
APR 02, 2025|5분 읽음

Apache Iceberg™는 상호 운용 가능한 스토리지의 업계 표준 형식으로서 그 위상을 지속적으로 강화해 오고 있습니다. 지난해 6월 오픈소스 커뮤니티의 성과로 공개된 최신 Iceberg v3 테이블 사양은 업계를 대표하는 최상위 스토리지 형식으로서의 Iceberg의 입지를 한층 더 공고히 했습니다. 그리고 이제 Iceberg v3 지원이 Snowflake에서 공개 미리보기(PuPr)로 제공됩니다.
이 글에서는 Snowflake의 뛰어난 성능을 기반으로 최신 주요 사용 사례를 구현할 수 있게 해주는 Iceberg v3 지원이, 개방적이고 상호 운용 가능한 데이터 전략을 한 단계 더 발전시키는 데 어떤 의미를 갖는지 살펴봅니다. Snowflake 관리형 또는 외부 관리형 Apache Iceberg™ 테이블을 표준으로 사용하고 있다면 이제 공개 미리보기(PuPr)를 통해 다양한 기능을 활용할 수 있습니다. 예를 들어, 행 계보와 선언적 단순성을 기반으로 복잡한 변경 데이터 캡처(CDC) 파이프라인을 구현할 수 있으며, 구조화된 쿼리 성능을 가진 유연한 반정형 데이터 유형인 variant를 사용할 수 있습니다. 또한 Snowflake는 삭제 벡터, 기본값, 지리 공간 데이터(geometry 및 geography) 및 나노초 단위의 타임스탬프도 지원함으로써 더 많은 사용 사례를 가능하게 합니다.
Iceberg v3는 최신 사용 사례를 지원하는 테이블 형식의 강력한 신규 기능을 제공하지만, 진정한 엔터프라이즈 도입을 위해서는 통합 거버넌스, 보안 및 비즈니스 연속성 제어를 지원하는 플랫폼이 필수적입니다. 이 글에서는 Horizon Catalog를 기반으로 하는 Snowflake AI 데이터 클라우드가 개방적이고 상호 운용 가능한 레이크하우스를 위해 안전하고 일관되며 가용성이 높은 플랫폼을 제공함으로써, v3 테이블 도입 첫날부터 프로덕션 환경에서 활용할 수 있도록 지원하는 방법도 함께 소개합니다.
Iceberg v3 지원에 대한 기술 세부 사항은 공식 설명서를 확인하거나 가이드를 활용하여 직접 실습해 보시기 바랍니다.
Iceberg v3는 행 계보 메타데이터를 네이티브로 지원합니다. 이전 버전에서는 테이블 변경 사항이 레코드 추가, 삭제, 업데이트 중 무엇에 해당하는지 판별할 수 있는 명확하고 공통된 기준이 없었기 때문에 CDC 활용이 매우 제한적이거나 사실상 구현이 불가능했습니다. 이제 v3 Iceberg 테이블에 대한 쓰기 작업에는 행 계보가 필수로 포함되며, 이를 통해 어떤 레코드에 어떤 변경이 이루어졌는지 일관되게 파악할 수 있습니다.
