Data Vault Techniques on Snowflake: Conditional Multi-Table INSERT, and Where to Use It


Snowflake continues to set the standard for data in the cloud by removing the need to perform maintenance tasks on your data platform, and giving you the freedom to choose your data model methodology for the cloud. In today’s blog post we will explore the appropriate place to use a conditional multi-table INSERT for your Data Vault, and where not to use it.
This post is number 6 in our “Data Vault Techniques on Snowflake” series:
- Immutable Store, Virtual End Dates
- Snowsight Dashboards for Data Vault
- Point-in-Time Constructs and Join Trees
- Querying Really Big Satellite Tables
- Streams and Tasks on Views
- Conditional Multi-Table INSERT, and Where to Use It
- Row Access Policies + Multi-Tenancy
- Hub Locking on Snowflake
- Virtual Warehouses and Charge Back
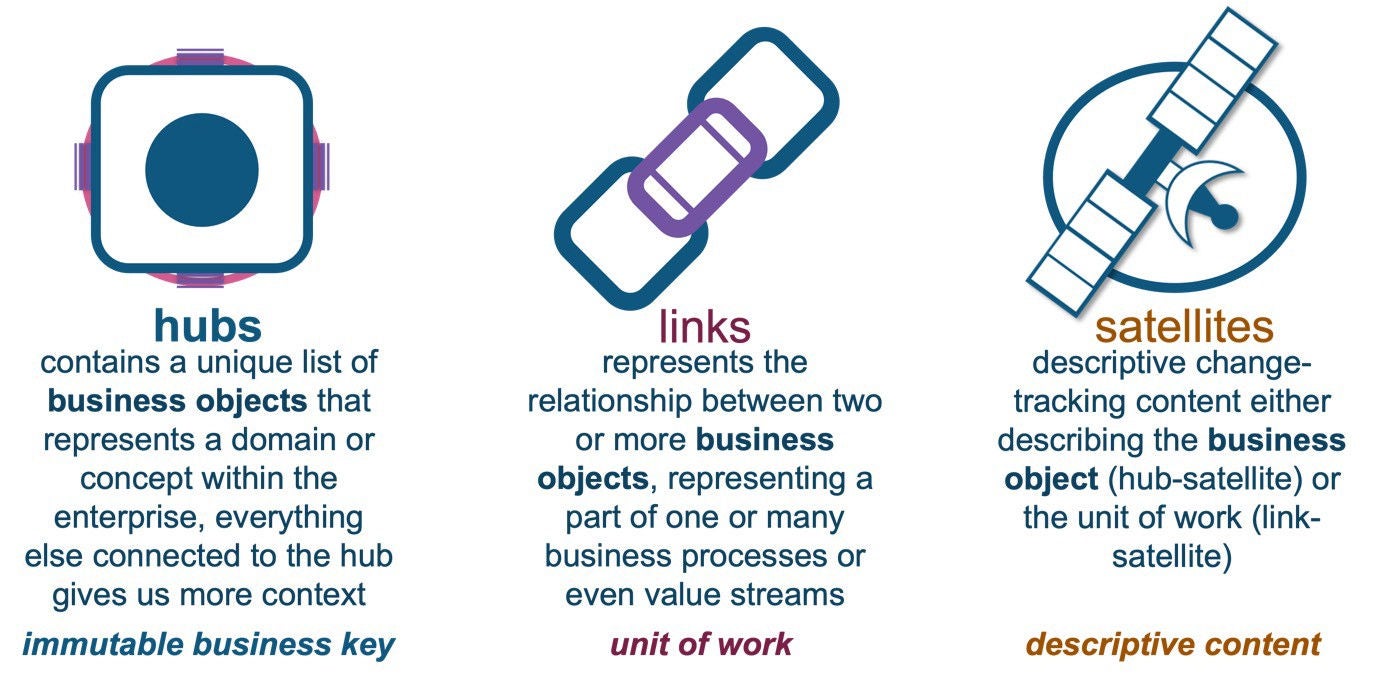
A reminder of the data vault table types:
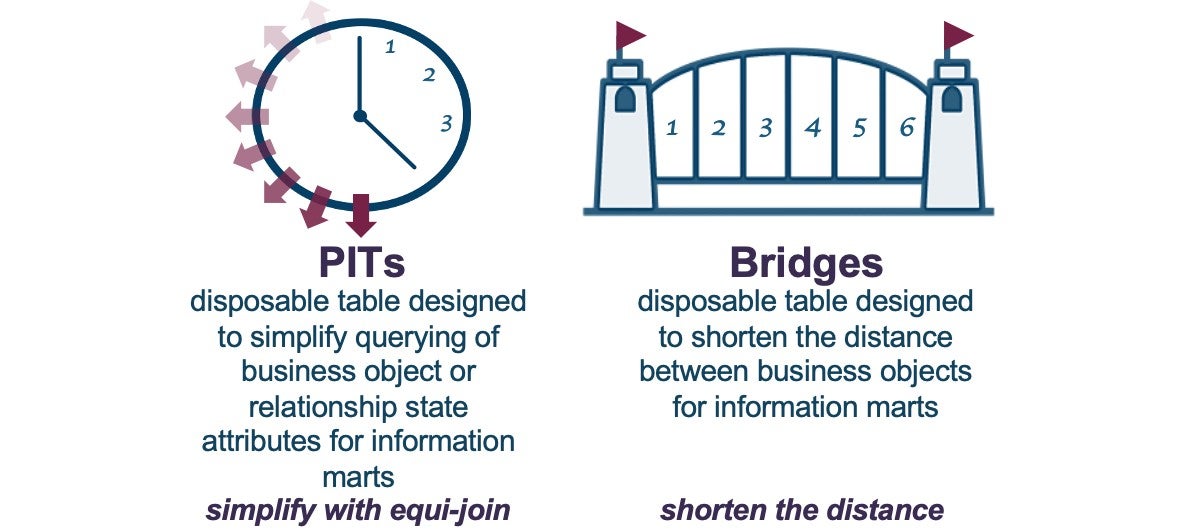
We will again be using the PIT query assistance table in our Data Vault implementation.
