
APR 02, 2025|Lettura: 5 min

Apache Iceberg™ continua a essere il formato standard di settore per lo storage interoperabile. L’ultima specifica delle tabelle Iceberg v3, che abbiamo celebrato come un traguardo per la community open source lo scorso giugno, ha ulteriormente consolidato il suo ruolo come formato di storage di riferimento. Siamo entusiasti di annunciare che il supporto per Iceberg v3 è ora disponibile in public preview su Snowflake.
In questo articolo spieghiamo come il supporto a Iceberg v3 rappresenti un passo fondamentale per una strategia dati aperta e interoperabile, abilitando direttamente casi d’uso moderni con le prestazioni superiori di Snowflake. Che tu stia standardizzando su tabelle Apache Iceberg™ gestite da Snowflake o gestite esternamente, hai ora accesso in public preview a funzionalità come pipeline complesse di change data capture (CDC) con row lineage e semplicità dichiarativa, oltre alla possibilità di utilizzare variant come tipo di dato semi-strutturato flessibile con prestazioni di query strutturate. Snowflake supporta inoltre deletion vectors, valori predefiniti e dati geospaziali (geometry e geography) e timestamp a livello di nanosecondi, ampliando ulteriormente i casi d’uso.
Sebbene Iceberg v3 introduca potenti funzionalità di formato tabellare per casi d’uso moderni, una reale adozione enterprise richiede una piattaforma che garantisca governance unificata, sicurezza e controlli di business continuity. In questo articolo vedremo anche come l’AI Data Cloud Snowflake, basata su Horizon Catalog, offra una piattaforma sicura, coerente e altamente disponibile per il tuo lakehouse aperto e interoperabile, rendendo le tabelle v3 pronte per la produzione fin dal primo giorno.
Approfondisci subito i dettagli tecnici nella nostra documentazione sul supporto a Iceberg v3 oppure prova direttamente questa guida.
Iceberg v3 introduce metadati nativi di row lineage. Nelle versioni precedenti di Iceberg non esisteva un metodo condiviso e definitivo per identificare se le modifiche a una tabella riguardassero nuovi record, record eliminati o record aggiornati, limitando o impedendo i casi d’uso CDC. Con row lineage obbligatoria nelle operazioni di scrittura sulle tabelle Iceberg v3, esiste ora un riferimento comune per comprendere quali modifiche sono state apportate e a quali record.
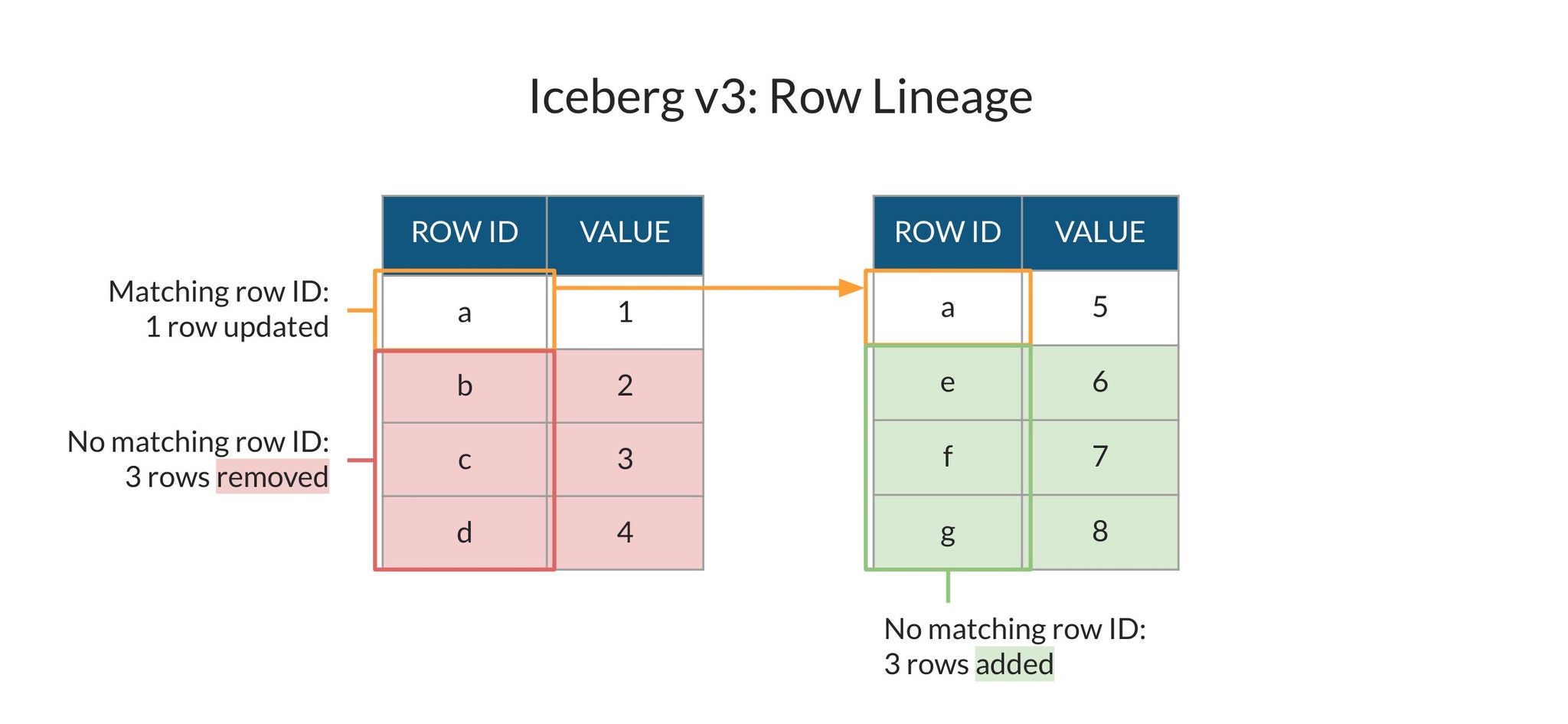
Snowflake sfrutta i metadati di row lineage dietro le quinte di Dynamic Iceberg Tables e Streams su tabelle Iceberg v3 per abilitare casi d’uso CDC con elaborazione incrementale efficiente direttamente sul tuo data lake open. In particolare, le Dynamic Iceberg Tables semplificano i casi d’uso CDC grazie a sintassi dichiarativa, orchestrazione automatica e aggiornamenti intelligenti ed efficienti in termini di costi. Il supporto Snowflake per row lineage include operazioni INSERT, UPDATE, DELETE e MERGE sia per tabelle Iceberg gestite da Snowflake sia per quelle gestite esternamente.
