Preserving Data Privacy in Life Sciences: How Snowflake Data Clean Rooms Make It Happen


The pharmaceutical industry generates a great deal of identifiable data (such as clinical trial data, patient engagement data) that has guardrails around “use and access.” Data captured for the intended purpose of use described in a protocol is called “primary use.” However, once anonymized, this data can be used for other inferences in what we can collectively define as secondary analyses. Secondary data is defined as data being used for a purpose that differs from the intention for which the data were collected, as defined by the Dictionary of Statistics and Methodology. These data sets can come from various sources, as illustrated in Figure 1.
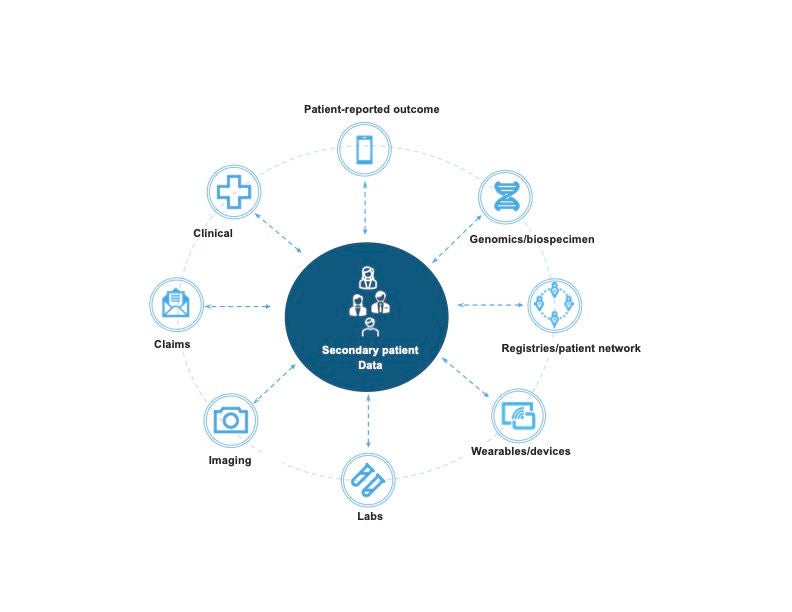
Secondary analysis is increasingly important to pharmaceutical companies, with a shift toward precision medicine and patient centricity. Patient-generated health data offers a new avenue through which pharmaceutical companies can derive additional insights into disease and treatment patterns.
The use of this data is varied, ranging from creating enriched patient cohorts to power clinical development efforts to identifying populations to quantify treatment effectiveness and associated value outcomes. Pharmaceuticals have years of rich data sets about patient characteristics collected over time (such as from clinical trials and omics studies), which makes it very beneficial to tap into.
Uses of data from secondary analysis across pharma value chain
- Predictive Analytics for Patient Stratification - Using secondary data to analyze and identify subpopulations for targeted therapies, improving clinical trial design and patient recruitment.
- Drug Repurposing and Market Expansion Opportunities - Data generated for secondary analysis from trials and enriched with associated multi-omics data can identify new indications for existing drugs and help with expanding market opportunities while minimizing development costs.
- Treatment Adherence and Comparative Effectiveness Studies - Data from secondary analysis is commonly used to facilitate assessments of treatment adherence and comparative effectiveness of drugs in the market. These data originate from third-party acquisitions of claims data.
- Health Economic Modeling for Pricing and Reimbursement - Conducting health economics and outcomes research (HEOR) with secondary data coming from the external real world called (RWD) demonstrates the real-world value of pharmaceutical interventions, informing pricing and reimbursement strategies.
The challenge of leveraging secondary data at scale
Data for secondary analysis can be obtained from either internal sources or purchased from external, third-party data aggregators and vendors. In fact, there has been a marked growth in the number of vendors selling longitudinal patient data. In this evolving landscape, the challenge for life sciences organizations is to seamlessly and reliably integrate the vast array of distributed, complex and heterogeneous data sources. Current methodologies fall short in providing adequate mechanisms for large-scale data aggregation that simultaneously meet stringent security and confidentiality requirements. Further, organizational silos; diversity of data sources (ranging from genetic and behavioral to clinical data, and each necessitating distinct processing methods); and lack of a common identifier for data integration all add to the difficulty of effectively managing and harnessing this wealth of information.
To counter these hurdles, life sciences companies are seeking technological interventions to bring scalability and security to the data they gather for secondary analysis. We call these interventions “privacy preservation” techniques. Privacy preservation encompasses a spectrum of techniques, grounded in two fundamental principles: the provision of mathematical guarantees of privacy and the prevention of reverse engineering of row-level data and insights. Long established in the adtech domain, these principles are now gaining momentum in the life science and healthtech data provider ecosystem, where collaborations and access to high-quality data are pivotal in the pursuit of targeted therapies.
