
NOV 06, 2024|7 min read

Data Manipulation Language (DML) operations, including DELETE, UPDATE and MERGE statements, are essential for maintaining current and accurate data in modern cloud data platforms and underpinning critical processes such as ETL/ELT and change data capture (CDC). These operations can become performance bottlenecks due to write amplification, where small data changes have an outsized impact on performance.
Snowflake directly addresses this challenge with Snowflake generation 2 standard warehouses (Gen2), along with other performance innovations. These enhancements significantly and automatically accelerate data engineering and data transformation workloads, with applicable DML operations showing up to 4.4x faster execution times as of May 2, 2025, when comparing performance on a 2XL Standard Warehouse and 2XL Gen2. This leap in performance streamlines data pipelines, translating to more efficient usage and faster time to value for business-critical insights. Ultimately, Gen2 allows data teams to deliver fresh, reliable data for analytics and AI more rapidly and cost effectively.
In Snowflake's architecture, data is stored in immutable units (read more here), which enables higher performance and data consistency. However, optimizing DML operations is a key opportunity to enhance performance in data platforms. DML operations such as DELETE, UPDATE and MERGE have traditionally involved rewriting larger portions of data than the actual changes. This could lead to write amplification, where the volume of data written sometimes significantly exceeds the actual modifications, resulting in longer execution times and increased resource consumption for DML-heavy workloads.
To illustrate this challenge, consider a real-world example of a MERGE operation executed on a Snowflake generation 1 standard warehouse (Gen1):
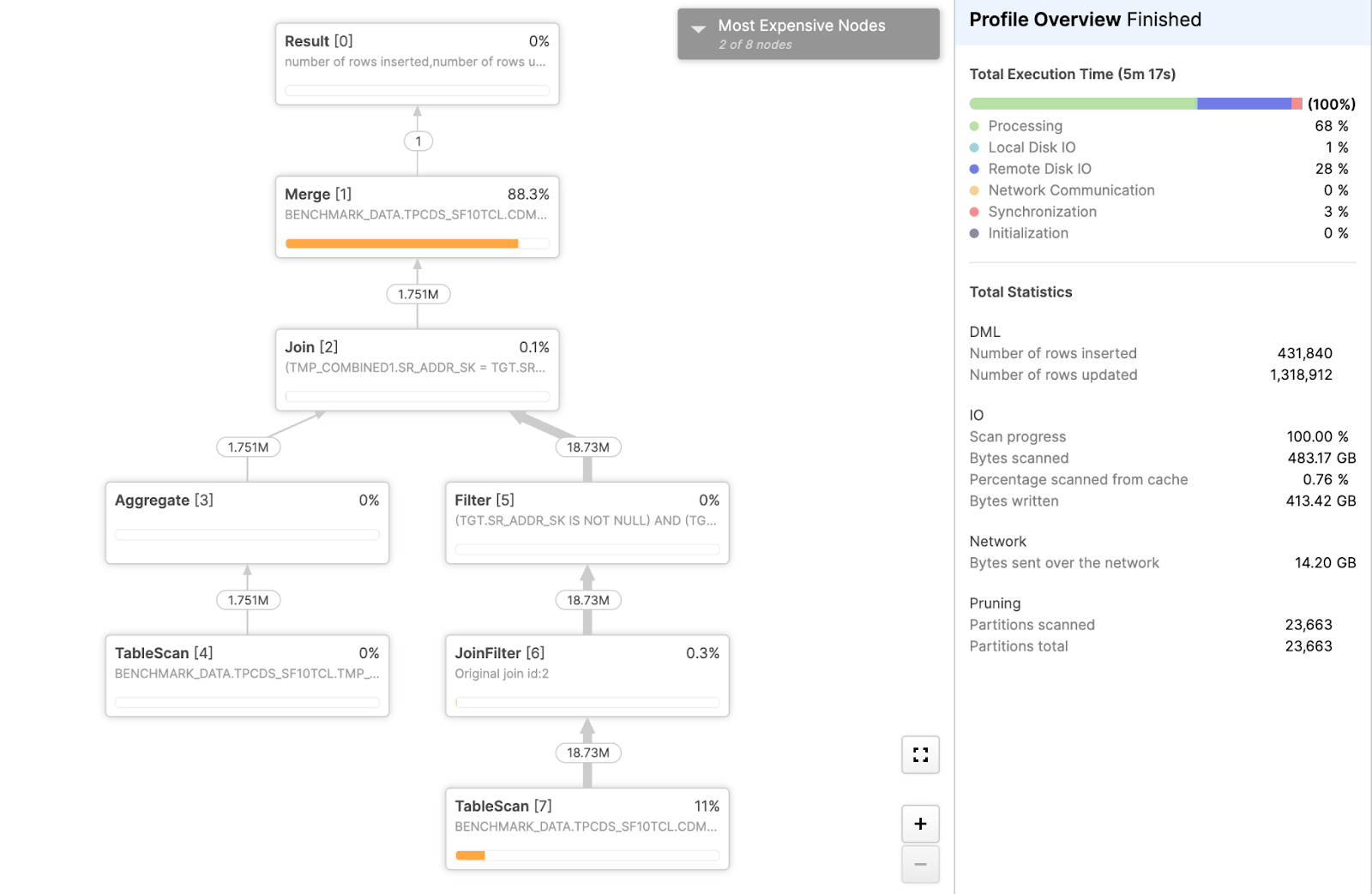
