Data Engineering
Build reliable, continuous data pipelines for the enterprise in the language of your choice.
Product
Accelerate time to data and AI innovation on a fully managed, enterprise-ready platform that is easy to use, connected across your entire data and AI estate, and trusted by thousands.
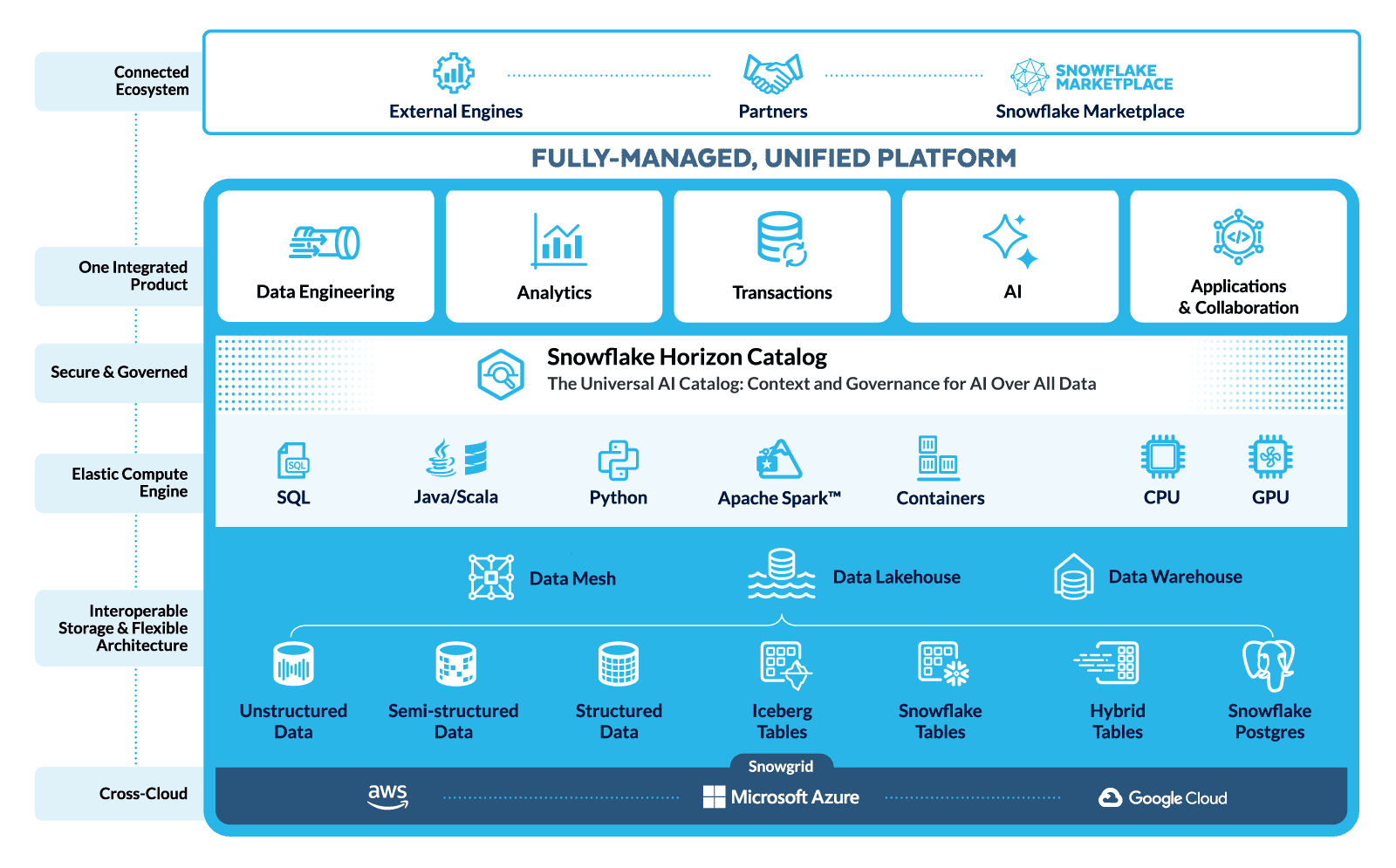


Remove the complexity of managing infrastructure with a single, fully managed data and AI platform.