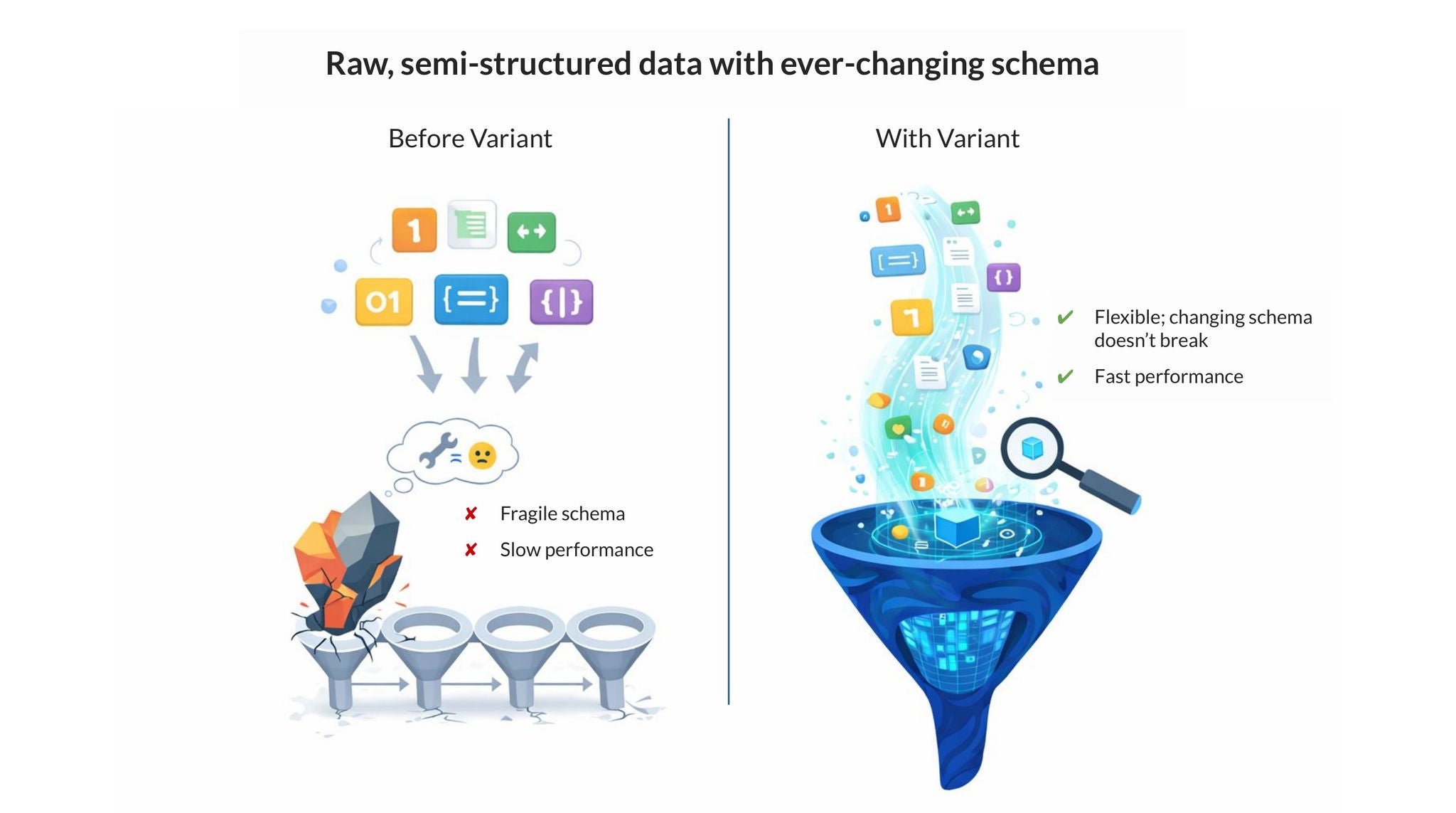
Prima dell’introduzione del tipo di dato variant in Iceberg v3, la gestione dei dati semi-strutturati nelle tabelle Iceberg comportava un compromesso tra efficienza e flessibilità, costringendo a memorizzare JSON come stringhe, con parsing completo lento e costoso in fase di query, oppure come schemi rigidi e molto estesi con migliaia di colonne nullable, con frequenti modifiche di schema e metadati sovradimensionati. Con l’introduzione di variant, è ora possibile memorizzare dati eterogenei e profondamente annidati in un’unica colonna tramite una codifica binaria ad alte prestazioni. Questa codifica consente ai motori di escludere file non rilevanti e applicare filtri ai sotto-campi senza analizzare l’intero blob, avvicinando le prestazioni delle colonne strutturate alla flessibilità di JSON.
Il supporto a Iceberg v3 per il tipo di dato variant rappresenta un’importante svolta per il settore. Mi aspetto un forte incremento di soluzioni di osservabilità basate su Iceberg come conseguenza diretta. La consolidata esperienza Snowflake nella subcolumnarizzazione del variant su scala enterprise li rende la scelta naturale per alimentare queste soluzioni, ora anche con Iceberg nel mix.”
