FEB 03, 2026|8 min de lectura
Modernización de la pila de ML: flujos de trabajo de agentes, multimodales y en tiempo real

El aprendizaje automático (ML) tradicional sigue siendo clave en el panorama actual de la inteligencia artificial (IA) ya que constituye la base de la información predictiva que genera valor para el negocio, desde la optimización de la cadena de suministro hasta la detección de fraude en tiempo real. Sin embargo, el paso de la experimentación a la producción sigue siendo complejo: herramientas fragmentadas en distintos ecosistemas que requieren una configuración compleja, múltiples iteraciones de optimización y un mantenimiento continuo. En Snowflake, nos comprometemos a ofrecer una plataforma de ML moderna, estrechamente integrada con tus datos para unificar la seguridad y acelerar los flujos de trabajo con una escalabilidad que se adapta al ritmo de las necesidades de tu negocio.
Nos complace anunciar que las siguientes capacidades ya están disponibles para tus flujos de trabajo de modelos en Snowflake ML:
Automatizar el desarrollo de flujos de ML totalmente funcionales con prompts sencillos en lenguaje natural desde un entorno basado en Jupyter en Snowflake Notebooks (con disponibilidad general) con Cortex Code en Snowsight (con disponibilidad general próximamente)
Implementar de forma eficiente el modelo con mejor rendimiento al aprovechar Experiment Tracking (con disponibilidad general), integrado de forma nativa, para identificar, compartir y reproducir fácilmente los mejores resultados en distintas ejecuciones de entrenamiento
Ofrecer predicciones de baja latencia en milisegundos con Snowflake Feature Store en línea (con disponibilidad general) e inferencia de ML en línea (con disponibilidad general) para impulsar casos de uso en tiempo real como recomendaciones personalizadas y detección de fraude
Ejecutar workloads de inferencia para modelos multimodales (en vista previa pública) para inferencia a gran escala con datos no estructurados, como imágenes y audio
Desarrollo de modelos de agentes
En Snowflake seguimos invirtiendo en experiencias de desarrollo modernas que mejoran la productividad de los desarrolladores. Hoy reinventamos el ML en producción con el lanzamiento de capacidades de ML de agentes, integradas en una nueva experiencia de entorno de desarrollo integrado (IDE) en Snowflake Notebooks.
Cortex Code para flujos de ML
Los científicos de datos suelen dedicar largos ciclos al desarrollo y la resolución de problemas de los flujos de trabajo de ML, lo que genera cuellos de botella operativos y reduce el número de modelos