

In 2023, as part of the TruLens open source project developed by the TruEra team, we introduced the RAG Triad.1, 2, 3 This triad comprises a set of three metrics — context relevance, groundedness and answer relevance — that measure how well each step of a retrieval-augmented generation (RAG) system is performing.
Each of these metrics is automatically computed using an LLM-as-a-Judge (a carefully prompted LLM), thus providing a scalable evaluation method for the common case in enterprises where ground truth data sets are often limited in scope. This kind of LLM-as-a-Judge can also be thought of as an agent that reviews and reasons about the quality of the retrieval and generation steps of a RAG.
The RAG Triad introduced a modular approach to specifying requirements for each step of a RAG and either verifying that these requirements are met or enabling debuggability by localizing errors. As this approach has gotten widespread adoption with RAGs increasingly moving into production in enterprises, we have consistently heard one question from our users: How can we evaluate an LLM-as-a-Judge and build confidence in its trustworthiness?
In this blog post, we report on our recent work that addresses this question. Specifically, we share the results of benchmarking the three LLM Judges on standard ground truth data sets — TREC-DL4 for context relevance, LLM-AggreFact for groundedness and HotpotQA4 for answer relevance — reporting precision, recal, F1 scores and Cohen's Kappa5. Our benchmarking results indicate that our LLM Judges are comparable to or exceed the existing state of the art for groundedness and MLflow for the other two metrics in the RAG Triad. The Cohen Kappa results range from high moderate to substantial agreement with human annotators for all our results, providing additional support for the trustworthiness of the LLM Judges.
The LLM Judge for groundedness has an F1 score of 81%, a precision of 78%, a recall of 85% and a Cohen’s Kappa of 0.54 on the LLM-AggreFact data set. This placed it above the SOTA fine-tuned, proprietary Bespoke-MiniCheck-7B model on precision, recall and F1 score, as well as above the related LLM Judge from MLflow with respect to precision, F1 score and Cohen’s Kappa.
The LLM Judge for context relevance has an F1 score of 64%, a precision of 51% and a recall of 87% on the TREC-DL data set. This placed it above the LLM Judge with the UMBRELA prompt and the corresponding MLflow Judge on the F1 and recall metrics.
The LLM Judge for answer relevance has an F1 score of 79%, a precision of 99% and a recall of 66% on the HotpotQA data set. This makes it comparable to the MLflow Judge for the related metric.
We compare our results to SOTA baselines from the literature, such as the Bespoke-MiniCheck-7B model for groundedness and the UMBRELA prompt-based LLM Judge for context relevance, in addition to open source library MLflow, which provides some metrics related to the RAG Triad. We used GPT-4o as the default LLM in all our experiments. Note also that while we worked with an internal benchmark on which we could evaluate all three Judges of the RAG Triad, it would be useful to have public benchmarks for RAGs that enable this form of evaluation.
As a key part of this work, we introduced a new method for eval-guided optimization and applied it to improve the prompts for the LLM Judges. We will discuss this method and its application in a follow-up blog post.
We are also open sourcing the updated prompts in TruLens (see here). We encourage you to try them out as you build and evaluate RAGs. Here’s a notebook to get you started!
The RAG Triad
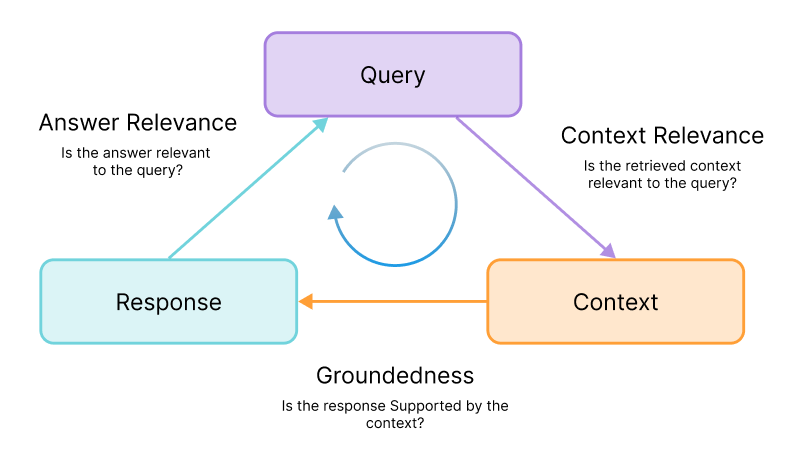
Before we consider a system of evaluations, it's useful to first discuss the architecture of the RAG system itself. In a simple RAG, there are three primary artifacts we can use to evaluate quality: query, retrieved context and generated output. Common failure modes of RAGs, including poor retrieval quality, hallucination and irrelevant answers, can all be traced back to the interactions between those three artifacts.
