Fastest Speculative Decoding in vLLM with Arctic Inference and Arctic Training

Authors: Ye Wang, Gabriele Oliaro, Jaeseong Lee, Yuxiong He, Aurick Qiao (co-lead), Samyam Rajbhandari (co-lead)
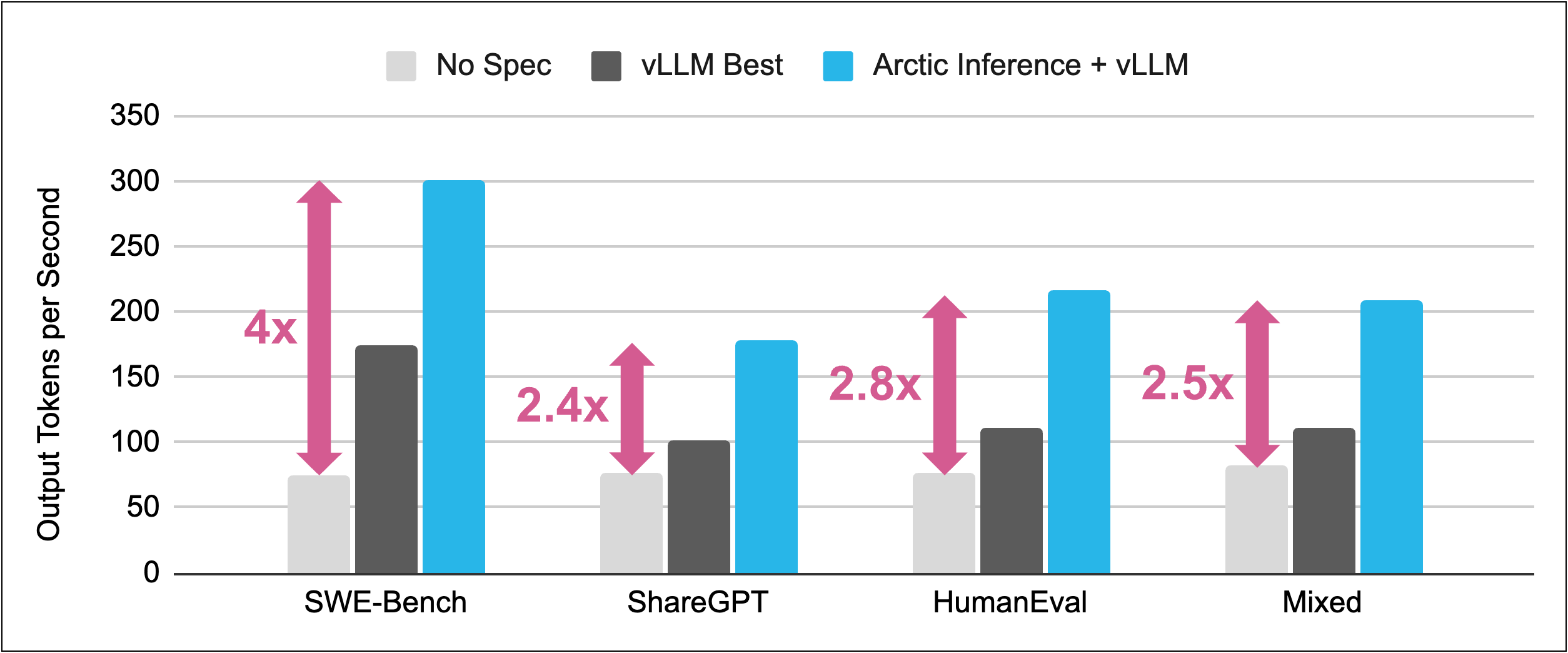
In this blog, we present our recent work in speculative decoding, and how Arctic Inference + vLLM can achieve 4x faster inference for LLM agents (averaged across SWE-Bench tasks) and up to 2.8x faster decoding for open-ended interactive workloads, when compared with vLLM without speculation.
At the time of publishing, Arctic Inference is the fastest speculative decoding solution for vLLM (v0.8.4), significantly surpassing both the native N-gram and EAGLE speculators in vLLM v1 across several workloads.
This work is released in the following open source projects from Snowflake AI Research:
Arctic Inference: a vLLM-compatible plugin with fast speculation and verification
- Arctic Training: a speculator training framework with reproducible YAML-based recipes
- Pretrained speculators for Llama-3.1-8B, Llama-3.1-70B, Llama-3.3-70B, and Qwen2.5-32B
The rest of this blog presents an overview of what we built how to get started and a deep dive into methodology. If you would like to cite our work, check out our BibTeX citation below.
Why traditional speculative decoding falls short in the real world
Generation latency remains the primary bottleneck in modern LLM applications — slowing down chat assistants, coding tools and multistep agentic workflows. Long wait times not only reduce productivity, they frustrate users and limit the practical use of emerging agentic applications.