de ML que llegan a producción. Ahora Snowflake incorpora agentes de IA a los flujos de trabajo de ML desde Cortex Code en Snowsight (con disponibilidad general próximamente) para flujos de trabajo de ML en Snowflake Notebooks, con el fin de iterar, ajustar y generar de forma autónoma un flujo de ML totalmente ejecutable a partir de prompts sencillos en lenguaje natural.
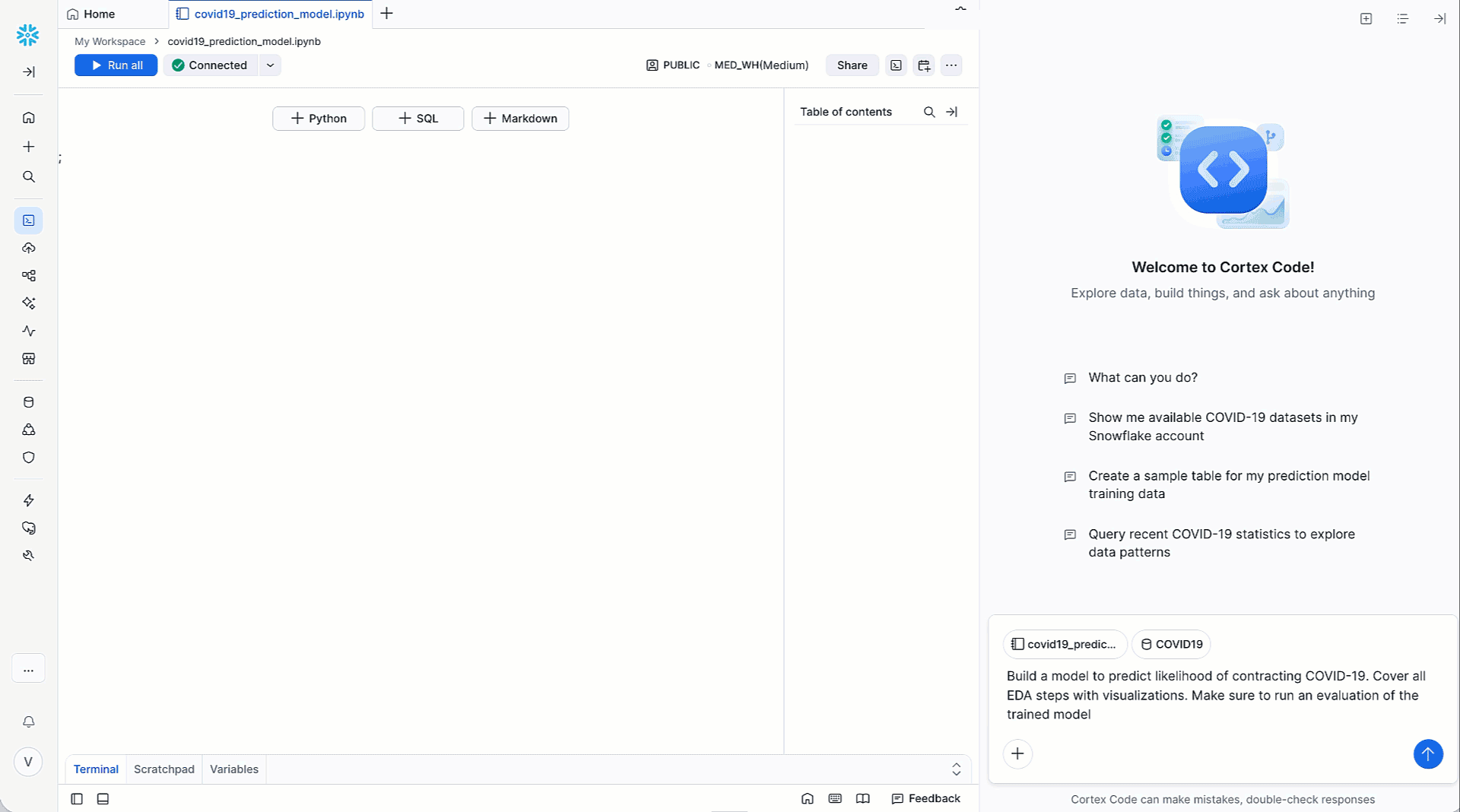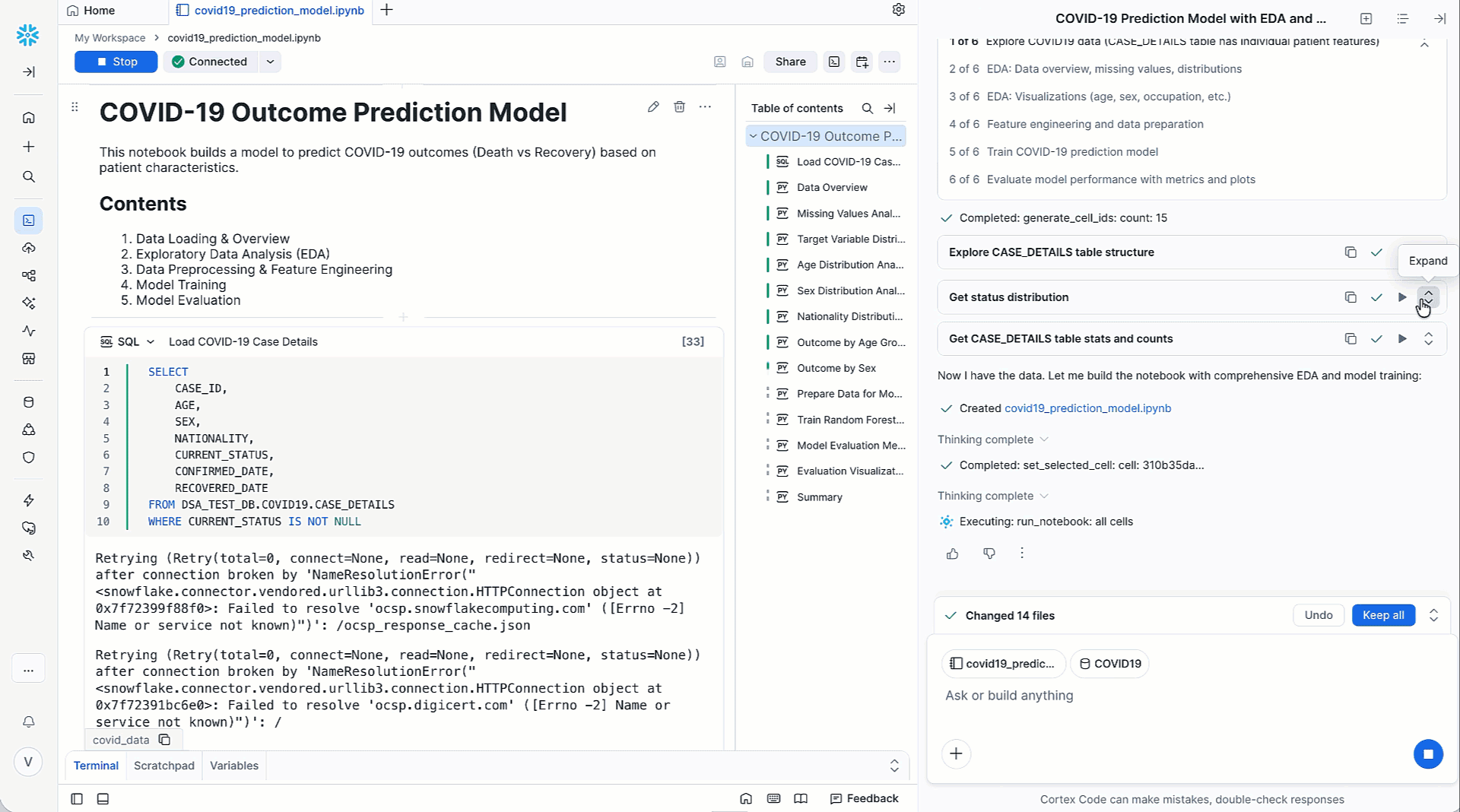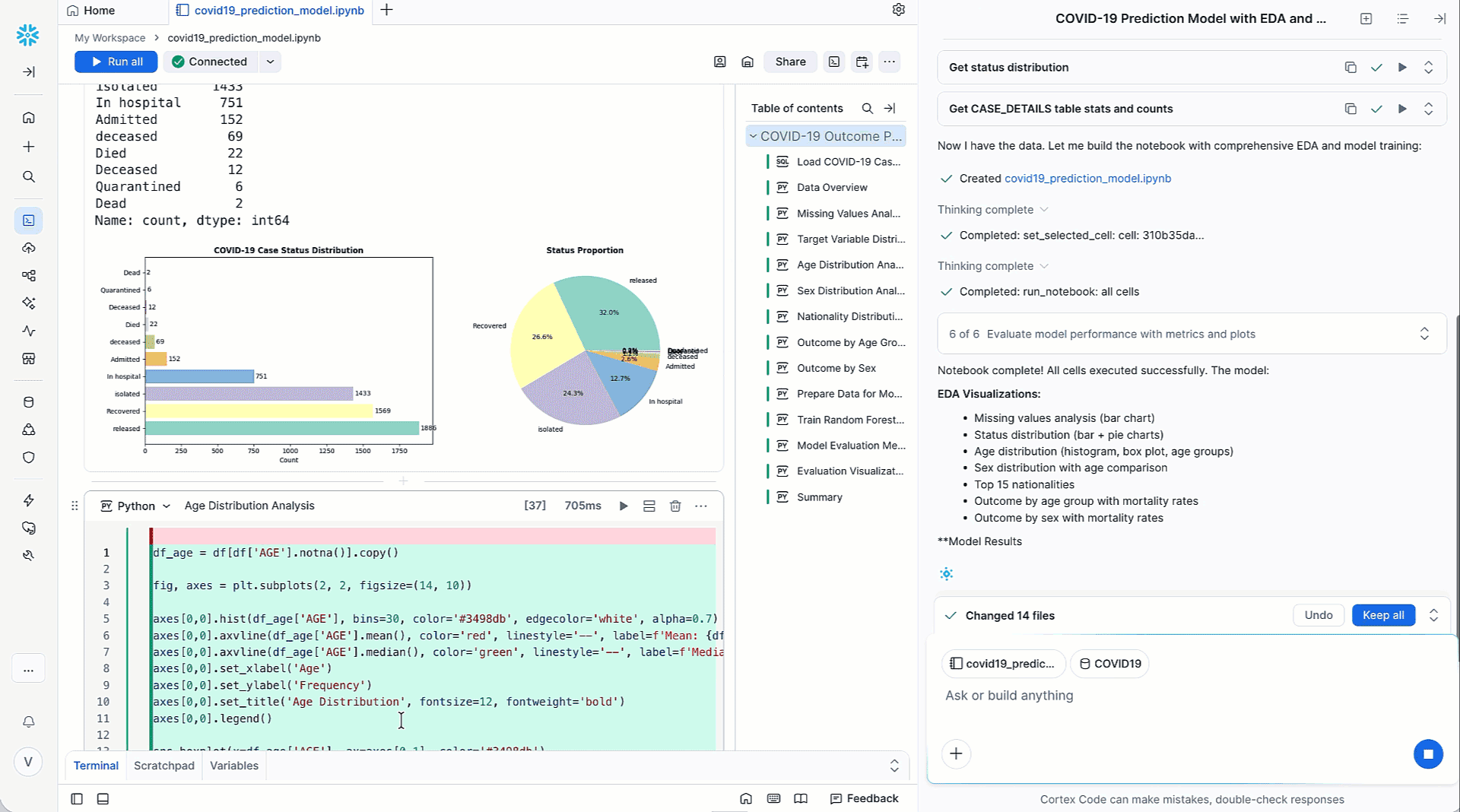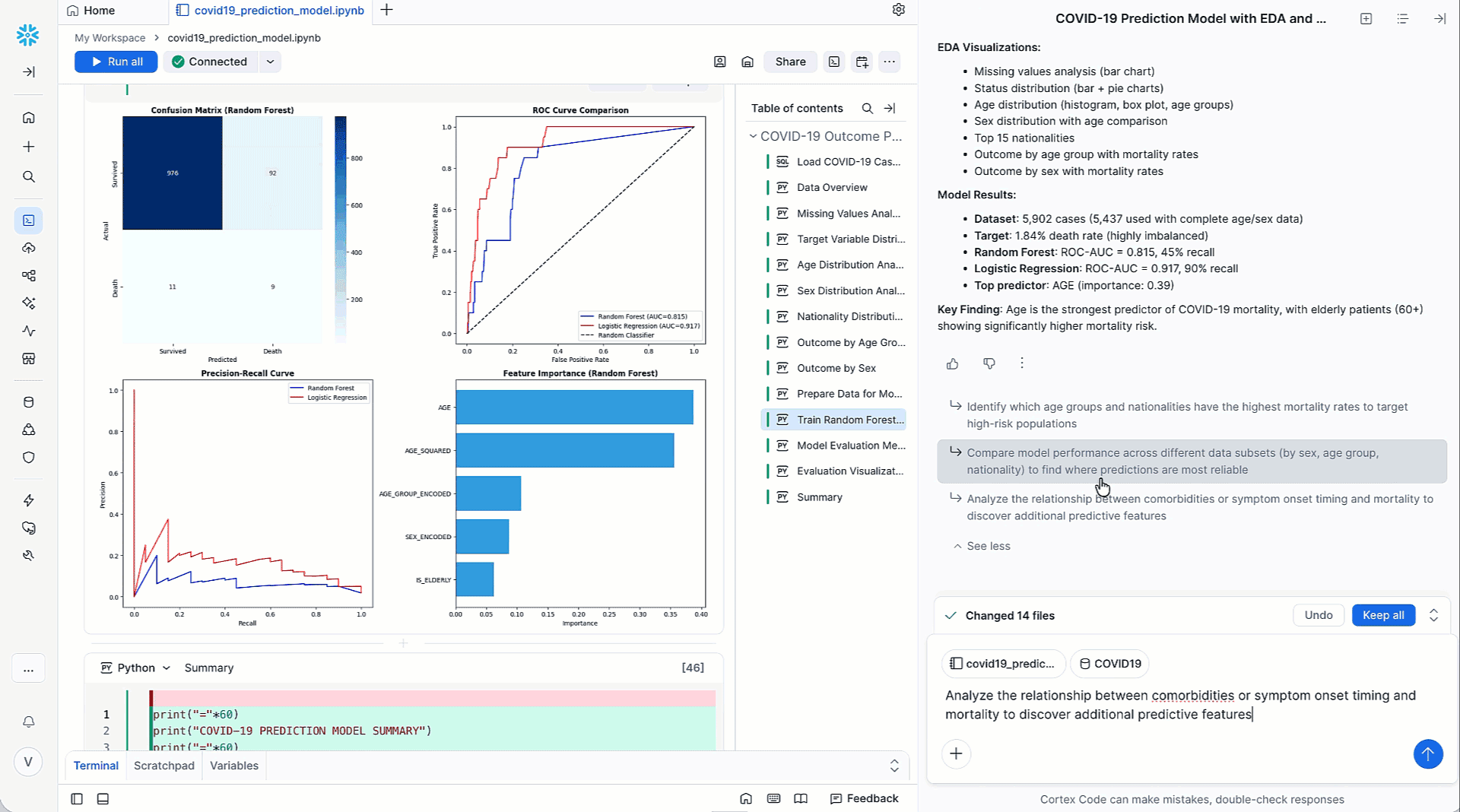
Cortex Code descompone los problemas asociados a los flujos de trabajo de ML en pasos diferenciados, como el análisis de datos, la preparación de datos, la ingeniería de características y el entrenamiento. Al combinar técnicas avanzadas como el razonamiento en varios pasos, la comprensión contextual y la ejecución de acciones, Cortex Code ofrece soluciones verificadas en forma de flujos de ML totalmente funcionales que se pueden ejecutar fácilmente desde Snowflake Notebook. Con mejoras sugeridas o con seguimientos aportados por el usuario, Cortex Code ayuda a iterar fácilmente hacia la siguiente mejor versión. Al automatizar este trabajo tedioso, los equipos de ciencia de datos ahorran horas que normalmente dedicarían a experimentar o depurar, y pueden centrarse en iniciativas de mayor impacto.
