snowflake: Introducing Our Next-Gen Snowpipe Streaming Architecture


The data landscape is fundamentally shifting. With the advent of sophisticated AI applications and real-time analytics, the demand for high-volume, low-latency data is no longer a niche requirement — it is business critical. For industries from retail to finance, real-time streaming unlocks the ability to act quickly on insights, whether it’s improving a customer's experience in the moment or taking action before fraudulent transactions complete. Addressing these new demands on streaming data here at Snowflake required more than an incremental improvement to our existing Snowpipe Streaming product; it called for fundamental changes to our architecture to build for the future.
Our next-gen high-performance architecture, now generally available on AWS with support for Azure and GCP coming soon, is the result of that effort. It is a new foundation for streaming ingestion designed to deliver massive throughput, superior cost efficiency and true "ingest to insight" experiences. This new architecture supports up to 10 GB/s throughput per table with data typically available for querying in under 10 seconds. This is all delivered under a new predictable and flat ingest-based pricing model.
In this post, we’ll detail the goals of this new architecture, share initial performance results and explain how it enables organizations to act on data at an unprecedented scale and speed.
Our vision for a streaming-first world
At its core, Snowpipe Streaming is Snowflake’s API for real-time data ingestion, enabling developers to write rows of data directly into Snowflake tables from their applications. This approach provides a powerful, low-latency alternative to traditional file-based ingestion, making data available for analytics in seconds. While this powerful capability was the foundation, our goal for the next generation of streaming was to push the boundaries of performance, cost efficiency and scale. This vision was guided by the following principles:
High-throughput performance: The volume of data being generated and used is growing exponentially. To address this challenge, our new architecture is engineered to support up to 10 GB/s throughput per table, enabling customers to handle their current and future data demands.
Faster time to insight: We define end-to-end latency as the time from ingestion to the moment data is fully queryable and optimized for analytics. While some systems can land data quickly, they often require further processing before data can be used effectively.
Flexibility: The new architecture is built around a high-performance Rust core client-side SDK, which enables multilanguage support, currently in Java and Python. For additional flexibility there is also a direct REST interface to enable Internet of Things integrations and light-weight deployments. These new interfaces provide a consistent, high-performance experience for developers, regardless of their ecosystem.
Infight transformations and pre-clustering: With the new architecture and reliance on the Pipe object, it is now possible to perform simple stateless transformations and pre-cluster data for optimal downstream performance.
Serverless and throughput-based pricing: We believe in transparent and predictable pricing. The new model is both serverless and consumption based, charging 0.0037 credits per uncompressed gigabyte ingested. This moves the cost of ingestion from compute to a simple throughput metric, providing a predictable total cost of ownership (TCO).
Customer validation: How Cboe Global Markets queries 190 billion daily rows in under 30 seconds
During the preview of our new streaming architecture, we partnered with Cboe Global Markets (Cboe). Their engineering team had a requirement to replace a legacy system that relied on proprietary wire protocols and end-of-day batch ETL. The goal was to provide internal teams with near real-time access to market data, requiring both high-ingest throughput and immediate data availability for queries.
Implementation and results
Using the new Snowpipe Streaming Java SDK, Cboe built a pipeline that directly ingests market data into Snowflake. This created a scalable, decoupled architecture that reduced the operational overhead and data latency inherent in their previous batch process.
The production workload achieves the following metrics:
Ingest throughput: The pipeline processes over 100 TB of uncompressed data daily.
Row velocity: The ingestion rate is over 190 billion rows per day.
Low-latency querying on live data: The streaming architecture writes directly to Snowflake's native file format, making data available for query immediately. In conjunction with Snowpipe Streaming's new pre-clustering feature, the ingested data is optimized for querying while inflight. As a result, Cboe's analytics platforms can execute queries against the live dataset and achieve a P95 query latency of under 30 seconds.
Cboe's implementation shows that the new streaming architecture can sustain high-volume ingestion while maintaining low-latency query access on the live dataset.
