Snowpark: Designing for Secure and Performant Processing for Python, Java, and More


To run a diverse set of workloads with minimal operational burden, Snowflake built an intelligent engine that plans and optimizes the execution of concurrent workloads using a multi-clustered, shared data architecture. It also features logically integrated but physically separated storage and compute.
SQL developers were the first to be able to interact with this engine, which comes with many built-in optimizations such as auto-clustering and micro-partitioning. And now with Snowpark we have opened the engine to Python, Java, and Scala developers, who are accelerating development and performance of their workloads, including IQVIA for data engineering, EDF Energy for feature engineering, Bridg for machine learning (ML) processing, and more.
Spearheading the engineering team behind Snowpark has been a rewarding experience, and one that has helped me gain a much better understanding of the existing large-scale processing ecosystem that played a role in defining the vision of what Snowpark should and shouldn’t be. This blog post will be a close look at key principles we wanted to adhere to and how we made it work.
Key principles driving the vision for Snowpark
As we designed Snowpark, the most important thing was that it had to be part of a single product experience. As part of that experience there was a set of principles, listed in order of priority below, that would help us make decisions around the implementation.
1. Trusted: To get any data product into production, security, data governance, and reliability are non-negotiable and, as such, were a key requirement for Snowpark—both in how it handles processing of Python open source libraries and how the engine interacts with external systems to maintain enterprise-grade security of data.
2. Easy to use: Whether you’re a developer using SQL or Python to build a data pipeline, for example, or you’re using Python for ML, you should not have to worry about tuning knobs or managing data across multiple compute clusters, repetitive tasks that take away time from development. Snowpark just works!
3. Powerful: Performance and scalability should be best of class in a way that meets the processing demands of our customers. This performance had to be present across any of a diverse set of workloads, whether it is a data engineering pipeline, ML model training, or a Native App that serves that model to end users.
4. Familiar: Developers should not have to learn a completely new way to define the way they process data; instead, end users should be provided with APIs and frameworks that they already know.
Snowpark execution
The first decision was to decide where Python or other language processing would run. We optimized for trust and ease of use, using these principles to guide us away from building a separate engine that would run outside of Snowflake’s governance boundary and would silo users to run separate infrastructure based on programming language preference.
With a single engine strategy, the next thing to address was performance. We decided to implement the following execution path for the instructions going into that single engine:
1. Code is compiled for the execution plan.
2. The execution plan is submitted to a driver, which plans and schedules execution based on required resources and, if results are requested, those are created and returned.
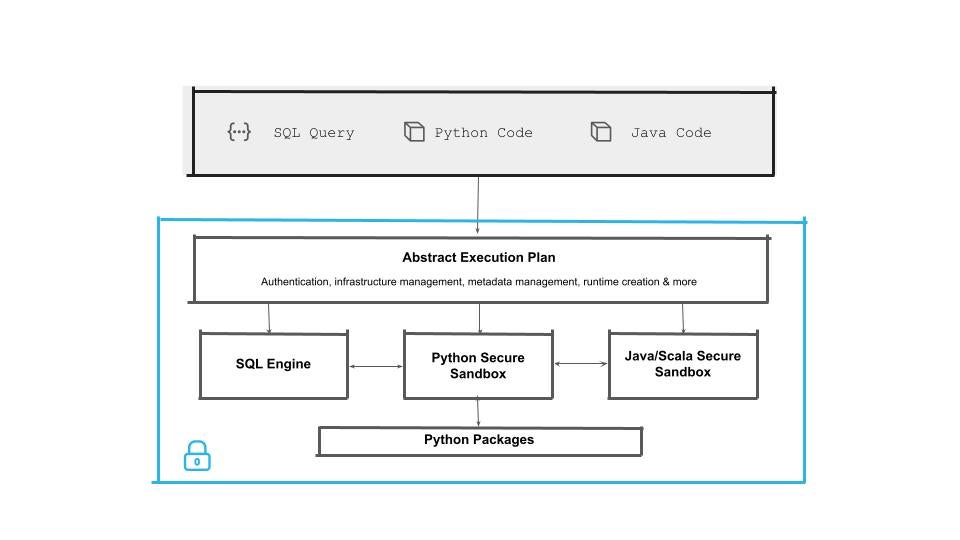
Developers should be able to write and deploy their code from their favorite integrated development environment (IDE) or notebook to make it a familiar experience. So there is no need to move from existing tools used for development and hosting of code to leverage Snowflake’s engine, which can do all the processing securely and at nearly any scale.