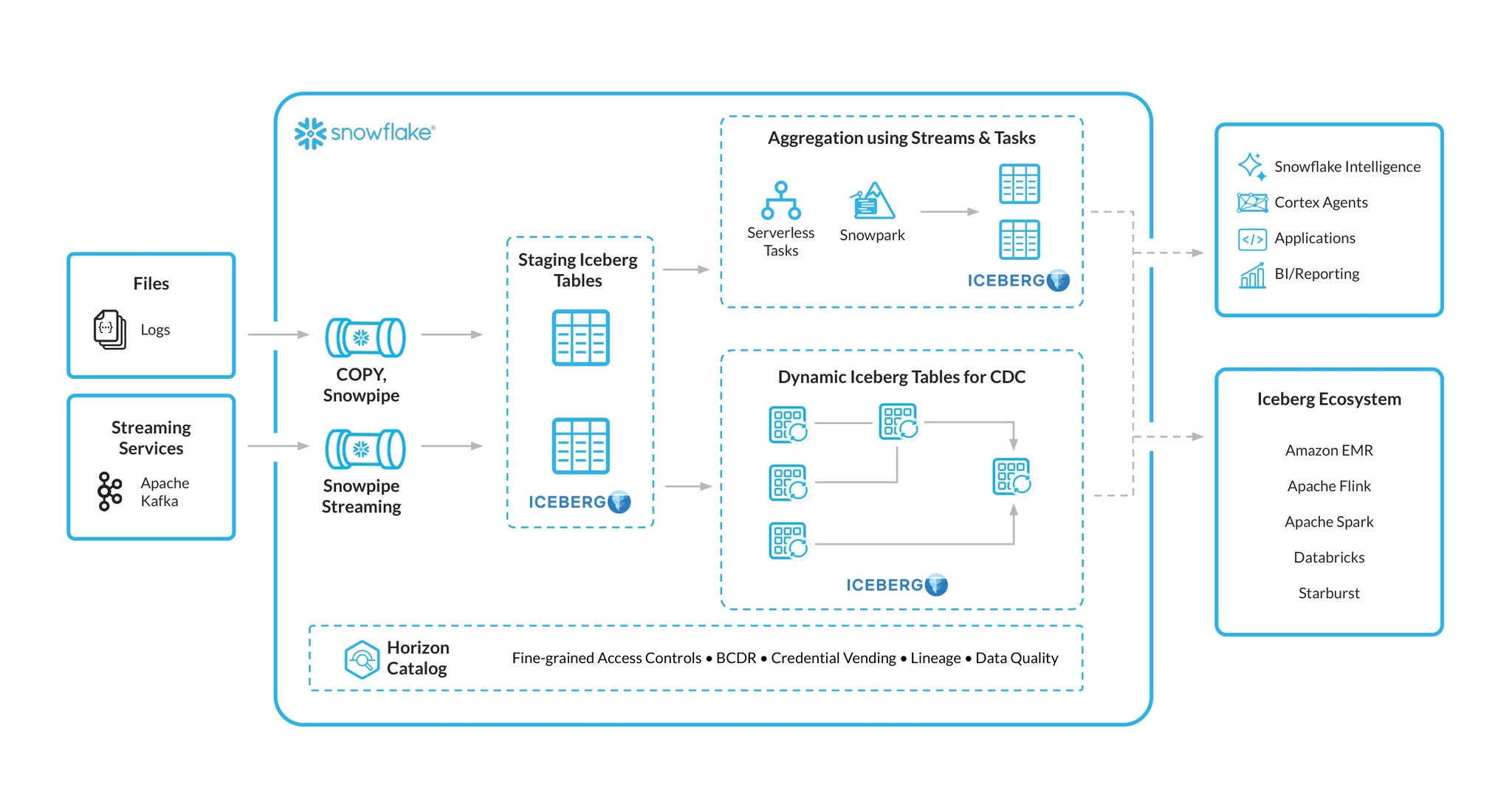
Il supporto consolidato di Snowflake per il tipo di dato variant si estende ora alle tabelle Iceberg con v3, includendo pipeline batch (COPY), microbatch (Snowpipe) e streaming (Snowpipe Streaming) direttamente nelle tabelle Iceberg con “shredding” automatico per prestazioni di lettura altamente ottimizzate.