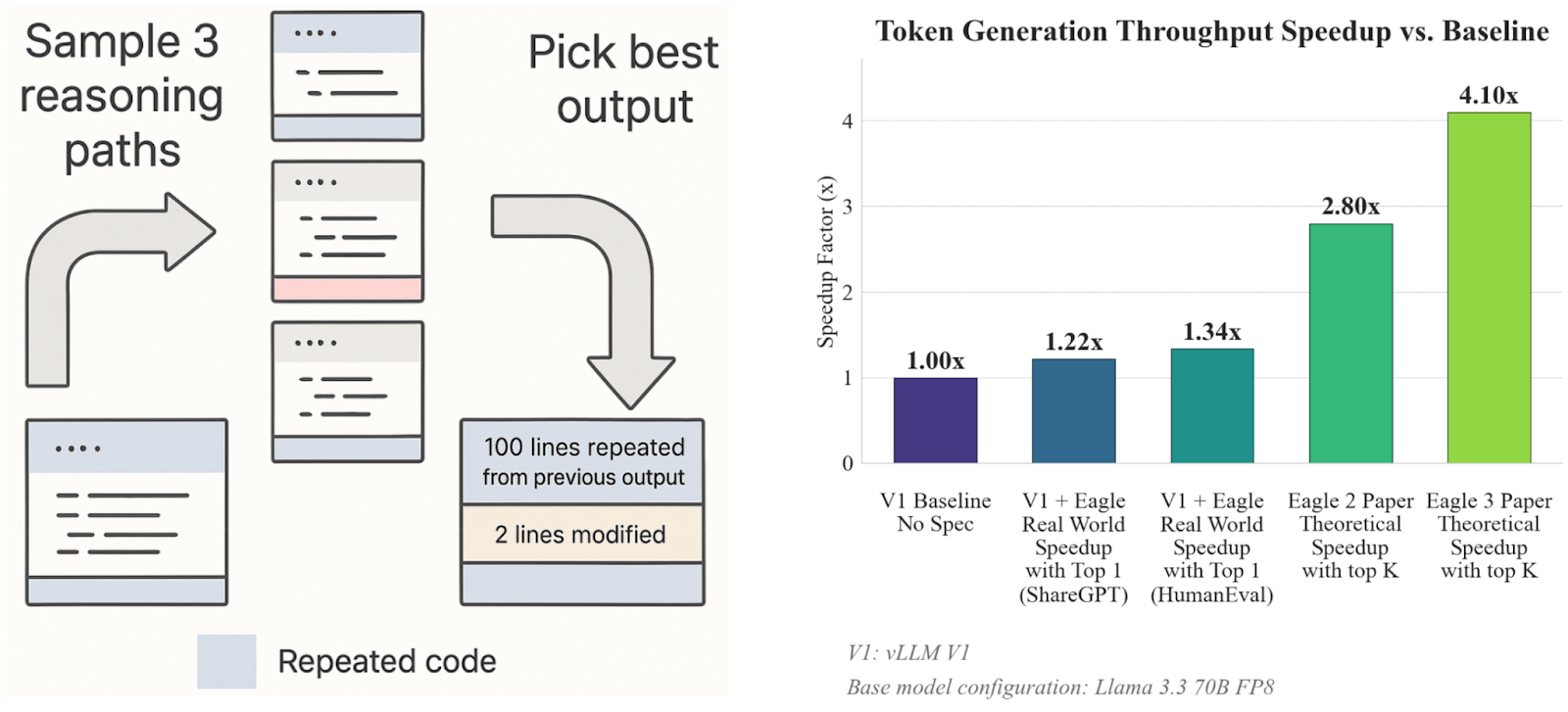
Speculative decoding offers a solution by predicting and validating multiple tokens in parallel, slashing latency for chatbots, coding assistants and complex agentic loops. However, existing open source speculative decoding solutions have several shortcomings (Figure 2):
- They fail to fully exploit the repetitive generation patterns present in many emerging agentic applications (e.g., self-reflection loops, multiple reasoning paths) because they only predict a small number of tokens in advance even when there are many obvious repeated tokens.
- They lack a simple and standardized framework for training custom draft models and bringing them seamlessly to production-serving, which is necessary for speculating non-repetitive generation patterns common in open-ended conversations. Additionally, system-level overheads prevent draft models from achieving their theoretical peak speedups.
Introducing enhanced speculative decoding with Arctic Inference and Arctic Training
We’re excited to introduce enhanced speculative decoding capabilities, for our Arctic Inference and Arctic Training ecosystems, that solve these challenges with two set of improvements:
Suffix decoding for repetitive (i.e., agentic) generation: It unlocks efficient speculation across longer-token sequences, at a blazing 20 microseconds per speculated token on the CPU, without needing a draft model.
Speculative training and inference pipeline for non-repetitive generation: It provides easy-to-use training pipelines for creating powerful but lightweight draft models. It also implements an optimized speculation code path that achieves up to 91% of the theoretical maximum speedup in vLLM.
Finally, we combined both suffix decoding and optimized draft model speculation to realize the best of both worlds. These capabilities dramatically reduce generation latency across repetitive and non-repetitive workloads (see Figure 1), making Llama 3.3 70B generation up to:
4x faster for agentic tasks like SWE-Bench, resulting in 1.8-4.5x faster end-to-end task completion
2.8x faster for open conversations like ShareGPT and code generation like HumanEval
1.8x faster than the best available open source alternative in vLLM
Here’s how you can get started using Arctic Inference’s enhanced speculative decoding pipeline in your existing vLLM deployment. You’ll also learn how to customize your own draft model with Arctic Training.
Deep dive into our methodology
For readers who would like to go deeper into the technical details, the rest of this blog will cover some background on speculative decoding, detailed architecture of our solutions for both repetitive and non-repetitive tasks, and real-world benchmarks across SWE-Bench, ShareGPT and HumanEval data sets.
What is speculative decoding?
Speculative decoding works by using a smaller, faster model to speculate or propose potential future tokens, which are then efficiently checked by the main, larger model.
We can break down the speculative decoding process into three components:
Proposer: This can be a smaller and cheaper language model (known as a draft model) that rapidly generates a sequence of candidate tokens (e.g., 3 to 5 tokens). It can also be model-free and generate candidate tokens from a different source (such as n-grams from the prompt itself).