These techniques are frequently employed in collaboration with the use of a data clean room. Data clean rooms are trusted research spaces designed to enable internal and external stakeholders to collaborate and implement privacy-preservation techniques safely. They serve as controlled and secure virtual environments where diverse data sources can be seamlessly stitched together and analyzed by multiple collaborating and analytical parties, all within a framework of robust security measures. These environments are particularly vital for life sciences organizations that find themselves compelled to share sensitive patient data for research and analytics with a diverse set of stakeholders, both internal and external to the companies.
In addition, differential privacy and tokenization are two privacy-preservation strategies you can employ in a data clean room, both of which allow you to anonymize identifiable elements in query results programmatically to stitch together disparate data sets by providing common tokens (or identifiers) based on statistical linkages of the patient respectively.
To learn more, read our ebook 3 Steps to Building an Effective Data Clean Room.
- Privacy preservation encompasses a spectrum of techniques, grounded in two fundamental principles: the provision of mathematical guarantees of privacy and the prevention of reverse engineering of row-level data and insights. Long-established in the Adtech domain, these principles are now gaining momentum in the life sciences and health tech data provider ecosystem, where collaborations and access to high-quality data are pivotal in the pursuit of targeted therapies.
- Data clean rooms are trusted research spaces designed to enable internal and external stakeholders to collaborate and implement the privacy preservation techniques safely. They serve as controlled and secure virtual environments where diverse data sources can be seamlessly stitched together and analyzed by multiple collaborating and analytical parties, all within a framework of robust security measures. These environments are particularly vital for life science organizations that find themselves compelled to share sensitive patient data for research and analytics with a diverse set of stakeholders, both internal and external to the companies.
- Differential privacy and Tokenization are two privacy preservation strategies part of the clean room that allow you to anonymize identifiable elements in query results programmatically to stitch together disparate data sets by providing common tokens (or identifiers) based on statistical linkages of the patient, respectively.
With the help of clean rooms, life sciences companies can gain several competitive advantages:
- Enhanced anonymization strategies: Anonymize data on demand by creating secondary data sets from internal primary data sets via the implementation of on-query anonymization (that is, performing anonymization at the time of executing analytical queries). This is done by either allowing aggregate queries to be returned or by masking data dynamically per pre-configured rules. This privacy-preservation technique inside a data clean room ensures queries do not return any identifiable data, and the data has sufficient levels of aggregation to prevent reidentification. This eliminates the need for duplicating data and manual biostatistical anonymization, which has been the standard previous practice.
- Organizational-scale analysis: A secure data clean room allows cross-regional teams as well as external organizations securely access data to perform analysis at scale. Empowering both internal and external employees within an organization to access data across geographies, without the necessity of data replication or copying sanitized subsets, accelerates insights generation without compromising on compliance or geographical restrictions.
- Elimination of duplicate data purchases: Expand patient sample sizes without spending money on duplicate data by performing overlap analysis prior to any data set purchase. Tokenization strategies on patient-related third-party data allow you to identify common patients between both data sets, mitigating the risk of buying overlapping data from two different providers. In addition to cost savings, the elimination of overlapping patient data across two data sets provides a larger sample of unique patient data, which is very helpful when conducting observational analyses, such as incidence and prevalence, or studying treatment patterns.
- Expanded patient sample sizes: Tokenization allows life sciences companies to create enriched patient cohorts by combining elements from diverse data sources (for example, EHR, claims, mortality indicators, patient-reported outcomes) that do not have an actual patient identifier; for example, you could combine mortality data points from one data set with hospital claims that have information on drug prescriptions and specific therapy recommendations. A data clean room using a token allows for such connections while providing guardrails against the possibility of identifying individual patients.
The solution: Snowflake Data Clean Rooms
Snowflake Data Clean Rooms, formerly Samooha, is a platform that provides data clean rooms as a first-party native application, built entirely on Snowflake’s architecture. In addition to performing the role of a traditional clean room, Snowflake Data Clean Rooms also allow life sciences organizations to run privacy-safe analytics and AI/ML workloads.
Snowflake Data Clean Rooms offer a dual-mode, no-code web application as well as a developer edition for advanced analytics and ML/AI use cases. It also provides differential privacy capabilities, which allow users to interrogate data with identifiable elements without exposing them in their query results. It serves as a platform in which an entire developer ecosystem is empowered to build their own applications anchored around secure data collaboration, in addition to performing privacy-preserved analytics.
Snowflake’s partnership with Datavant also makes it a solution that is particularly focused on the life sciences industry. Datavant provides the first layer of privacy-preserving technology through its tokenization process, while Snowflake Data Clean Rooms ensure no data leakage during collaboration. This is critical even with the use of privacy-preserving tokenization, as other patient attributes could be exposed and used to identify a patient if done outside of a data clean room.