Con il supporto a timestamp con precisione al nanosecondo, le tabelle Iceberg v3 raggiungono la stessa precisione temporale delle tabelle native Snowflake. Questo livello di precisione è spesso richiesto in casi d’uso come dati finanziari ad alta frequenza o dati provenienti da dispositivi Internet of Things. Le funzionalità avanzate di serie temporali Snowflake, come ASOF JOIN e ML Forecasting, si estendono anche alle tabelle Iceberg.
I tipi di dato geometry e geography sono ora supportati in Iceberg v3, in linea con i tipi di dato geospaziali delle tabelle native Snowflake. Snowflake sfrutta bounding box e metadati per un’esclusione efficiente nei casi d’uso di analisi geospaziale, grazie a un’ampia gamma di funzioni geospaziali.
Iceberg offre opzioni come copy-on-write e merge-on-read per ottimizzare le prestazioni in base alle esigenze di ciascun caso d’uso. Tuttavia, i delete posizionali della versione v2 comportano in genere un compromesso prestazionale legato alla granularità e al numero di file di delete. Iceberg v3 migliora questo aspetto con deletion vectors come modalità predefinita per merge-on-read, memorizzando la granularità a livello di file in un numero inferiore di file consolidati. Snowflake supporta ora i deletion vectors sia per letture sia scritture su tabelle Iceberg v3, in cataloghi gestiti da Snowflake o esterni, migliorando le prestazioni delle pipeline con frequenti update, delete e merge.
Horizon Catalog unifica discovery, governance e collaborazione tra gli asset dell’organizzazione, incluse le tabelle Iceberg, con lineage integrata, policy e controlli di sicurezza. Horizon Catalog espone le tabelle Iceberg tramite un’interfaccia REST Iceberg standardizzata, basata su Apache Polaris™ integrato in Horizon, consentendo ai motori esterni di leggere tabelle Iceberg gestite da Snowflake, incluse ora quelle v3.
Horizon ti aiuta a garantire che le tabelle Iceberg v3 siano governate e interoperabili tra i tuoi strumenti. Ciò include la possibilità di fornire credenziali di storage temporanee e con ambito limitato in fase di esecuzione, sempre più standard di settore per un’integrazione sicura tra motori, cataloghi e storage di oggetti.
Inoltre, le policy di protezione dei dati come row access e column masking sulle tabelle Iceberg, introdotte inizialmente su v2 e ora applicate anche a v3, sono applicate quando si accede tramite Apache Spark utilizzando Snowflake Connector for Apache Spark™ (GA).
