
MAY 29, 2025|15 min read

Many real world AI use cases — like analyzing dense documents, long chat conversations or RAG pipelines — easily span hundreds of thousands of tokens. But most models are trained on short text fragments. It’s like asking a model to summarize a novel after only reading one page. It may capture the voice or style, but completely misses the story arc. To reason across long context, models must be trained on long context.
Even though models like Llama 3.x and Qwen 2.5 32B now support 128k-token sequences, and Llama variants can stretch up to 10M, fine-tuning at these lengths to enhance task-specific capabilities remains out of reach for most data scientists. The primary bottleneck is GPU memory. Most training pipelines are designed for short sequences, not millions of token inputs. As a result, training at scale is limited to teams with access to sophisticated enterprise training systems.
The open source release of Arctic Long Sequence Training (ALST) addresses this gap. It’s a set of modular, open source techniques that enable Meta’s Llama-8B training on sequences up to 15 million tokens on 4 H100 nodes, all using Hugging Face Transformers and DeepSpeed, with no custom modeling code required. ALST makes long-sequence training fast, efficient and accessible on GPU nodes or even single GPUs.
Using these methods, we trained sequences of 500K tokens on a single H100 GPU, 3.7M on a single node, and 15M on Llama-8B using just four nodes — representing respective 16x, 116x and 469x improvements in max trainable sequence lengths vs. standard Hugging Face pipelines (see figure below).
