Synthetic Data Generation at Scale – Part 2


In the first part of this post, I demonstrated how to create vast amounts of data in Snowflake using standard SQL statements. Creating the SQL statements by hand is labor-intensive, but fortunately you can automate the task. All you need is a specification that defines table and column names, data types, and additional statistical information.
With the help of James Frink, a Sales Engineer at Snowflake, I created a Python script that automates the generation of the SQL statements based on a standardized spec. You can find the whole project, including the Python script and documentation, here.
Schema Specification
The schema specification for the generation utility requires the following attributes as input:
- Schema name
- Column name
- Column cardinality (the number of distinct values in this column)
- Table cardinality (the number of rows in this table)
- Data type (see the list of values in the table below)
- Data length (valid for data types char, varchar, and number)
- Data precision (valid for data types varchar and number)
Using Excel or Google Sheets is an easy way to manage the spec, particularly if you want to make mass changes. Both Excel and Google Sheets provide the ability to create functions, which comes in handy when you want to modify (reduce) the number of rows per table for testing.
The utility generates data type-specific code for the most widely used data types. For instance, if we want to generate 100 different dates, we add a random number of days (1 to 100). Or if we want to create random timestamps down to the second for a 24 hour period, we can add a random number of seconds (1 to 24*60*60) to a base date.
The supported data types and the correct method to create unique values are described in the table below. Please note that CHAR and VARCHAR use two different methods. VARCHAR is using the randstr() function. The biggest advantage of randstr() is that it creates truly random strings. But that advantage comes at a cost. Foreign key relationships are much harder to manage this way (see below). For that reason, fixed length CHAR values are created by generating a random number (out of a set of numbers from 1 to column cardinality), which are then padded by a static string.

Code Generation
If you haven’t already cloned or downloaded the GitHub repo, take a moment to do it now.
The repo includes:
- A Python script (used to generate SQL statements from a spec)
- An Excel workbook (used to generate SQL statements from a spec)
- An awk script (used to assemble the SQL statements for the Excel code generator)
- .txt files (intermediate output for the Excel code generator)
- .csv files (schema spec for the Python code generator)
- .sql files (SQL output files)
There are two supported ways to generate SQL statements from the spec. You can either use the Excel workbook or a Python script to generate the SQL statements. You can find an in-depth description on how to use both methods on GitHub.
Both methods have advantages and disadvantages. The Excel route provides more flexibility for more-complex situations because you can easily modify the text functions in Excel that generate the SQL code. But then you have to use the awk script to create the final SQL script. Because using the Python script is a single-step process, it is easier to demo and, therefore, that’s what we will focus on in this post.
Single Table Schema
We will start with creating a spec for the test table, testdf, from Part 1. All columns are of data type VARCHAR and have a specific length, which defines the maximum length of the column. The license_plate column also has a precision, which defines the minimum length. Lastly we specify the column cardinality, specifically the number of distinct values for each column, and the table cardinality, which is the number of rows in the table.

You can copy the spec above into Excel or Google Sheets and save it as a .csv file. I called my file testdf.sql.
The next step is to generate the SQL statement by running the Python code generator script.
python3 snowflake_python_generator.py testdf.csv The output is printed directly to the console:
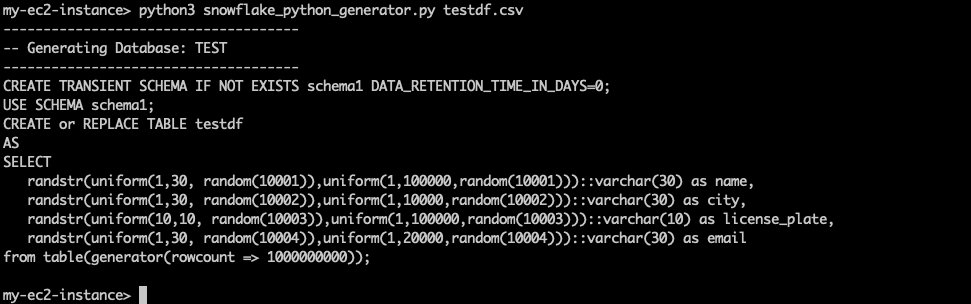
For your convenience, I have put the output below so you can copy it if necessary.
