사용 사례
Snowflake데이터 파이프라인
파이프라인을 며칠이 아닌 몇 분 만에 구축, 배포, 확장할 수 있습니다. 통합 데이터 엔지니어링 워크플로우가 복잡한 작업을 자동화하여 인프라 관리 대신 고품질 데이터 제공에 집중할 수 있도록 지원합니다





개요
ZeroOps 파이프라인 개발로 워크플로우 현대화
Snowflake는 탁월한 성능과 오픈 소스 기반의 유연성을 결합하여 아키텍처 오버헤드 없이 데이터에 소프트웨어 엔지니어링 수준의 엄격함을 적용할 수 있도록 지원합니다

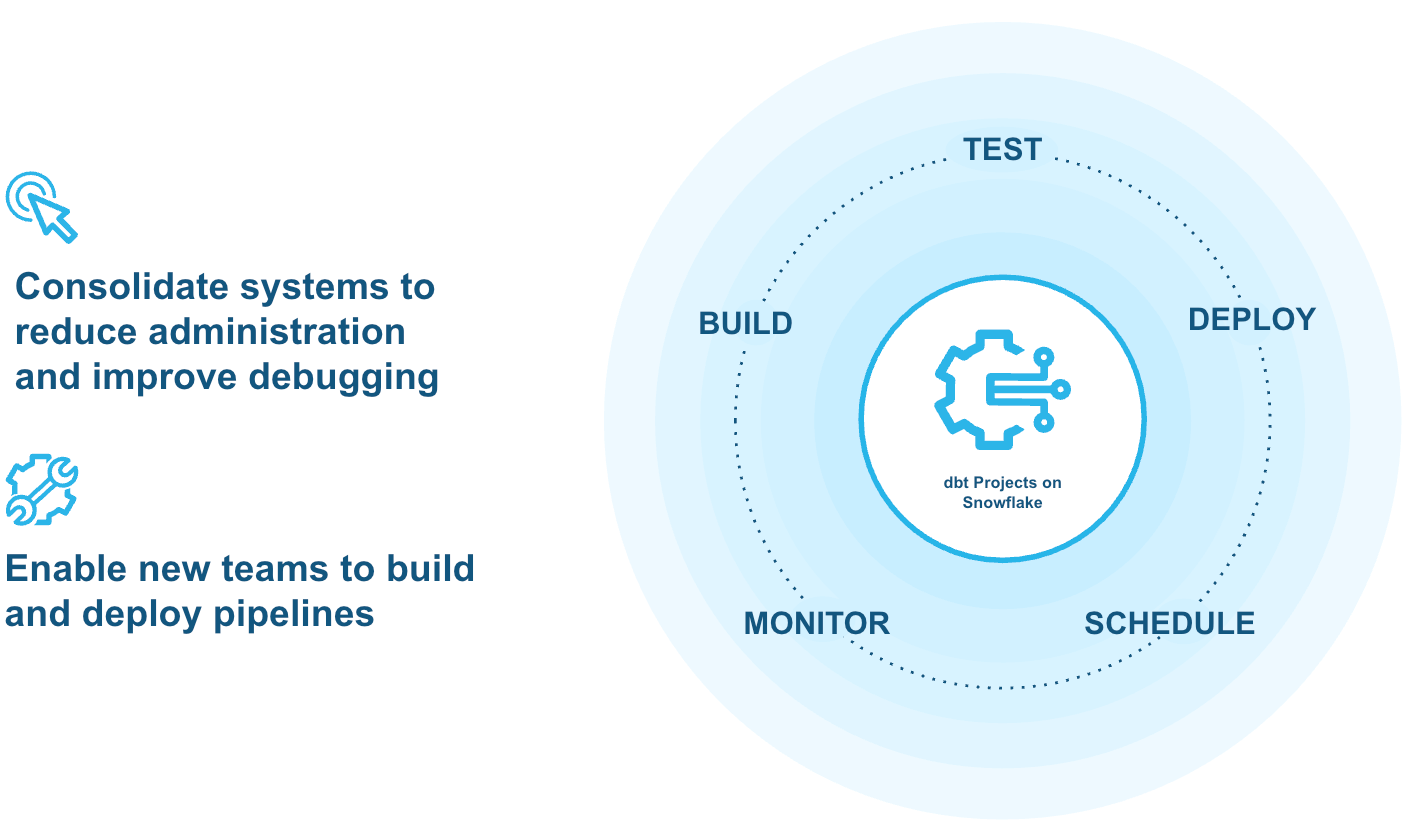
단일 통합 엔진에서 파이프라인 개발 표준화
Snowpark, Dynamic Tables, 네이티브 dbt 프로젝트를 포함하는 통합 환경에서 데이터 파이프라인을 구축, 테스트 및 배포합니다. 분산된 도구 관리를 중단하고 통합된 엔터프라이즈급 워크플로우를 통해 Snowflake에서 직접 데이터 엔지니어링을 확장할 수 있습니다.