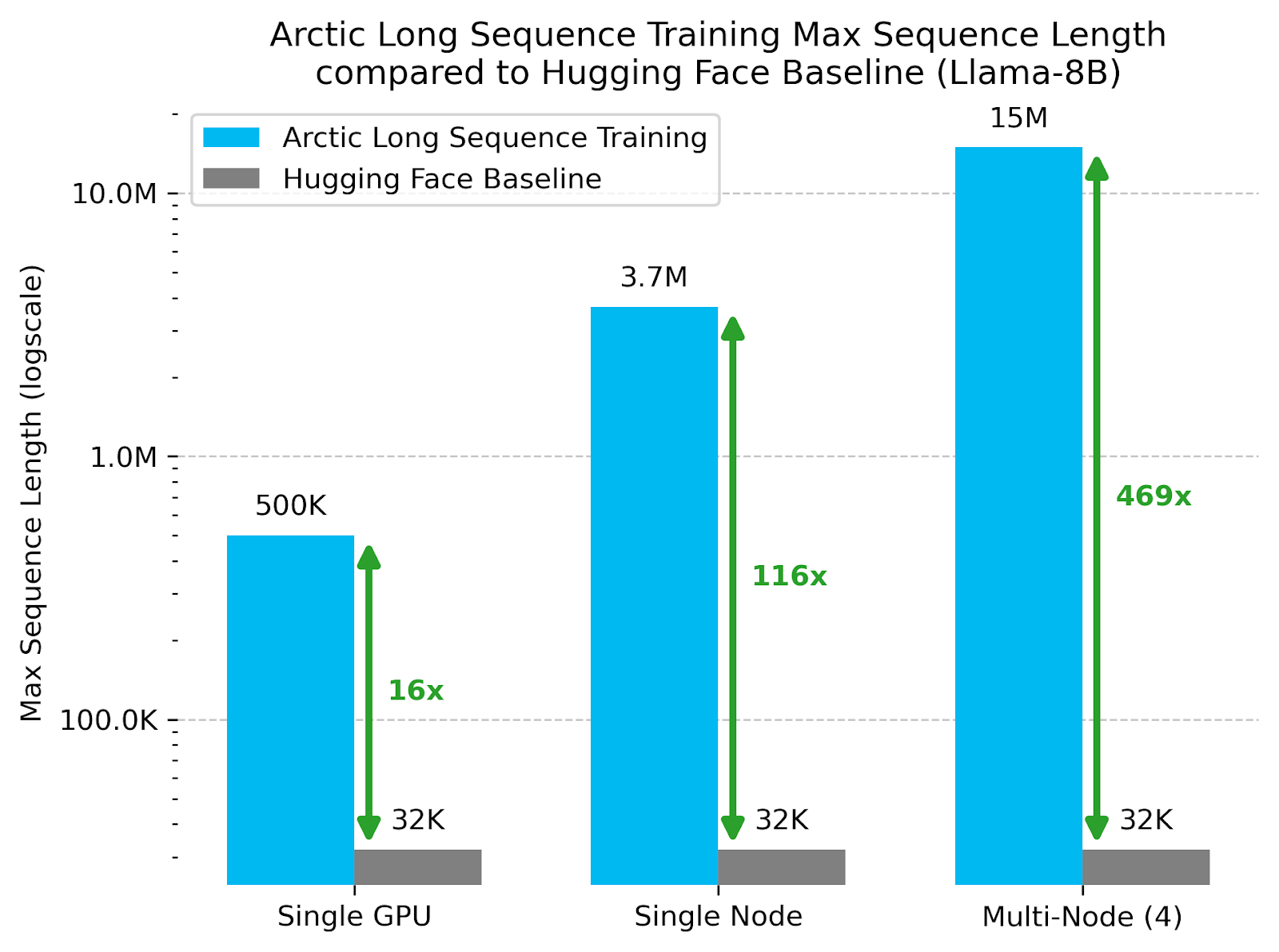
For full methodology and reproducibility benchmarks, check out the ALST paper.
In the rest of this blog post, we’ll explain what makes long-sequence training so challenging, how Arctic Long Sequence Training works, and how you can use it today.
Training language models on very long sequences sounds simple: Just give the model more tokens, right? Unfortunately, in practice, it quickly runs into major GPU memory bottlenecks.
Here’s why:
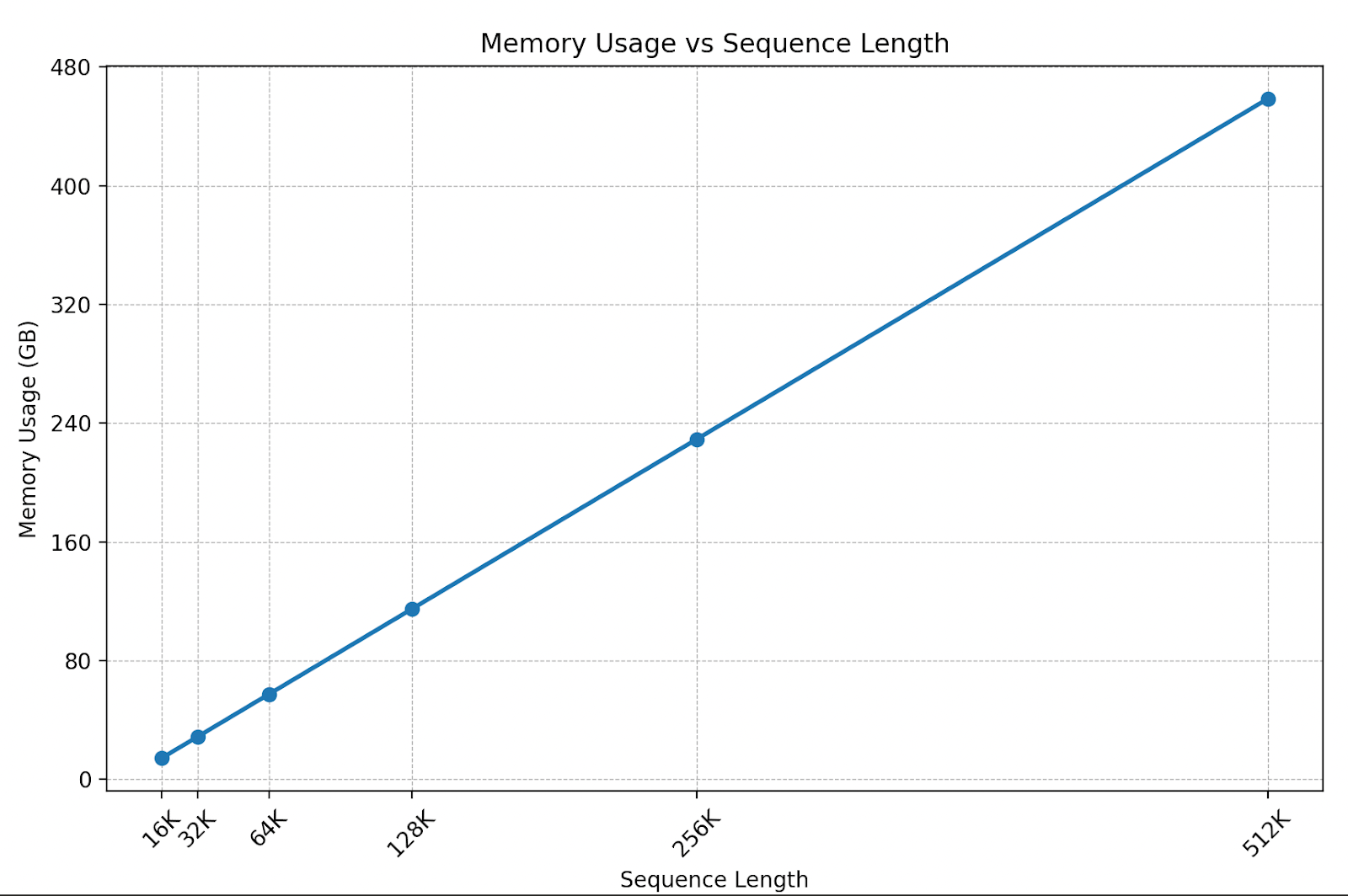
Memory explodes with sequence length. As inputs get longer, the model must store more intermediate results (called activations) in GPU memory for backpropagation. Activation memory size grows linearly with sequence length, while memory for self-attention grows quadratically.
The following chart shows what that looks like in practice for Llama-3.1-8B. As the sequence length grows from 16K to 512K, the required activation memory shoots past 400 GB, far bigger than any single GPU can handle.
Most training frameworks assume short sequences. Tools like Hugging Face Transformers are optimized for inputs around 2K to 32K tokens. They lack built-in strategies for handling the memory and compute demands of multimillion-token training.
Inefficient memory handling in PyTorch. Additional GPU memory is consumed due to fragmentation, poor memory reuse and inefficient checkpointing and communication strategies.
Inflexible memory distribution methods. Some techniques like Ring Attention can distribute memory across GPUs, but they only support specific attention mechanisms and require massive changes to modeling code. They often fail with formats like block sparse or MoBA, which are commonly used in long-context models.
Arctic Long Sequence Training was built to change that.
Arctic Long Sequence Training (ALST) overcomes the memory bottlenecks of long-context training, without requiring changes to modeling code.
ALST layers together three complementary techniques: sequence parallelism, sequence tiling compute and a set of PyTorch-level memory optimizations to reduce runtime overhead and extend sequence length even further.
Traditionally, models process every token in a sequence on the same GPU. As sequences grow longer, memory consumption explodes, especially in attention layers, causing training to crash and forcing developers to shorten their inputs.
Our unique approach to sequence parallelism as conceived by Ulysses SP solves this by splitting long-input sequences across multiple GPUs. Instead of giving the full sequence to each GPU, Ulysses SP divides the sequence into chunks. Each GPU processes its corresponding chunk, dramatically reducing memory requirements on any one device. This enables models to scale to much longer sequences without hitting memory limits.
But attention layers require the full sequence length to compute correctly. To support that, ALST dynamically switches to head parallelism just for the attention computation, distributing the attention head projections across GPUs and letting each head process the full sequence length. After the attention step, training returns to sequence-parallel execution. The following diagram depicts that.