Scorer (base model): This is the large, high-performance LLM whose output quality we want to preserve. Instead of generating just one token, it takes the sequence of draft tokens proposed by the Proposer and evaluates them all in parallel within a single computational forward pass.
Verifier (rejection sampling): This is a step that determines which tokens are accepted.
Acceptance rate and its implications
The acceptance rate is a key metric used to measure how effective the speculative decoding process is. This metric calculates the average number or percentage of draft tokens that the Proposer suggests, which are then validated and accepted by the Verifier during each decoding step.
A high acceptance rate signifies that the draft model is adept at predicting the output of the target model. This translates to a greater number of tokens being generated per verification step, culminating in an enhanced speedup. Conversely, a low acceptance rate implies that the speculations of the draft model are frequently incorrect, leading to inefficiencies in the decoding process.
Balancing acceptance rate vs. draft overhead
The relationship between acceptance rate and computational resources underscores a fundamental trade-off in speculative decoding. While a higher acceptance rate is desirable for faster decoding, it is equally important to minimize the computational overhead of producing the draft tokens. Therefore, to achieve the best performance, it is critical to develop a speculator that can balance the acceptance rate and computational resources based on model and workload characteristics.
A Simple Example
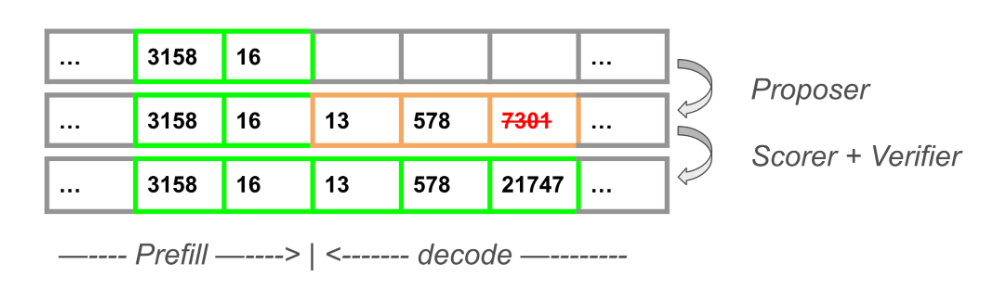
Figure 3 demonstrates how speculative decoding functions in a single decoding step. Using the states generated from the prefill step, the Proposer speculates three additional tokens: 13, 578 and 7301. The Scorer then runs the base model and in parallel obtains the token IDs of the last verified token plus the speculated tokens, which are 16, 13, 578, and 7301. Using the sampling strategy, the Verifier determines that 13 and 578 are acceptable and appends 21747 as the last verified token.
In this instance, the speculative decoding step accepts two out of three predicted tokens, resulting in a 66.7% acceptance rate.
Let us now review the enhanced speculative decoding capabilities for both repetitive and non-repetitive generation.
Suffix decoding for repetitive (agentic) generation
Many agentic workflows consist of iterative self-reflection loops and/or sampling multiple reasoning paths, containing predictable and repeated token sequences. But most speculative approaches only predict a small handful of tokens at a time and do not fully exploit the opportunity to accelerate these naturally repetitive tasks.
We develop a novel lightweight speculative approach called Suffix Decoding to address this limitation. It exploits repetitive textual structures by dynamically building speculative sequences based on historical outputs and current inputs. Instead of speculating a fixed number of tokens, Suffix Decoding adaptively identifies the matching sequences that are highly likely to occur next.
At its core, Suffix Decoding maintains a compact cache of previously generated sequences, using a data structure called a suffix tree. A suffix tree efficiently indexes and matches repeating token patterns from both historical generations and the current input prompt, enabling rapid and adaptive speculation. With this optimized structure, Suffix Decoding can speculate tokens extremely quickly — on the order of 20 microseconds per token — enabling adaptive speculation of significantly longer sequences than previously possible.