운영 오버헤드와 성능 병목 현상 제거
관리형 컴퓨팅을 활용하면 더 이상 인프라 튜닝 작업이 필요 없습니다. 이제는 고성능으로 최적화된 서버리스 변환과 오케스트레이션 옵션에 모두 맡기세요.
팀과 함께 실무에 AI 적용
Snowflake Workspaces의 목적에 맞게 설계된 IDE와 통합된 지능형 코딩 어시스턴트 Cortex Code를 통해 개발 속도를 가속화할 수 있습니다.
이점
Snowflake SQL과 Python 활용을 통한 구축 및 오케스트레이션
고급 선언형 워크플로우
단순한 데이터 이동을 넘어서는 표현력 높은 파이프라인 구축
Dynamic Tables를 활용한 효율적인 증분 업데이트로 수동 오케스트레이션의 필요성을 제거하고 리소스 사용을 줄일 수 있습니다.
dbt 프로젝트를 통해 Snowflake 내에서 직접 데이터 변환을 구축, 테스트, 배포 및 모니터링할 수 있습니다.
데이터 엔지니어링을 위해 설계된 전용 IDE인 Workspaces로 개발을 가속화할 수 있습니다.
- 지능형 코딩 어시스턴트 Cortex Code를 통해 데이터 엔지니어링 작업을 보강할 수 있습니다.
