Bringing the Snowflake Platform to Data Lakes

The data management landscape is undergoing a fundamental transformation, shifting from monolithic, proprietary data warehouses to open, interoperable data lakehouse architectures. At the heart of this movement is Apache Iceberg™, which allows organizations to leverage best-of-breed compute engines like Snowflake against a single, governed copy of data.
As organizations adopt an open lakehouse, however, a key engineering challenge emerges: How do you integrate this new, open data stack with your existing data platform? This is not just a state management problem; it's a problem of finding a semantically correct mapping between the data lake model (e.g., catalogs, namespaces, tables) and the warehouse model (e.g., databases, schemas, tables).
When we analyzed how our customers wanted to connect these two models, we found they had two valid, but technically contrasting needs. This post explores how Snowflake addressed this complex semantic-mapping dilemma by building two distinct solutions: a per-table link for tactical use cases and a catalog linked database for strategic use cases to map the full data lake.
The semantic-mapping challenge: Data lake vs. warehouse models
The core engineering challenge stems from two different, perfectly valid design philosophies for data management.
Data lake-native model: Engines in this world (such as Spark) are designed to be stateless. They rely on an external catalog (e.g. Hive Metastore or AWS Glue) as the central "source of truth." The catalog's concept of a "namespace" (or database) is the primary unit of organization. This is ideal for flexibility and a multi-engine strategy but would lack the performance and strong data-consistency guarantees on the warehouse model.
Warehouse-native model: In a traditional data warehouse, the platform is the catalog. The database, schema and table are the source of truth, providing tight integration, governance controls and transactional consistency. When these platforms need to access external data, they typically use the concept of an "external or a federated table."
Another key part of this semantic challenge is the structural mismatch in how data is organized. Data lake catalogs, like Apache Iceberg catalog, can support an arbitrary, nested hierarchy of namespaces. In contrast, traditional data warehouses like Snowflake have a fixed, two-level hierarchy (database → schema). The challenge, therefore, is how to represent a deep, multi-level data lake structure in a flat, two-level warehouse model without losing meaning or scalability.
The "external table" concept, a simple per-table link, was designed for tactical queries. It works perfectly for that, but it lacks scalability and semantic equivalence for an entire "namespace" or "catalog." As a result, organizations that want a deep, scalable integration (e.g., managing thousands of tables) find this model doesn’t scale, forcing them into manual synchronization and complex lifecycle management.
Addressing two distinct customer needs
This difference in design philosophy led us to recognize two distinct user needs, both of which we had to solve:
The tactical need: A data scientist or analyst just wants to link one specific table (e.g., a telemetry data set from Spark) into their existing Snowflake database. They don't want a new database; they want a pointer. They are happily living in the "warehouse model" and just need to augment it.
The strategic need: A data platform team wants to mirror their entire data lake catalog (e.g., thousands of tables in AWS Glue) and have it "just work" in Snowflake. They need a deep, "data lake-native" mapping, where an action in one model has a clear, automatic implication on the other.
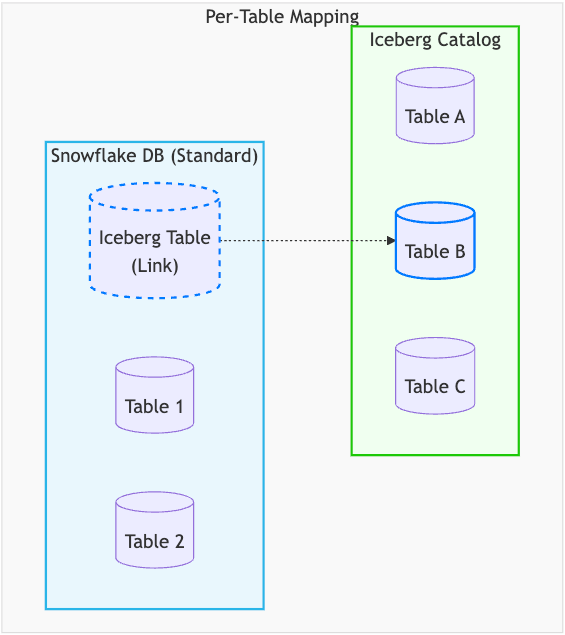
The tactical link (per-table mapping)
For the "tactical need," we embraced the simplicity of the "shallow mapping" model but engineered it to be reliable. This involves creating a Snowflake Iceberg table using the CREATE ICEBERG TABLE statement, which uses parameters like CATALOG and CATALOG_TABLE_NAME to establish a direct, explicit link to a single, preexisting table in an external catalog. This is the perfect fit for the analyst who wants to add a few data lake tables to their existing database.
The key engineering challenge was solved by overlaying Snowflake’s metadata layer on top of the data lake tables. The advantage of this overlay is that it offers superior, cost-effective performance by ingesting the Iceberg table's structure and statistics into Snowflake's metadata system compared to using a query engine directly on iceberg metadata. This allows the optimizer to perform fast query planning and data pruning, just as it would for a native Snowflake table. This "pay once" cost model, where metadata is fetched only during a serverless refresh, eliminates the high-latency I/O and repeated costs of fetching metadata for every single query. This approach also grants platform completeness, making the linked table a first-class citizen that integrates fully with Snowflake's governance capabilities and ecosystem.
The Snowflake table is a link to the external Iceberg table with a serverless polling process that continuously synchronizes the linked object's state, eliminating staleness without requiring a deep semantic integration. This model has a decoupled lifecycle by design which means executing a DROP TABLE in Snowflake only unlinks the object; it doesn't delete the table in the external catalog.