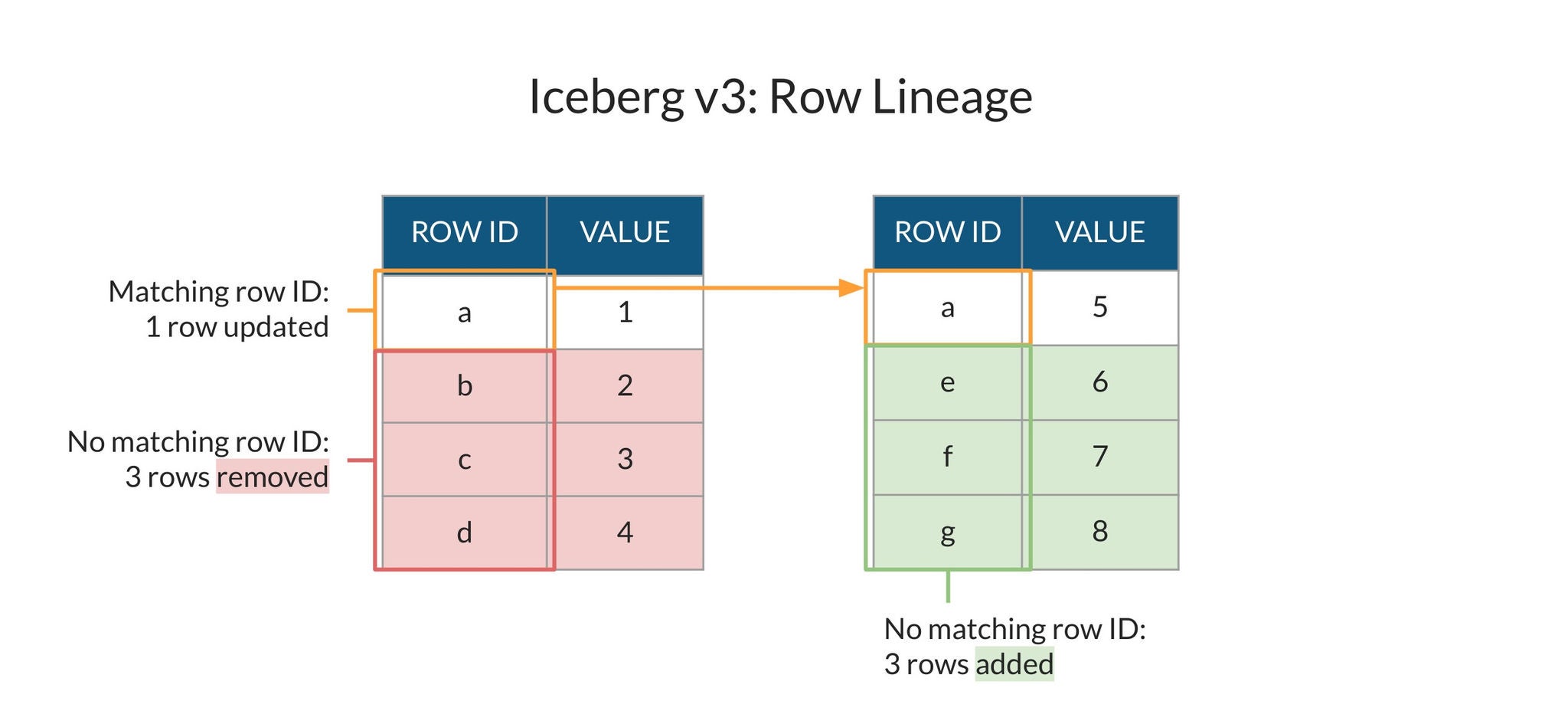
Snowflake는 v3 Iceberg 테이블에서 동적 Iceberg 테이블과 Streams의 내부 동작에 행 계보 메타데이터를 활용하여, 오픈 데이터 레이크상에서 효율적인 증분 처리 방식으로 CDC 사용 사례를 지원합니다. 특히 동적 Iceberg 테이블은 선언적 구문, 자동 오케스트레이션, 비용 효율적인 지능형 새로 고침 기능을 통해 CDC 구현을 크게 단순화합니다. Snowflake의 행 계보 지원은 Snowflake 관리형 및 외부 관리형 Iceberg 테이블 모두에 대해 INSERT, UPDATE, DELETE 및 MERGE 작업을 포함합니다.