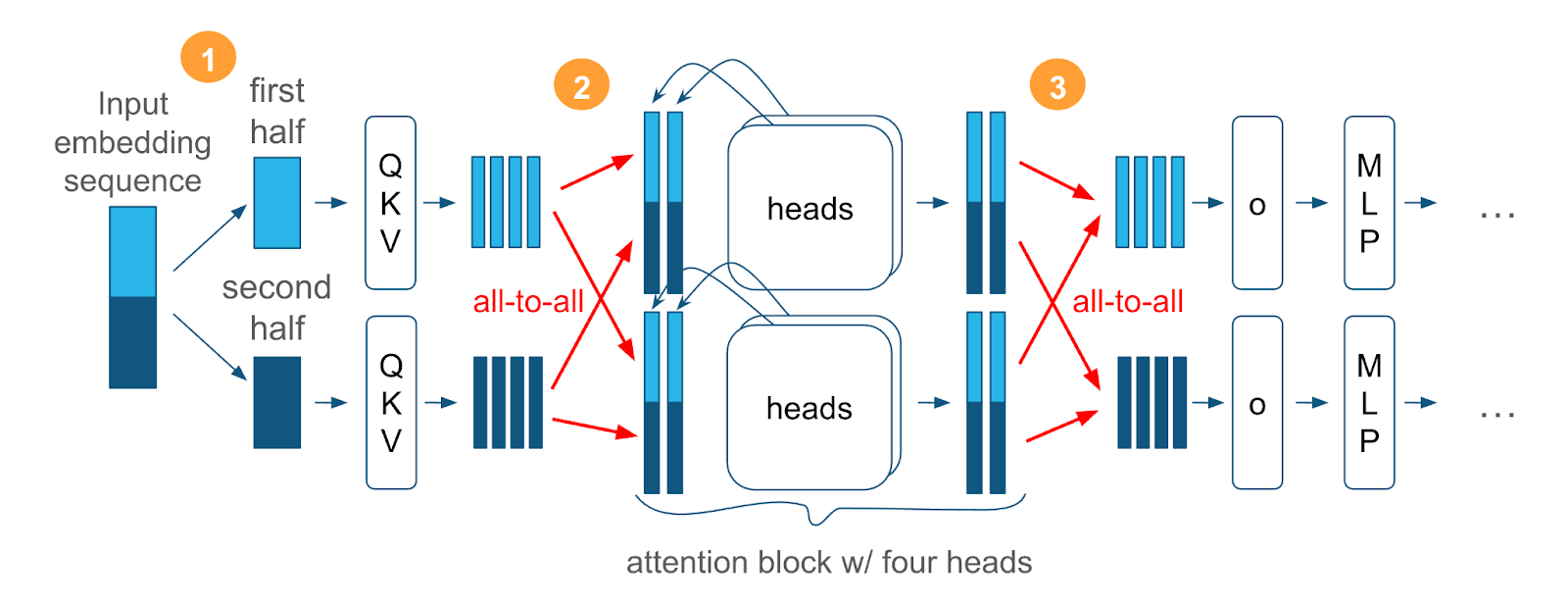
Check out the ALST paper to learn more about how Ulysses SP supports an attention-agnostic mechanism by distributing key/value head projections across GPUs and gathers back the partial activations.
Even with Ulysses Sequence Parallelism, some layers in the model, such as multilayer perceptrons (MLP), embeddings and loss computation still try to process large chunks at once. At long sequence lengths, these layers become the bottleneck, requiring more memory than a single GPU has.
To address this, ALST uses a technique called Sequence Tiling. Instead of processing the entire sequence chunk in one step, ALST breaks it into smaller tiles and processes them one tile at a time. This reduces the amount of memory needed at any one time during both the forward and backward passes, and it lets the GPU handle long sequences without running out of memory.
For example, imagine a sequence of 8 tokens split across 2 GPUs, which results in 2 chunks of 4 tokens each. Tiling each of those chunks then could process one token at a time, instead of all 4 at once. Now scale that up: With 1 million tokens and 8 GPUs, each GPU gets a chunk of 125K tokens with sequence parallelism. Tiling could break those into 1K-token slices, processed one at a time, keeping memory use low.
We called this reusable mechanism TiledCompute, which automatically applies to operations that don’t require interaction across tokens, such as linear layers, embedding lookups and per-token logits plus loss calculations. This results in a significantly lower memory overhead, especially at extremely long sequence lengths.
Figure 4 below shows the impact of sequence tiling compute on memory requirements. Please refer to the ALST paper for an in-depth dive of this versatile feature.
Even with sequence parallelism and tiling, memory inefficiencies in the PyTorch runtime can still limit the possible sequence length. ALST includes a set of runtime-level optimizations to reduce memory fragmentation, offload unnecessary at the moment tensors, and push hardware efficiency further, without modifying the modeling code.
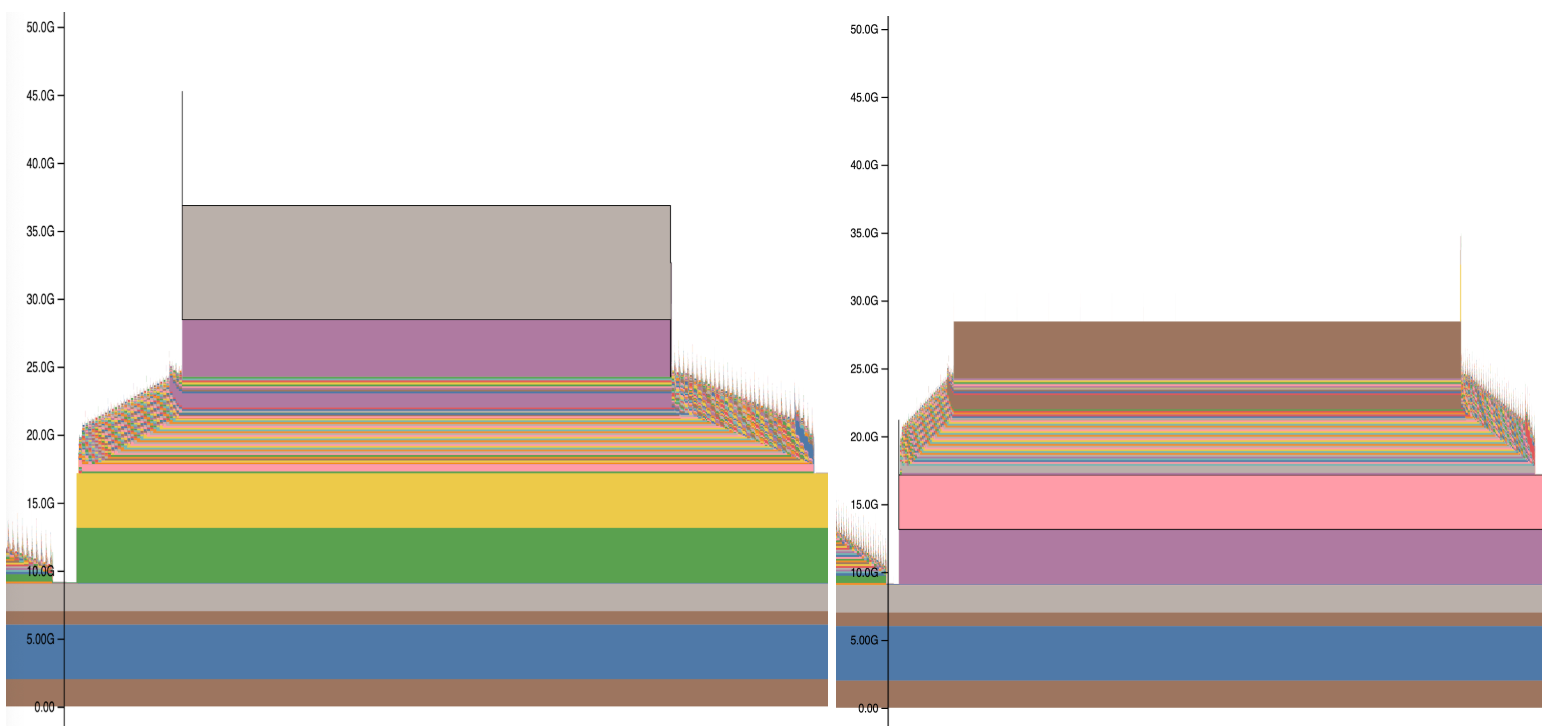
One of the most impactful of these is activation checkpoint offloading to CPU memory.