We proposed the RAG Triad of metrics — context relevance, groundedness and answer relevance — as a system of reference-free evaluations to identify and root-cause these common failure modes of RAG systems.
Let us examine each of the LLM Judges for the RAG Triad in detail below. Prompting for these LLM Judges is composed of a few key parts: the system prompt, judging criteria, few-shot examples, output scale and a user prompt containing the text to be evaluated. TruLens provides an easy way to configure the judging criteria, few-shot examples and output scale. In this blog post, we will focus on the default prompts and capabilities for each metric, including the default output scale of 0-3. The LLM Judge also makes use of an LLM. We used GPT-4o as the default LLM in all our experiments.
Context relevance
Context relevance addresses the retrieval step by evaluating the relevance of the context to the query. While this failure mode can lead to inaccurate or irrelevant application output, low-context relevance scores allow us to root-cause this output as poor retrieval performance and give the AI engineer a starting point to improve the application performance by focusing on the retriever.
As mentioned above, LLM Judge prompting is composed of the system prompt, criteria, few-shot examples and a user prompt containing the text to be evaluated. Context relevance utilizes each of these components and is evaluated on each piece of retrieved context independently. The prompt below is an optimized version of an LLM Judge for context relevance created in collaboration with the Snowflake Cortex Search team. We share each component of the prompt below, deferring the specific few-shot examples to the appendix.
Context relevance system prompt
You are an EXPERT SEARCH RESULT RATER. You are given a USER QUERY and a SEARCH RESULT.
The context relevance system prompt provides an overall description of the evaluation task and sets the role of the LLM. It also emphasizes the exact terminology to be used later in the user prompt (“question” and “context”).
Context relevance criteria
Your task is to rate the search result based on its relevance to the user query. You should rate the search result on a scale of 0 to 3, where:
0: The search result has no relevance to the user query.
1: The search result has low relevance to the user query. It may contain some information that is very slightly related to the user query but not enough to answer it. The search result contains some references or very limited information about some entities present in the user query. In case the query is a statement on a topic, the search result should be tangentially related to it.
2: The search result has medium relevance to the user query. If the user query is a question, the search result may contain some information that is relevant to the user query but not enough to answer it. If the user query is a search phrase/sentence, either the search result is centered around most but not all entities present in the user query, or if all the entities are present in the result, the search result while not being centered around it has medium level of relevance. In case the query is a statement on a topic, the search result should be related to the topic.
3: The search result has high relevance to the user query. If the user query is a question, the search result contains information that can answer the user query. Otherwise, if the search query is a search phrase/sentence, it provides relevant information about all entities that are present in the user query and the search result is centered around the entities mentioned in the query. In case the query is a statement on a topic, the search result should be either directly addressing it or be on the same topic.
You should think step by step about the user query and the search result and rate the search result. Be critical and strict with your ratings to ensure accuracy.
Think step by step about the user query and the search result and rate the search result. Provide a reasoning for your rating.
For context relevance, we provide qualitative descriptions for each possible score. Additionally, we provide additional guidance for the LLM to be “critical and strict” with ratings to avoid inflated relevance scores.
Context relevance user prompt
Now given the USER QUERY and SEARCH RESULT below, rate the search result based on its relevance to the user query and provide a reasoning for your rating.