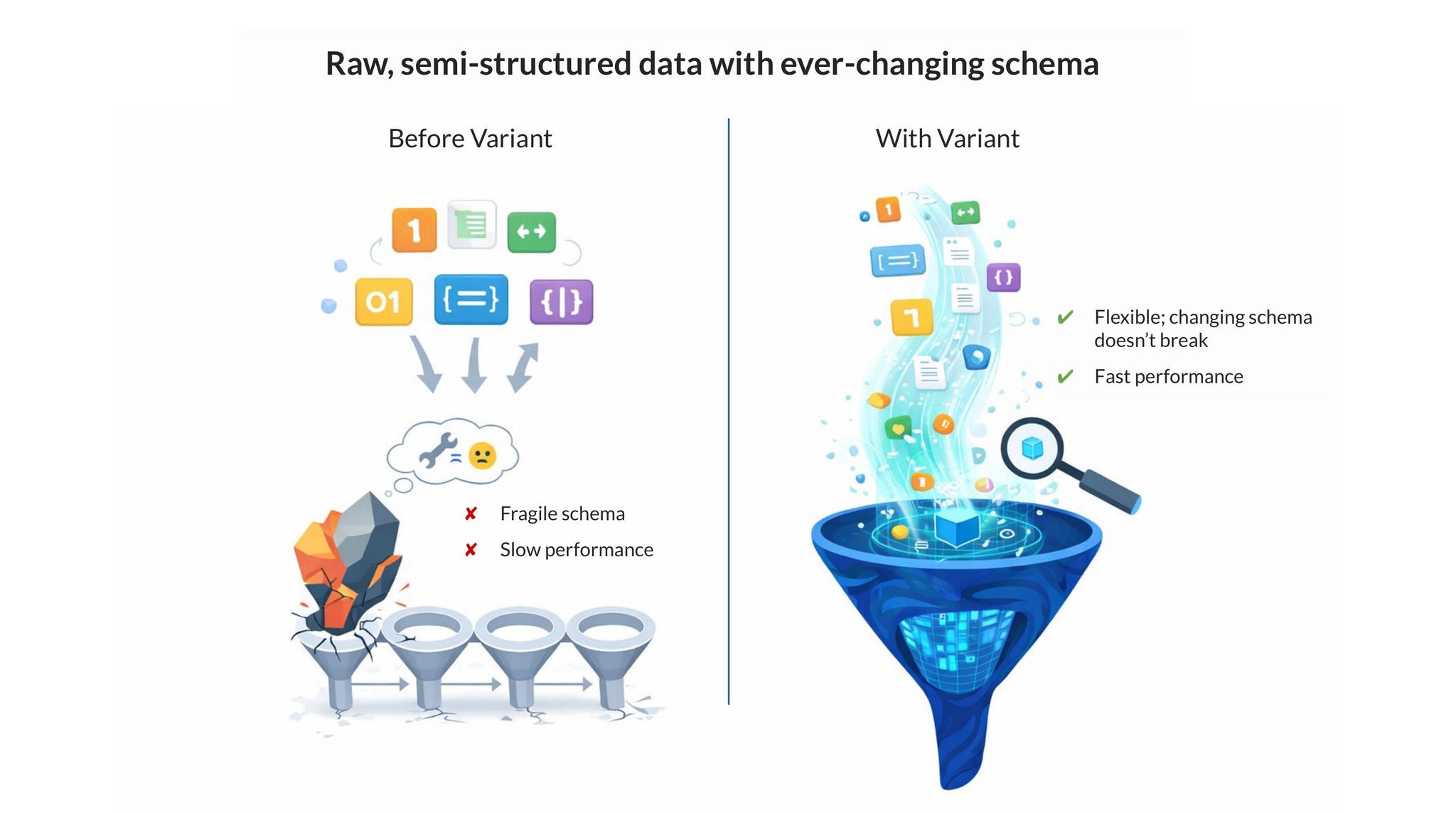
Iceberg v3에서 variant 데이터 유형이 도입되기 전에는 Iceberg 테이블에서 반정형 데이터를 처리할 때 효율성과 유연성 사이에 트레이드오프가 있었습니다. JSON 데이터를 문자열로 저장하면 쿼리 시 전체에 대해 구문 분석을 수행해야 해 성능과 비용 부담이 컸고, 반대로 수천 개의 nullable 컬럼으로 된 고정 스키마로 펼쳐 저장하면 잦은 스키마 변경과 메타데이터 증가 문제가 발생했습니다. 그러나 이제 variant의 도입으로 고성능 바이너리 인코딩 방식을 사용해, 깊이 중첩된 다양한 데이터를 하나의 컬럼에 저장할 수 있게 되었습니다. 이 인코딩 방식은 전체 블롭에 대해 구문 분석을 수행하지 않고도 파일을 선별하고 하위 필드 수준으로 필터를 푸시다운할 수 있게 해주며, 그 결과 JSON의 유연성을 유지하면서도 구조화된 컬럼에 가까운 성능을 제공합니다.
Variant 데이터 유형에 대한 Iceberg v3 지원은 업계에 있어 중요한 전환점입니다. 이를 계기로 Iceberg 기반의 옵저버빌리티 솔루션이 크게 늘어날 것으로 기대합니다. Snowflake는 엔터프라이즈 규모에서 Variant를 서브컬럼화(shredding)해 온 오랜 경험을 보유하고 있어, 이제 Iceberg까지 결합된 환경에서 이러한 솔루션을 구현하는 데 최적의 선택이라고 생각합니다.
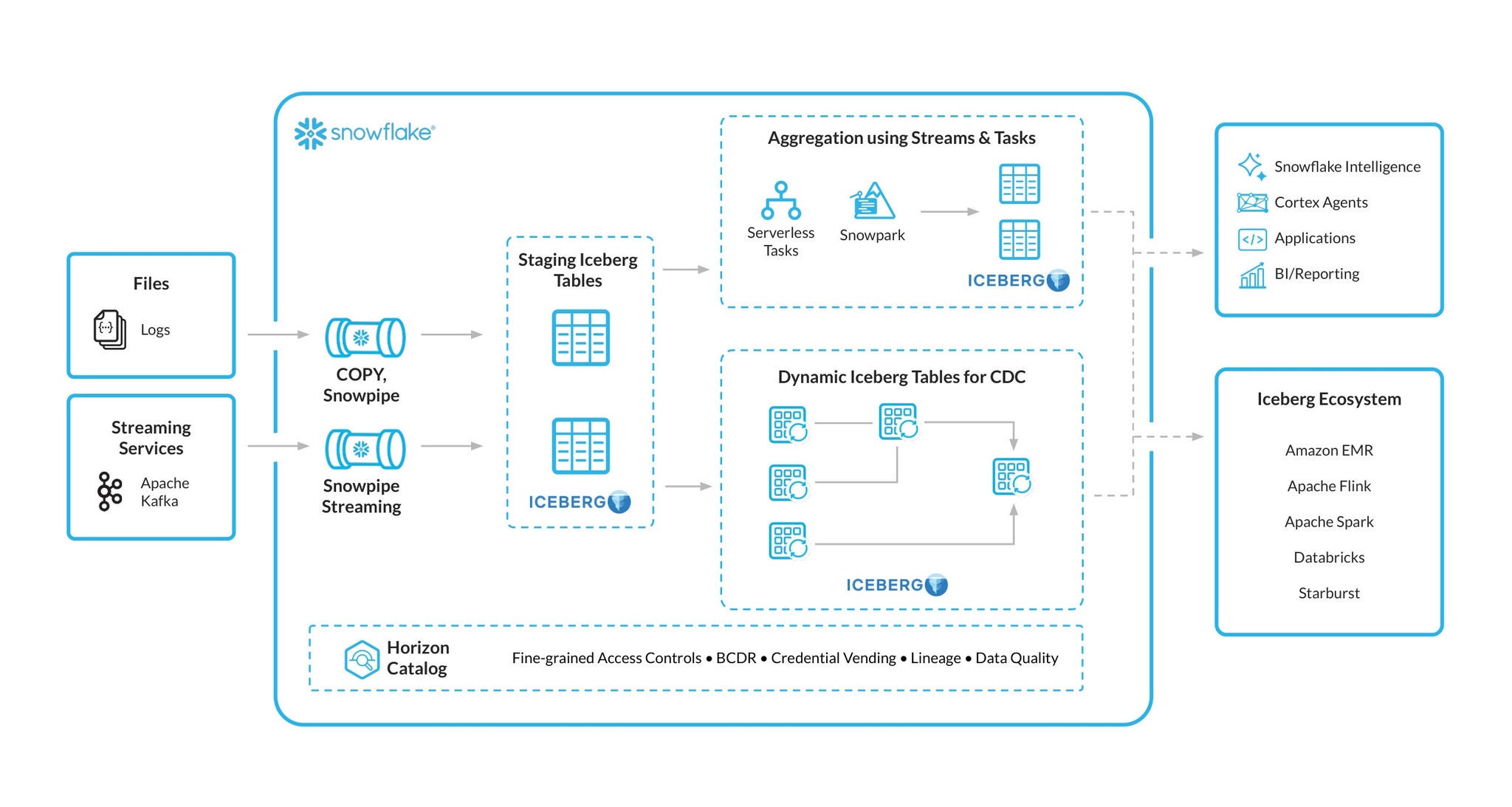
Snowflake는 오랫동안 variant 데이터 유형을 지원해 왔으며, 이제 v3를 통해 그 지원 범위가 Iceberg 테이블까지 확장되었습니다. 이에 따라 Iceberg 테이블에 직접 데이터를 적재하는 배치(COPY), 마이크로배치(Snowpipe) 및 스트리밍(Snowpipe Streaming) 파이프라인을 모두 지원합니다. 또한 자동 서브컬럼화(이른바 ‘분쇄’)를 통해 최적화된 읽기 성능을 제공합니다.
v3 Iceberg 테이블은 이제 나노초 단위 정밀도의 타임스탬프를 지원함으로써 네이티브 Snowflake 테이블과 동일한 수준의 시간 정밀도를 제공합니다. 이러한 정밀도는 고빈도 금융 데이터나 사물 인터넷(IoT) 데이터와 같은 사용 사례에서 특히 중요합니다. 또한 ASOF JOIN, ML Forecasting등 Snowflake의 고급 시계열 기능도 Iceberg 테이블에서 사용할 수 있습니다.
v3 Iceberg는 geometry 및 geography 데이터 유형을 지원하며, 네이티브 Snowflake 테이블과 동일한 지리 공간 데이터 유형을 제공합니다. Snowflake는 경계 상자(bounding box)와 메타데이터를 활용해 효율적인 프루닝을 수행하며, 다양한 지리 공간 함수를 기반으로 한 분석 워크로드를 지원합니다.
Iceberg는 사용 사례의 요구에 따라 성능을 최적화할 수 있도록 복사-쓰기, 병합-읽기 형태의 옵션을 제공합니다. 그러나 Iceberg v2의 위치 삭제 방식은 일반적으로 삭제 파일 수와 세분화 수준에 따라 성능 저하가 발생하는 한계가 있었습니다. v3의 경우에는 병합-읽기의 기본 모드로 삭제 벡터를 도입해, 파일 단위로 더 적은 수의 통합된 파일에 저장함으로써 성능을 높였습니다. Snowflake는 이제 Snowflake 관리형 및 외부 관리형 카탈로그의 v3 Iceberg 테이블에서 읽기와 쓰기 모두에 대해 삭제 벡터를 지원합니다. 이를 통해 업데이트, 삭제, 병합 작업이 많은 파이프라인의 성능을 향상시킬 수 있습니다.
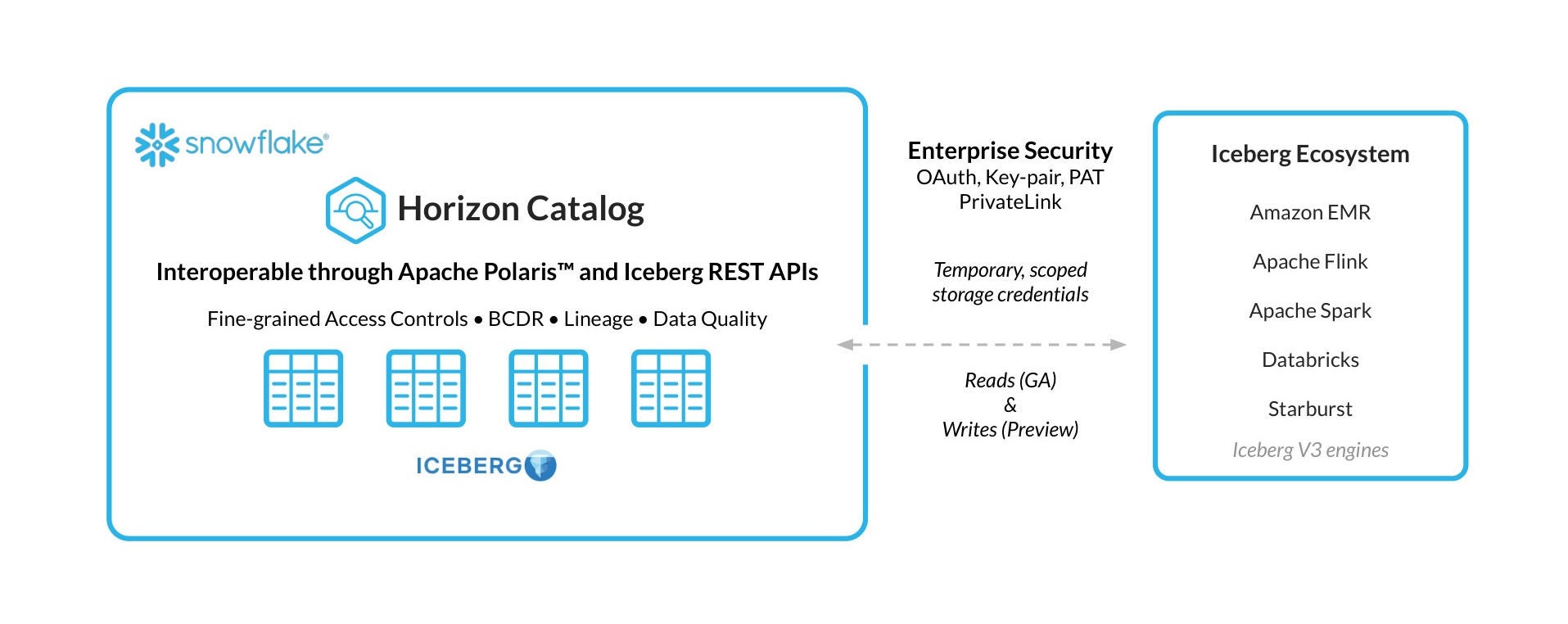
Horizon Catalog는 Iceberg 테이블을 포함한 조직 내 다양한 자산 전반에 걸쳐 검색, 거버넌스, 협업 기능을 통합 제공하며, 내장된 계보, 정책, 보안 제어 기능을 통해 데이터 관리를 일관되게 수행할 수 있습니다. Horizon Catalog는 Horizon에 통합된 Apache Polaris™를 기반으로 표준화된 Iceberg REST 인터페이스를 통해 Iceberg 테이블을 외부에 노출합니다. 이를 통해 외부 엔진에서도 Snowflake 관리형 Iceberg 테이블(이제 Iceberg v3 포함)을 읽을 수 있습니다.
Horizon은 v3 Iceberg 테이블이 다양한 도구 전반에 걸쳐 거버넌스와 상호운용성을 유지하도록 지원합니다. 여기에는 런타임에 범위가 지정된 임시 스토리지 자격 증명을 발급할 수 있는 기능도 포함되며, 이는 엔진, 카탈로그, 블롭 스토리지 간의 보안 통합을 위한 업계 표준으로 자리 잡고 있습니다.
