Synthetic Data Generation at Scale - Part 1


During one of my recent projects, the customer asked me to run a performance comparison between Snowflake and their existing system, with the caveat that I couldn’t use their data (not even a sanitized copy) to run the comparison. Without access to the customer’s data, my only option was to create synthetic data that matched the customer’s data in terms of structure (schema) and size.
Although database professionals often need to generate data for test or demo purposes, it is an age-old challenge in spite of the fact that there are many tools and open source frameworks available for creating synthetic data. The question was whether any of those solutions would be able to handle the scaling requirements for this project because we were not talking about hundreds of thousands of rows, but billions of rows for most of the fact tables.
Python Data Generation Packages
Python has excellent support for synthetic data generation. Packages such as pydbgen, which is a wrapper around Faker, make it very easy to generate synthetic data that looks like real world data, so I decided to give it a try.
Installing pydbgen is very simple. Here’s a link to the pydbgen documentation, which describes how to use the pip package manager to install pydbgen.
For the following example test, I’m creating a simple AWS EC2 box running Ubuntu 18.04. Although the AMI (Amazon Machine Image) comes preinstalled with Python3, it does not come with the pip package manager. Therefore, you need to install pip3 before installing pydbgen.
sudo apt install python3-pipIf you see the error Unable to locate package python3-pip, this means you must first patch your server because the list of package repos is out of sync.
Reading package lists... Done
Building dependency tree
Reading state information... Done
E: Unable to locate package python3-pipPatching your server is easy and just requires the two commands below.
sudo apt update
sudo apt upgradeNow you’re ready to install pydbgen via pip3. Depending on what packages were previously installed in your environment, your success message might list more or fewer packages than what’s shown below.
pip3 install pydbgen
Successfully installed Faker-1.0.7 Pandas-0.24.2 numpy-1.16.4
pydbgen-1.0.5 python-dateutil-2.8.0 pytz-2019.1 six-1.12.0
text-unidecode-1.2
Because pydbgen requires Python 3.x, if you are trying to install pydbgen on Python 2.x, you will get an error message indicating pydbgen could not be found.
ERROR: Could not find a version that satisfies the requirement pydbgen
(from versions: none)
ERROR: No matching distribution found for pydbgen
Now we are ready to create some test data using the Python shell. Following the pydbgen documentation, we first have to create an object of class pydb before we can start generating data.
import pydbgen
from pydbgen import pydbgen
myDB = pydbgen.pydb()Let’s now assume we want to generate data for a table that has the following schema:
- name
- city
- license_plate
testdf=myDB.gen_dataframe(5,fields=['name','city','license_plate','email'
],real_email=False,phone_simple=True)
print(testdf)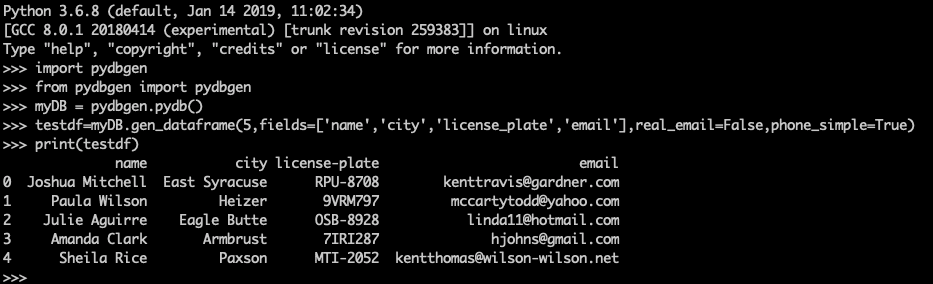
Generating five rows runs very quickly, so let’s run another test and with 100,000 rows. If you are brave enough to try, you most likely will find that it takes about 10 minutes. But what if we needed 1 million rows? As they say, “please do not try this at home.” It would take about two hours, which might still be acceptable if you are willing to spend the money and time. However, scaling it up to 1 billion rows wouldn’t be manageable at all, so I had to look for a different solution.
Snowflake Data Generation Functions
It occurred to me: Why not use Snowflake itself to generate the data I needed for testing Snowflake? Snowflake, with its very unique approach to scalability and elasticity, also supports a number of functions to generate data truly at scale.
Building Blocks
Generating synthetic data in Snowflake is straightforward and doesn’t require anything but SQL.
The first building block is the Snowflake generator function. The generator function creates rows of data based either on a specified target number of rows, a specified generation period (in seconds), or both. For the purpose of this test, let’s use only the row option.
The following statement creates 10 rows, each row having one column with the static value of 1.
select
1 as col1 from
table(generator(rowcount=>10));Of course, we don’t just want to generate static values of 1; so we need another building block to generate random values. And that’s what Snowflake’s random function does. Each time random() is called, it returns a random 64-bit integer value.
select
random() as col1
from table(generator(rowcount=>10));So far so good. But most likely, you want to generate more than one random value in a single SQL statement.
select
random() as col1
,random() as col2
from table(generator(rowcount=>10));Unfortunately, all the calls to the random() function return the same value in the same row.