Snowflake’s SQL multi-table INSERT allows you to insert data into multiple target tables in a single SQL statement, in parallel with a single data source. The SQL conditional multi-table insert extends that capability by allowing for WHEN conditions to be configured for each of the target tables based on the content of the source data. Think of it like a CASE...WHEN condition you’d see in an SQL SELECT statement that executes IF…THEN…ELSE logic, except in this case ☺ the conditional output is defining the target table to send data content to.
Let’s see what that looks like:

from Snowflake docs, see bit.ly/3h97Ypz
In a Data Vault context there is a smart way to use the conditional multi-table INSERT and make it completely business-driven. I’ll show you what I mean shortly, but first …
Where it should not be used
As data lands in the data platform’s landing zone, the content is staged by applying hard rules such as trimming columns and ensuring that timestamps align. Data Vault staging will also add Data Vault tag columns such as the following:
- Surrogate hash keys: Destined to be loaded to hub tables as hub-hash-keys, and if a relationship in the data exists, will also be destined to be loaded to link tables as link-hash-keys.
- Record source: Denoting where the record came from.
- Load date timestamp: For when the data is loaded into Data Vault.
- Applied date: The date of the business event as it occurred in the source, essentially the extract date.
- Record hash, or HashDiffs: Record digest; from a single source there could be one or many HashDiffs depending on the satellite split.
In the scenario illustrated below, it might be tempting to use this staged content as a base for a multi-table insert.
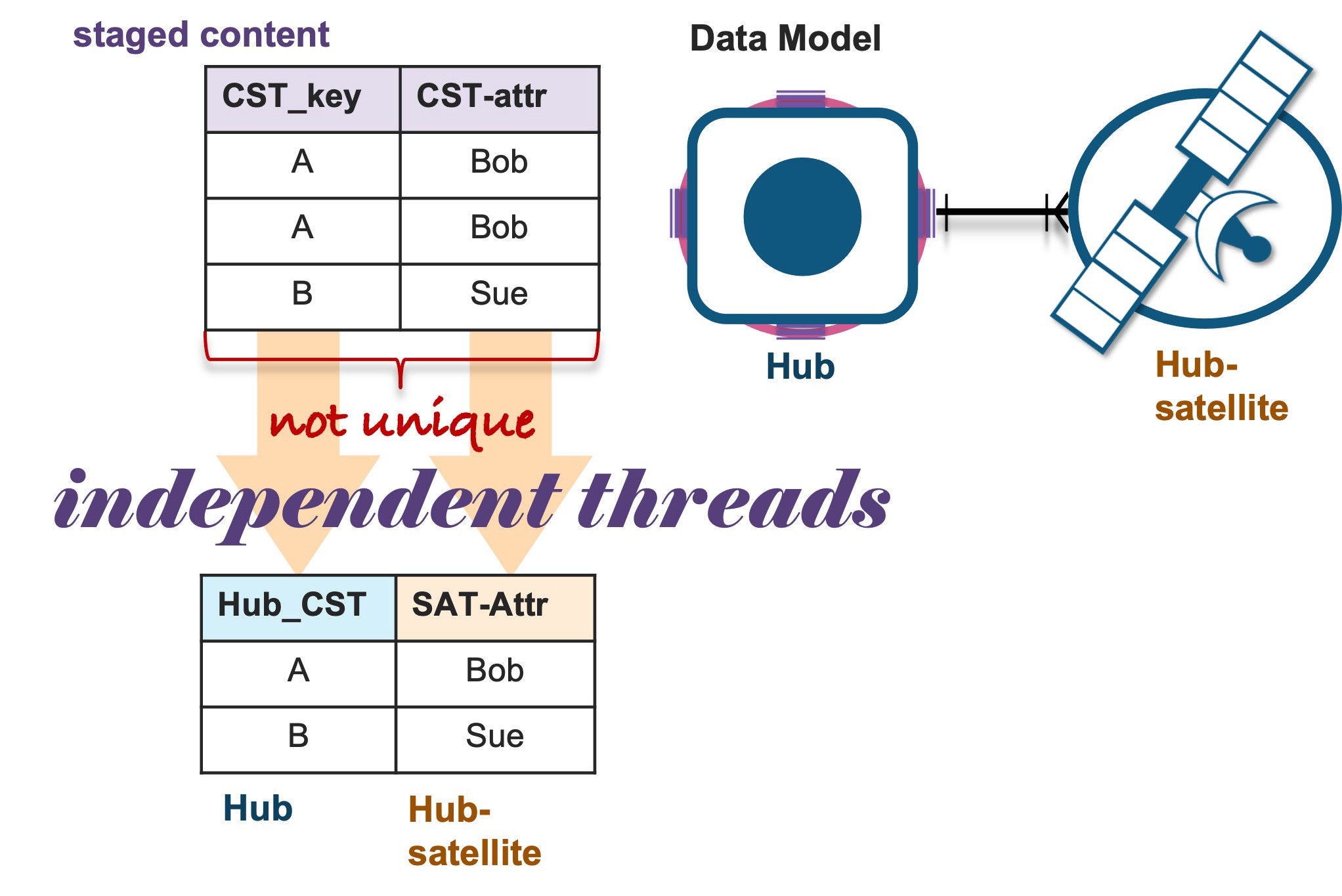
A simple model, a business object, and its descriptive attributes. (Table names and content have been simplified for clarity.)
SELECT DISTINCT will eliminate duplicates in the staged content and the Data Vault model integrity remains valid. In reality, however, data does not arrive in such perfect harmony. Source-system data is profiled and will be mapped to hub, link, and satellite tables but what if we have modeled the following scenario:
- A “same-as” link table that essentially references the same hub in the model; and
- Defined satellite splitting to ensure the right attributes are allocated to the right entity from a single load.
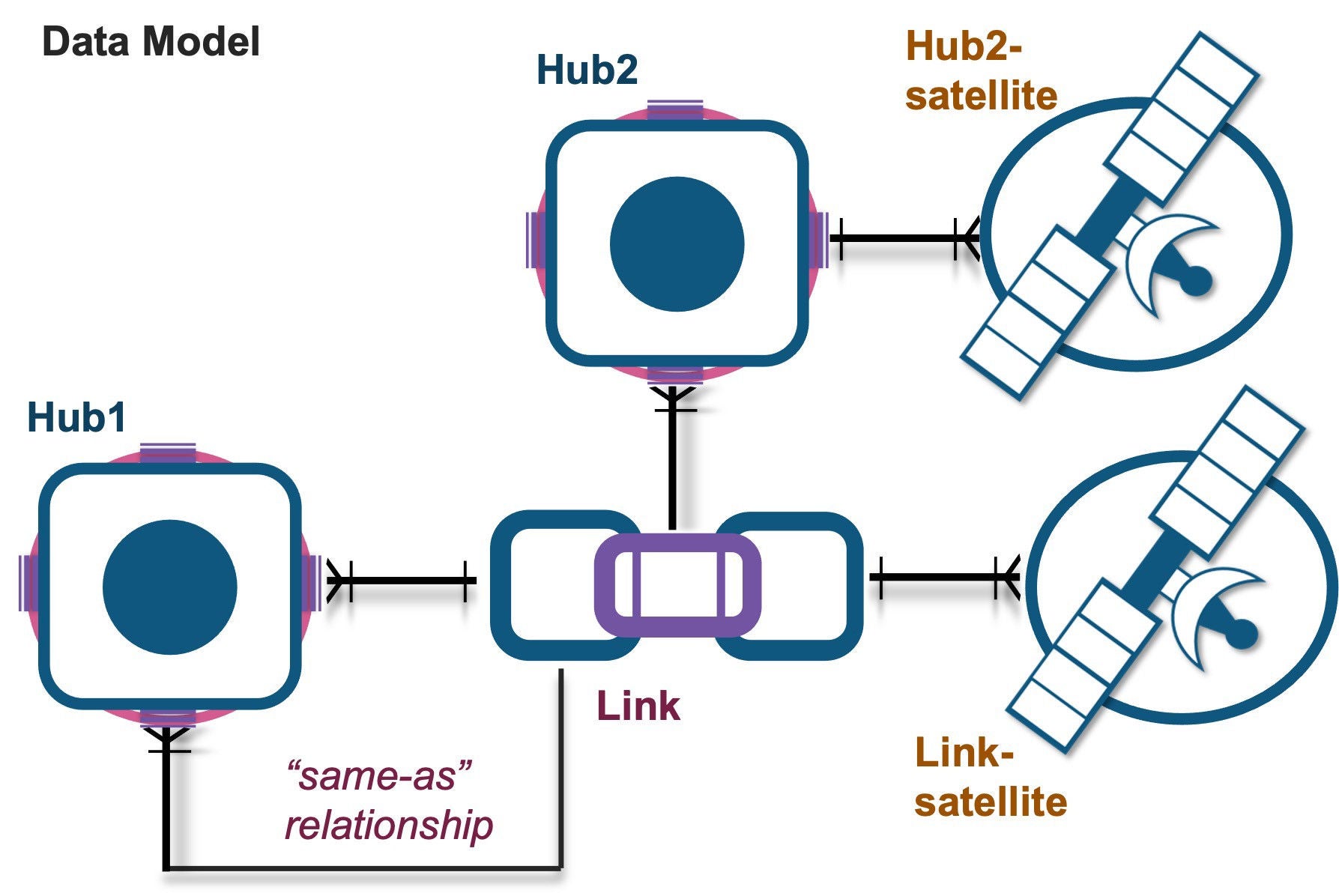
A more realistic model, what does it mean for a multi-table INSERT?