또한 Iceberg 테이블에 대한 행 수준 액세스 및 컬럼 마스킹과 같은 데이터 보호 정책은 v2에서 처음 도입되었으며, 이제 v3 Iceberg에 적용됩니다. 이러한 정책은 Snowflake Connector for Apache Spark™(GA로 제공)를 통해 Apache Spark에서 Iceberg 테이블에 접근할 때도 그대로 적용됩니다.
Horizon Catalog는 크로스 리전 및 크로스 클라우드 환경에서의 복원력을 구현하는 데에도 핵심적인 역할을 수행합니다. Snowflake의 엔터프라이즈급 비즈니스 연속성 및 재해 복구(BCDR)는 이제 Snowflake 관리형 v3 Iceberg 테이블을 보조 리전이나 다른 클라우드로 복제하는 기능을 포함합니다. 이를 통해 장애 조치가 필요한 상황에서도 데이터 무결성과 일관성을 유지할 수 있습니다.
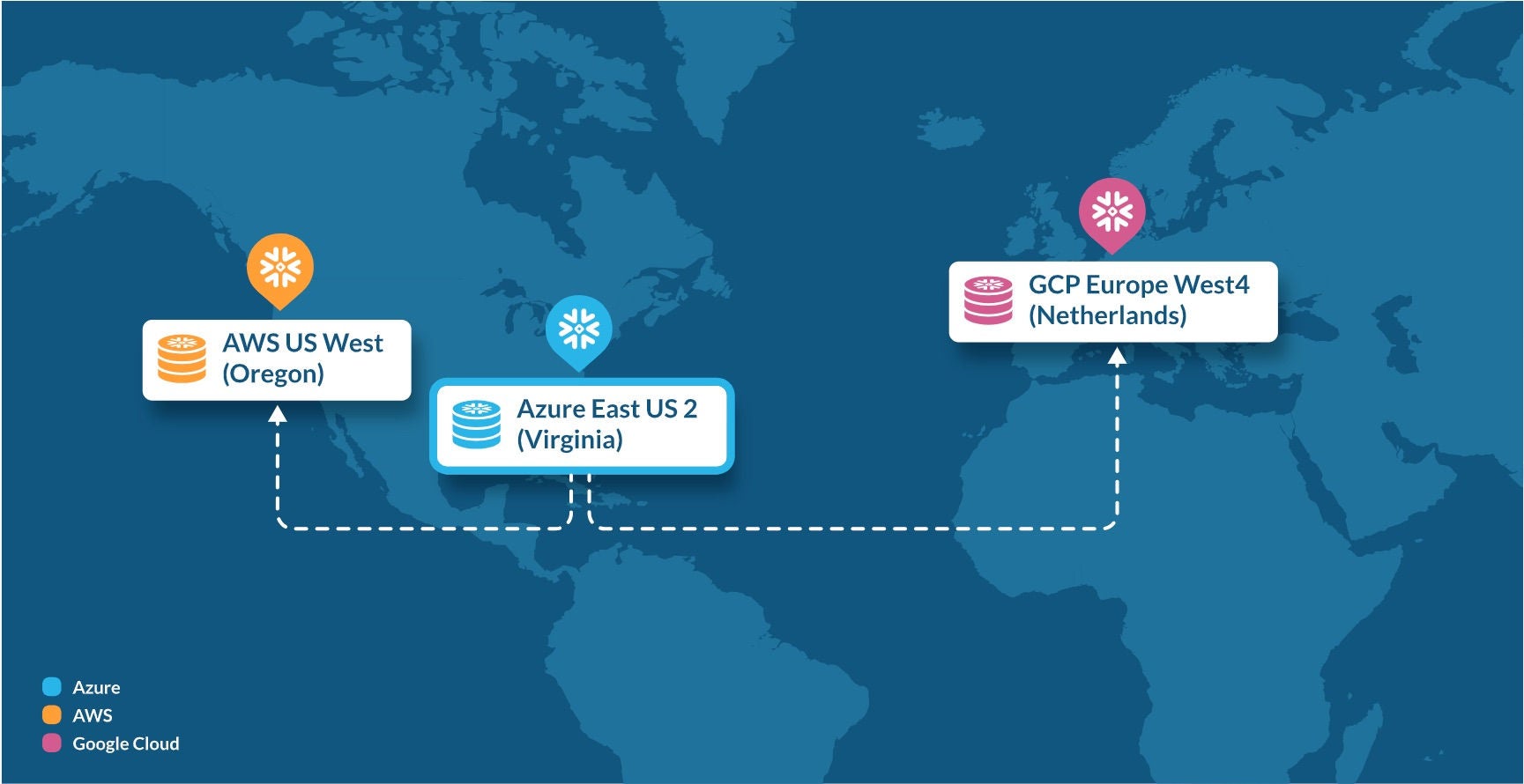
플랫폼이 장기적인 상호운용성 전략에 얼마나 잘 부합하는지 평가하려면 크게 두 가지 측면을 살펴봐야 합니다.
이 주제에 대해서는 이 블로그에서 더 자세히 다루고 있습니다. 다만, 아직 부분적으로만 상호 운용 가능하거나 상대적으로 보안이 약한 인증 방식을 사용하는 대부분의 다른 플랫폼과 달리, Snowflake는 이 두 가지 측면을 모두 충족하고 있습니다.