USER QUERY: <user query> SEARCH RESULT: <search result>
RELEVANCE:
The context relevance user prompt is where the text to be evaluated is inserted and ties in consistent terminology with the system prompt — maintaining clear instructions for the LLM’s evaluation task.
Groundedness
Groundedness looks at the generation step, considering the adherence of the LLM response to the retrieved context. Importantly, groundedness considers the adherence of each claim made in the LLM’s response to the entire set of retrieved contexts. This allows us to identify unfaithful segments of the response and, in turn, allows the engineer to iterate on the generation step as the root cause. This could mean testing different models, engineering prompts, testing model parameters and more.
Preprocessing
Prior to the groundedness LLM Judge evaluation, the feedback function performs two preprocessing steps. The first step is claim decomposition. Here we break down the full LLM response into its composite claims or facts so that each can be evaluated independently. This step is performed either with a sentence tokenizer or with an LLM.
Second, any trivial claims are removed from the set prior to the evaluation. These trivial claims are claims that do not contain fact and therefore should not be considered in the evaluation. This step is performed with an LLM.
After the LLM response is processed into individual, nontrivial claims, we proceed with the evaluation.
The groundedness evaluation prompt includes a system prompt, criteria and a user prompt but does not make use of few-shot examples.
Groundedness system prompt
You are an INFORMATION OVERLAP classifier; providing the overlap of information (entailment or groundedness) between the source and statement.
The groundedness system prompt provides an overall description of the evaluation task and sets the role of the LLM to evaluate the information overlap between the source and statement. It also uses terminology (“source” and “statement”) consistent with the user prompt.
Groundedness criteria
- Statements that are directly supported by the source should be considered grounded and should get a high score.
- Statements that are not directly supported by the source should be considered not grounded and should get a low score.
- Statements of doubt, that admissions of uncertainty or not knowing the answer are considered abstention, and should be counted as the most overlap and therefore get a max score of 3.
- Consider indirect or implicit evidence, or the context of the statement, to avoid penalizing potentially factual claims due to lack of explicit support.
- Be cautious of false positives; ensure that high scores are only given when there is clear supporting evidence.
- Pay special attention to ensure that indirect evidence is not mistaken for direct support.
The groundedness criteria accomplish two primary objectives. The first three bullets provide a qualitative description for low, high and maximum scores. The remaining three bullets in the prompt caution the LLM against common evaluation failure modes including both false positives and false negatives.
Groundedness user prompt
Source: {all retrieved context}
Statement: {individual claim from LLM response}
Please meticulously answer with the template below for ALL statement sentences:
Criteria: <individual claim from LLM response>
Supporting Evidence: <Identify and describe the location in the source where the information matches the statement. Provide a detailed, human-readable summary indicating the path or key details. if nothing matches, say NOTHING FOUND. For the case where the statement is an abstention, say ABSTENTION>
Score: <Output a number based on the scoring output space / range>
First, the user prompt provides the source (retrieved) context along with an individual claim, using terminology (“source” and “statement”) consistent with the system prompt. Second, we provide chain-of-thought instructions to the LLM to first state the evaluation criteria and reasoning before the score. This is useful for ensuring both the quality and the interpretability of the groundedness evaluation. While chain-of-thought reasoning is an option for other TruLens evaluators, it is mandatory for groundedness due to the difficulty of the task.
Answer relevance
Answer relevance takes a second look at the generation step but focuses on the relevance of the LLM response to the user query. This allows us to identify cases where the response may be accurate to the limit of the retrieved context but still fails to answer the user question.
Answer relevance system prompt
You are a RELEVANCE grader; providing the relevance of the given RESPONSE to the given PROMPT.
Similar to context relevance, the answer relevance system prompt provides an overall description of the evaluation task and sets the role of the LLM. It also places emphasis on the exact terminology to be used later in the user prompt.
Answer relevance criteria
- RESPONSE must be relevant to the entire PROMPT to get a maximum score of 3.
- RELEVANCE score should increase as the RESPONSE provides RELEVANT context to more parts of the PROMPT.
- RESPONSE that is RELEVANT to none of the PROMPT should get a minimum score of 0.