In this specific MERGE operation, 483 GB of the table were scanned, and less than 1% of the rows were updated. However, the operation subsequently wrote 413 GB of data — roughly 86% of the scanned data volume, even though a relatively small percentage of the rows in the table needed to be modified. Critically, this meant writing approximately 1,500 times more data than what was actually modified by the query. This effect, known as write amplification, directly translates to longer execution times, higher resource consumption and increased storage cost for features such as Time Travel and replication.
Gen2 introduces a novel, adaptive approach to DML operations, fundamentally changing how these operations are handled. For many DELETE, UPDATE and MERGE statements, especially those modifying a smaller number of rows within a micropartition, the system automatically decides whether to create a more compact record of modification instead of a full new copy of the input partition. Unlike with other systems, this decision is dynamic at the micropartition level; requires no configuration changes, code changes or decisions by the user; and ensures optimal performance across different scenarios for both write and read queries.
When data is queried, the Snowflake query engine efficiently applies these changes on the fly to return the current, accurate state of the data to the user. Data visibility in Snowflake also remains unchanged: Previous versions of modified data are inaccessible after the configured Time Travel and retention periods.
The advantages of this adaptive change are substantial:
Reduced write amplification: By avoiding full file rewrites for minor modifications, the amount of data written is drastically reduced, making the write path much more efficient.
Faster DML completion times: Less data to write means DML queries complete significantly faster, improving overall pipeline performance.
Reduced storage cost: The use of smaller delete files can lead to considerable storage savings, particularly for tables with nonzero retention intervals (for example, for Time Travel) and replicated tables.
Automatic performance: Users don't need to decide when to use the new feature. The system will automatically apply it when it is beneficial for performance.
To illustrate the significant impact of these advancements, let's revisit the same MERGE operation profiled earlier, now running on a Gen2.