Python sandbox
For Python (and similarly for Java) functions to be natively executed in Snowflake, code is compiled into Python bytecode and executed via User Defined Functions (UDFs) inside of Snowpark’s restricted sandbox environment. One of the biggest challenges with Python was the security aspect of running third-party packages. We partnered with Anaconda to bring vetted versions of the most popular Python packages, with a way to also bring your own package that meets safeguard requirements. We did this to prevent supply chain attacks from malicious packages that could do things like corrupt or exfiltrate data, rather than just allowing any package from the internet to be executed in Snowflake..
We seamlessly integrated the Anaconda package manager into the Python UDF creation workflow to bring ease of use into the experience. This is immensely valuable because without the right packages, resolving dependencies between different packages can land developers in “dependency hell”. This can also be a huge time sink.
Yet, because almost all of those libraries are written on top of Numpy/Pandas, the execution of this code is bound to a single node. We have implemented the following optimizations to get the best performance out of custom Python code:
- Snowpark DataFrame API enables query/transform operations to scale out (we’ll dive deeper into this in the next section)
- UDFs can be pre-registered in your Snowflake account, so they don’t need to be installed every time as part of your automated pipelines.
- Vectorized Python UDFs provide a way to process Pandas DataFrames in batches versus operating row by row. For things like numerical computations, Snowpark developers can expect +30% performance improvements on average.
- To support the needs of workloads that have large memory requirements, developers can use Snowpark-optimized warehouses, which for customers such as Spring Oaks Capital has provided an 8x improvement over prior solutions.
- For Machine Learning workloads on Snowpark-optimized warehouses we allow Python code to take full advantage of all CPU cores available on the node through Python multiprocessing libraries like Joblib.
This is just the beginning and not an exhaustive list as we are continuously measuring and looking for ways to improve performance.
DataFrame operations
To query, transform, or clean the data for downstream consumption, data engineers and scientists processing data at scale are most comfortable using DataFrames. This provides abstraction to organize data into named columns, similar to a table. That’s why for Snowpark Python DataFrames and other supported Snowpark languages, this is the primary interface to manipulate data in Snowflake.
DataFrame operations are also submitted to the execution plan to optimize the processing using the SQL engine and all of its optimizations. In this way, the Snowflake services layer can make decisions to parallelize and execute code efficiently. It can do this even if the code is not optimized by leveraging a decade’s worth of optimizations. Both Python bytecode and SQL run in the same virtual warehouse, which reduces the need to convert, egress, scan, and load data across compute clusters. This is how Snowflake customers see their workloads immediately run faster, often without making any changes to PySpark code.
With more advanced DataFrame operations, and future enhancements to Snowflake’s compute infrastructure, we continue to provide familiar programming paradigms and work on making your code run securely and faster without operational complexity. Stay tuned for more announcements coming at Snowflake Summit.
Performance testing
We test the performance of Snowpark with benchmarks such as TPCxBB as part of our QA workflow. But making competitive performance claims that aren’t grounded in real-world workloads is not our goal. Our engineering team instead continues to work hand-in-hand with customers' real-world scenarios to build automated optimizations that make Snowpark more performant and cost-effective. I want to encourage you to try Snowpark and let us know how we are performing on your workload.
How to get started
The fastest way to try Snowpark for Python is by going through a new trial experience, which has a pre-populated Python worksheet with code samples to help you go from zero to deploying your first set of DataFrame operations on a data set with ~300K records—all from within Snowflake.
And check out these two guided walkthroughs if you are ready to take it to the next level:


