



Blog
Supercharging Scikit-Learn and Pandas in Snowflake with GPUs
Learn how to accelerate model development cycles for scikit-learn, pandas, UMAP and HDBSCAN with GPUs — no code changes required.
Go from data to predictive insights faster with Snowflake CoCo. Build production-ready ML pipelines using natural language — right where your governed data lives.

Overview
Accelerate the model lifecycle with automated ML pipelines from Snowflake CoCo. Drive predictive insights tailored to your business with native context across your data, features, models and notebooks — all on a unified, governed platform.

Unify workflows across development, inference and ops where your data already lives.

Discover, manage and govern features and models in Snowflake across the entire lifecycle with centralized lineage and role-based access control (RBAC).



ML Workflow
Model Development
Optimize data loading and accelerate training from Snowflake Notebooks or directly from VS Code using Snowflake’s VS Code Extension or through Cursor.†
Use pre-installed libraries such as XGBoost and PyTorch, or pip install from open source hubs such as PyPI and Hugging Face.
Customize and train open-weight foundation models with Cortex Training.*

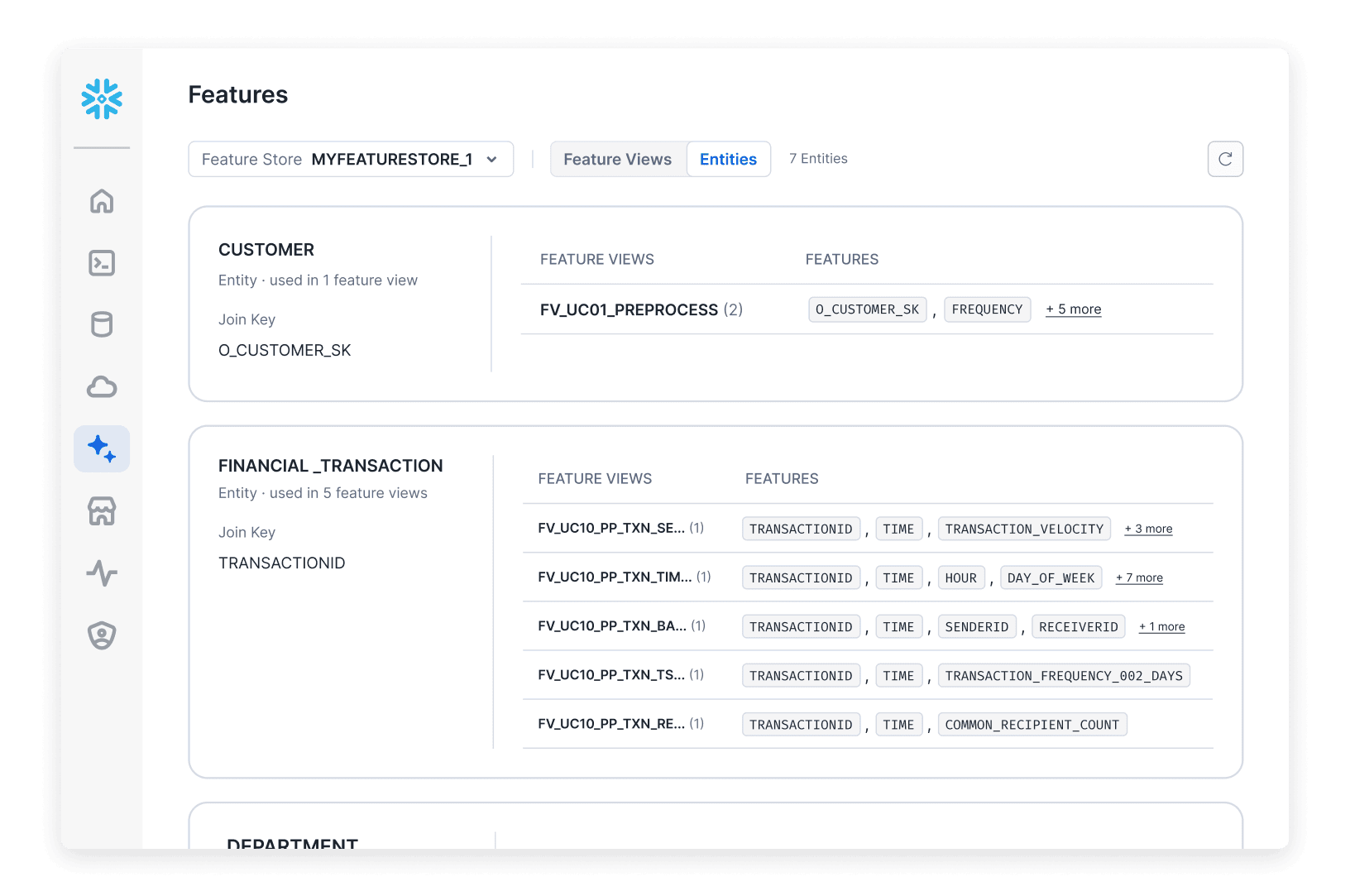
Feature Management
Create, manage and serve ML features with continuous, automated refresh on batch or streaming data in under 10 milliseconds using the Snowflake Feature Store, with benchmarks showing 2.5x lower latency and 7x higher queries per second.
Promote discoverability, reuse and governance features across training and inference.
Easily search for and visually trace features across the pipeline via the integrated Feature Store UI.
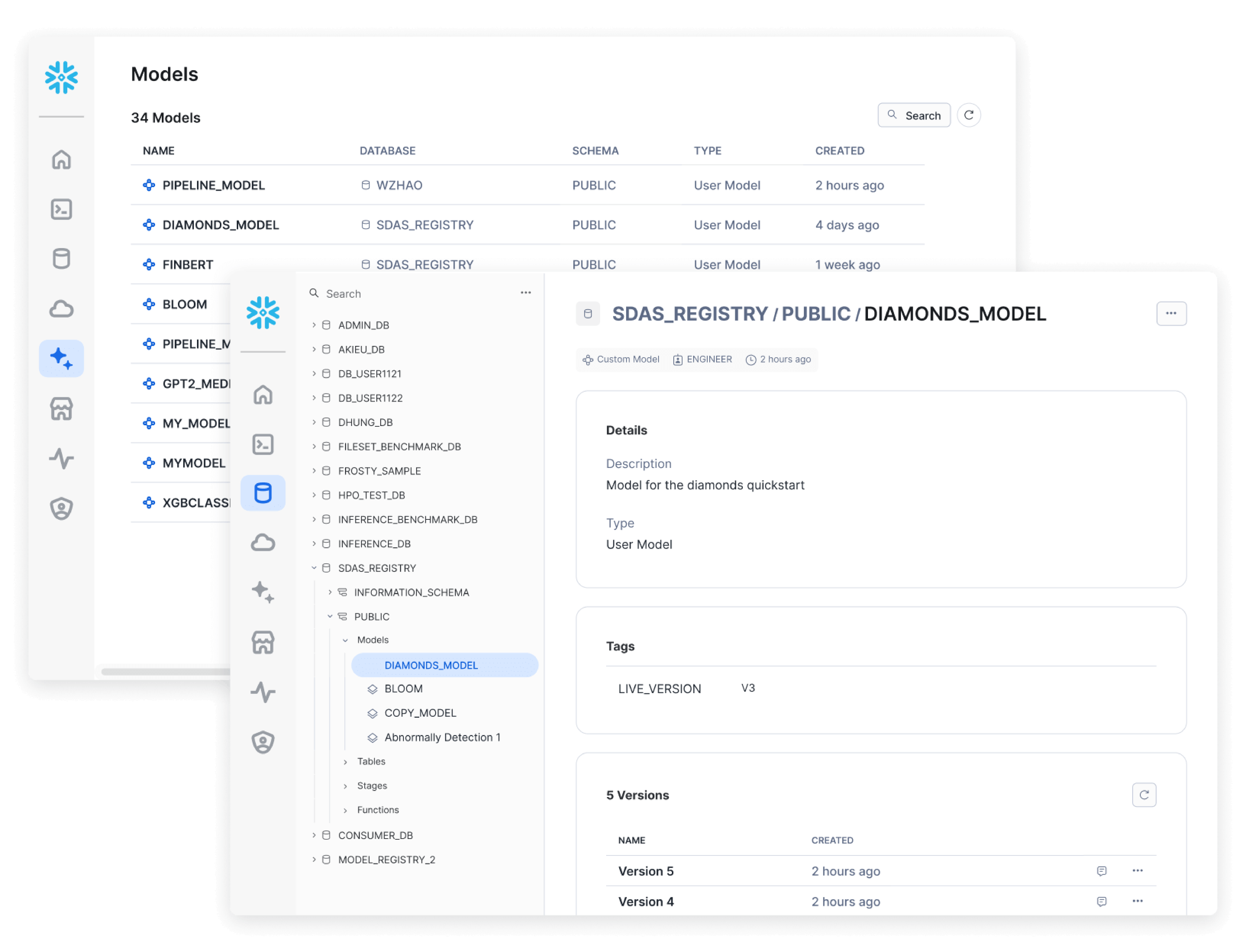
Model Management
Log models built on any platform in Snowflake Model Registry and serve for batch or real-time predictions on Snowflake data with CPUs or GPUs.
Power low-latency online use cases such as customer lifetime value and fraud detection with sub-100ms model serving benchmark results up to 10x faster than alternative platforms.