First, here is the profile of the MERGE on a Gen2 warehouse — to establish a baseline, we’ve disabled the DML-specific software optimization:
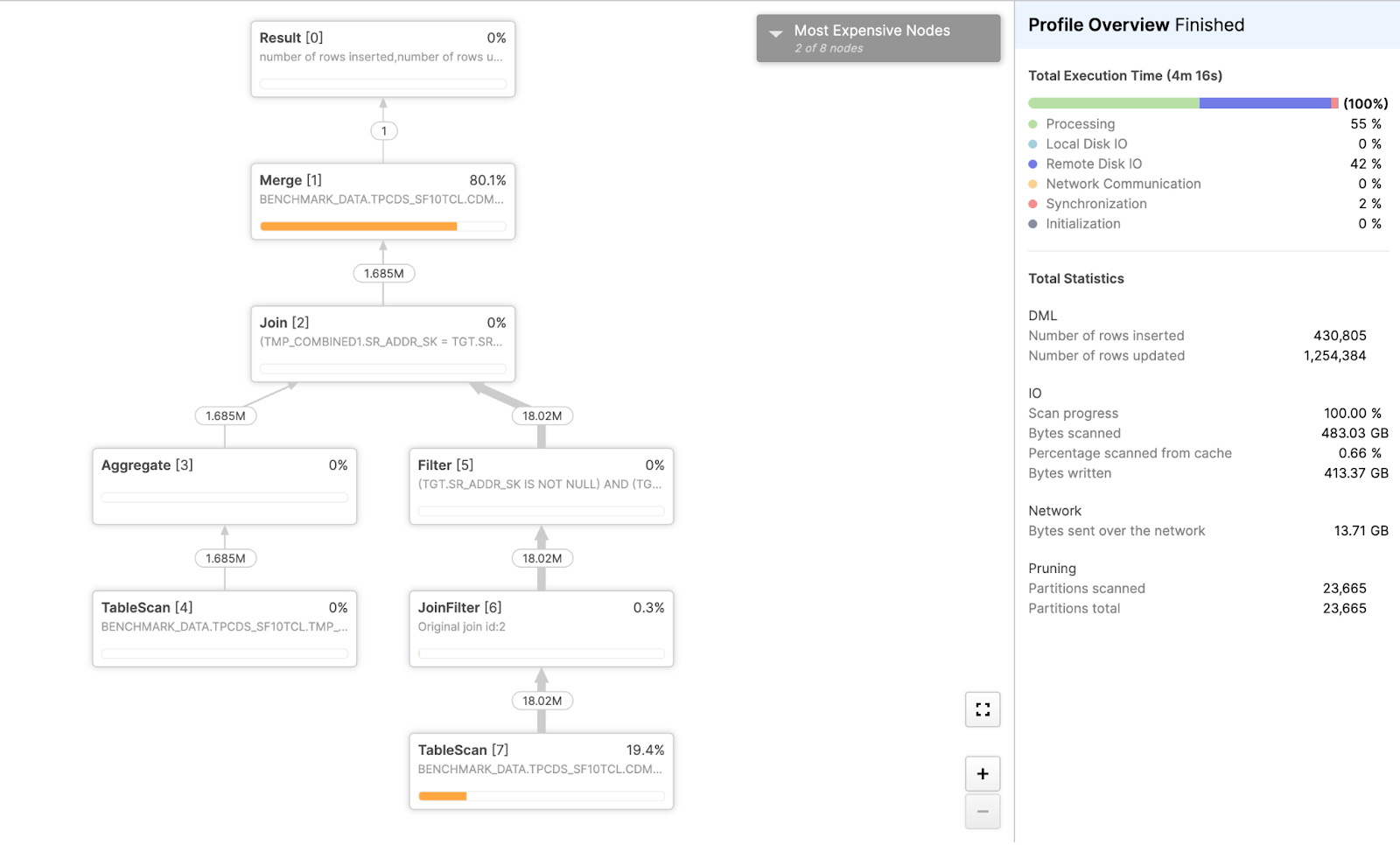
Even without the DML-specific software optimizations, we can see a significant improvement over Gen1 just from the upgraded hardware and other software enhancements in Gen2. The execution time drops from 5 minutes, 17 seconds, to 4 minutes, 16 seconds — an impressive 1.2x improvement in query performance. However, the write amplification problem persists, indicating where most of the operation's time is still being spent.