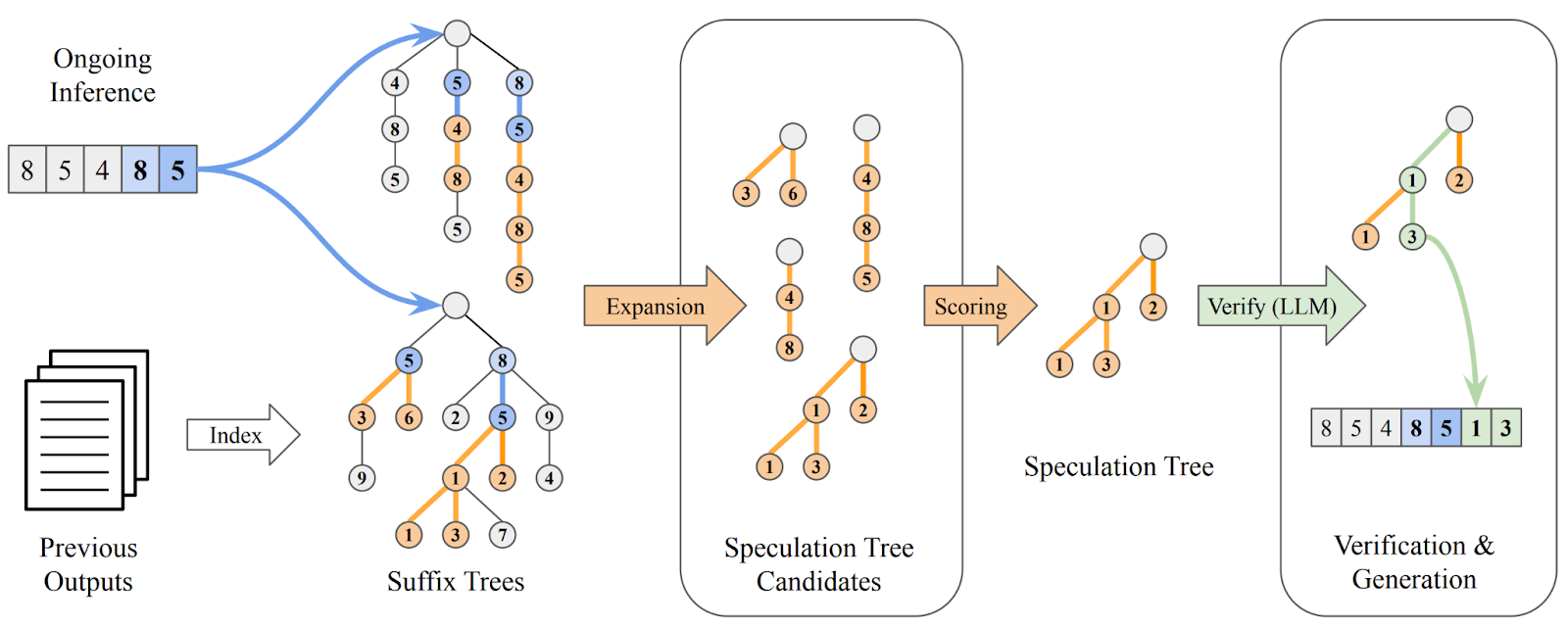
In practice, Suffix Decoding (Figure 4) works as follows:
Suffix tree construction: Historical outputs from past generations and the current prompt context are decomposed into token suffixes and indexed into a compact suffix tree, allowing very rapid lookups of repeating patterns.
Adaptive pattern matching for speculation: At inference time, Suffix Decoding rapidly matches the current token sequence against the suffix tree, adaptively identifying the longest speculative sequences that historically followed similar contexts.
Frequency-based expansion: Each speculative candidate is prioritized by empirical likelihood (frequency-based scoring), enabling speculative expansions to remain highly accurate even for longer sequences.
Parallel verification: Speculated token sequences are efficiently verified in a single forward pass by the primary LLM model, accepting correct predictions and discarding incorrect ones with minimal computational overhead.
For further details on how Suffix Decoding works, see our paper.
Suffix Decoding significantly outperforms existing speculative decoding techniques for agentic applications that involve repetitive LLM queries, delivering 1.8x-4.5x speedups on end-to-end SWE-Bench task completion (generation and performing actions). A more thorough evaluation is presented near the end of this blog.
Improving speculation for non-repetitive generation
Easy-to-use speculator training recipes
Draft models for speculative decoding are a well-established method, particularly useful in open-ended conversational settings with less repetition that can be exploited. However, adoption has been slowed by the lack of standardized training tools. Our Arctic Training framework addresses this gap by offering accessible, standardized training recipes. Each recipe includes the data set, hyperparameters and model architecture bundled into a single YAML file, simplifying reproducibility and result sharing.
While the framework supports arbitrary draft model architectures, we focus on MLP-Speculator-like designs due to their simplicity and strong balance between acceptance rate and inference latency optimization.
We provide end-to-end recipes, including data generation, for two draft model types:
- MLP-based speculators (Figure 5a): Simple feed-forward models using LLM final hidden states and last token IDs, similar to RNNs by passing hidden states between steps.
- LSTM-based speculators (Figure 5b): An extended version of the MLP speculator with standard LSTM gates (forget, input, output, cell), to demonstrate the flexibility of our training pipeline.
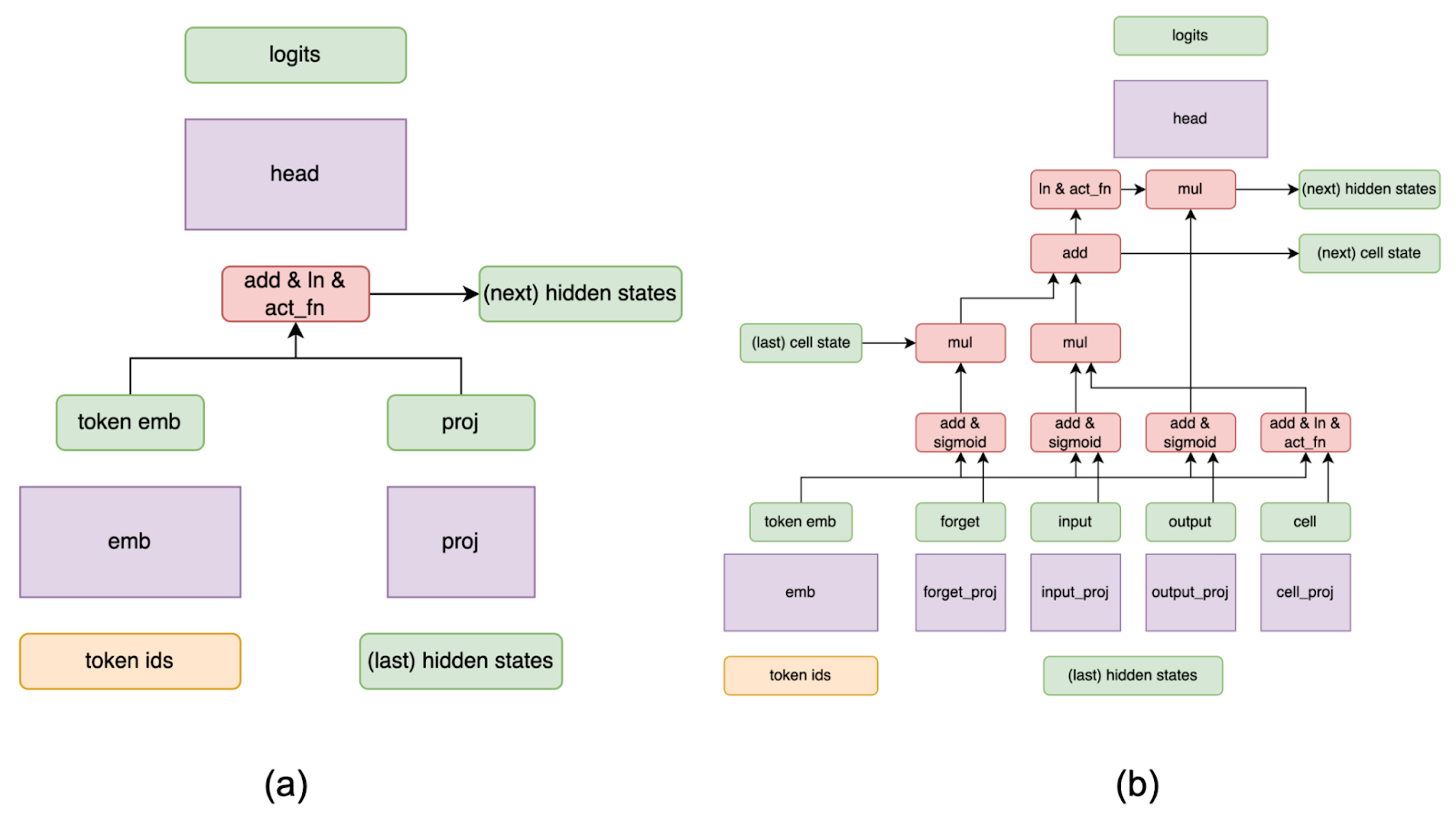
| Parameter counts (B) | Acceptance rate | |
|---|---|---|
| MLP-Speculator (original) | 2.1 | 13.7% |
| MLP-Speculator (ours) | 2.1 | 42.7% |
| LSTM-Speculator (ours) | 1.8 | 44.5% |
Table 1. Comparison of speculators with three additional heads on Llama 3.1-70B-Instruct. We evaluated the acceptance rate with the ShareGPT data set.
With Arctic Training, we achieve significantly stronger lightweight speculators compared to existing open source baselines. We use the same architecture, but instead of a two-stage training — on a nonsynthetic data set and then on target model-generated synthetic data — we use a single-stage training just on generated synthetic data using UltraChat and MagiCoder prompts over a longer training horizon. This allows us to get a 3.1x higher acceptance rate. Our LSTM-Speculator further improves efficiency, achieving a higher acceptance rate with fewer parameters. All training pipelines are fully reproducible with our recipes.
Optimized speculative inference pipeline
The speculative decoding pipeline includes a Proposer (speculator), Scorer and Verifier. To speed it up, we optimized the speculator and verifier, and reduced pipeline overhead holistically.
Speculator optimizations:
FP8 quantization: Reduces memory bandwidth bottleneck in linear layers, lowering proposer latency.
Tensor parallelism (TP): Splits computation across GPUs to reduce per-GPU load and improve latency and throughput.
Communication optimization: Instead of gathering full logits across GPUs, each GPU computes a local Top-K first, then allGather operates only on Top-K results, massively cutting communication overhead.
Initial: Logits(Sharded) -> AllGather -> Logits(Global) -> TopK(Global)Optimized: Logits(Sharded) -> Topk(Sharded) -> AllGather -> TopK(Global)
CUDA graphs: Captures the entire speculative model and inference loop into one CUDA graph, reducing kernel launch overhead.
Together, these optimizations reduce a MLP-based proposer latency from ~1.47ms/token to ~0.47ms/token (~3.1x improvement).
Verifier optimizations:
Switched from rejection sampling to greedy verification (accept tokens only if they match greedy decoding), ensuring outputs are identical to the base model without lowering acceptance rate.
Further speedup was achieved with a lightweight CUDA kernel, reducing verifier latency from ~1.34ms to ~0.38ms (~3.5× improvement) on top of vLLM V0.
Holistic improvements:
Simplified speculative decoding logic (e.g., replacing sampling with Top-K in the MLP-Speculator, removing metadata and unnecessary data structures) to cut GPU/CPU overhead.
Overall, these changes deliver up to 1.42x end-to-end speedup over vLLM V0 using the same speculative model, achieving up to 91% of the theoretical speculative decoding speedup, even atop highly optimized vLLM baselines.
Combining Suffix Decoding and MLP/LSTM-Speculator
So far, we have discussed Suffix Decoding’s strength for speculating repetitive token sequences common in agentic applications, and training MLP- and LSTM-based draft models for nonrepetitive sequences common in open-ended conversational use cases. However, in the real world, LLM deployments often need to deal with both types of generations simultaneously.
Luckily, we can combine both Suffix Decoding and draft models. This can be done using Suffix Decoding’s existing scoring function, which it uses to select candidate tokens. In short, the score given to candidate sequences is an empirical estimate of the number of tokens that would be accepted according to historical patterns (more details in the paper).
Thus, we can decide between Suffix Decoding and draft model speculation for each sequence using a simple rule:
Generate candidate tokens using Suffix Decoding.
If the score is less than the max speculation tokens using a draft model, then discard the candidate tokens and use the draft model instead.