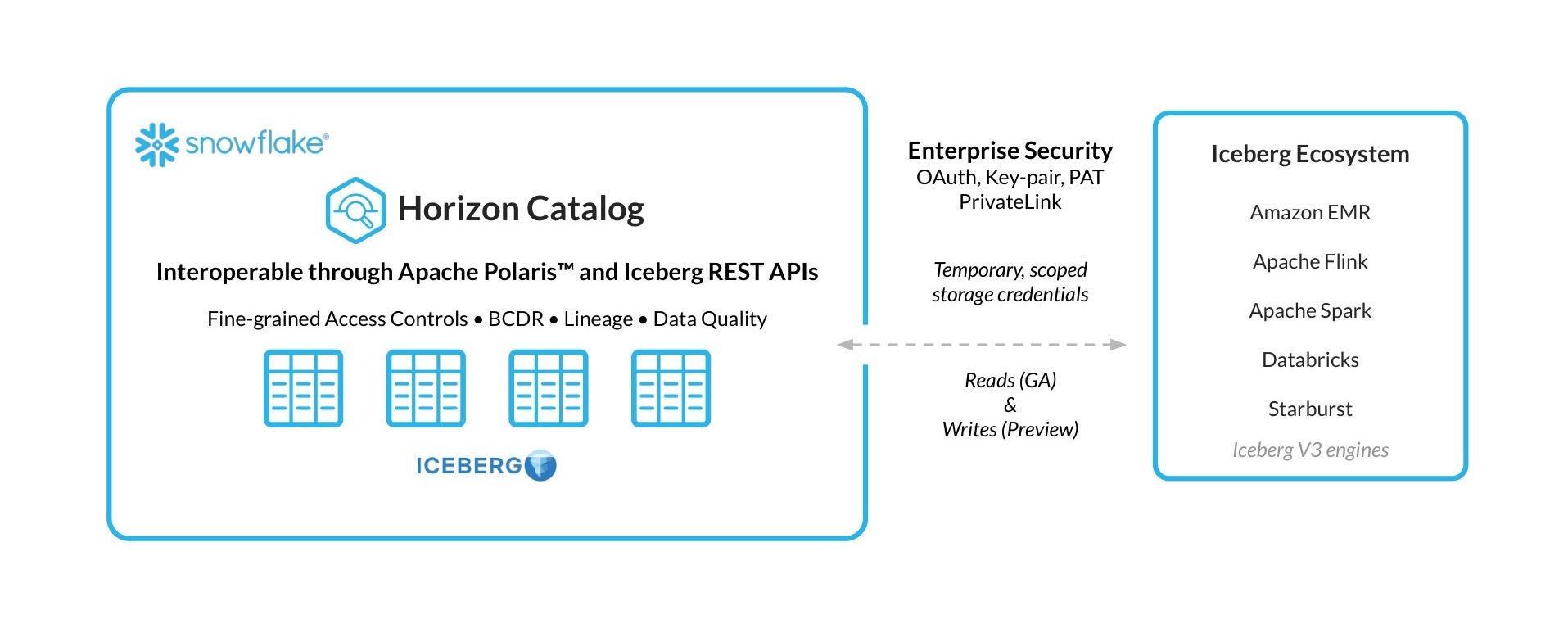
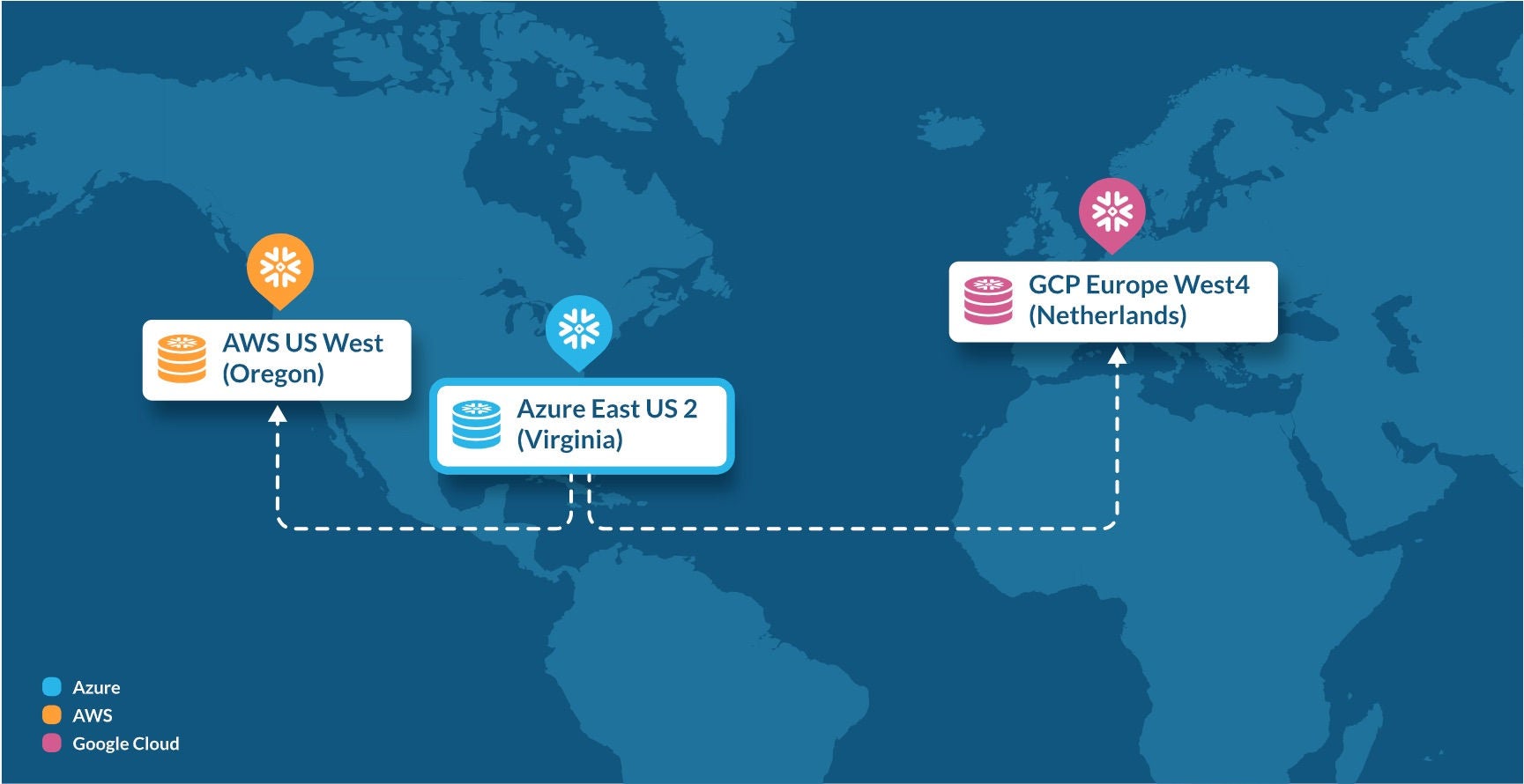
Horizon Catalog è inoltre fondamentale per abilitare resilienza cross-region e cross-cloud. La business continuity e il disaster recovery di livello enterprise Snowflake (BCDR) includono ora il supporto alla replica delle tabelle Iceberg v3 gestite da Snowflake verso una regione o un cloud secondario con piena integrità e coerenza in caso di failover.
Esistono due dimensioni principali per valutare quanto una piattaforma sia allineata a una strategia di interoperabilità di lungo periodo:
Questo articolo del blog approfondisce il tema, ma a differenza di molte altre piattaforme ancora solo parzialmente interoperabili o basate su meccanismi di autorizzazione meno sicuri, Snowflake offre entrambe le capacità.