- RESPONSE that is RELEVANT and answers the entire PROMPT completely should get a score of 3.
- RESPONSE that is confidently FALSE should get a score of 0.
- RESPONSE that is only seemingly RELEVANT should get a score of 0.
- Answers that intentionally do not answer the question, such as 'I don't know' and model refusals, should also be counted as the least RELEVANT and get a score of 0.
The answer relevance criteria provide qualitative descriptions of the minimum and maximum scores, along with an instruction for the direction of middle scores: “RELEVANCE score should increase as the RESPONSE provides RELEVANT context to more parts of the PROMPT.” Last, the criteria address key evaluation failure modes, including confident falsehoods and seeming relevance, and provide direct instructions for scoring abstention.
Answer relevance user prompt
QUESTION: <question>
CONTEXT: <context>
RELEVANCE:
The novelty of the RAG Triad comes with its direct tie to the RAG architecture, with evaluations targeting each step of the RAG. Additionally, the RAG Triad operates reference-free, without requiring ground truth, which in most cases is expensive or impossible to collect in generative AI systems. By decomposing a composite RAG system into its components — query, context and response — our evaluation framework can triage the failure points, provide a clearer understanding of where improvements are needed in the RAG system and guide targeted optimization.
Benchmarking results
In this section, we report the results of benchmarking the three LLM Judges discussed above on ground truth data sets: TREC-DL for context relevance, LLM-AggreFact for groundedness and HotpotQA for answer relevance. We compare our results to SOTA baselines from the literature, such as the Bespoke-MiniCheck-7B model for groundedness and the UMBRELA prompt-based LLM Judge for context relevance, in addition to open source libraries such as MLflow, which provide some metrics related to the RAG Triad. Our benchmarking results indicate that our LLM Judges are comparable to or exceed the existing state of the art for groundedness and MLflow for the other two metrics in the RAG Triad.
Groundedness
We use LLM-AggreFact as the benchmark data set to evaluate the TruLens LLM Judge for groundedness using GPT-4o and compare it against the SOTA Bespoke-MiniCheck-7B model.
LLM-AggreFact is chosen, given that it is the largest annotated collection of 11 claim verification data sets to our knowledge. All labels are unified to either 0 (not grounded) or 1, thus making metrics used in binary classification easily interpretable in the benchmarking of our groundedness LLM Judge.
On the LLM-AggreFact holdout set of 11,000 examples, the TruLens groundedness evaluator beats the SOTA Bespoke-MiniCheck-7B model on all three metrics. Doing so shows that optimized prompting can match and surpass the performance of task-specific fine-tuned models, such as Bespoke-MiniCheck-7B, on a large-scale benchmark.
Evaluator |
Precision |
Recall |
F1 Score |
Cohen’s Kappa |
Bespoke-MiniCheck-7B |
0.7610 |
0.8038 |
0.7771 |
0.5525 |
MLflow faithfulness |
0.6693 |
0.8902 |
0.7545 |
0.4155 |
TruLens groundedness |
0.7830 |
0.8515 |
0.8082 |
0.5358 |
Context relevance
Context relevance is closely related to the task of relevance prediction in information retrieval. For the benchmark data set, we used a sample of TREC-DL passage retrieval data sets with human annotations from the years 2021 and 2022 with a fair distribution of labels from each relevance score {0, 1, 2, 3}.
The original relevance scores are then unified to binary labels {0, 1}, where {2,3} are converted to 1 (relevant) and {0, 1} are converted to 0 (nonrelevant), following the instructions from the original TREC passage retrieval challenge.
The TruLens LLM Judge using GPT-4o context relevance scores makes a positive trade-off of recall at the expense of a smaller drop in precision compared to the UMBRELA evaluator. This results in the TruLens context relevance evaluator landing a higher F1 score than UMBRELA on the TREC-DL data set, while keeping a comparable off-by-one accuracy.