CREATE TRANSIENT SCHEMA IF NOT EXISTS schema1
DATA_RETENTION_TIME_IN_DAYS=0;
USE SCHEMA schema1;
CREATE or REPLACE TABLE table1
AS
SELECT
randstr(uniform(1,30, random(10001)),
uniform(1,100000,random(10001)))::varchar(30) as name,
randstr(uniform(1,30, random(10002)),
uniform(1,10000,random(10002)))::varchar(30) as city,
randstr(uniform(10,10, random(10003)),
uniform(1,100000,random(10003)))::varchar(10) as license_plate,
randstr(uniform(1,30, random(10004)),
uniform(1,20000,random(10004)))::varchar(30) as email
from table(generator(rowcount => 1000000000));The generated SQL statements include a CREATE SCHEMA statement. To save space and keep cost low, the statement creates a transient schema with a data retention time of 0 days. This prevents consuming additional space for Snowflake Fail-Safe or Time Travel. No having Fail-Safe space isn’t really a problem here, because we can always re-run the statements, in case the dataset gets corrupted.
If you want to route the output into a file, use the --sqlfile parameter and provide a file name.
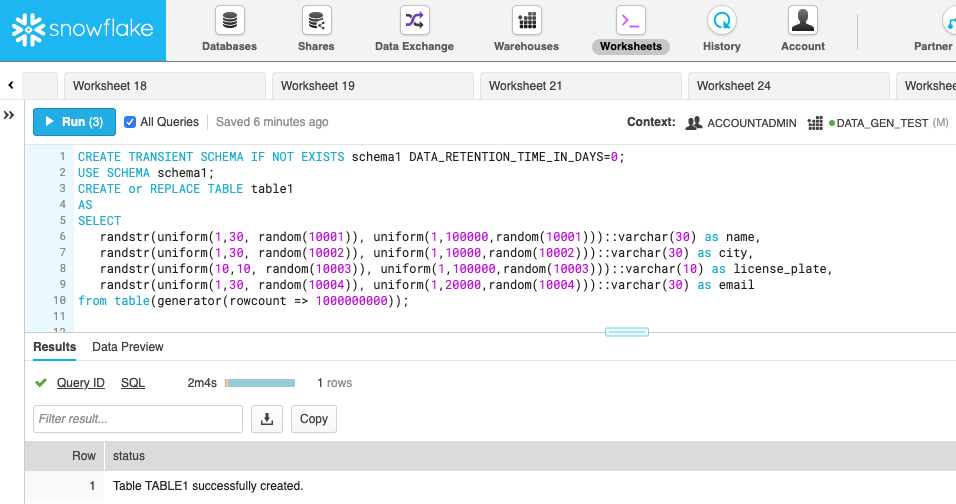
python3 snowflake_python_generator.py testdf.csv --sqlfile testdf.sqlImport the SQL script into a Snowflake worksheet (or just copy it from above), pick a database and a warehouse, and run it. As expected (due to our benchmark in Part 1), Snowflake creates the 1 billion row data set in 2 minutes because we are running on a Medium warehouse.
Multiple tables and foreign keys
Creating a SQL script for one table can be a lifesaver if you are testing generating data for a table with hundreds of columns. But the real power comes when you build multiple schemas with multiple tables that have foreign key relationships.
For the purpose of this post, I’ll demonstrate the concepts on a database with two schemas having a total of four tables.
- OLTP schema:
- Order_master: 10000000 rows
- Order_detail: 1000000000 rows, foreign keys to order_master, product
- Product: 10000 rows
- LOG schema
- Log: 5000000000 rows
The table definitions are fairly self-explanatory. Of course we can make these tables as wide and as complex as we want. This is just a small example.
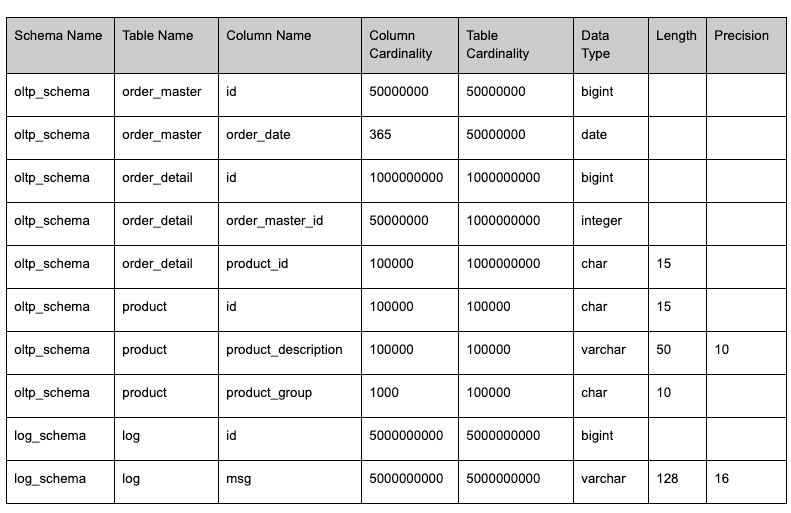
Note that the order_detail table has two foreign keys: one to the order_master table and one to the product table. The spec does not explicitly define foreign keys. However, the keys still work if we ensure two requirements:
- First, the data type of the primary key attribute and the foreign key attribute have to match exactly. For instance, in the spec above, order_master.id matches order_detail.order_master_id. If the data types don’t match, the generated data will not match.