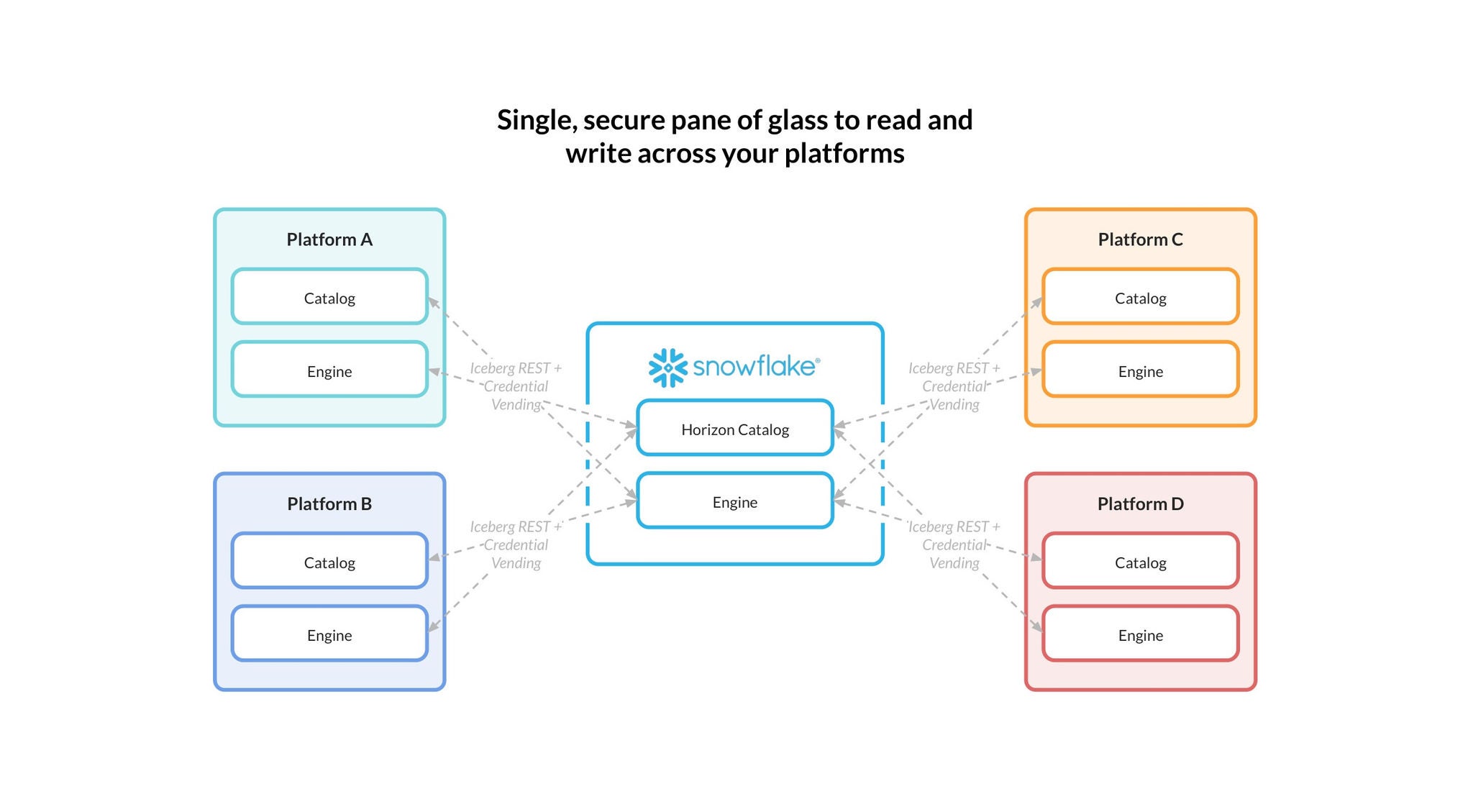
La public preview del supporto per Iceberg v3 su Snowflake include la possibilità di leggere e scrivere su qualsiasi catalogo Iceberg REST che supporti Iceberg v3 tramite catalog integration, inclusa l’opzione di utilizzare catalog-vended credentials.
Il supporto a Iceberg v3 è profondamente integrato nell’intera piattaforma Snowflake, consentendoti di beneficiare di governance unificata su dati interoperabili lungo tutto il loro ciclo di vita, dall’ingestione dei dati grezzi alla trasformazione, ottimizzazione delle tabelle, governance, collaborazione, analisi e applicazioni di agentic AI.
In definitiva, questo amplia il potenziale del tuo lakehouse, abilitando funzionalità prima troppo complesse o semplicemente irraggiungibili. Automatizzando workflow critici come BCDR, controlli di accesso granulari su dati sensibili, pipeline CDC e ingestione in streaming, i team possono smettere di gestire compromessi tipici dei lakehouse frammentati. E Snowflake è al tuo fianco in ogni fase del percorso.
Che aspetti a iniziare? Consulta questa guida pratica per iniziare oggi stesso a sviluppare con Iceberg v3 su Snowflake e scopri di più nella documentazione della public preview.