We include MLflow relevance metrics for comparison’s sake, but note that we are not reporting off-by-one accuracy for MLflow as the output scores are all between 0.0 and 1.0 instead of being directly prompted to generate relevance scores {0, 1, 2, 3} like UMBRELA’s and TruLens’s adapted context relevance feedback function. MLflow relevance also takes into account the generated responses from the LLM, whereas the other two require only query and context, and we substitute the retrieved responses given the query for the missing LLM-generated responses on our TREC-DL data set.
Evaluator |
Precision |
Recall |
F1 Score |
Off-by-1 Accuracy |
Cohen’s Kappa |
UMBRELA |
0.6000 |
0.6449 |
0.6216 |
0.8945 |
0.4529 |
MLflow relevance |
0.5973 |
0.6885 |
0.6396 |
N/A |
0.4873 |
TruLens context relevance |
0.5129 |
0.8660 |
0.6443 |
0.8902 |
0.4769 |
Answer relevance
Among all three metrics of the RAG Triad, answer relevance is the most straightforward task. Most high-quality, established benchmarks of intelligent question-answering (QA) systems can be used for benchmarking the answer relevance feedback function, with the expected golden answers in the QA benchmark being treated as relevant (ground truth label 1).
We report our answer relevance meta-evaluation results on HotpotQA samples. The benchmark examples are sampled with both classes balanced, where ground truth answers are assumed to be relevant and we shuffle answers to queries to create negative examples (ground truth label 0).
In our answer relevance benchmarks, the TruLens answer relevance LLM Judge using GPT-4o achieves near-perfect precision and identical recall to the MLflow implementation. This is partly due to the simpler nature of the HotpotQA data set, where the ground truth answers to questions are likely to be considered perfectly relevant by the LLM Judges and negative examples are mined by pairing questions with answers from another disjoint set of questions.
Evaluator |
Precision |
Recall |
F1 Score |
Cohen’s Kappa |
MLflow answer relevance |
1.0000 |
0.6650 |
0.7988 |
0.665 |
TruLens answer relevance |
0.9924 |
0.6550 |
0.7892 |
0.605 |
It is important to note that TruLens’s definition of answer relevance does not encompass answer correctness. That is, while a correct answer, whenever available, should always be judged as relevant, an incorrect answer can still be scored as perfectly relevant.
Conclusions
In this blog post, we shared the results of benchmarking the LLM Judges of the RAG Triad — a modular approach to specifying requirements for each step of a RAG and either verifying that these requirements are met or enabling debuggability by localizing errors. Specifically, we shared the results of benchmarking the three LLM Judges on standard ground truth data sets: TREC-DL for context relevance, LLM-AggreFact for groundedness and HotpotQA for answer relevance. Our benchmarking results indicate that our LLM Judges are comparable to or exceed the existing state of the art for groundedness (the Bespoke-MiniCheck-7B model) and popular open source libraries (MLflow) for the other two metrics in the RAG Triad. The Cohen Kappa results range from high moderate to substantial agreement with human annotators for all our results, providing additional support for the trustworthiness of the LLM Judges.
While we introduced the concept of the RAG Triad back in July 2023,1 as part of this work, we have improved the prompts for the LLM Judges significantly by leveraging a new method for eval-guided optimization. Stay tuned for a follow-up blog post on that next week.
We are also open sourcing the updated prompts in TruLens (see here). We encourage you to try them out as you build and evaluate RAGs. Here’s a notebook to get you started!
1 Shayak Sen, LLMs: Consider Hallucinatory Unless Proven Otherwise, AI Transformation Summit – Pinecone, July 2023.
2 Anupam Datta, Jerry Liu with Andrew Ng, Building and Evaluating Advanced RAG.
3 TruLens docs, The RAG Triad.
4 https://creativecommons.org/licenses/by/4.0/legalcode
5 Cohen's Kappa measures inter-rater reliability between humans and LLM judges tasked in the same experiment. Cohen’s Kappa, ranging from -1 to 1, takes into account agreement by chance between human and LLM judges.
Appendix: Context relevance few-shot examples
Use the following format:
Rating: Example Rating
Reasoning: Example Reasoning
### Examples
Example:
Example 1:
INPUT:
User Query: What is the definition of an accordion?
