Powering the Latest LLM Innovation, Llama v2 in Snowflake, Part 1

This blog series covers how to run, train, fine-tune, and deploy large language models securely inside your Snowflake Account with Snowpark Container Services
This year there has been a surge of progress in the world of open source large language models (LLMs). This world of free and open source LLMs took yet another major step forward just this week with Meta’s release of Llama v2.
Responding to customer needs to safely package and run code, especially sophisticated AI models and data intensive apps, we released Snowpark Container Services in Private Preview at Snowflake Summit last month. The reception has been incredible, with many customers and third parties packaging a variety of applications and models to run within these containers securely in Snowflake.
Llama v2 is a LLM trained by Meta on a vast amount of training data across a huge number of GPUs, ranging in sizes from 7 to 70 billion parameters. And most interestingly, Meta has released the model in a variety of sizes in a way that makes it possible for anyone to run it themselves wherever they like, and free of any licensing fees for most corporations worldwide.
We know that many Snowflake customers want to run Llama, and forthcoming derivatives of Llama that the open source community is likely to create, inside their Snowflake accounts. This allows them to have a LLM run right within their Snowflake Data Cloud data. Customers have also told us they want to fine-tune Llama v2 with their own data from their Snowflake accounts directly inside the Snowflake Data Cloud, to create and serve new bespoke models for their specific use cases.
After we announced Snowpark Container Services and our partnership with NVIDIA, many customers asked if they could run open source and commercially-friendly LLMs on NVIDIA-powered GPU-accelerated computing in Snowflake. The answer is yes! The walkthrough below shows how this can be done today in just a few minutesby our customers who are previewing Snowpark Container Services, and soon by any Snowflake customer.
Deploying Llama v2 in Snowpark Container Services
To deploy Llama, or another Hugging Face-hosted free or open source LLM, we can combine an NVIDIA-provided PyTorch Docker container, Hugging Face’s Transformer models, and LmSys’s FastChat system and deploy them in Snowpark Container Services.
To deploy Llama in Snowflake, you will need access to Snowpark Container Services, currently in private preview to an initial set of Snowflake customers. If you are not yet a part of the preview, please contact your Snowflake account team to join the waitlist. In the meantime, you can read through below and see screenshots showing how it works.
First, create a GPU-based compute pool. Llama v2 and other open source models often come in multiple sizes, generally 7b, 13b, 30b, and 70b or so parameters—the number of billions of weights and biases that connect the neurons inside their neural networks.
CREATE COMPUTE POOL GPU_3_POOL
with instance_family=GPU_3
min_nodes=1
max_nodes=1;
This creates a GPU_3-sized compute pool, based on NVIDIA GPU chips, suitable to run a 7b or 13b-sized LLM. Larger models, like Llama-2-70b, take more resources—and therefore larger compute pools—to run, but may be useful when more model sophistication is required. Smaller models, on the other hand, like the one we will run in this walkthrough, are perfectly fluent and may be good starting points for fine tuning, the process where you can influence the way a model works by folding in your own training data or example responses from your Snowflake account.
There are three steps to deploying the service:
1. Building and Pushing the Docker Container
The Snowpark Container Services tutorials detail how to create and push Docker containers to Snowpark Container Services, and you should follow those first to learn the basics if you are in the preview. Once you have done that, you can build your LLM container using the following Dockerfile:
FROM nvcr.io/nvidia/pytorch:23.06-py3
COPY llm_service.py ./
RUN pip3 install --upgrade pip && pip3 install accelerate
RUN pip3 install fschat
CMD nohup python3 -m fastchat.serve.controller > controller.out 2>controller.err & nohup python3 -m fastchat.serve.model_worker --model-path meta-llama/Llama-2-7b-chat-hf --num-gpus 1 > model_worker.out 2>model_worker.err & nohup python3 -m fastchat.serve.gradio_web_server > gradio.out 2>gradio.err & python3 llm_service.pyThis pulls a base container from NVIDIA that contains the prerequisites to run NVIDIA-powered AI services in Snowflake, in this case services based on PyTorch. Then it installs FastChat, a framework for running LLMs on GPUs. Finally it loads the Llama v2 small 7b model, and launches a Gradio server to allow users to interact with the model via a web interface. Contact your Snowflake account team for a copy of llm_service.py, and for instructions to connect your container to your HuggingFace account, as the Llama models require authentication. Then build and push this container to your Snowpark image registry.
2. Staging the Spec (YAML) File
Each service in Snowpark Containers is defined by a YAML file. Here is the YAML file for the LLM Service. Fill in and push this file to your Snowflake stage using SnowSQL.
spec:
container:
- name: llm_service
Image: ////llm_service
endpoint:
- name: udf
port: 8080
- name: gradio
port: 7860
public: true
- name: api
port: 8000
public: true
- name: jupyter
port: 8888
public: trueThis YAML file points to the container you pushed in the previous step, and specifies 4 ports that authorized users of your Snowflake account with rights to the LLM service will be able to access on an inbound basis. One is used to connect to the container via Snowflake User Defined Functions (UDFs) so you can call it via SQL, one for the Gradio web GUI we will show below, one for an OpenAI-compatible API endpoint, and one for a Jupyter notebook interface.