Architecture deep dive
Our new Snowpipe Streaming architecture is a major evolution in Snowflake’s approach to real-time data ingestion due to its core architecture built around Snowpipe — a mature, first-class Snowflake service that defines the target table and ingestion settings for incoming data. By utilizing Snowpipe under the hood, Snowpipe Streaming taps into years of proven reliability and scalability, providing a robust entry point for data flows and unlocking advanced capabilities not previously possible with our classic architecture. Architecturally, Snowpipe is built to scale ingestion seamlessly from kilobytes to gigabytes per second. It enables inflight data transformations for stateless cleaning and restructuring logic to be applied prior to data landing in the table, which reduces downstream data cleansing, lowers costs and improves query performance.
Designing this new Snowpipe Streaming architecture was also driven by the need to address key challenges faced by customers, notably the high operational costs of client hosting and buffering with our classic architecture. To address this, we implemented a new, highly efficient Buffering Tier, which reduces client-side costs. Server-side buffering also opens up new REST API ingestion endpoints and maximizes the Rust SDK core performance. The Rust SDK core is seamlessly integrated with both Java and Python via a foreign function interface (FFI) layer, which allows developers to leverage the latest ingestion optimizations in familiar languages. This FFI-based approach not only prepares Snowpipe Streaming for the future by making additional language integrations possible but also provides a consistent, high-performance API across different stacks, helping organizations scale their real-time pipelines while keeping infrastructure costs down.
Overall architecture
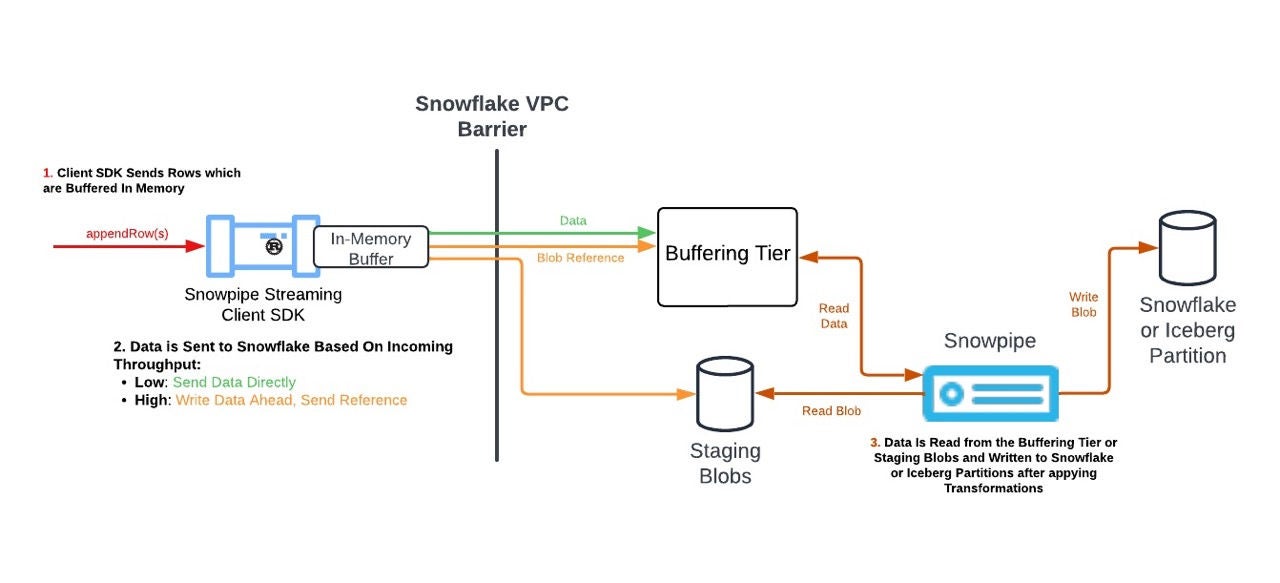
Beginning ingestion: SDK or REST
A customer can begin data ingestion in one of two ways:
By calling appendRows in a Java or Python Client SDK integrated with the highly efficient Rust core. The Rust core can transparently toggle between data transport strategies to offer the lowest-cost and highest-performance ingestion for various throughputs.