Search Result: Accordion definition, Also called piano accordion. a portable wind instrument having a large bellows for forcing air through small metal reeds, a keyboard for the right hand, and buttons for sounding single bass notes or chords for the left hand. a similar instrument having single-note buttons instead of a keyboard.
OUTPUT:
Rating: 3
Reasoning: In this case the search query is a question. The search result directly answers the user question for the definition of an accordion, hence it has high relevance to the user query.
Example 2:
INPUT:
User Query: dark horse
Search Result: Darkhorse is a person who everyone expects to be last in a race. Think of it this way. The person who looks like he can never get laid defies the odds and gets any girl he can by being sly,shy and cunning. Although he\'s not a player, he can really charm the ladies.
OUTPUT:
Rating: 3
Reasoning: In this case the search query is a search phrase mentioning \'dark horse\'. The search result contains information about the term \'dark horse\' and provides a definition for it and is centered around it. Hence it has high relevance to the user query.
Example 3:
INPUT:
User Query: Global warming and polar bears
Search Result: Polar bear The polar bear is a carnivorous bear whose native range lies largely within the Arctic Circle, encompassing the Arctic Ocean, its surrounding seas and surrounding land masses. It is a large bear, approximately the same size as the omnivorous Kodiak bear (Ursus arctos middendorffi).
OUTPUT:
Rating: 2
Reasoning: In this case the search query is a search phrase mentioning two entities \'Global warming\' and \'polar bears\'. The search result contains is centered around the polar bear which is one of the two entities in the search query. Therefore it addresses most of the entities present and hence has medium relevance.
Example 4:
INPUT:
User Query: Snowflake synapse private link
Search Result: "This site can\'t be reached" error when connecting to Snowflake via Private Connectivity\nThis KB article addresses an issue that prevents connections to Snowflake failing with: "This site can\'t be reached" ISSUE: Attempting to reach Snowflake via Private Connectivity fails with the "This site can\'t be reached" error
OUTPUT:
Rating: 1
Reasoning: In this case the search result is a search query mentioning \'Snowflake synapse private link\'. However the search result doesn\'t contain information about it. However it shows an error message for a generic private link which is tangentially related to the query, since snowflake synapse private link is a type of private link. Hence it has low relevance to the user query.
Example 5:
INPUT:
User Query: The Punisher is American.
Search Result: The Rev(Samuel Smith) is a fictional character, a supervillain appearing in American comic books published by Marvel Comics. Created by Mike Baron and Klaus Janson, the character made his first appearance in The Punisher Vol. 2, #4 (November 1987). He is an enemy of the Punisher.
OUTPUT:
Rating: 1
Reasoning: In this case the search query is a statement concerning the Punisher. However the search result is about a character called Rev, who is an enemy of the Punisher. The search result is tangentially related to the user query but does not address topic about Punisher being an American. Hence it has low relevance to the user query.
Example 6:
INPUT:
User Query: query_history
Search Result: The function task_history() is not enough for the purposes when the required result set is more than 10k.If we perform UNION between information_schema and account_usage , then we will get more than 10k records along with recent records as from information_schema.query_history to snowflake.account_usage.query_history is 45 mins behind.
OUTPUT:
Rating: 1
Reasoning: In this case the search query mentioning one entity \'query_history\'. The search result is neither centered around it and neither has medium relevance, it only contains an unimportant reference to it. Hence it has low relevance to the user query.
Example 7:
INPUT:
User Query: Who directed pulp fiction?
Search Result: Life on Earth first appeared as early as 4.28 billion years ago, soon after ocean formation 4.41 billion years ago, and not long after the formation of the Earth 4.54 billion years ago.
OUTPUT:
Rating: 0
Reasoning: In the case the search query is a question. However the search result is completely unrelated to it. Hence the search result is completely irrelevant to the movie pulp fiction.
###


Arctic RL: A Unified, Open Source RL Backend for Enterprise Post-Training

HybridDeepResearch: Enforcing Rigor Across SQL and Web Search for Enterprise Agents
Inside the ArcticSwarm Architecture: How ArcticSwarm Improves Deep Research