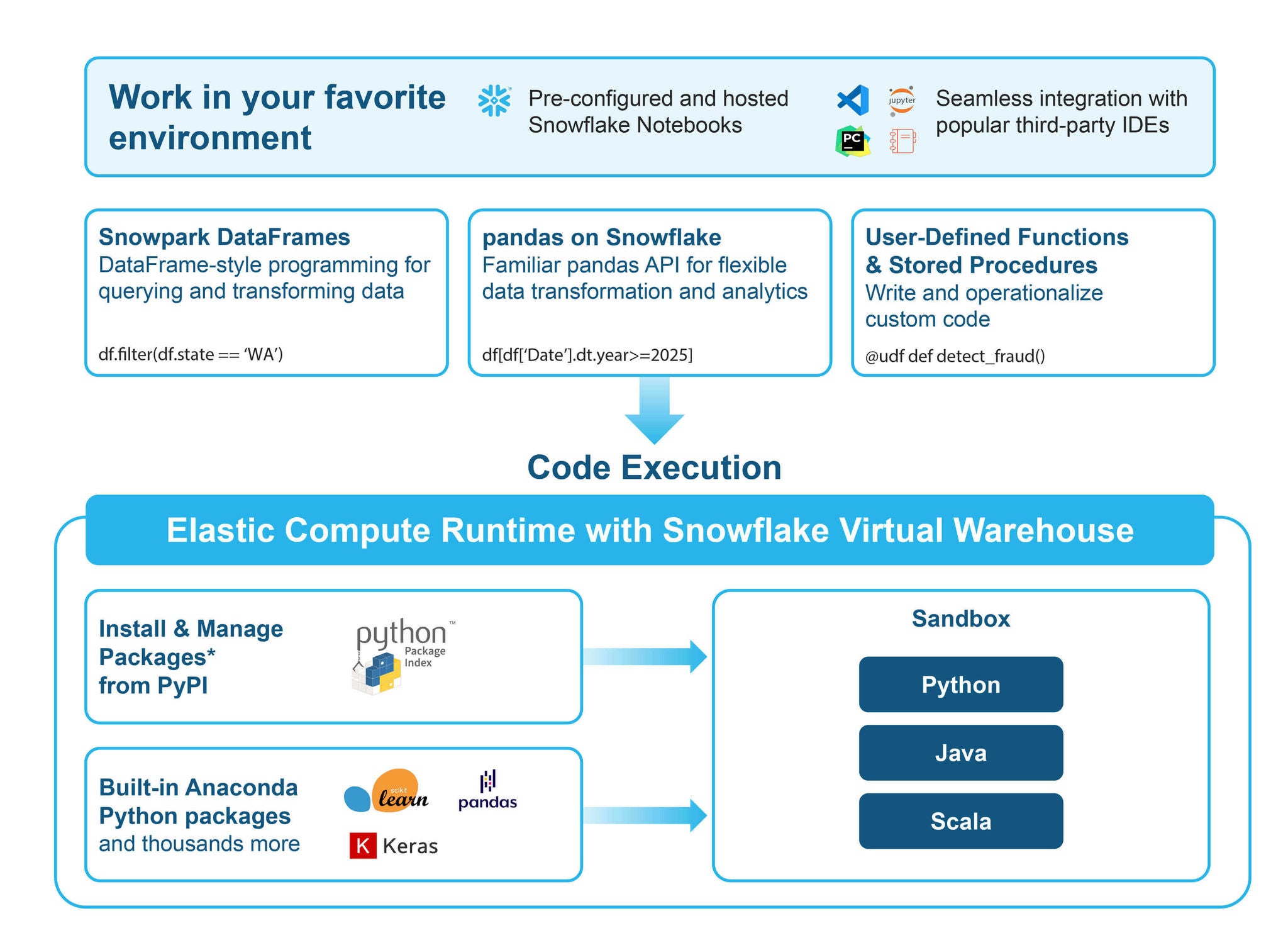
Apache SparkTM 및 Python 파이프라인 가속화
엔터프라이즈 규모의 고성능 파이프라인 실행
Snowpark Connect를 사용해 기존 Apache Spark 코드를 Snowflake 엔진에서 실행할 수 있으며 이제 Java, Scala, Python을 지원합니다.
Snowpark의 네이티브 Python 지원을 활용해 다양한 데이터 소스에 원활하게 액세스할 수 있으며 DB-API를 통한 외부 데이터베이스부터 Rowtag reader를 활용한 XML 파일까지 새롭게 확장된 기능을 사용할 수 있습니다.
운영 오버헤드 없이 더 빠른 성능과 비용 절감을 실현할 수 있습니다.
자동화 추가
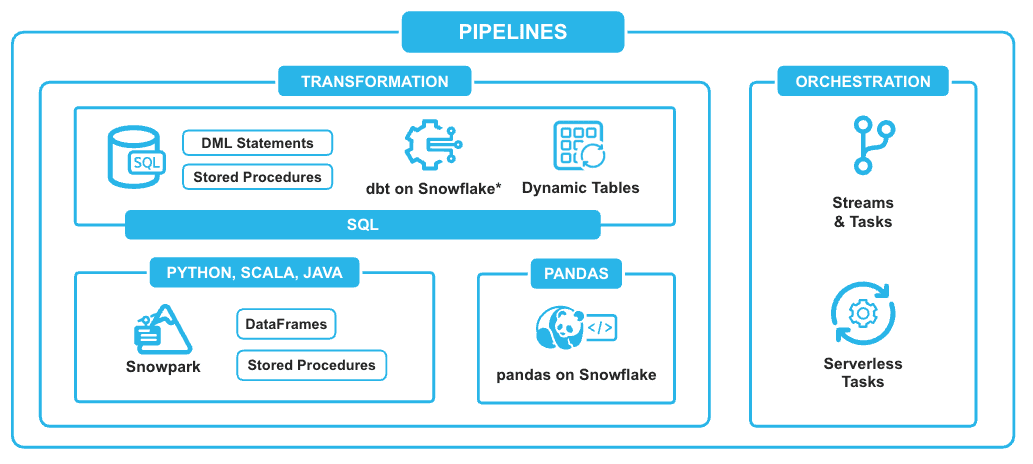
데이터 파이프라인 오케스트레이션
- 자동화된 오케스트레이션이 변환 워크플로우에 내장되어 운영 오버헤드 없이 일관된 실행을 위한 안정적이고 확장 가능한 프레임워크를 제공합니다.