- Second, the table cardinality of the master table has be equal (or bigger) than the column cardinality of the foreign key column in the detail table. For instance, product.id (100000) = order_detail.product_id(100000).
As long as those two requirements are met, foreign keys relationships will work in the generated data.
As before, we have to copy the spec into a CSV file via Excel or Google Sheets. Save the output as a .csv file (I called my file online_ship.csv) and run the code generator against the saved file.
python3 snowflake_python_generator.py online_shop.csv --sqlfile
online_shop.sqlHere’s the output as a reference:
CREATE TRANSIENT SCHEMA IF NOT EXISTS oltp_schema
DATA_RETENTION_TIME_IN_DAYS=0;
USE SCHEMA oltp_schema;
CREATE or REPLACE TABLE order_master
AS
SELECT
(seq8()+1)::bigint as id,
dateadd(day, uniform(1, 365, random(10002)), date_trunc(day,
current_date))::date as order_date
from table(generator(rowcount => 50000000));
CREATE or REPLACE TABLE order_detail
AS
SELECT
(seq8()+1)::bigint as id,
uniform(1,50000000 , random(10004))::integer as order_master_id,
rpad(uniform(1, 100000, random(10005))::varchar,15,
'abcdefghifklmnopqrstuvwxyz')::char(15) as product_id
from table(generator(rowcount => 1000000000));
CREATE or REPLACE TABLE product
AS
SELECT
rpad((seq8()+1)::varchar,15,
'abcdefghifklmnopqrstuvwxyz')::char(15) as id,
randstr(uniform(10,50,
random(10007)),uniform(1,100000,random(10007)))::varchar(50) as
product_description,
rpad(uniform(1, 1000, random(10008))::varchar,10,
'abcdefghifklmnopqrstuvwxyz')::char(10) as product_group
from table(generator(rowcount => 100000));
CREATE TRANSIENT SCHEMA IF NOT EXISTS log_schema
DATA_RETENTION_TIME_IN_DAYS=0;
USE SCHEMA log_schema;
CREATE or REPLACE TABLE log
AS
SELECT
(seq8()+1)::bigint as id,
randstr(uniform(16,128,
random(10010)),uniform(1,5000000000,random(10010)))::varchar(128) as
msg
from table(generator(rowcount => 5000000000));Lastly we are able to execute the SQL script in Snowflake. Creating over 6 billion rows for this test takes about 15 minutes on a Medium size warehouse. Thanks to per-second billing and nearly linear scalability in Snowflake, it costs the same whether it is running on a Medium warehouse or on an X-Large warehouse. An X-Large warehouse is four times as big and generates the data set about four times as fast. For that reason, I ran this test on an X-Large warehouse, which creates the 6+ billion rows in just about 4 minutes.