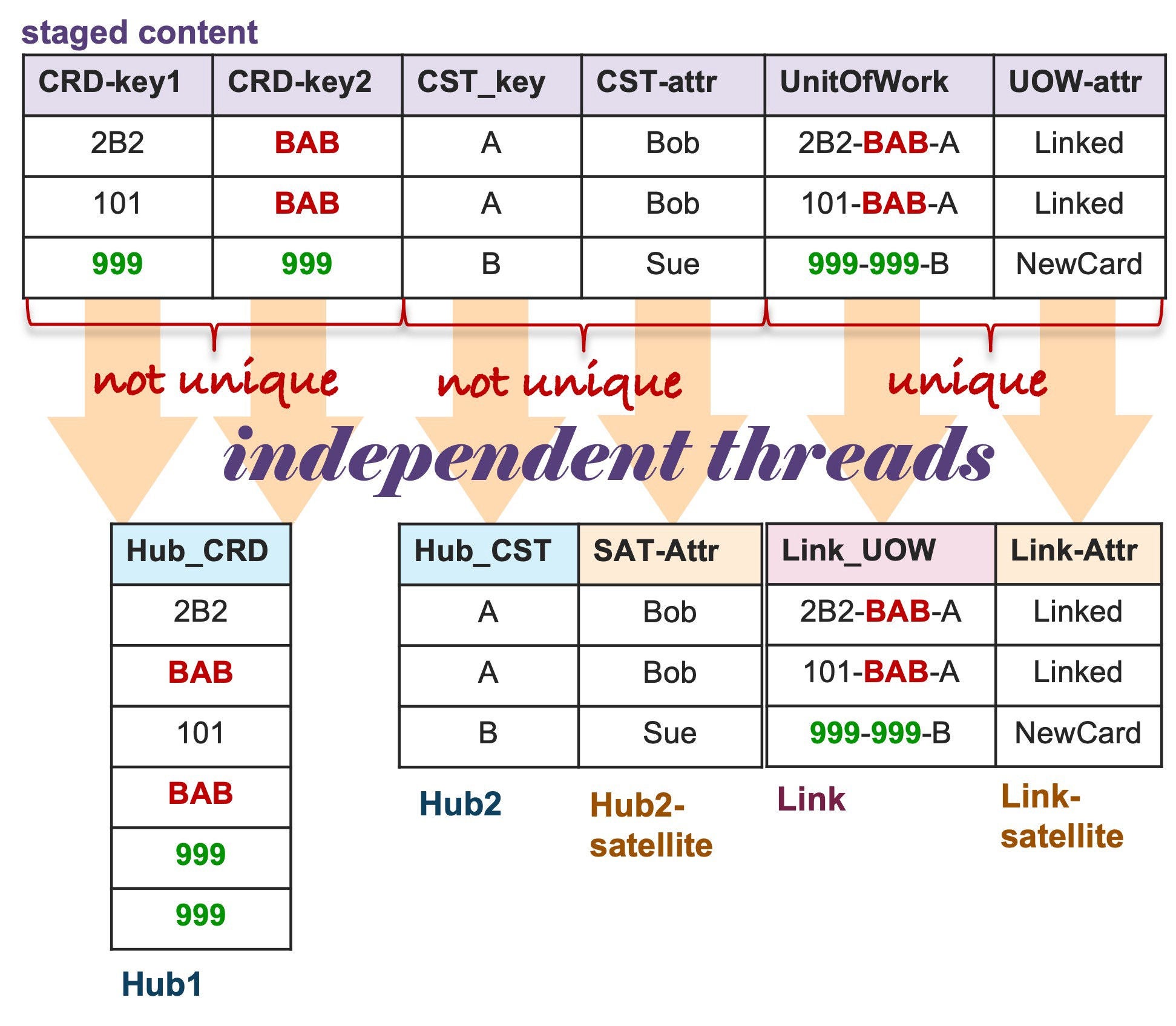
Multi-table INSERT will lead to model integrity issues.