Otherwise, skip the draft model and use the candidate tokens from Suffix Decoding.
Performance evaluation
First, we demonstrate that by leveraging Suffix Decoding, we achieve state-of-the-art generation performance for agentic workloads, like coding agents from Openhands, enabling end-to-end speedup of up to 1.8-4.5x across the different subtasks in SWE-Bench.
Second, we show that for open-ended conversations (ShareGPT) and general coding (HumanEval) tasks for Llama 3.1 70B, we achieve up to 2.45x speedup over optimized baseline implementation (nonspeculative decoding), and up to 1.82x faster generation speed, compared to the best available speculative decoding offering in vLLM.
Accelerating coding agents via Suffix Decoding
We designed Suffix Decoding to effectively speculate long sequences, which are frequent opportunities in agentic tasks. To demonstrate this, let’s consider the CodeAct 2.1 agent from OpenHands, which achieves state-of-the-art performance on SWE-Bench (resolving real-world GitHub issues).
A CodeAct agent can perform a combination of LLM queries and actions:
Receive instructions and feedback conversationally from the user.
Generate code and execute that code against a sandboxed environment.
Observe the outcomes of executing the generated code.
Respond to the user conversationally.
The agent is backed by a custom-trained LLM (all-hands/openhands-lm-32b-v0.1-ep3), which is repeatedly queried for reasoning/planning to decide the best next step based on prior instructions, feedback and code-execution outcomes. In our benchmarks, these LLM queries take the majority of the total time needed to complete various SWE-Bench tasks.
To accelerate the CodeAct agent, we employ Suffix Decoding on the core reasoning and planning queries to the LLM. We also compared our implementation of Suffix Decoding with the other popular methods in vLLM: (1) prompt-lookup decoding (e.g., ngram), and (2) vanilla decoding (no speculation). For EAGLE-3, a draft model trained for the agent’s custom LLM is not available, so we could not compare against it. The results are in Figure 6.
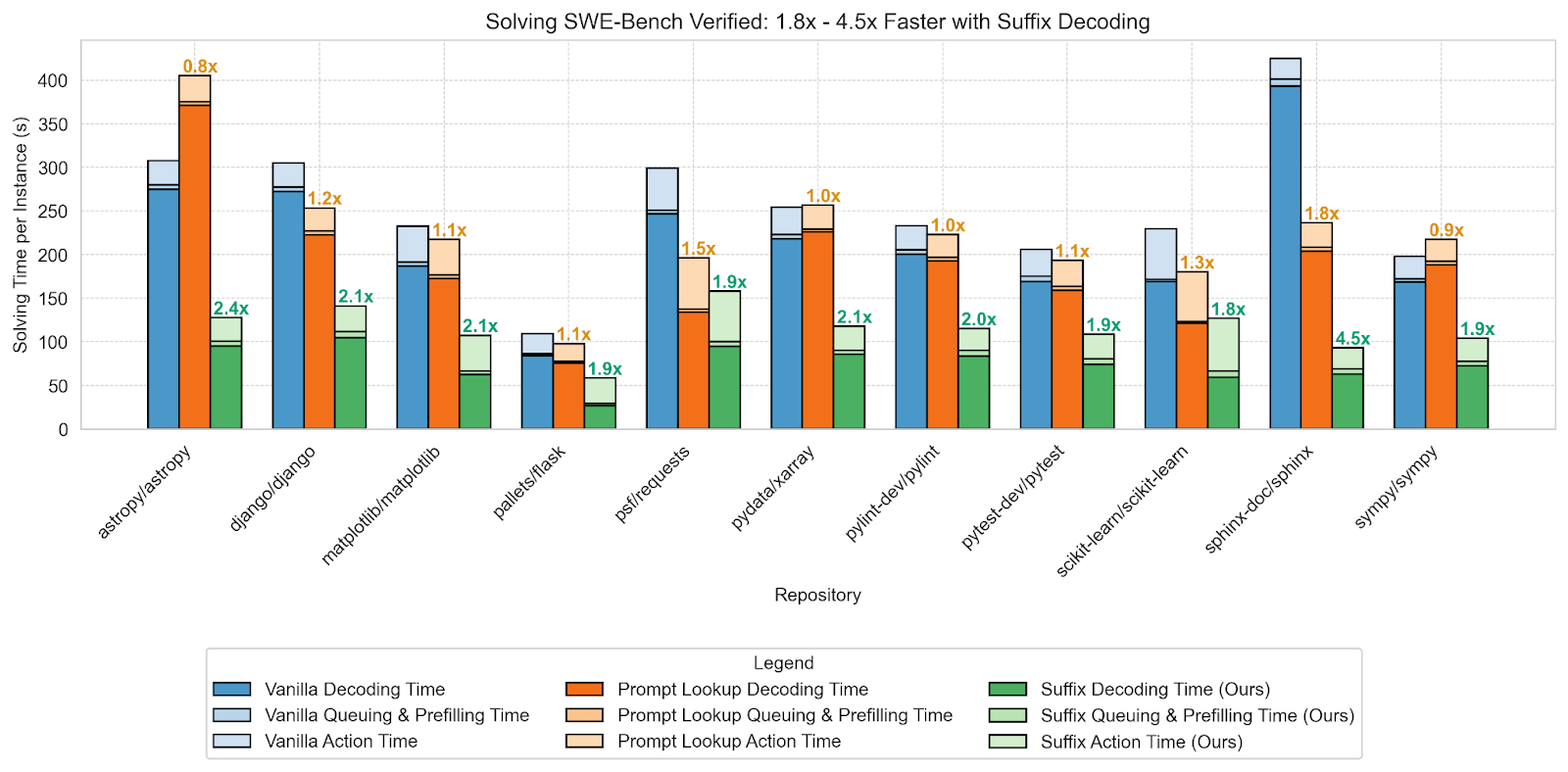
Suffix Decoding reduces the decoding time over vanilla decoding by 2.3x-6.3x, which leads to a corresponding 1.8x-4.5x reduction in end-to-end completion time across various SWE-Bench tasks. At the time of this blog, Suffix Decoding implemented in Arctic Inference is the fastest available option for running SWE-Bench with vLLM, being 1.4x-3.9x faster than prompt-lookup decoding (e.g., N-gram speculation in vLLM). At the same time, we verified that Suffix Decoding matches or exceeds the advertised 37%+ resolve rate of the original agent.