The strategic mirror (catalog-linked database)
For the strategic need, we built a deep semantic mapping solution for large scale, automated federation: the catalog-linked database (CLD). This solution is for the platform team that needs a scalable, automated and semantically equivalent mirror of their data lake.
The CLD is the warehouse-native representation of the external catalog. The engineering feat here is the creation of a bidirectional proxy that semantically equates the two models. A Snowflake SCHEMA is an external NAMESPACE. A Snowflake TABLE is an external TABLE. The semantic equivalence here implies that every action (such as table creation, rename, schema creation/drop, etc.) in the warehouse domain should be unambiguously translatable in the data lake domain and vice versa.
To address the namespace hierarchy mismatch, we implemented a "flattening" strategy. This is controlled by parameters like NAMESPACE_MODE and a NAMESPACE_FLATTEN_DELIMITER while creating the CLD. A Snowflake schema is mapped to a flattened external namespace. For example, if a catalog has a namespace A that contains a nested namespace B, Snowflake will create two schemas, A and A.B, to represent both namespaces. This concept extends to any arbitrary depth.
Because this semantic equivalence is established, state management becomes a radically simpler problem. We built a continuous, bidirectional synchronization engine that handles the full, automated lifecycle. This isn't just a read-only view; it's an active, bidirectional integration with a fully synchronized lifecycle:
Automatic discovery and refresh: New namespaces and tables created externally (e.g., by a Spark job) are automatically discovered and appear as schemas and tables in the CLD. Similarly, changes made to the tables externally are synchronized periodically.
Full schema evolution: Column additions or type changes in the catalog are automatically detected and reflected in the Snowflake table definition.
Bidirectional DDL/DML: A
CREATE TABLEorINSERTwithin the CLD executes the operation against the external catalog, making the table instantly available to other engines, such as Spark. ADROP TABLEin the CLD drops the table from the catalog, and vice versa. This synchronized lifecycle is the key differentiator.
This "deep semantic mapping" addresses the scalability problem by eliminating manual intervention and helping ensure the two models are continuously kept in sync.
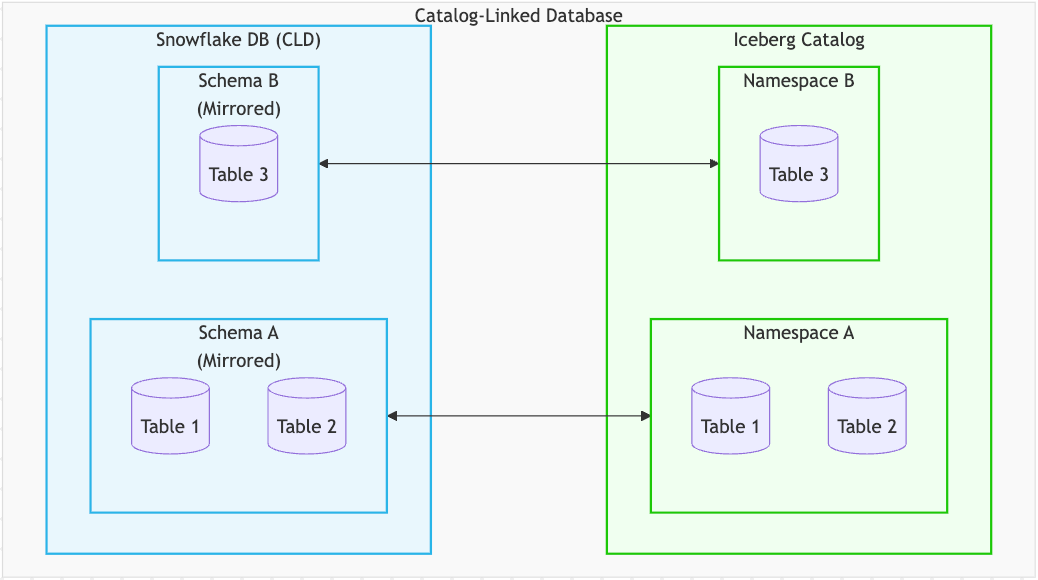
Table: Per-table mapping vs. catalog-linked database
| Feature | Per-table mapping (standard database) | Catalog-linked database (CLD) |
|---|---|---|
| Integration unit | Individual external table | Entire catalog with namespace-level sub scoping |
| Supported catalogs | OBJECT_STORE, GLUE, ICEBERG_REST (Polaris, AWS Glue, Unity, etc.) |
ICEBERG_REST (Polaris, AWS Glue, Unity etc.) |
| Setup model | Imperative: CREATE ICEBERG TABLE for each table |
Declarative: CREATE DATABASE once to link all tables across namespace(s). |
| Lifecycle management | Decoupled: DROP TABLE in Snowflake only unlinks. Any new table creation is link-only and table renaming in the remote catalog is not reflected in Snowflake. |
Synchronized: DROP TABLE in Snowflake drops from the catalog. External changes (create, drop, rename) are automatically propagated. |
| Scalability | Low. Best for a small, static number of tables. Operationally intensive at scale. | High. Designed for managing hundreds or thousands of tables automatically. |
| Metadata sync | Per-table, enabled via AUTO_REFRESH = TRUE. |
Database-level, continuous polling based on SYNC_INTERVAL_SECONDS for automatic schema/table discovery and REFRESH_INTERVAL_SECONDS for table-level metadata refresh. |
Conclusion
By building two distinct but complementary models, a simple link-based model for tactical needs and a deep semantic proxy for strategic scale, we created a flexible platform that meets users where they are. This addresses the mapping dilemma, providing a simple entry point for analysts and a powerful, automated and semantically correct solution for platform teams. This approach frees data engineers from manually managing metadata drift and allows them to build a reliable, single source of truth that serves all users, from tactical data science to strategic, platform-wide analytics.
Author