Integrity is lost! Why did it happen?
There are essentially two problems with using a multi-table INSERT to highlight here:
1. Record condensing
Data is profiled and modeled to a specific target table grain. Our example identified a relationship between two key columns that represent a linking of cards, and since both are essentially card numbers, they will be loaded to the same hub: hub_account (Hub1). A third relationship exists and that is with the customer—those keys are loaded to hub_customer (Hub2). We also applied some satellite splitting because not all the content is about the related cards. Since this is coming from a single staged file, the content used as a base for a multi-table INSERT statement must use a single SELECT statement over this data. A single SELECT DISTINCT does not distinguish which portions of the same file to apply this rule to; it applies to all card numbers in the relationship in that staged content and therefore why the hub-satellite content is not deduped.
2. Multi-table INSERT threads are executed in parallel
This means if we were loading to the same hub table at the same time, each thread executing the same load condition is not aware of the other thread’s execution condition, even if it’s coming from the same SQL statement.
Remember, Snowflake uses a READ COMMITTED transaction isolation level, and therefore an INSERT statement does not lock the target table for inserts, and each executing thread will see the table without the other thread’s uncommitted statements. In other words, the parallel execution of the multiple threads in a multi-table INSERT sees the same target table state, with each thread unaware that another thread is attempting to load to the same target table with the same load conditions, and with potentially overlapping content.
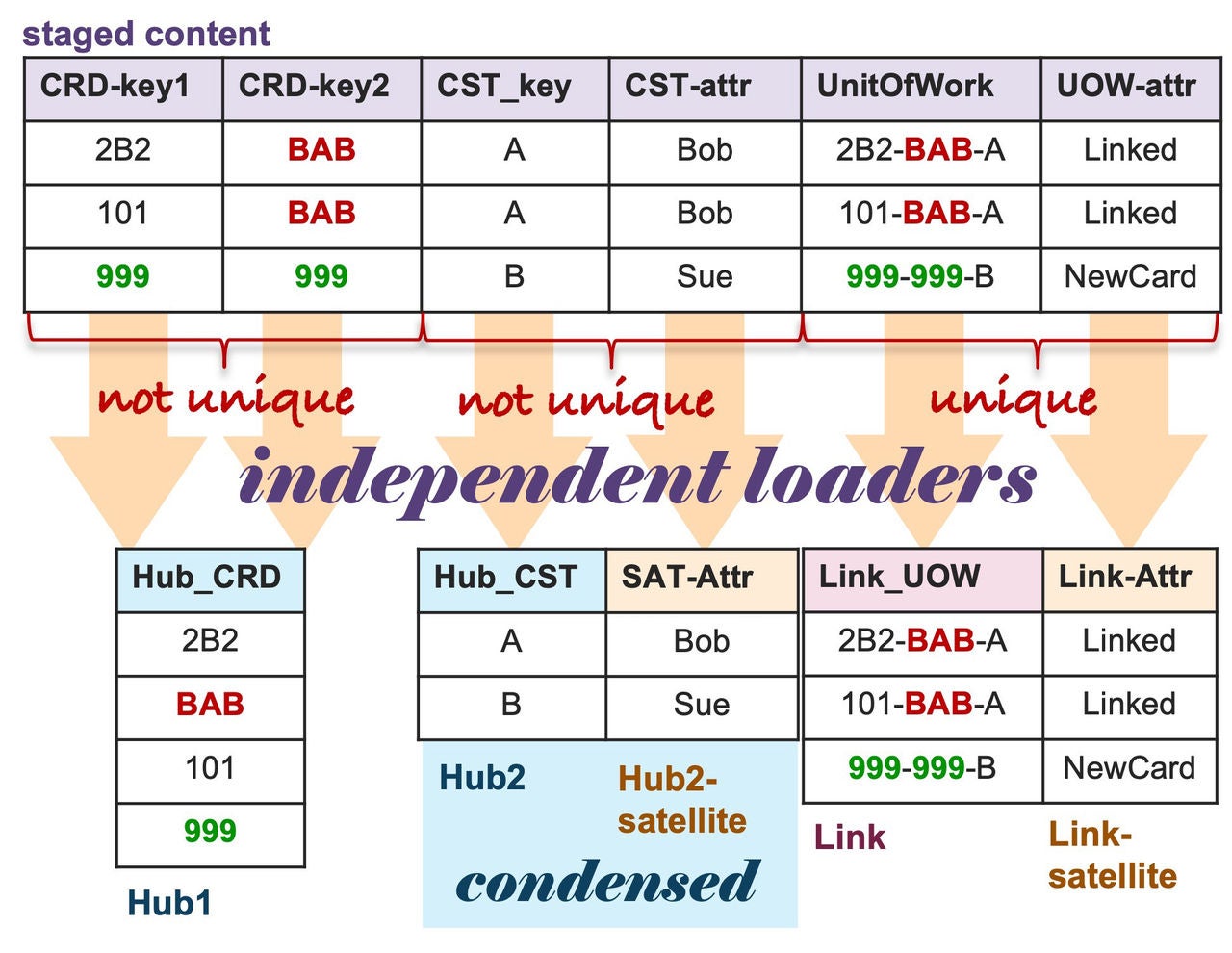
Independent configured hub, link and sat loaders.