To summarize, Snowflake Data Clean Rooms empowers users with the following benefits:
- Developer edition for easy customization, onboarding existing models and AI/ML workloads into the data clean room
- Native tokenization to ensure overlap is optimal and seamless to power life sciences company partnerships, such as with Datavant
- User-friendly UI to make it easier for non-technical users
- Differential privacy and other needs
Figure 2a and 2b below show a conceptual view of Snowflake Data Cleam Rooms and a sample data flow
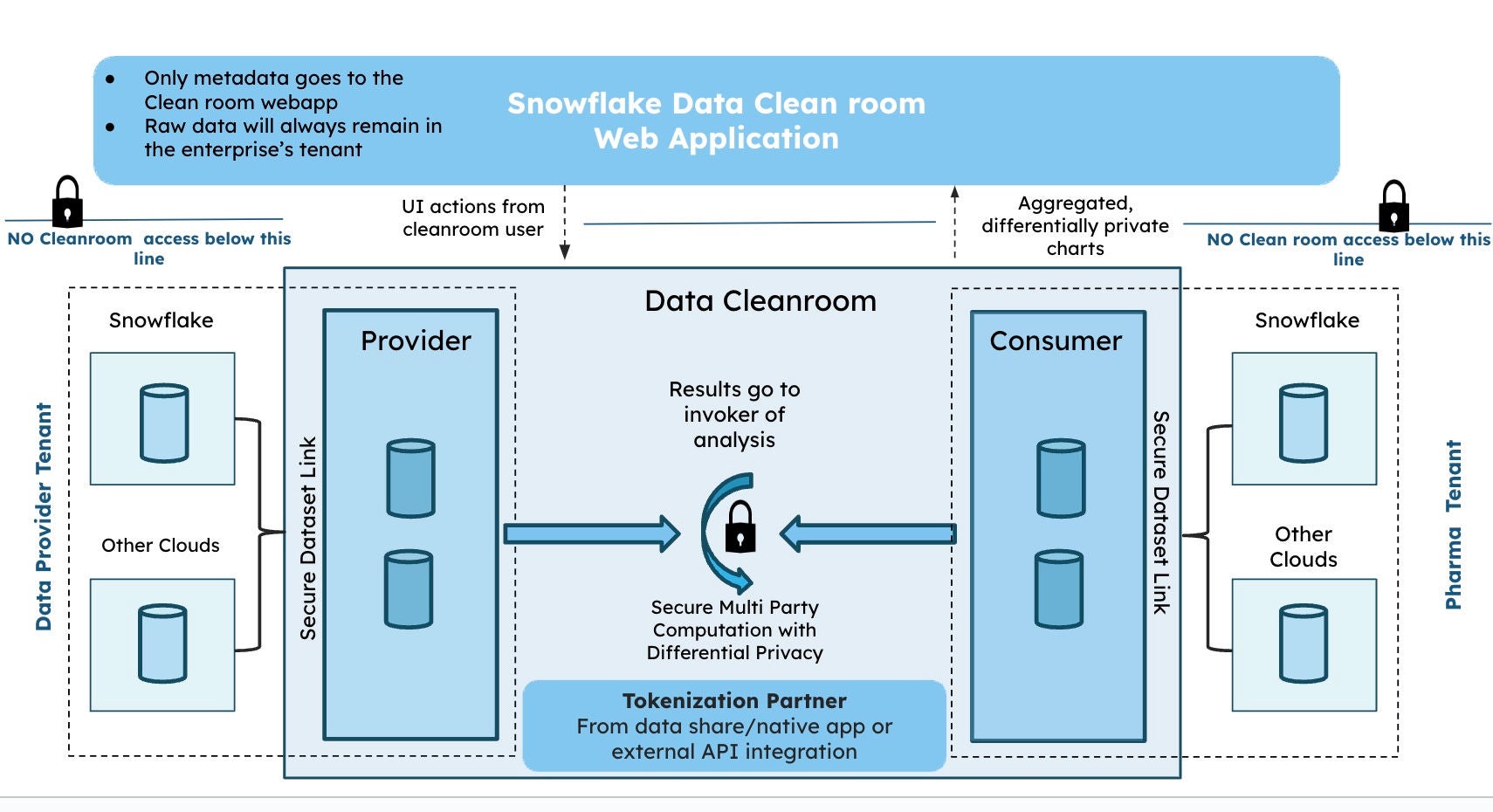
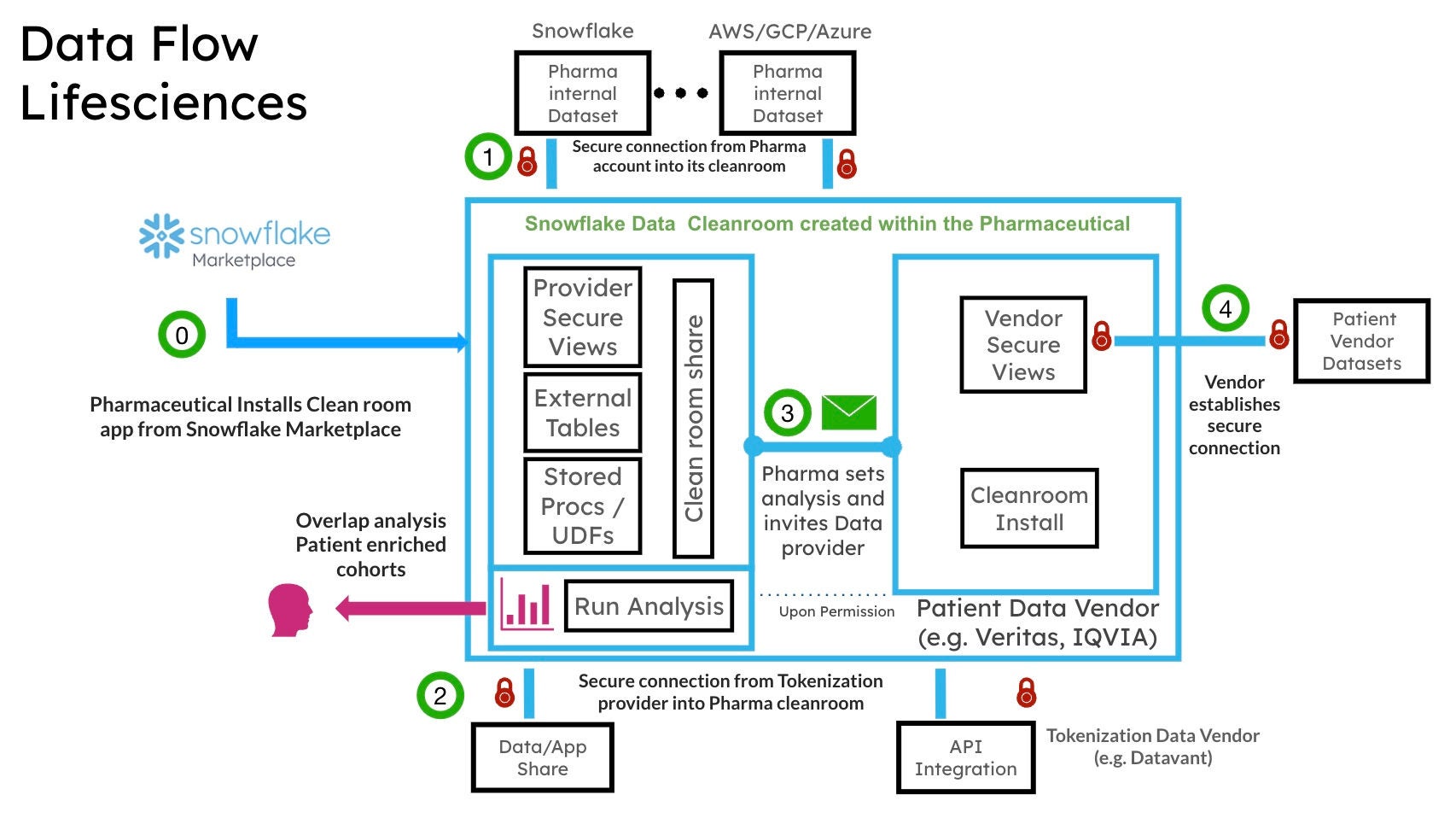
1. Pharmaceutical company and its collaborator join a Snowflake Data Clean Room.
2. Both parties leverage their tokenization provider of choice on their data to create tokens with patient identifiers. These tokens are then transformed into a common token key.
3. The pharma company configures the collaborator’s access to its internal data set, specifying which columns can be accessed and in what way. Both parties can join tokens in the clean room to create an enriched data set.
4. The collaborator runs insights within the clean room and configures appropriate privacy settings, such as threshold and differential privacy specific to its use case with required privacy obligation.
Ready to benefit from a data clean room?
Snowflake Data Clean Rooms framework, along with investment in Snowflake native applications, make it easy for life sciences organizations to securely and seamlessly collaborate, unlocking valuable health insights and improved patient outcomes. Customers can now leverage Snowflake Data Clean Room environments at no additional cost, simply drawing down from their existing Snowflake compute.
To learn more about implementing a data clean room, check out our 3 Steps to Building an Effective a Data Clean Room ebook. Please also note Snowflake Data Clean Rooms require acceptance of the specific Terms of Service.