By calling a Snowflake hosted REST endpoint to ingest rows of new line-delimited JSON (NDJSON) for situations where SDK usage isn’t feasible (IoT, analytics, etc.) and the volume of data is relatively low (MB/s) per source.
Snowflake recommends using the Client SDK because it can dynamically switch between File Mode and Rowset Mode depending on incoming throughput. File Mode is built for cost-effective high-throughput ingestion but is only supported with SDK ingestion. It uploads encrypted data to an internal stage and sends the file pointer to be buffered server-side in Snowflake, avoiding expensive, cross VPC or AZ traffic. Rowset Mode is built for flexibility and can be used by both the Client SDK and REST endpoints. It is highly efficient for low throughputs by sending data directly in the request payload to be buffered server-side in Snowflake.
Ingress Authentication and Routing
Snowflake’s high-performance server-side architecture begins with the Ingress Authentication and Routing component. It is built around the open source Envoy proxy to provide scalable and reliable load balancing to handle various incoming throughputs.
First, requests from either the SDK or REST endpoints are authenticated with an exchange-scoped token. This token is automatically fetched by the Client SDK when ingestion begins or manually fetched if using the REST endpoints. Valid and authenticated requests are cached to minimize latency for continuous ingestion scenarios.
To protect our customer’s inflight data at rest, the Ingress component also immediately encrypts Rowset Mode data payloads after authentication. Encryption is unnecessary for File Mode because the Client SDK encrypts the data before uploading to the internal stage.
Finally, requests are routed to the Buffering Tier. Here the Ingress component relies on Envoy to dynamically route traffic based on a routing table supplied by the Assigner service. The Assigner service, inspired by the Slicer Auto-Sharding algorithm, uses metrics from Buffering Tier to determine which Buffering Tier pod is available to buffer the request. By separating inflight data storage and routing table computation, Snowflake guarantees seamless scalability to efficiently handle any fluctuation in ingestion throughput.
Buffering Tier
A key improvement to the new high-performance architecture, the Buffering Tier is engineered for efficient and performant data storage. It is made up of two services, a sharded Buffering Service and a Buffer Controller Service.
Each Buffering Service accepts encrypted data (Rowset Mode) or the blob metadata reference (File Mode) from the Ingress component and updates the Assigner service with the current memory usage load. After computation, the Assigner service instructs both the Ingress component and Buffer Controller Service to scale up or down according to the incoming throughput. By dynamically scaling our routing and buffering components, the new high-performance architecture can support higher throughputs when compared to the client-side buffering required in the classic architecture.
Snowpipe warehouse execution
Once data is staged directly or via a blob metadata reference in the Buffering Tier, it is eligible for consumption into a destination Snowflake or Apache Iceberg™ table. Snowpipe periodically checks the Buffering Tier and sees whether there is incoming or outstanding data. Once Snowpipe determines that there is data, it will schedule execution jobs in a serverless fashion to ingest data into the target table based on the Pipe definition. It will compile and schedule jobs based on the throughput rate for channels. That is, Snowpipe may decide to schedule one job to consume data from multiple channels if the throughput per channel is relatively low, or it may decide to schedule one job per channel if the per-channel throughput is relatively high.
These jobs, once scheduled, will pull the blob-referenced data from the Buffering Tier and emit rowsets as extracted from either the data directly or from the blob to downstream operators in the execution plan. Once started, these jobs can run more or less continuously provided that there is outstanding data in the Buffering Tier. Data-related errors are handled by the job, and statistics are emitted about rows or data that could not be ingested into the target table.
The jobs may terminate when there is no more outstanding data in the Buffering Tier or if throughputs across channels change. That is, if throughput increases we may schedule additional jobs, but should throughput decrease then Snowflake may consolidate multiple channels onto a single job and terminate existing jobs. This helps us make optimal use of execution resources and provide low-cost ingestion.