Work across clouds and regions with an open, interoperable ecosystem of third-party data and AI-ready apps.
Protect critical workloads with built-in governance, security and compliance — including proven business continuity and disaster recovery controls.
use cases
Maintain trust
Effectively protect your most sensitive data and AI assets with enterprise-grade security and governance.
Manage secure, cross-engine access to data in open table formats and get read/write access for all Iceberg tables.
Provide context to AI agents for useful, trustworthy output.
Connect ecosystems across regions and clouds with unified manageability, business continuity and disaster recovery, and seamless collaboration.
Manage cost and performance

Monitor, troubleshoot and debug

Innovate with warehouses and container services
Experience 2.0x¶ faster performance for core analytics workloads with Standard Warehouse - Generation 2, Snowflake’s updated Standard Warehouse with upgraded hardware and additional performance enhancements.

All your data in one place
Stop managing separate databases. Instead, let Snowflake help unify your data footprint, so you can run transactional workloads alongside all your other workloads on a single platform.
Choose from two powerful capabilities: Snowflake Postgres for enterprise-ready Postgres, or Unistore’s Hybrid Tables to manage application state and build lightweight transactional apps directly on Snowflake.
Eliminate data pipelines to help reduce complexity, lower costs and innovate faster.

Benefits
Empower every user to answer complex questions in natural language with their own personalized enterprise intelligence agent.

Save time and money with a single fully managed platform for all workloads that is scalable, self-improving and has built-in FinOps for optimal cost efficiency
Accelerate strategic decision-making and unlock new business opportunities with an open architecture that provides direct access to the most complete ecosystem of AI-ready data, apps and agentic products.
Protect your assets and brand reputation by reducing compliance and security risks. Power your most mission-critical data, apps and AI workloads with enterprise-grade security, governance, observability and business continuity/disaster recovery controls across regions and clouds.
"The Snowflake Data Cloud has given us the power to harness and integrate data to create insights. With data at our fingertips, we are growing revenue, becoming more cost effective and, most importantly, improving the customer experience.”
Andy Markus
Chief Data Officer, AT&T

"KFC’s data sharing processes changed from taking days to being completed in just seconds. This allows access to more data faster and allows us to achieve greater insights and enhance our advanced analytics capabilities.”
Luis Bastos
Data Architect, KFC

“We’re talking about working with sensitive patient data — data that’s related to people’s mental health and specific clinical conditions so we have to build in security, governance, auditability, traceability and compliance from the very beginning, which Snowflake helps us achieve.”
Shahran Haider
Deputy Chief Data Officer at NYC Health + Hospital