Now, here is the profile of the same MERGE operation in Gen2, with the DML-specific software optimizations enabled:
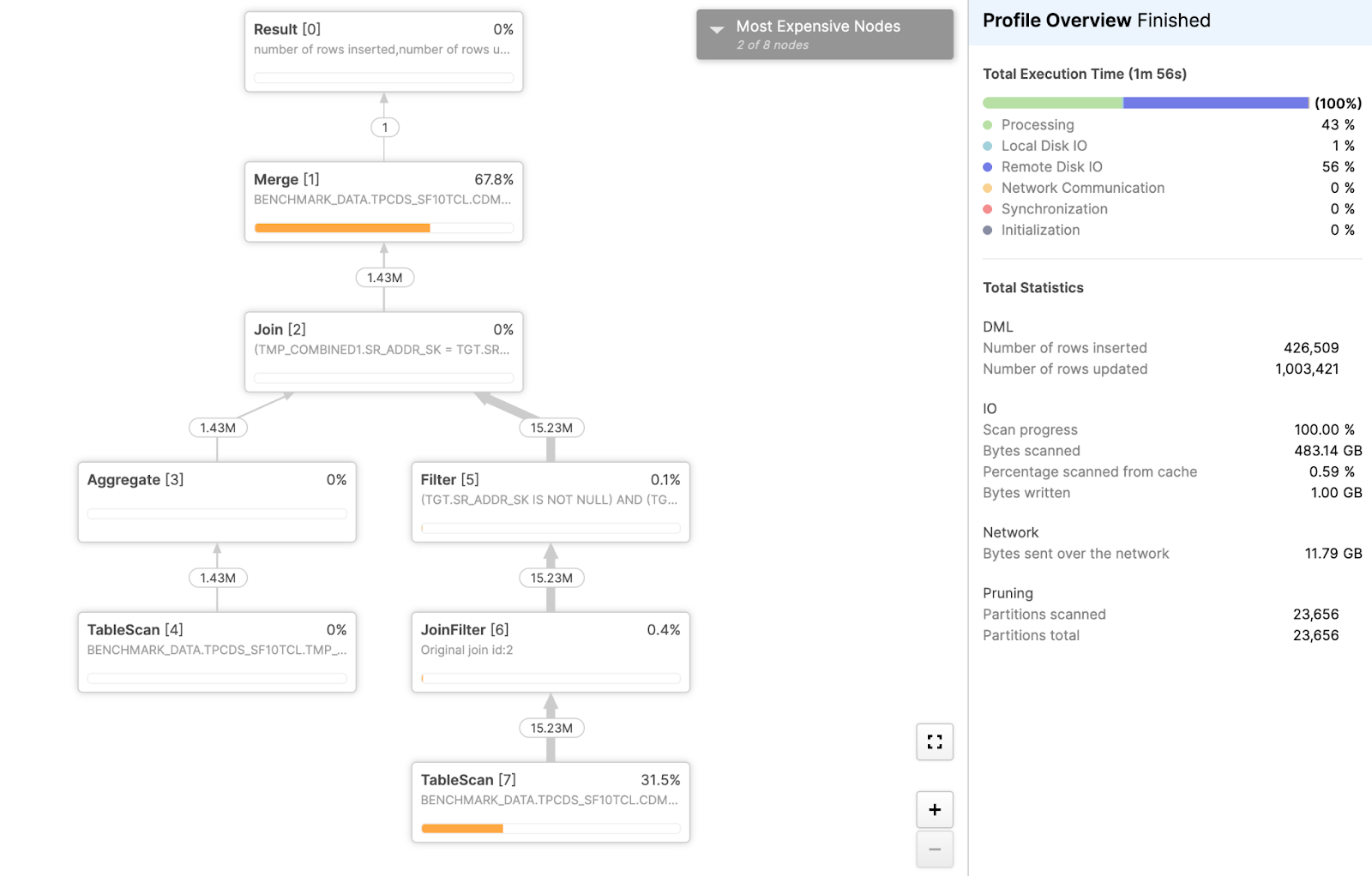
The difference is dramatic! The query duration time has dropped from 4 minutes, 16 seconds, to just 1 minute, 56 seconds — an improvement of 2.7x. Write amplification is reduced by just over two orders of magnitude, with bytes written dropping from over 400 GB to a mere 1 GB. Moreover, we estimate that this MERGE with Gen2 now writes approximately only 1.1 times the amount of data being directly inserted or updated, effectively eliminating the significant write amplification.