- 최종 상태를 정의하면 Snowflake가 Dynamic Table을 통해 새로 고침을 자동 관리합니다.
- Snowflake Tasks를 이용하여 정해진 스케줄 또는 정의된 트리거에 따라 명령을 실행하세요.
- 복잡한 주기적 처리는 방향성 비순환 그래프(DAG)를 정의하여 태스크를 연결하세요.
- 서버리스 태스크로 태스크 실행을 최적화하세요.

리소스
Snowflake에서 파이프라인 구축 및 오케스트레이션 시작하기



시작하기
Snowflake와 함께다음 단계로 나아가세요
Snowflake30일 무료 평가판지금 체험하기
- 400달러(USD) 상당의 무료 사용 크레딧 제공
- 즉시 이용 가능한 AI 데이터 클라우드
- 핵심 데이터 워크로드의 활성화 실현



데이터 파이프라인
자주 묻는 질문
Snowflake 데이터 파이프라인을 효과적으로 구축하고 관리하는 방법을 알아보세요. 지원되는 유형, 효율적인 데이터 처리 기법 등을 살펴보세요.
데이터 파이프라인은 데이터를 출처(소스 시스템)에서 저장과 분석을 위한 목적지(데이터 웨어하우스, 데이터 레이크 등)로 이동하고 변환하는 과정을 자동화하는 일련의 프로세스와 도구입니다. 기본적으로 가공 전 데이터가 수집, 처리되어 인사이트, AI, 앱 및 기타 다운스트림 사용 사례를 위해 준비되는 방식입니다.
일반적인 데이터 파이프라인 유형은 다음과 같습니다.
배치 파이프라인: 대량의 데이터를 스케줄에 따라 간격을 두고 처리
스트리밍 파이프라인: 생성된 데이터를 실시간 또는 준실시간으로 처리
마이크로 배치 파이프라인: 소량의 데이터를 짦은 시간 간격으로 처리하여 배치와 스트리밍 간의 균형을 제공하는 하이브리드 방식
Snowflake는 데이터 엔지니어링 페르소나 및 요구 사항에 따라 다양한 기능을 통해 이러한 방식을 모두 지원합니다.
Snowflake는 변환과 데이터 오케스트레이션을 모두 처리하는 여러 기능을 제공합니다. Snowflake Dynamic Table은 변환을 위한 새로 고침 스케줄을 자동화할 수 있습니다. Snowflake Tasks는 SQL 및 Python 변환을 오케스트레이션하기 위해 태스크 그래프(DAG)로 연결될 수 있습니다. dbt와 같은 도구는 변환에 중점을 두지만, 전체 파이프라인 오케스트레이션을 위해 Tasks 또는 외부 오케스트레이터(Apache Airflow 등)와 통합됩니다.
Snowflake의 네이티브 지원 기능인 Snowflake Tasks로 종속성을 관리할 수 있습니다. 태스크 그래프를 생성하여 실행 순서를 정의하면 다음 단계는 선행 태스크가 성공적으로 완료된 후에만 실행됩니다. Dynamic Table을 사용하는 경우, 종속성은 Dynamic Table에 의해 자동으로 관리됩니다.
아니요, 사용자 지정 데이터 파이프라인을 꼭 처음부터 구축할 필요는 없습니다. 데이터 엔지니어가 데이터 파이프라인의 다양한 부분과 상호 작용하는 방법은 여러 가지입니다. 데이터 로드 및 수집을 예로 들어 보겠습니다. 필요에 따라 데이터 통합 도구(Snowflake Openflow 등)를 사용하거나, Snowflake 마켓플레이스를 통해 직접 데이터 공유에 액세스하거나, 데이터가 이미 다른 Snowflake 계정에 있는 경우 Snowflake Secure Data Sharing을 활용할 수 있습니다.
변환 작업 수행 전 항상 데이터를 Snowflake의 내부 관리형 스토리지에 수집해야 하는 것은 아닙니다. Snowflake는 레이크하우스를 포함한 다양한 아키텍처를 지원하므로 외부 테이블이나 Apache Iceberg 테이블을 사용하여 외부 클라우드 스토리지에 있는 데이터를 Snowflake에서 변환할 수 있습니다. 이렇게 하면 항상 Snowflake 관리형 스토리지에 데이터를 수집하지 않고도 데이터 작업을 할 수 있습니다.