Snowflake Notebooks
Cortex Code se puede aprovechar directamente desde Snowflake Notebooks para crear e iterar flujos de trabajo de producción. La experiencia de desarrollo de última generación para Snowflake Notebooks ya está disponible de forma general en Workspaces. Con estos Notebooks basados en Jupyter, puedes incorporar cuadernos, secuencia de comandos y entrenamiento de modelos existentes a la plataforma unificada de Snowflake, y, al mismo tiempo, mantener tus bibliotecas preferidas, las funciones del entorno de ejecución de Jupyter y los atributos de IDE que ya conoces, además de la organización basada en archivos dentro de Workspaces.
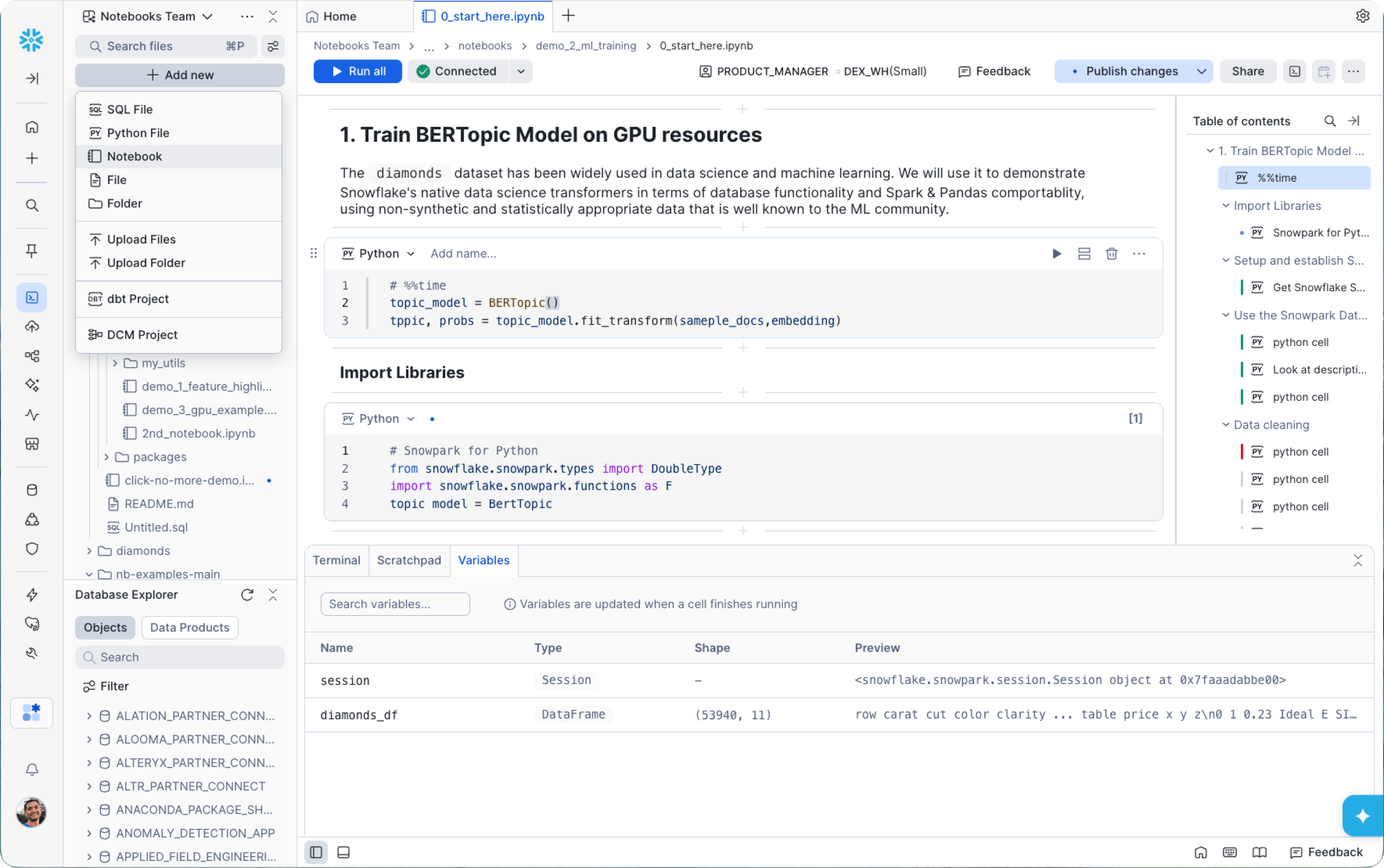
Esta nueva experiencia de desarrollo incluye las siguientes mejoras:
Kernel de Jupyter/IPython gestionado: Ahora los cuadernos se ejecutan en un kernel de Jupyter/IPython gestionado por Snowflake, lo que garantiza la compatibilidad con magics y cuadernos existentes. Esto incluye ejecutar código SQL, Python y Markdown, y transferir datos fácilmente entre celdas. Consulta los resultados en Results Explorer, debajo de cada celda, con tablas y un generador de visualizaciones.