This behavior is caused by how the random() function is “seeded.” The random() function takes one optional parameter, called the seed value. When you call the random() function without a seed value, a random seed value is assigned. When you call random() without a seed value, all calls are seeded with the same seed value and, therefore, they return the same value for the same row. Using unique seed values for each call to the random() function ensures that each call to random()returns a different value.
select
random(1) as col1
,random(2) as col2
from table(generator(rowcount=>10));At this point, I was able to generate a certain number of rows with multiple attributes of independent numeric values. The next step is to solve how to generate values that fall within a certain range of values (for example, between a minimum and a maximum value).
You can handle this using the next building block, which is Snowflake’s uniform function. The uniform() function takes three parameters: min to specify a minimum value, max to specify a maximum value, and gen, which is a generator expression. A static generator function produces the same value over and over within the range of min and max. Therefore, we will use the random() function, which generates random values, and as a result, the uniform() function will return random values between min and max.
select
uniform(1,10,random(1)) as col1
from table(generator(rowcount=>100));Lastly, we need a way to generate random strings of variable length. In Snowflake, random strings can be generated through the randstr function, which accepts two parameters. The first parameter is the length of the string, and the second is the generator expression. The same pattern also applies for the randstr() function. A static generator expression produces a static string. For that reason, we’ll use the random function to produce random strings through randstr().
The following statement puts all of these building blocks together.
select
randstr(uniform(3,10,random(1)),uniform(1,100,random(1))) as col1
from table(generator(rowcount=>10));The first parameter specifies the length of the string to be generated. In this case, it’s a random value with a range from 3 to 10; in other words, we are creating variable length strings of 3 to 10 characters. The second parameter, the generator expression, is a random number with a range of 1 to 100. This means we are generating 100 different strings with a variable length of 3 to 10 characters.
Please note that we are using the same seed value for both random() functions. Using the same seed value ensures that the same string value has the same length. Using different seed values would dramatically increase the number of unique string values.
Consider the following statement.
select count(distinct col1) from (
select
randstr(uniform(3,10,random(1)),uniform(1,1000,random(1))) as col1
from table(generator(rowcount=>10000)));The inner SELECT statement creates 1,000 distinct strings because the generator expression in the randstr() function creates 1,000 unique numbers. However, if you change the seed value of the first random() function to anything but 1, the statement creates more than 5,000 distinct values. This happens because for the same value of the generator function, you will have multiple (different) values for length.
Putting it all together
With all the building blocks in place, you now can craft a SQL statement to generate a data set, similar to the one above that was created using pydbgen.
create or replace table testdf as
select
randstr(uniform(10,30,random(1)),uniform(1,100000,random(1)))::varchar(30) as name
,randstr(uniform(10,30,random(2)),uniform(1,10000,random(2)))::varchar(30) as city
,randstr(10,uniform(1,100000,random(3)))::varchar(10) as license_plate
,randstr(uniform(10,30,random(4)),uniform(1,200000,random(4)))::varchar(30) as email
from table(generator(rowcount=>1000000000));The SQL statement above creates 1000000000 rows, casts it to the desired data type, and also specifies the number of distinct values per attribute (that is, it defines the distribution of values within the data set).