We obtain these speedups by exploiting the substantial repetition in the LLM reasoning queries. This repetition arises naturally from (see Figure 2):
Code corrections due to execution feedback. Often, generated code will contain bugs that are fixed with minor modifications. The newly generated code is highly repetitive with the previously generated code.
Sampling multiple reasoning paths. To enhance reasoning ability, the agent will query the LLM multiple times during each step and choose the best response. Although these reasoning paths are different, they still contain substantial repetition with each other.
Accelerating open-ended conversations and coding tasks
We evaluated the ability of our speculative decoding enhancements to accelerate open-ended conversations and coding tasks by benchmarking average generation throughput on ShareGPT and HumanEval (Figure 7), using Llama 3.1 70B as the target model. We used MLP/LSTM-based speculators trained via the Arctic Training recipe and ran inference with Arctic Inference atop vLLM V1. The request arrival rate was set at 0.5 req/sec.
To establish competitive baselines, we used the fastest setups supported by vLLM: (i) nonspeculative decoding with FP8 and TP=8 (vLLM V1), and (ii) speculative decoding with FP8, TP=8 using open source MLP-Speculator (vLLM V0) and EAGLE/EAGLE-3 checkpoints (vLLM V1). We also chose the best-performing version of FlashAttention (V2 or V3).
We note that the full acceptance rate and speedup from EAGLE/EAGLE-3 could not be replicated in vLLM, which could be due to the EAGLE speculator not being fine-tuned on a similar data set, vLLM's lack of a tree-decoding speculative system or overheads in the speculative inference code path.
Results
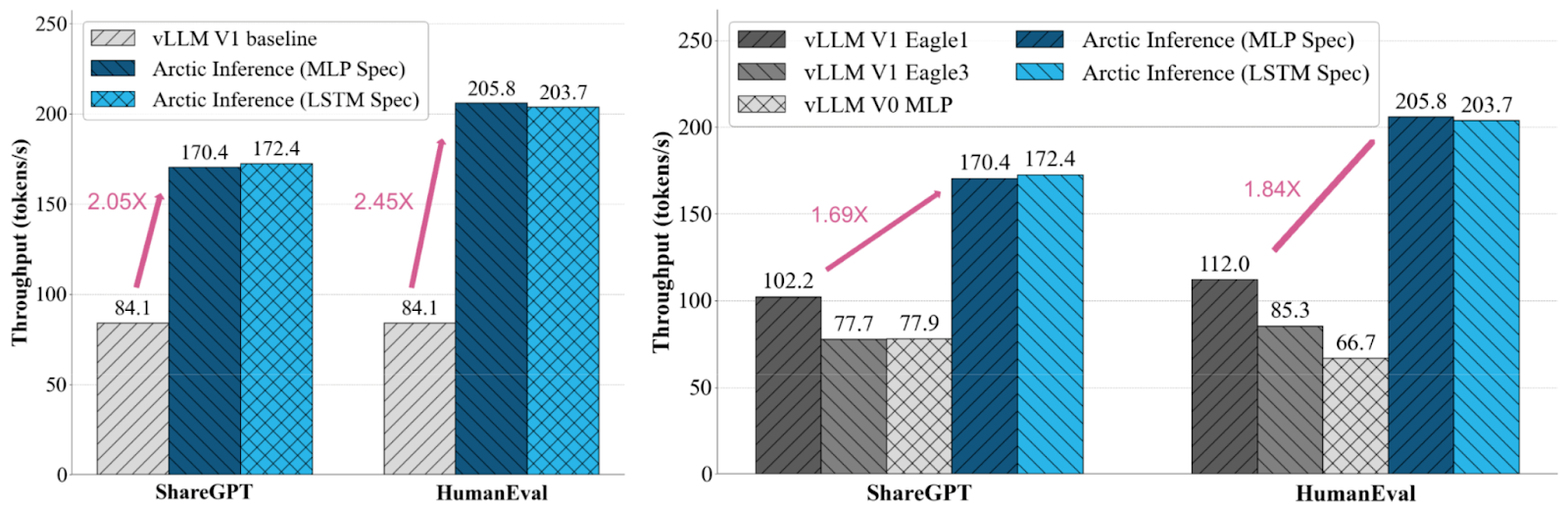
Key drivers of improvement:
| Public MLP (vLLM V0) |
Our MLP (vLLM V0) |
Improvement | |
|---|---|---|---|
| ShareGPT | 77.9 tokens/s | 120.5 tokens/s | 54.7% |
| HumanEval | 66.7 tokens/s | 144.7 tokens/s | 116.9% |
Table 2. Arctic-trained MLP/LSTM speculators vs public speculators on vLLM V0
Superior draft models: Arctic-trained MLP/LSTM speculators achieve up to 3.1x higher acceptance rates on ShareGPT compared to open source MLP-Speculator (Table 1). Additional comparisons (Table 2) show throughput speedup by simply replacing with Arctic-trained speculators.