Organización nativa de Workspaces: Ahora puedes crear cuadernos directamente en Workspaces junto con tus archivos SQL, proyectos de dbt, utilidades de Python y cualquier otro recurso que uses para desarrollar en Snowflake. Esto te permite organizarlo todo en un único lugar y hace que los flujos de trabajo de varios archivos resulten naturales. Puedes refactorizar la lógica en funciones auxiliares, dividir los flujos en componentes más pequeños y conectarlos según lo necesites. Nuestro nuevo terminal y el explorador de variables también ofrecen un ciclo de desarrollo más rápido y productivo.
Colaboración fluida con Git como base: Los Workspaces con Git como base ahora te permiten trabajar sin fricciones en todo tu repo: crear ramificaciones, confirmar cambios (commit) y comparar diferencias (diff) directamente desde Snowflake. Y si Git no es tu flujo de trabajo preferido, Share Workspaces ofrece una alternativa para tus equipos: colaboración en un conjunto de archivos, gobernada por control de acceso basado en roles (RBAC), con control de versiones y seguimiento de cambios integrados.
Posibilidad de ejecutar en Snowflake Container Runtime (CPU y GPU): Nuestra nueva experiencia se ejecuta exclusivamente sobre Snowflake Container Runtime, un entorno de ejecución preconfigurado para ciencia de datos y aprendizaje automático que se ejecuta directamente en Snowpark Container Services. Esto ofrece un conjunto de marcos de ML populares y varias versiones de Python, y acelera el entrenamiento y la carga de datos al distribuir los recursos de cómputo. La versión del entorno de ejecución que uses para crear prototipos es la misma que usarás para programar y llevar a producción, lo que elimina los típicos problemas de “pero en mi portátil funcionaba...”.
Empresas globales como Aimpoint Digital, líder en consultoría de datos e IA, están utilizando Snowflake Notebooks para impulsar flujos de trabajo de desarrollo listos para producción.
“La disponibilidad general de Snowflake Notebooks es un momento revolucionario para la experiencia del desarrollador. Hemos podido desarrollar y poner en producción workloads de ML con facilidad, desde precios dinámicos hasta predicciones del comportamiento de usuarios basada en grafos para clientes. El desarrollo en Notebooks en Workspaces nos permite centralizar el código común, mientras se descentraliza lo que los desarrolladores compilan sobre él. Poder hacer referencia a tus celdas SQL en Python, y viceversa, y parametrizar tus Notebooks es un cambio de paradigma. Se acabaron los días de programar procedimientos almacenados; Notebooks habilita la máxima flexibilidad para flujos de trabajo dinámicos, ya sean de ML, IA o ingeniería”.