Pre-clustering
A feature introduced in the new Snowpipe Streaming architecture is the ability to “pre-cluster” the data before writing it out to a Snowflake or Iceberg table. For tables with queries on them that take advantage of clustering, this feature is extremely important in order to deliver optimal query performance.
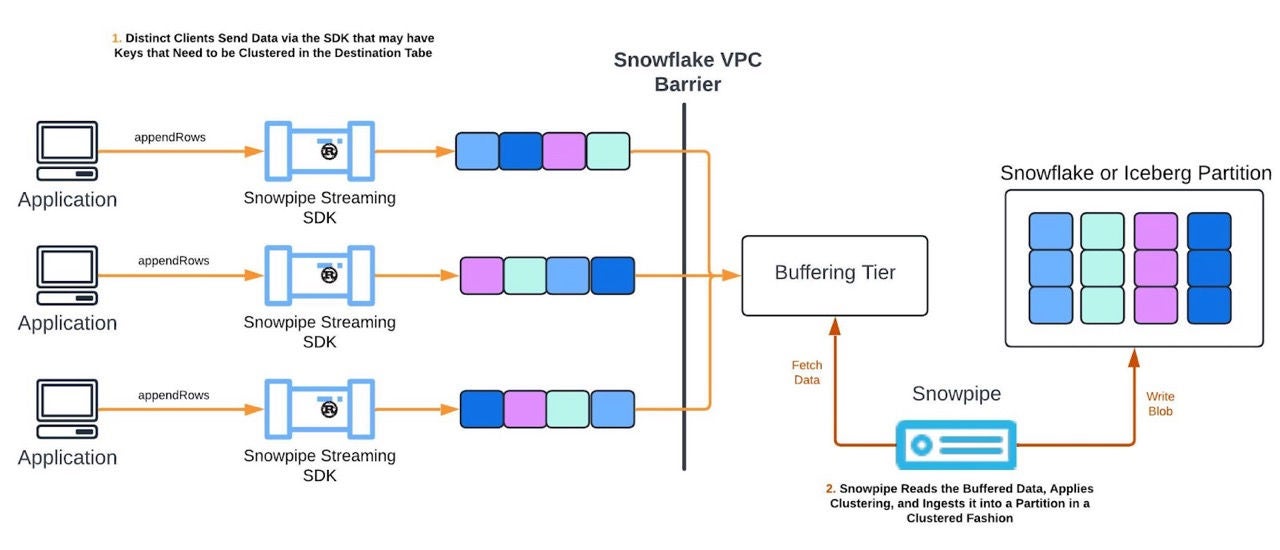
Rather than running an execution job continuously based on the Pipe definition, what Snowpipe will opt to do is wait and periodically schedule “mini” batches of data to be ingested into the table. A batch may consist of multiple channels, and batches can run concurrently across channels if the throughput for a set of channels would exceed a given worker’s processing limits. Batches are determined based on the channel names, that is, a lexicographical sort is applied to the channels based on names in order to provide clustering. Users can take advantage of this to “naturally” cluster data along the channels.
Batching enables more optimally sized partitions to be written that align with the clustering keys such that at query time optimal pruning with respect to the clustering keys will take place. The primary benefit is dramatically faster query performance on the clustered data; however, this feature does introduce some additional ingest latency during the pre-clustering.
Performance and cost efficiency results
From our early preview, customers have successfully validated the ability of our new architecture to meet demanding real-time requirements. Based on this customer testing and our internal benchmarking, we are seeing improvements across the entire data pipeline.