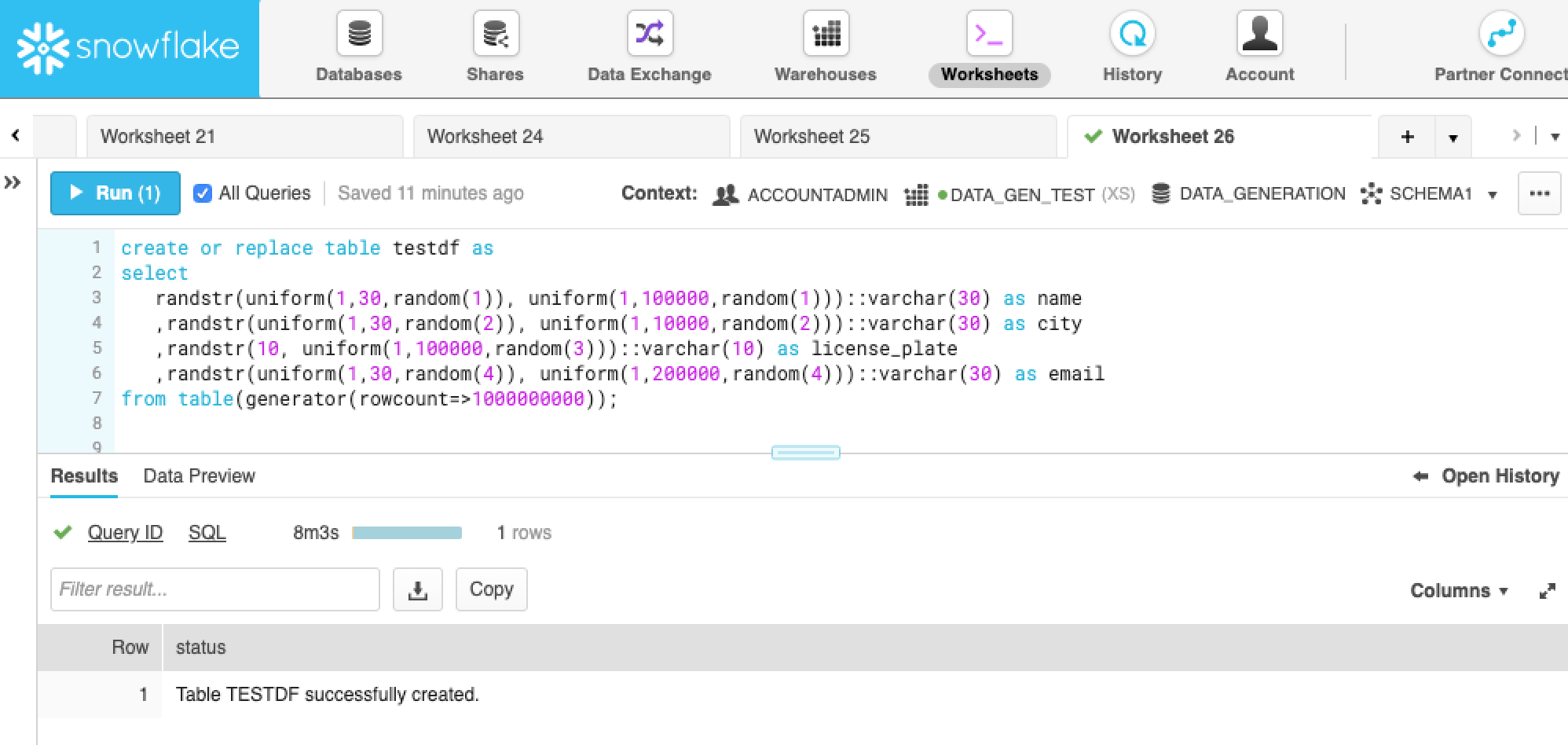
To recap, it took 10 minutes to create 100,000 rows for the schema above using pydbgen. Now we’re trying to generate 1 billion rows. Running the statement above on the smallest cluster in Snowflake takes about 8 minutes. If we extrapolate the runtime for the Python script, it would take approximately 87 days and would fail without a sufficient amount of RAM on your box. As you can see, Snowflake makes quite an improvement.
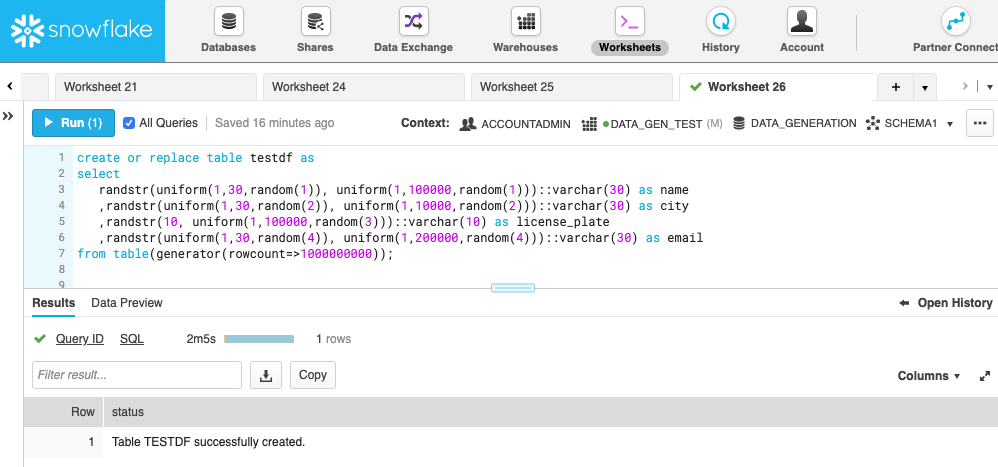
If you need to create even bigger data sets with wider tables, you can elastically increase the compute capacity, which reduces the runtime. To illustrate this behavior, let’s rerun the statement above on a Small size Snowflake cluster. Since a Small size cluster provides twice the amount of compute capacity as the default X-Small size cluster, it takes about half the time to generate the data. In my test, the statement completed in 4 minutes. If that’s not fast enough, try a Medium size cluster, which ran the statement in 2 minutes in my test.