READ COMMITTED transaction isolation is excellent for keeping the platform scalable and allowing for the extreme levels of concurrency on Snowflake. This ensures you are not risking object locking and possible race conditions. In a future blog post we will discuss how to lock tables on Snowflake, and where it’s most applicable.
You could imagine that the above scenarios could be coded for using multi-table INSERTS, and you could design and build a conditional ingestion pattern (e.g., if you encounter this modeling scenario, then use Pattern A rather than Pattern B, and so on). But this code suite will become monolithic and tedious to maintain. Just how many scenarios would you have to consider?
The essence of an architecture approach that uses repeatable patterns does not have such switch conditions to load the same table type. Rather, there should be only one way to load a hub, a link, or a satellite table, and the automation of these patterns reuses those simple building blocks through parameterization to deploy this as an idempotent technique, such as service-oriented architecture. No matter the Data Vault model, you simply configure the hub, link, and satellite loaders as such.
So where can we use multi-table INSERTS? Well …
Where you could use it
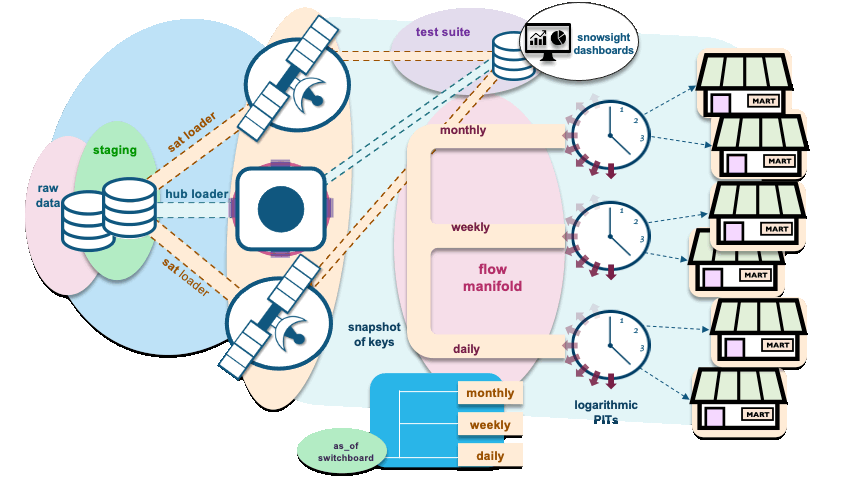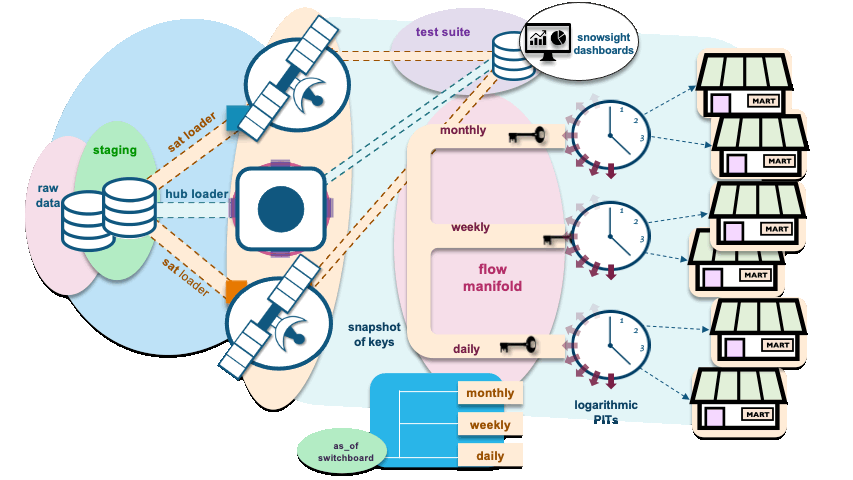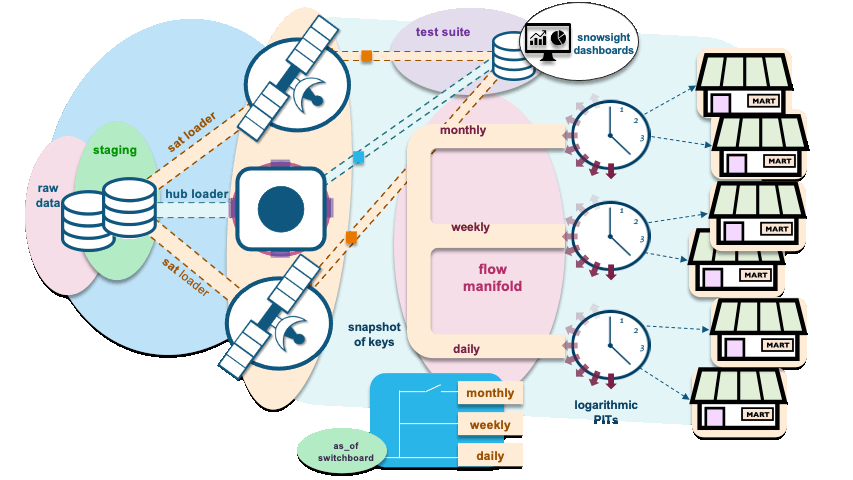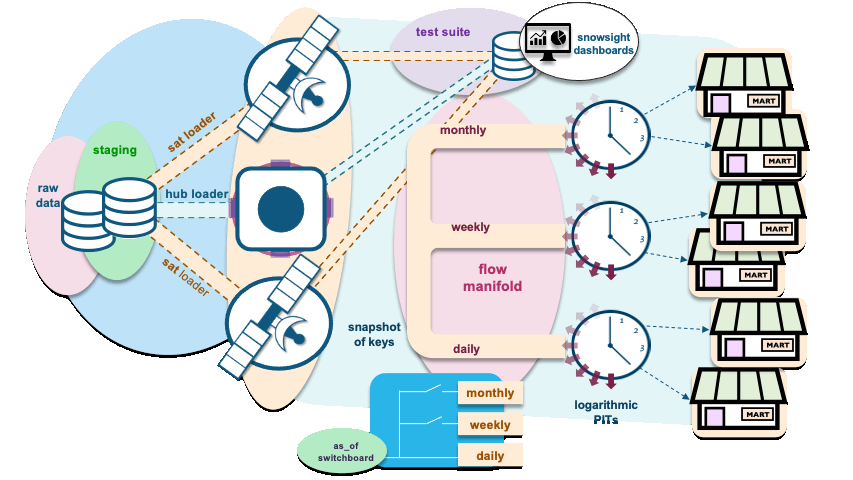
Let’s discuss the components of the architecture illustrated above:
as_of switchboard is the date dimension table used as a base to set PIT windows (start and end dates). In addition to the regular columns, you’ll find in a date dimension this table will also include columns used as flags to denote whether a date or timestamp used in the window falls on a specific reporting timestamp: daily, weekly, monthly, and so on.
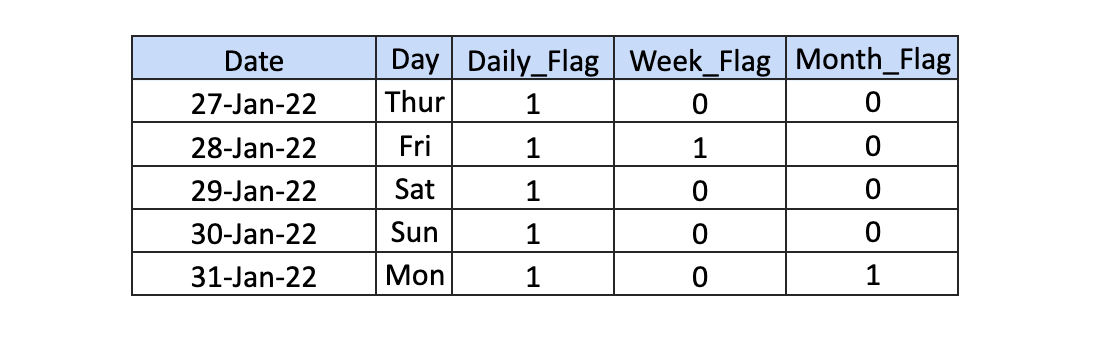
The data model in the above animation contains a hub and two satellite tables, and data is constantly being loaded to those tables using independent and parameterized hub and sat-loaders, respectively. The loaders are executed in parallel. PIT flow manifold, on the other hand, can be executed in one of two ways:
- As PIT table rebuilds: In this case, a window is selected as a time period for reporting. If we were loading for a period window from 1 Jan 22 to 30 Jun 22, and when parsed through the manifold the as_of table’s flags control, the flow of surrogate hash keys and load dates will be directed toward the logarithmic PIT table constructs.