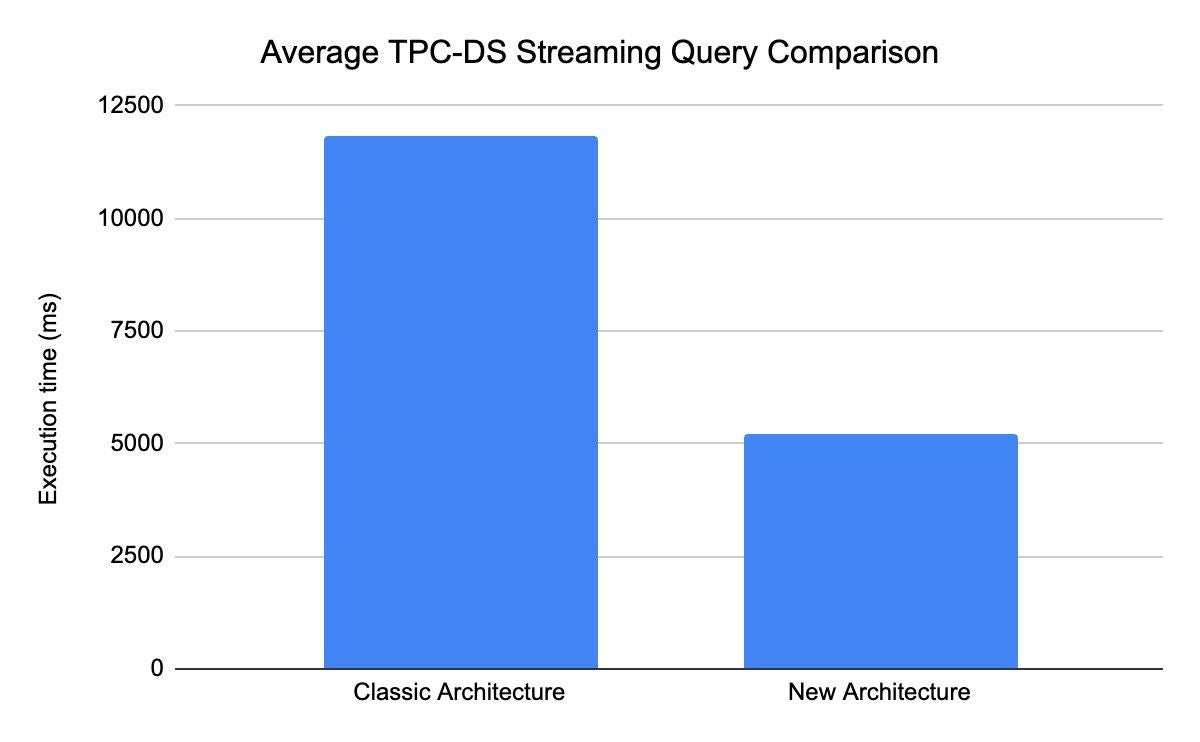
Our recent benchmark tests highlight the performance gains of the new Snowpipe Streaming architecture. When streaming and querying fresh data, utilizing the queries from the TPC-DS test suite, the new architecture completed queries in just 5,212 ms compared to 11,845 ms with Snowpipe Streaming Classic, or a 56% reduction.1
Furthermore, the new architecture significantly reduces the client-side burden. By moving key processes server-side, customers are reporting up to 30% lower client-side resource costs using our new Rust-based SDK.
This all leads to a better TCO. The efficiency gains are threefold:
Lower client costs: Applications use fewer resources to send data.
Predictable ingest pricing: A flat, affordable rate is based on data volume.
Improved query performance: Data is landed in a highly optimized format, reducing the compute costs required to gain insights.
Get started with our next-gen architecture today
Our next-gen architecture for Snowpipe Streaming is generally available for all Snowflake customers in AWS (Azure and GCP coming soon). To get started with the new SDK, check out our documentation and our quickstart guides.
We can't wait to see what you build with our next-gen architecture!
Forward Looking Statements
This article contains forward-looking statements, including about our future product offerings, and are not commitments to deliver any product offerings. Actual results and offerings may differ and are subject to known and unknown risk and uncertainties. See our latest 10-Q for more information.
1 This benchmark report is derived from the TPC-DS benchmark, and as such, its results are unofficial and not validated or certified by the Transaction Processing Performance Council. These results are for informational purposes only and are not comparable to any official TPC-DS results.