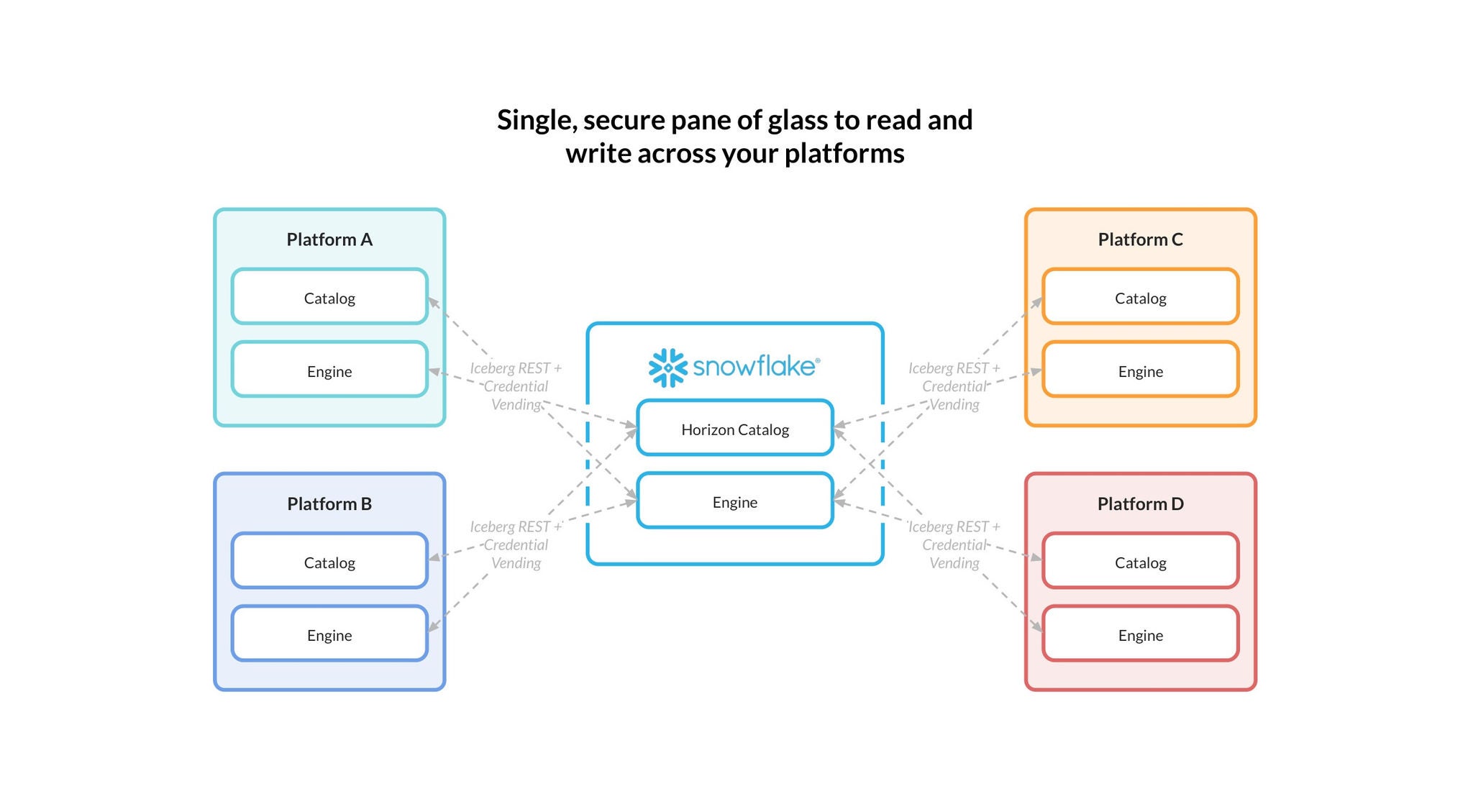
Snowflake의 Iceberg v3 공개 미리보기(PuPr)는 카탈로그 통합을 통해 Iceberg v3를 지원하는 모든 Iceberg REST 카탈로그에 대해 읽기 및 쓰기 작업을 수행할 수 있는 기능을 포함하며, 카탈로그가 발급하는 자격 증명을 사용할 수 있는 옵션도 제공합니다.
Iceberg v3 지원은 Snowflake 플랫폼 전반에 깊이 통합되어 있습니다. 이를 통해 원시 데이터 수집부터 변환, 테이블 최적화, 거버넌스, 협업, 분석 그리고 에이전틱 AI 애플리케이션에 이르기까지 데이터 수명 주기 전반에서 상호 운용 가능한 데이터에 대한 통합 거버넌스를 구현할 수 있습니다.
궁극적으로 이는 레이크하우스의 활용 범위를 확장하여, 이전에는 너무 복잡하거나 사실상 구현이 어려웠던 기능까지 가능하게 합니다. 또한 BCDR, 민감 데이터에 대한 세분화된 액세스 제어, CDC 파이프라인 및 스트리밍 수집과 같은 핵심 워크플로우를 자동화함으로써, 단편화된 레이크하우스 환경에서 흔히 발생하는 트레이드오프에 더 이상 얽매이지 않게 합니다. 그리고 Snowflake는 이러한 여정의 모든 단계에서 고객을 지원하기 위해 최선을 다하고 있습니다.
시작할 준비가 되셨나요? 지금 바로 Snowflake에서 Iceberg v3로 구축을 시작할 수 있는 실습 가이드를 확인하고, 공개 미리보기(PuPr) 설명서를 통해 보다 자세한 내용을 알아보세요.