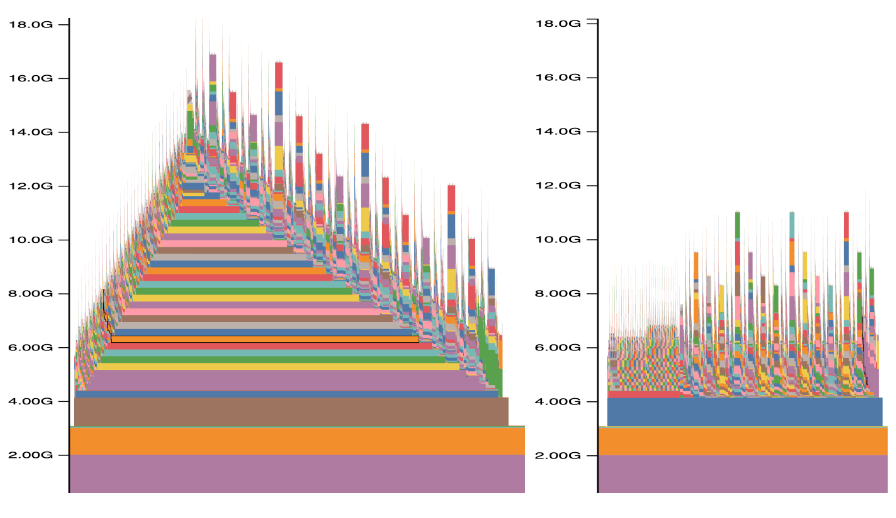
For extremely long sequences, even when activation checkpointing is enabled, the checkpointing tensors are still too large for the available GPU memory. ALST offloads activation checkpoints to CPU memory. Since long sequence length computation dominates the workload, the overhead of copying to and from the CPU memory has a minimal impact on performance, but significantly lowers peak GPU memory usage.
The difference is clearly visible via memory profiling. Figure 5 shows CUDA memory usage during a single forward-backward pass: The left side shows the memory usage pattern without activation checkpoint offloading, while the right side shows the same pass with it enabled.
Additional runtime optimizations:
Memory allocator: We enable PyTorch’s expandable segments memory allocator to reduce fragmentation at large sequence lengths.
Collectives and APIs: We avoid all_reduce_object, which adds more than 3GB of GPU memory overhead per GPU, and use all_reduce instead everywhere.
Version tuning: We observed excess memory usage (~3GB per GPU) in PyTorch 2.6–2.7 due to a dist.barrier issue, so we used PyTorch version 2.8.0.dev20250507 (aka nightly) for our experiments, but the recently released 2.7.1 should work just as well.
Efficient position encoding: For long sequences, a 4D attention mask becomes impractically large due to its quadratic to sequence length nature. ALST uses 1D position ids instead, maintaining efficiency and correctness when using packed samples.
Check out the ALST paper for a deep dive into these runtime-level improvements.
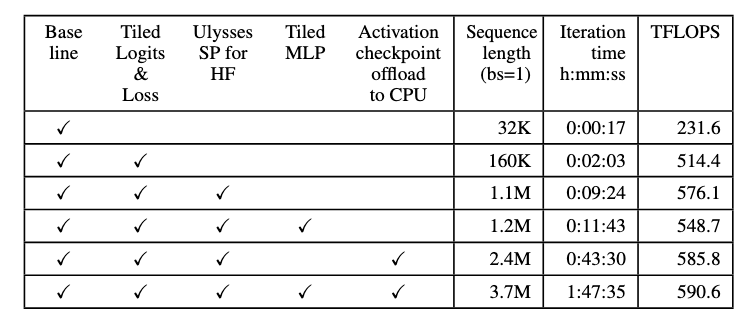
To understand the impact of each optimization, we performed a feature ablation study using Llama-8B across eight H100 GPUs. Each setup adds one new ALST component to measure its contribution.
We also measured TFLOPS (tera floating point operations per second), a standard metric for GPU utilization throughput. It reflects how many trillions of floating-point operations are executed per second (higher values indicate more efficient GPU utilization during training).
As can be seen from the following table and its plot, with each addition, max trainable sequence length increases significantly, from just 32K up to 3.7M tokens, while the TFLOPS metric remains strong, even at long contexts.