For the scenario above, let’s give a simple example without showing table growth. Each satellite gets 1,000 records a day and only deltas are loaded, so if we attempted to load 1,000 records a day for the month of January, we will likely have less than 31,000 records in the satellite but 31,000 recorded keys and load dates in the PIT-daily table. Here’s a summary for each PIT table:
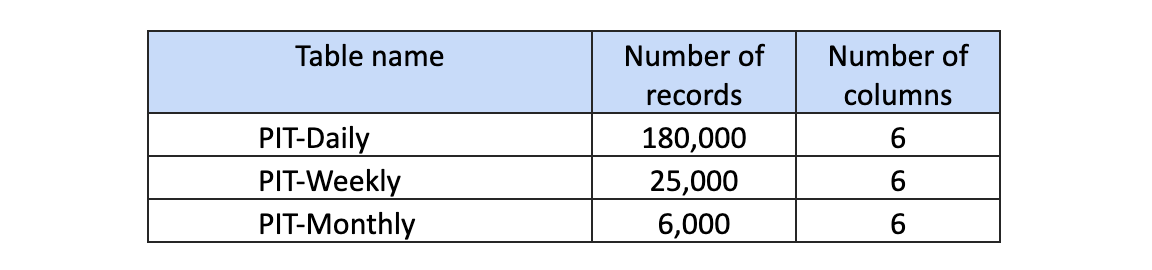
Remember, satellite tables only load changes to the previous current state, so if for a consecutive day the record state hasn’t changed, then that record is not loaded.
- As a part of the data pipeline: Yes, you could be running the flow through the PIT flow manifold daily and incrementally publish keys and load dates to the logarithmic PIT tables. The PIT window in this case is the single date this publishing of keys and load dates is run on. If the number of hub business keys remains consistent as they do in the above example, then you will expect the same record count as the above table. If the hub tables are growing (as they should in a prospering business), then the record counts will differ between this pipeline PITs and rebuilt PITs.
In both implementation types the code is identical—the variance is only in the selection of a PIT-window.
How do we make this business-driven? Deploying the switchboard as a reference table controlled by reporting needs of the business. The code for the PIT flow manifold is deployed once and it sends keys and load dates to the target PIT tables controlled by the switchboard. The animation above was purely for illustration, but essentially you can design the as_of switchboard table to include switches for:
- U.S. financial year-end, U.K. financial year-end
- Business daily (Monday-Friday) instead of just daily (Monday-Sunday)
- First business day of the week
- Last business day of week
Observe…
insert all
when (first_business_day_of_week=1) then into PIT_1BDW
(…PIT Columns…)
values(…PIT Columns…)
when (quarter_end_day=1) into PIT_QE
(…PIT Columns…)
values(…PIT Columns…)
when (last_business_day_of_week=1) then into PIT_LBDW
(…PIT Columns…)
values(…PIT Columns…)
with as_of as (
select *
from rawvault.as_of_date aof
where as_of=to_timestamp($my_loaddate)
)
…PIT Code…
;
my_loaddate is the PIT Window, each PIT output is logarithmic.
For PIT table rebuilds, change the PIT window to a start and end date.
Query assistance tables (PITs and Bridges) are disposable and only used to store keys and very light derived content—content that does not need to be stored permanently because the metrics used for this calculation are stored in both the raw and business vault of the Data Vault. Because these constructs use inherent data platform techniques to boost query performance and simplify table join, the information marts are intended to be deployed as views. Multi-table INSERTS is just another technique we can use in Snowflake to simplify our Data Vault deployment even further.
Other performance tips:
- Hash key and HashDiff column generation should be done in one place, and that is in staging. Do not perform hashing in the Data Vault table loaders (hub, link, and satellite). By performing the hashing in staging, the hash keys and HashDiffs are simply used and carried in the loaders and query assistance table builders.
- To generate the hash key and HashDiff column, values do not use functions intended to concatenate semi-structured table data (example array_construct or object_construct). These functions will perform slower than the concat function that is intended to be used with structured table columns. For performance results, click here.
- Store hash columns as binary data type. They will use half the storage footprint if you were to store them as varchar columns, and they will perform better in SQL joins.
- Include untreated business keys in satellite tables. This eliminates the need to perform an SQL join to a hub table to fetch the treated business key(s). Learn more about business key treatments here.
- Do not bring hash-keys into the information marts—they serve no purpose to the business user.
- Consider satellite splitting when designing your raw vault satellites. This will eliminate the need to denormalize the content further downstream and will save you credits at query time.
- Business keys are always of data type varchar. This eliminates any need to refactor should another source provide a business key to the same hub table that is of a different data type.
- Raw vault reflects raw data. Do not conform the column and table names in raw vault or this will lead to rework and refactoring when source schema drifts.