Here is an overview of the improvement for our example query:
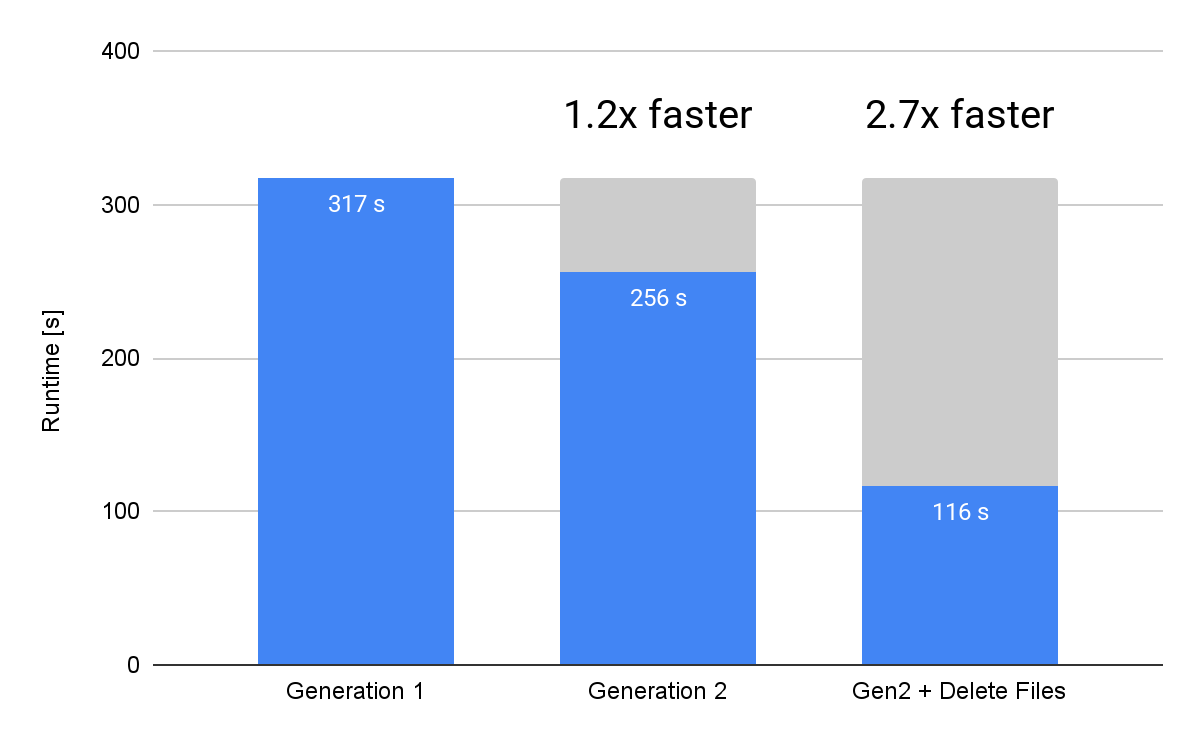
Above, it’s clear that our query benefits from both hardware improvements and software innovations included in Gen2 warehouses. We’ve measured up to 4.4x improvement for DML operations such as DELETE, UPDATE and MERGE — but don’t just believe what you read on the internet, convert your warehouse to Gen2 and try this out for yourself!
The best part about these DML optimizations is their simplicity: If you are using a Gen2, applicable DML operations will automatically benefit from these write amplification optimizations. No tuning or code changes are needed for your SQL queries.
To take advantage of these enhancements, simply switch your warehouse to Gen2 (click here to learn how to do that).
If you want to ensure you are using the latest generation of warehouses, you can easily check your warehouse type in the Snowflake UI under the "Warehouses" tab or by executing a SQL query such as:
SHOW WAREHOUSES LIKE '<your_warehouse_name>';Look for the TYPE column in the output. If it's STANDARD_GEN2, you're all set!
Snowflake’s mission is to continuously improve the performance and efficiency of your workloads — automatically. The advancements in Snowflake generation 2 warehouses represent the latest in a series of database engine enhancements that deliver significant performance improvements with zero effort from users. If your workloads rely heavily on DELETE, UPDATE and MERGE operations, switching to Gen2 is the easiest way to unlock faster data pipelines, reduce processing overhead and achieve higher data freshness without any code changes.
To learn more about DML in Snowflake and Gen2, visit the Snowflake Documentation.