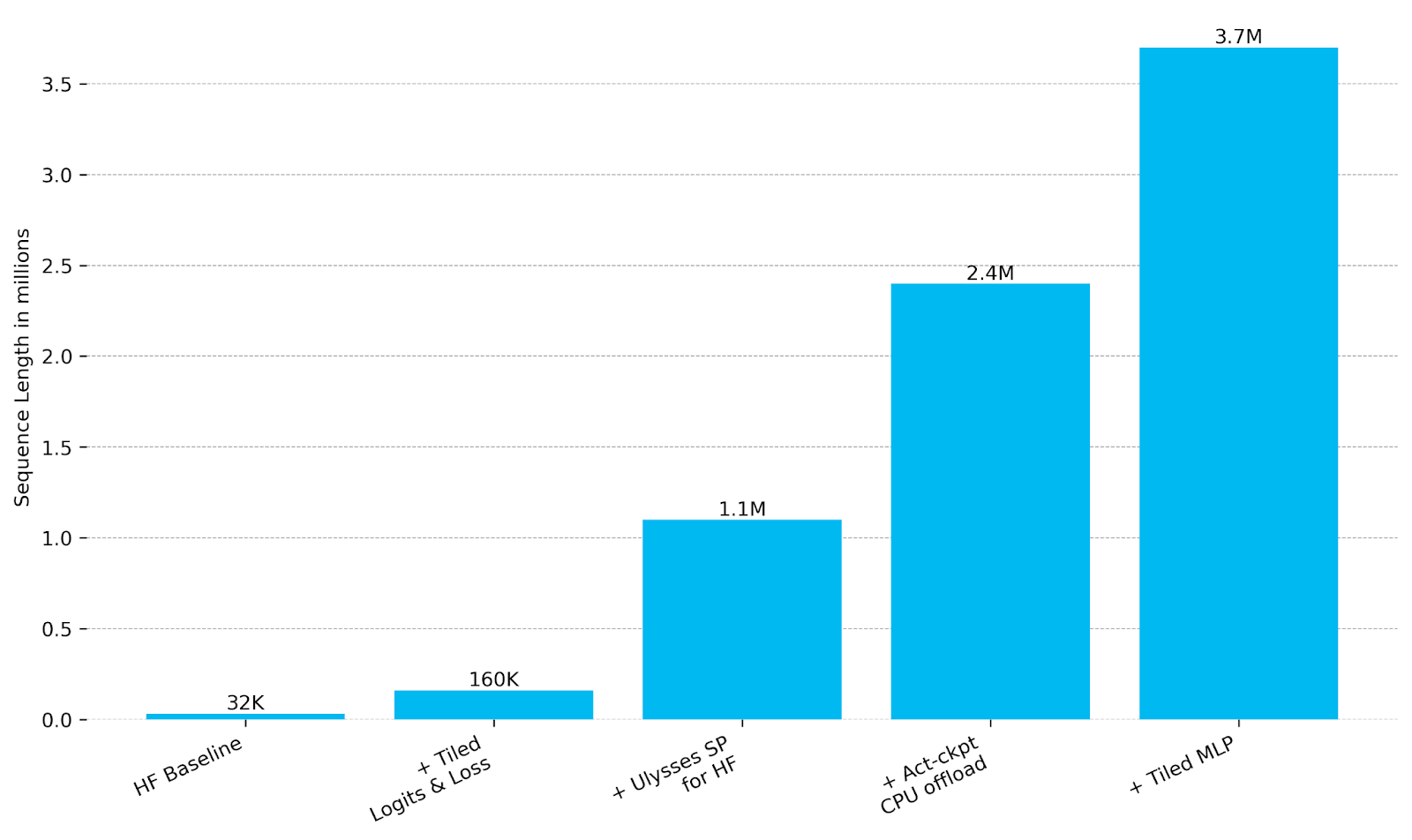
To visualize the trend more clearly, Figure 6 below charts the max trainable sequence length as each optimization is introduced. The progression highlights how ALST scales training from just 32K tokens up to 3.7M tokens, showing how each technique unlocks longer contexts without degrading efficiency.
Efficiency only matters if the model still learns correctly.