Resources
Get Started
Snowflake Platform
Get common questions answered about the Snowflake platform and its capabilities.
Yes, the Snowflake platform is a fully managed service with many serverless capabilities. While you configure virtual warehouses, Snowflake handles the underlying infrastructure, scaling and maintenance.
Yes, Snowflake supports multi-cloud and cross-region operations. It’s available on major cloud providers (AWS, Azure, GCP) across numerous global regions. Snowflake’s Snowgrid enables cross-cloud and cross-region data sharing, replication for business continuity, and a consistent experience independent of the underlying cloud.
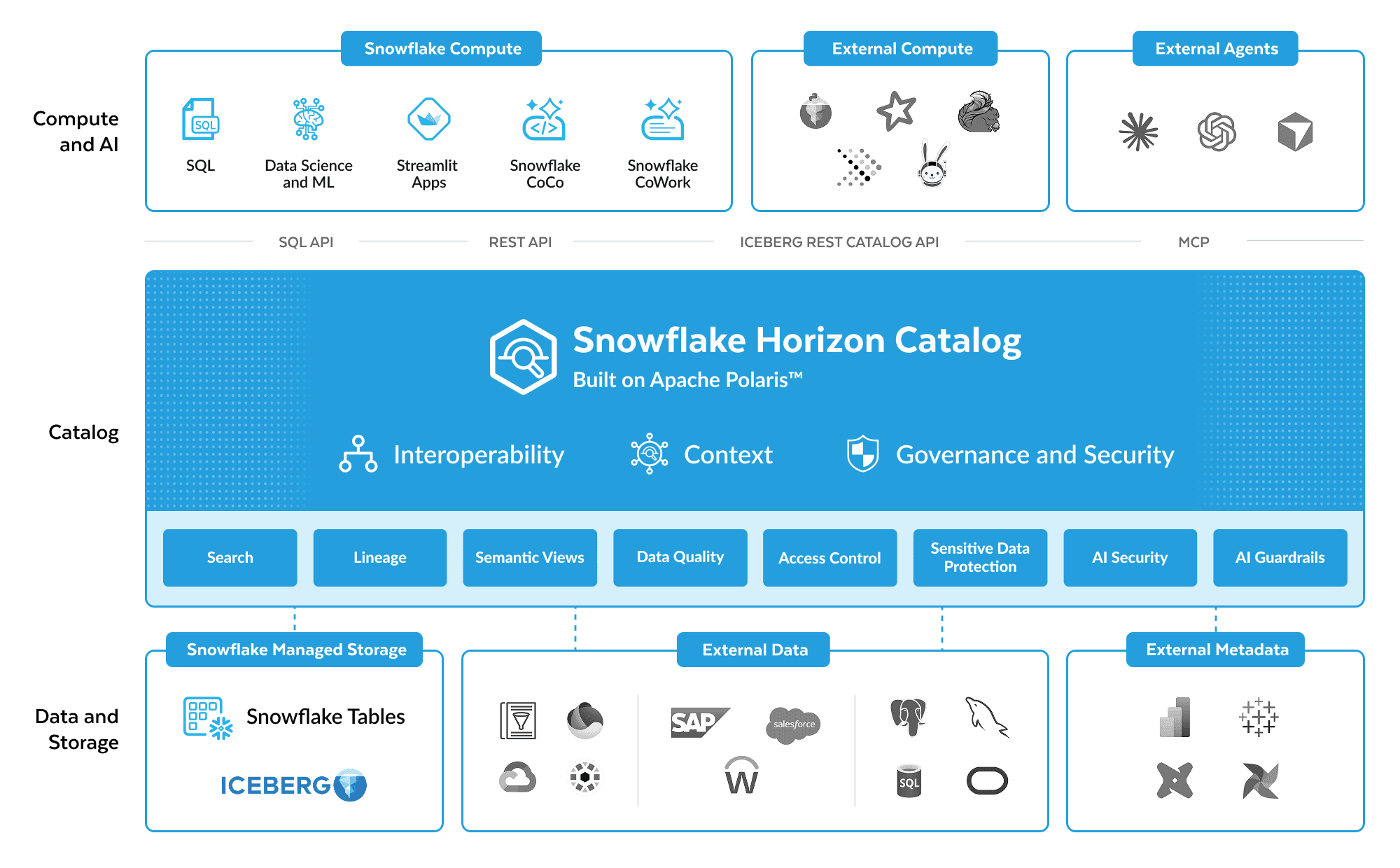
Yes, Snowflake has built-in security and governance features. This includes end-to-end encryption, role-based access control (RBAC), network policies, multi-factor authentication and data masking. Snowflake Horizon Catalog provides a unified governance solution with features like data discovery, compliance tools, access history and object tagging.
The two primary cost drivers are compute and storage. For compute resources, Snowflake employs a consumption-based model. Storage costs are based on the amount of data (measured in terabytes per month) stored within Snowflake. To get a detailed breakdown of our pricing and see our consumption table, we encourage you to visit the Snowflake Pricing Page for the most up-to-date and comprehensive information.
Yes, Snowflake offers a unified Cost Management Interface that allows you to see, control and optimize your Snowflake spend, serving as a built-in tool for FinOps. This interface also helps you easily check insights to proactively save on costs.
Snowflake offers several observability capabilities to monitor your account and workloads, including:
Foundation observability capabilities: Metrics, traces, logs, notifications and alerts
Infrastructure observability: Optimize Snowflake costs and performance through better resource utilization insights.
Pipeline observability: Help ensure reliable data delivery by proactively identifying and fixing pipeline failures.
Application observability: Quickly pinpoint and resolve bottlenecks in applications interacting with Snowflake.
AI observability: Accelerate AI development by confidently evaluating and improving AI agents and apps.
These features help in monitoring performance, troubleshooting and managing costs.