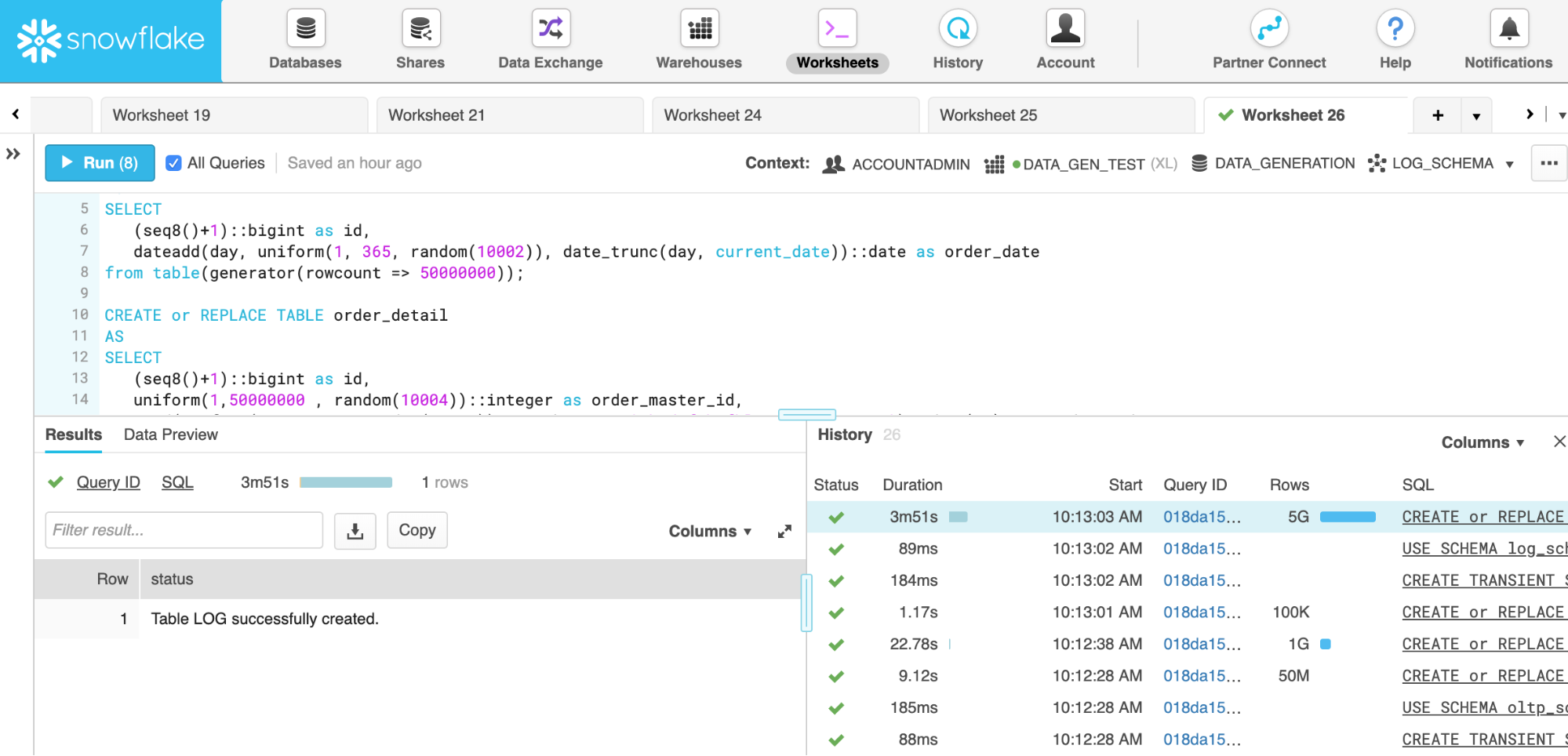
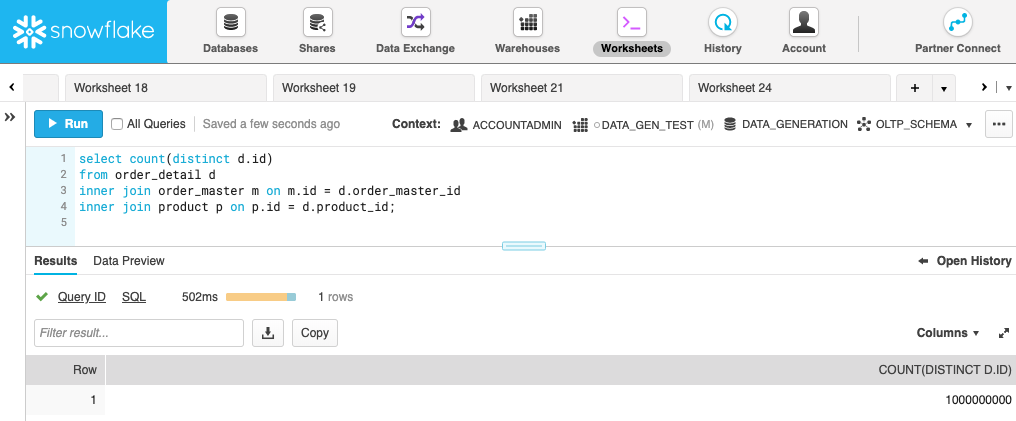
The total time for running all statements is about 4 minutes and 20 seconds. To prove that the foreign keys have been created correctly, the following screenshot shows a query running inner joins between the order_detail, order_master, and product tables. We are expecting 1 billion rows because we created 1 billion rows in the order_detail table and, as you can see, the result of the query is 1 billion.
Conclusion
Snowflake data generation functions make is very easy to create test data for a variety of different data types. The framework implemented in the data generation Python script automates the whole process of generating the necessary SQL code for multiple schemas, multiple tables within one schema, and even foreign key relationships between different tables. And Snowflake’s performance at near-linear scalability which makes creating even billions of rows a breeze.