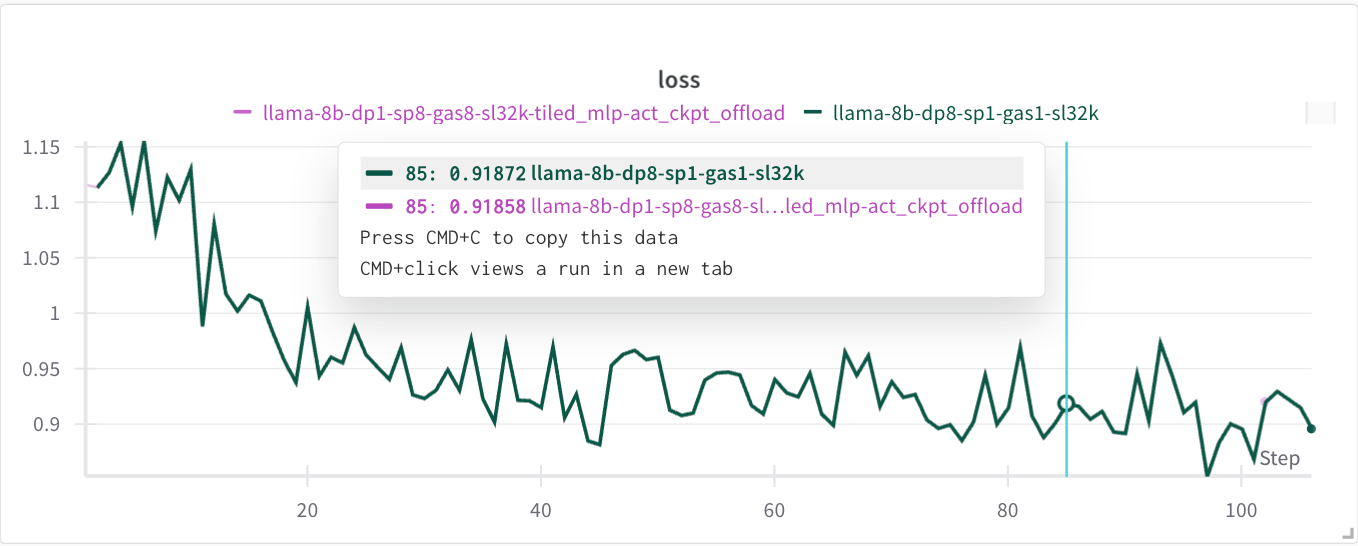
To ensure ALST maintains training quality, we ran a controlled comparison against a standard Hugging Face pipeline. Both setups trained Llama-8B on 32K-token sequences using eight H100 GPUs. Since ALST uses all 8 GPUs to process a single sample, we enabled gradient accumulation steps of 8 to match the effective batch size. We chose 32K because it’s the longest sequence length the baseline Hugging Face setup could handle, making it the highest fair comparison point.
As shown in Figure 7 below, the training loss curves from ALST and the Hugging Face baseline are nearly identical, converging at the same rate and to the same values. This validates that ALST preserves correctness, even as it changes how memory and compute are managed under the hood.
Check out the ALST paper for a deeper dive into each feature ablation and our evaluation methodology.
Ready to try it yourself? The open source ArcticTraining GitHub repo includes working out-of-the-box ALST post-training recipes. Simply follow the README instructions to reproduce any results from this blog, or swap in your own dataset to run your own custom long-sequence workloads.
To better understand how much GPU memory is required for your model we have created a helpful interactive Streamlit memory calculator to better understand these requirements.
Have you built something cool using this tech? Share what you’ve built in GitHub Discussions — we’d love to see it!
The following people and teams contributed to this work:
The Snowflake AI Research team: Stas Bekman, Samyam Rajbhandari, Michael Wyatt, Jeff Rasley, Tunji Ruwase, Zhewei Yao, Aurick Qiao and Yuxiong He
The HuggingFace team: Cyril Vallez, Yih-Dar Shieh and Arthur Zucker
The PyTorch team: Jeffrey Wan, Mark Saroufim, Will Constable, Natalia Gimelshein, Ke Wen and albanD
Blog post reviewer: Krista Muir
The original Ulysses for Megatron-DeepSpeed team: Sam Ade Jacobs, Masahiro Tanaka, Chengming Zhang, Minjia Zhang, Shuaiwen Leon Song, Samyam Rajbhandari and Yuxiong He