| vLLM V0 | Arctic Inference + vLLM V0 |
Arctic Inference + vLLM V1 |
Improvement | |
|---|---|---|---|---|
| ShareGPT | 120.5 tokens/s | 153.1 tokens/s | 171.2 tokens/s | 42.1% |
| HumanEval | 144.7 tokens/s | 186.6 tokens/s | 205.8 tokens/s | 42.2% |
Table 3. Speculative inference pipeline with or without optimizations
Faster speculative decoding system: Generation throughput significantly improved over vLLM V0, and further accelerated after porting MLP-Speculator in Arctic Inference to vLLM V1 (Table 3).
Combining Suffix Decoding and draft model speculation
Finally, we evaluate the effectiveness of combining Suffix Decoding and draft-model-based speculative decoding. We measured the output tokens per second on four workloads: ShareGPT, HumanEval, SWE-Bench and a mixture of the three (Table 4).
| Workload | No Spec | N-gram (vLLM V1) | EAGLE (vLLM V1) | LSTM Only (Ours) | Suffix Only (Ours) | LSTM + Suffix (Ours) |
|---|---|---|---|---|---|---|
| ShareGPT | 76.0 tok/s | 91.2 tok/s | 102 tok/s | 172 tok/s | 113 tok/s | 179 tok/s |
| HumanEval | 77.2 tok/s | 100 tok/s | 112 tok/s | 204 tok/s | 148 tok/s | 217 tok/s |
| SWE-Bench | 75.8 tok/s | 175 tok/s | - | 123 tok/s | 286 tok/s | 302 tok/s |
| Mixed | 82.9 tok/s | 112 tok/s | - | 154 tok/s | 155 tok/s | 209 tok/s |
Table 4. Evaluation of combining LSTM and Suffix Decoding in Arctic Inference
First, as expected, the LSTM-based speculator performs better on ShareGPT and HumanEval, and Suffix Decoding performs better on SWE-Bench. However, the hybrid LSTM–Suffix speculator matches or exceeds both at all workloads, and is a full 55 tokens-per-second higher than either the LSTM or Suffix speculators alone on the mixed workload. EAGLE could not be run on SWE-Bench and Mixed because its draft models only supported 2K sequence lengths.
This result shows that one does not need to choose between Suffix Decoding and model-based speculative decoding, and can get the best of both worlds for both open-ended conversational tasks and repetitive agentic tasks simultaneously.
Deploy speculative decoding with Arctic Inference
Suffix Decoding, MLP/LSTM speculation and the system optimizations described in this blog are all implemented as part of the vLLM-compatible Arctic Inference project.
Arctic Inference is an open source library that contains current and future LLM inference optimizations developed at Snowflake AI Research. It is integrated with vLLM v0.8.4 using vLLM’s custom plugin feature, allowing us to develop and integrate inference optimizations quickly into vLLM and make them available to the community.
Once installed, Arctic Inference automatically patches vLLM with the speculative decoding features from this blog, and users can continue to use their familiar vLLM APIs and CLI. It’s easy to get started!
Install vLLM and Arctic Inference:
pip install "git+https://github.com/snowflakedb/ArcticInference.git#egg=arctic-inference[vllm]"Arctic Inference will add several additional configurations to the speculative config option in vLLM. The example below will run the MLP/LSTM draft model with Suffix Decoding:
vllm serve \
meta-llama/Llama-3.1-70B-Instruct \
--quantization "fp8" \
--tensor-parallel-size 2 \
--speculative-config '{
"method": "arctic",
"model":"Snowflake/Arctic-LSTM-Speculator-Llama-3.1-70B-Instruct",
"num_speculative_tokens": 3,
"enable_suffix_decoding": true
}'In the example above, "method": "arctic" enables the MLP/LSTM speculator, along with the system optimizations described in this blog post. "enable_suffix_decoding": True enables Suffix Decoding.
Training custom draft models with Arctic Training
Arctic Training makes it easy to train new draft models for different LLMs and workloads, which can be directly plugged into Arctic Inference for deployment. To get started, install Arctic Training:
pip install arctic-trainingIn Arctic Training, each training recipe is entirely specified in a single YAML file, which makes them easy to share and reproduce. For example, the draft model we used above was trained using this simple YAML file.
To reproduce training the draft model, save the YAML above into config.yaml, change the desired input/output paths, and run:
arctic_training config.yamlCitation
@misc{arctic-speculator,
author = {Wang, Ye and Oliaro, Gabriele and Lee, Jaeseong and He, Yuxiong and Qiao, Aurick and Rajbhandari Samyam},
title = {Fastest Speculative Decoding in vLLM with {Arctic Inference} and {Arctic Training}},
year = {2025},
month = {May},
day = {1},
howpublished = {\url{https://www.snowflake.com/en/engineering-blog/fast-speculative-decoding-vllm-arctic}}
}That’s it! The trained model can then be used in Arctic Inference.
1 MLP is not supported in vLLM V1, and we found that EAGLE speculator with vLLM V1 offers the best generation throughput using Speculative Decoding in vLLM across both V0 and V1.
Arctic RL: A Unified, Open Source RL Backend for Enterprise Post-Training

HybridDeepResearch: Enforcing Rigor Across SQL and Web Search for Enterprise Agents
Inside the ArcticSwarm Architecture: How ArcticSwarm Improves Deep Research