We will use the first two in this blog, and upcoming blogs in this series will cover the OpenAI-compatible endpoint, and fine-tuning of Llama models inside Snowpark Container Services using Jupyter notebooks.
3. Creating the LLM Service
Once your image and YAML file are in place, you can create an instance of the LLM Service, with this command:
CREATE SERVICE llm_service
MIN_INSTANCES = 1
MAX_INSTANCES = 1
COMPUTE_POOL =
SPEC = @/llm_service.yaml;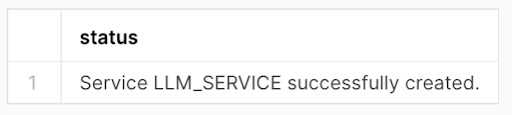
Also, create a UDF to communicate with your service from SQL:
CREATE or REPLACE FUNCTION llm(text varchar)
RETURNS varchar
SERVICE=llm_service
ENDPOINT=udf;You will now have a Llama v2 7b LLM running inside your Snowflake account. Your interactions with it will stay entirely inside your account, with no data flowing to any outside API or service. You can also grant access to this service instance to other users or roles within your Snowflake account.
You will now have a Llama v2 7b LLM running inside your Snowflake account. Your interactions with it will stay entirely inside your account, with no data flowing to any outside API or service.
Finally, run this command to get the endpoints of your service so you can connect to it via your web browser:
DESCRIBE SERVICE llm_service;Note the URL for the Gradio endpoint returned by this command, and connect to it via your web browser. Fill in your Snowflake username and password, or login via SSO or OAuth, and then you will be redirected to the chat GUI.
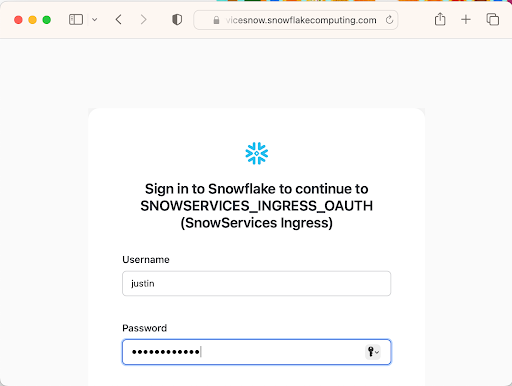
Chatting via the Gradio Web Interface
You can now chat with your privately-hosted LLM running securely in your Snowflake account using the Web GUI, as shown below. This instance is running the Llama-2-13b medium-sized model:
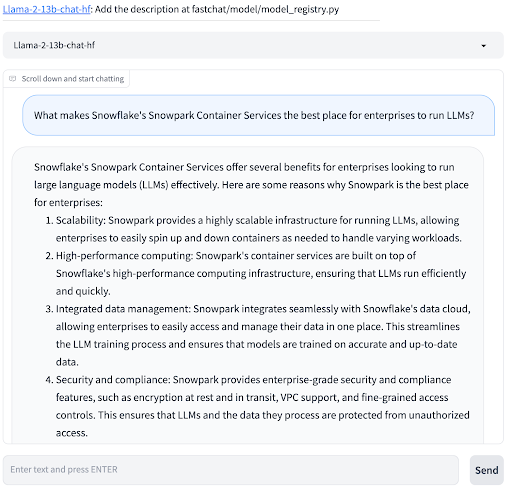
To chat, simply enter your text in the box, and you will see the responses appear:
Next Steps: Fine-Tuning, API access, Streamlit
You now have one of the latest and most advanced LLMs running inside of your Snowflake account! In addition to interacting with it via this Web GUI, you can also call it via SQL UDFs, Stored Procedures, from other Snowpark Container Services, and via an OpenAI-compatible API from internal or external services. We will cover these additional interaction modes in future blog posts. We will also show how you can use models deployed this way together with Streamlit’s new st.chat feature.
You can also fine-tune Llama models within Snowpark Container Services, to create new models that are a combination of an original Llama v2 model merged with your own data from your Snowflake account. We will cover this as well in a future blog post in this series. In the meantime if you are in the Snowpark Container Services preview and you’d like to explore fine-tuning or these other interaction models in the meantime, please contact your Snowflake account team for instructions.
Running LLMs securely with Snowflake
With the availability of free and high quality LLMs of various sizes from Meta with Llama v2 and likely from other sources in the near future, we are extremely excited about what our customers will be able to accomplish by running, fine-tuning, and even training these models with Snowpark Container Services directly and securely inside their Snowflake accounts. Within the secure boundaries of Snowflake, your data doesn’t need to go to an external or multi-tenant LLM service, even for the most advanced LLM use cases and deployment modes. (Of course, you should make sure that you have commercial rights to the LLM that you use.) And any models that you train or fine-tune on your own data are created and remain securely inside your Snowflake account.
Many of our customers have been asking us for these capabilities over the last few months as LLMs have captured the world’s attention. We are excited to bring these capabilities to you now, based on Snowpark Container Services. This blog, and the possibilities of training and running LLMs inside of Snowflake are just beginning!
Author