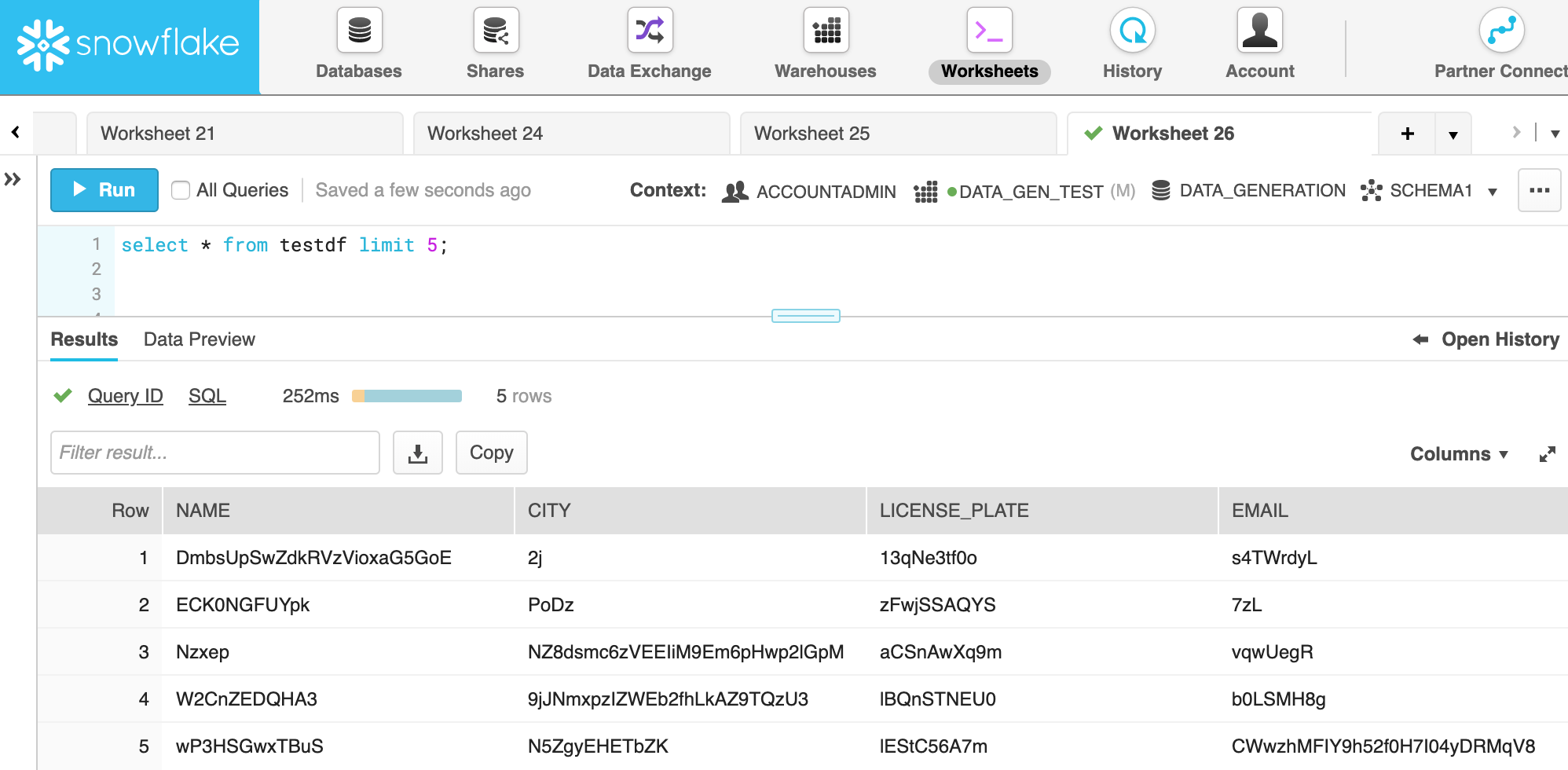
Lastly, here is a sample of the Snowflake dataset, which, as expected, is completely random.
Conclusion
Python has excellent support for generating synthetic data through packages such as pydbgen and Faker. Pydbgen supports generating data for basic data types such as number, string, and date, as well as for conceptual types such as SSN, license plate, email, and more. However, creating data at scale requires technology that’s much more scalable and elastic. Snowflake can generate billions of rows in minutes and scales nearly linearly for sufficiently big data sets. Doubling the size of the cluster, for example, resizing the cluster from X-Small to Small, cuts the execution time in half.
In part 2 of this post, I’ll demonstrate how to handle additional data types like date and timestamps and how to automate the generation of the SQL statements for generating synthetic data purely based on a schema (tables, columns, and data types) and statistical information about data distribution. I’ll also outline how to generate SQL not only for one table but for a complete schema as well as cover strategies for handling foreign key relationships.