Easily monitor performance and drift metrics with integrated ML Observability.
"Previously, the process to train all these models and generate predictions took a half hour. The unified model on Snowflake is super quick; we’re talking minutes to generate forecasts for hundreds of thousands of customers. This speed and simplicity will help unlock additional capabilities for the business like simulation and scenario forecasting.”
Dan Shah
Manager of Data Science


“Having everything unified within Snowflake ML, working seamlessly without needing to think about security or governance, is such a productivity enabler.”
Tuhin Ghosh
Head of Data Science for the Platform Product Group at Coinbase

Learn more about the integrated features for development
and production in Snowflake ML.
Get Started
End-to-end ML
Have questions about Snowflake ML? We've got answers. Here are some of the most common questions to help you understand how it works and how you can get started.
Yes, data scientists and ML engineers can build and deploy models with distributed processing in CPUs or GPUs. This is enabled by the underlying Ray-based modern container infrastructure that powers the Snowflake ML platform.
Yes, Snowflake ML handles both online and batch workloads. For real-time needs, our online feature store and online model inference are generally available to power use cases including personalized recommendations, fraud detection, pricing optimization and anomaly detection.
No, you can bring models built anywhere externally to run in production on Snowflake data. During inference, you can take advantage of integrated MLOps features such as ML observability and RBAC governance.
Yes, Snowflake ML is fully compatible with any open source library. Securely access open source repositories via pip and bring in any model from hubs such as Hugging Face.
Snowflake operates on a consumption-based pricing model. Explore the latest credit pricing table.
Yes, you can try any of our ML quickstarts directly from the trial experience.