Christopher Marland
Snowflake Practice Lead, Aimpoint Digital
Para empezar con Snowflake Notebooks, consulta esta guía quickstart sobre el modelado de temas.
Experiment Tracking
Después de crear e iterar con Snowflake Notebooks y Cortex Code, puedes pasar rápidamente de una hipótesis inicial a un modelo de alto rendimiento con Experiment Tracking, integrado de forma nativa (ahora con disponibilidad general). Esto permite a los equipos de ML identificar, compartir y reproducir de forma sistemática los modelos con mejor rendimiento en distintas ejecuciones de entrenamiento. Asimismo, simplifica la colaboración, mejora la reproducibilidad y acelera las iteraciones de modelos en toda la empresa. Con la última versión de Experiment Tracking de Snowflake, puedes registrar sin fricciones millones de métricas generadas durante grandes ejecuciones de entrenamiento, junto con parámetros del modelo, artefactos y metadatos.
Muchas empresas utilizan Experiment Tracking para almacenar, monitorizar y comparar información crítica del entrenamiento de modelos entre ejecuciones, como EnergyHub, que ayuda a las empresas de servicios públicos y a sus clientes a impulsar un futuro energético limpio y distribuido.
“Como pioneros en la adopción de Experiment Tracker de Snowflake, hemos descubierto que satisface nuestras necesidades al tiempo que elimina la molestia de mantener un servidor MLFlow independiente. Consolidar el seguimiento de experimentos de ML dentro de nuestra plataforma de Snowflake ha sido un logro operativo significativo. Además, Snowflake ha sido increíblemente receptivo a los comentarios, lanzando mejoras a un ritmo impresionante”.
Dr. Wiliam Franklin
Principal Machine Learning Scientist, EnergyHub
Ejecución de servicios en tiempo real
Una vez que hayas entrenado tu modelo en Snowflake o en cualquier otra plataforma externa, puedes implementarlo fácilmente para realizar inferencias sobre datos de Snowflake y generar resultados predictivos. Presentamos nuevas capacidades de ML en línea listas para producción, con disponibilidad general, para habilitar casos de uso en tiempo real como recomendaciones personalizadas y detección de fraude, sin infraestructura adicional ni configuraciones complejas. Ahora los desarrolladores pueden eliminar la latencia, el coste y los riesgos de seguridad asociados a la exportación de datos confidenciales a plataformas externas al unificar los casos de uso de ML por lotes y en línea en una única plataforma.
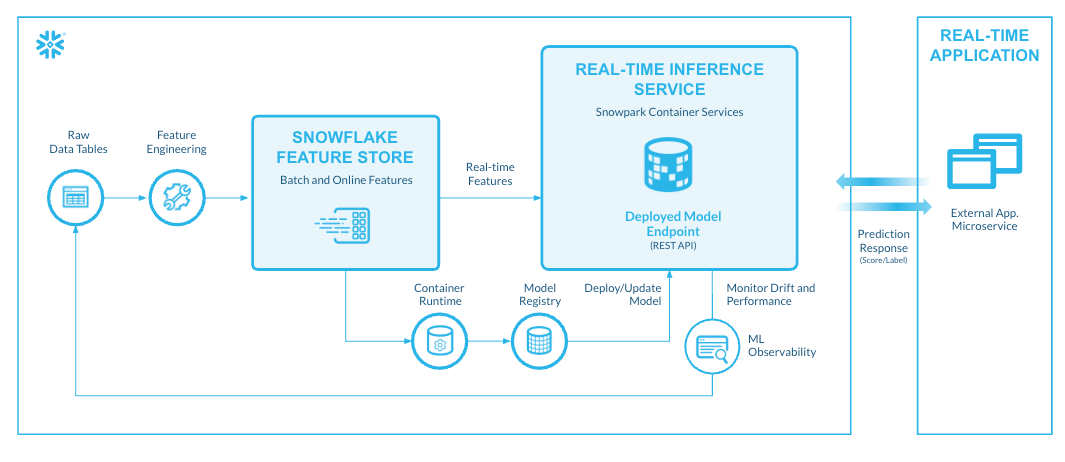
Snowflake Feature Store
Nos complace anunciar la disponibilidad general de la capacidad de ejecución de características en línea de Snowflake Feature Store. Snowflake Feature Store es una solución integrada para que los científicos de datos e ingenieros de ML creen, almacenen, gestionen y ofrezcan características de ML para la inferencia y el entrenamiento de modelos. Consta de API de Python e interfaces SQL para definir, gestionar y recuperar características, junto con infraestructura gestionada para la gestión de metadatos de características y el procesamiento continuo de características. Con la capacidad de ejecución de características en línea, Snowflake Feature Store actúa como una solución unificada tanto para casos de uso en línea de baja latencia como por lotes, proporcionando características en 30 ms.
Snowflake Feature Store se integra de forma nativa con tus datos, características y modelos en Snowflake, para que los flujos de ML a gran escala puedan llevarse a producción de forma sencilla y eficiente. Esto elimina la redundancia y la duplicación de flujos de características, y garantiza que los clientes dispongan de características coherentes, actualizadas y precisas, con seguridad y gobernanza a nivel empresarial. Una interfaz de usuario centralizada en Snowsight para la ejecución de feature store facilita la búsqueda y el descubrimiento de características y modelos, así como la visualización del flujo de datos mediante el linaje.
Si deseas empezar hoy mismo con Snowflake Feature Store para la ejecución de características en línea, consulta esta guía quickstart.
Inferencia de ML en línea
Inferencia de ML en línea está también disponible de forma general, lo que te permite ejecutar modelos desde el Snowflake Model Registry para inferencia en tiempo real en menos de 100 ms.
Para satisfacer las rigurosas exigencias de los workload de producción, la inferencia de ML en línea integra escalabilidad automática inteligente, rendimiento de baja latencia y observabilidad integral en un flujo de trabajo cohesionado. Se parte de un rendimiento rentable: nuestra lógica de escalabilidad automática gestiona al instante grandes picos de tráfico y escala a cero cuando baja la demanda, lo que elimina el costoso sobrecoste de GPU sobreaprovisionadas. Y, lo que es clave, cuando el tráfico vuelve a aumentar, el sistema está diseñado para responder de inmediato, garantizando que los modelos se amplíen rápidamente para mantener un rendimiento por debajo de 100 ms.
La implementación es igual de resiliente: permite pasar a nuevas versiones del modelo mediante actualizaciones progresivas automatizadas que garantizan que el tráfico de la aplicación nunca se interrumpa, con la seguridad adicional de poder revertir versiones fácilmente. Los equipos también pueden aprovechar el modo sombra para validar nuevos modelos de forma segura, supervisando el rendimiento en un entorno paralelo, aislado de la versión de producción, antes de realizar el cambio definitivo. Snowflake también facilita la visibilidad inmediata de la latencia, el rendimiento y las tasas de error con una observabilidad integrada que registra todas las solicitudes y respuestas directamente en una tabla de Snowflake, para una depuración en profundidad y auditorías a largo plazo.
Inferencia para modelos multimodales
Además, ahora es fácil ejecutar inferencia en línea y por lotes a gran escala con la compatibilidad de inferencia de Snowflake para modelos multimodales de código abierto de plataformas como Hugging Face. La compatibilidad de inferencia para datos no estructurados ya está disponible en vista previa pública e incluye tipos de datos como imágenes, vídeo y audio. Esta capacidad impulsa casos de uso de IA como la detección de objetos, las preguntas y respuestas visuales y el reconocimiento de voz automático en Snowflake, sin flujos complejos ni movimiento de datos.
Snowflake admite tanto las necesidades de procesamiento en tiempo real como por lotes. Los usuarios pueden implementar modelos multimodales como servicio para la inferencia en línea mediante REST API o registrarlos en el Snowflake Model Registry para su invocación inmediata por lotes. Al aprovechar la capa de cómputo distribuido de Snowflake, los equipos pueden ejecutar tareas de inferencia enormes sobre grandes conjuntos de datos sin salir de su entorno habitual.
Primeros pasos
Con esta nueva oleada de innovaciones en capacidades de agentes, en línea y multimodales, Snowflake ML acelera aún más el aprendizaje automático, del prototipo a producción, en la misma plataforma que tus datos gobernados.
Consulta nuestra documentación técnica de productos y prueba Snowflake ML hoy mismo con esta guía quickstart de introducción de la prueba gratuita de 30 días.
Artículo de



Solo para ti
FEB 03, 2026|6 min de lectura

FEB 04, 2026|13 min de lectura