Blog
Beschleunigung von scikit-learn und pandas in Snowflake mit GPUs
Erfahren Sie, wie Sie mit GPUs die Modellentwicklung für scikit-learn, pandas, UMAP und HDBSCAN beschleunigen können – ohne Codeänderungen.
Funktion
Mit Snowflake CoCo können Sie schneller von Daten zu prädiktiven Erkenntnissen gelangen. Erstellen Sie produktionsreife ML-Pipelines in natürlicher Sprache – genau dort, wo sich Ihre kontrollierten Daten befinden.
Übersicht
Beschleunigen Sie den Modelllebenszyklus mit automatisierten ML-Pipelines. Gewinnen Sie prädiktive, auf Ihr Unternehmen zugeschnittene Einblicke mit nativem Kontext – über Ihre Daten, Features, Modelle und Notebooks hinweg – auf einer einheitlichen, kontrollierten Plattform.

Vereinheitlichen Sie Workflows für Entwicklung, Inferenz und Betrieb – genau dort, wo sich Ihre Daten bereits befinden.
Entdecken, verwalten und kontrollieren Sie Features und Modelle in Snowflake über den gesamten Lebenszyklus hinweg – mit zentraler Lineage und rollenbasierter Zugriffskontrolle (RBAC).



ML-Workflow
Modellentwicklung
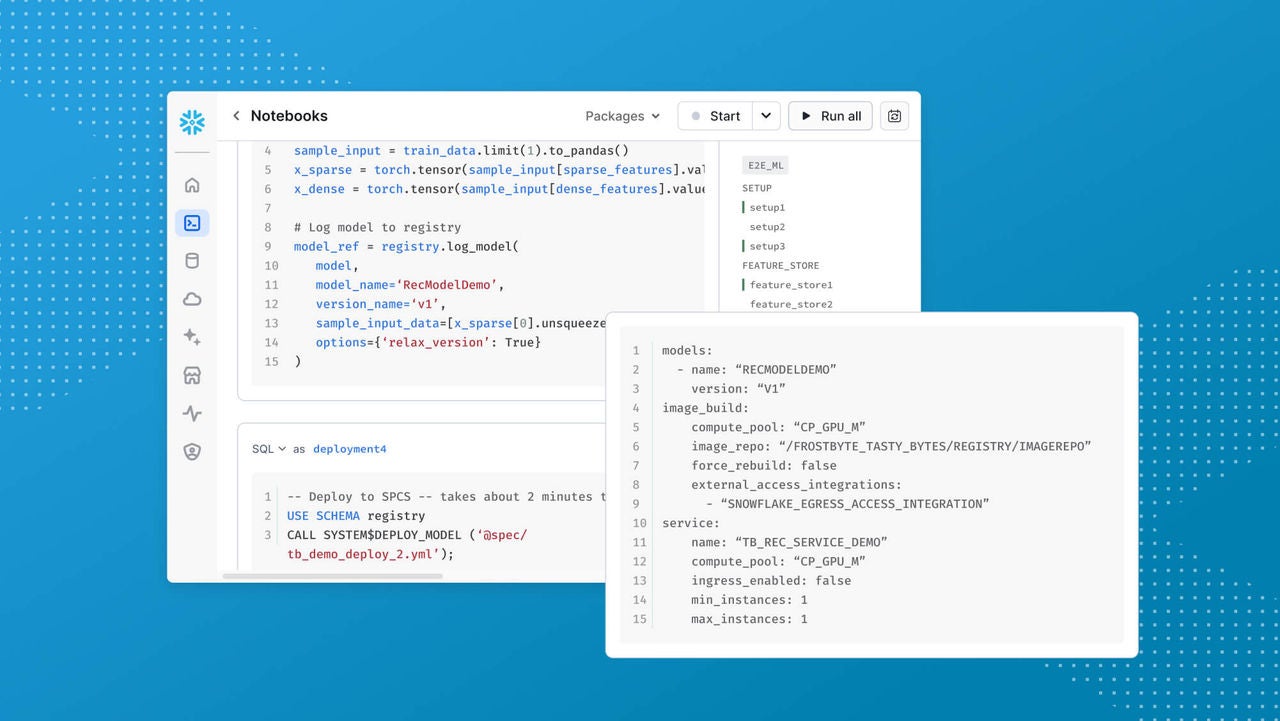
Optimieren Sie das Laden von Daten und beschleunigen Sie das Training aus Snowflake Notebooks oder direkt aus VS Code mit Snowflakes VS Code Extension oder über Cursor.†
Nutzen Sie vorinstallierte Bibliotheken wie XGBoost und PyTorch oder installieren Sie beliebige Pakete von Open-Source-Hubs wie PyPI und Hugging Face einfach per pip install.
Passen Sie Open-Weight Foundation-Modelle an und trainieren Sie sie – mit Cortex Training.*
Feature-Management
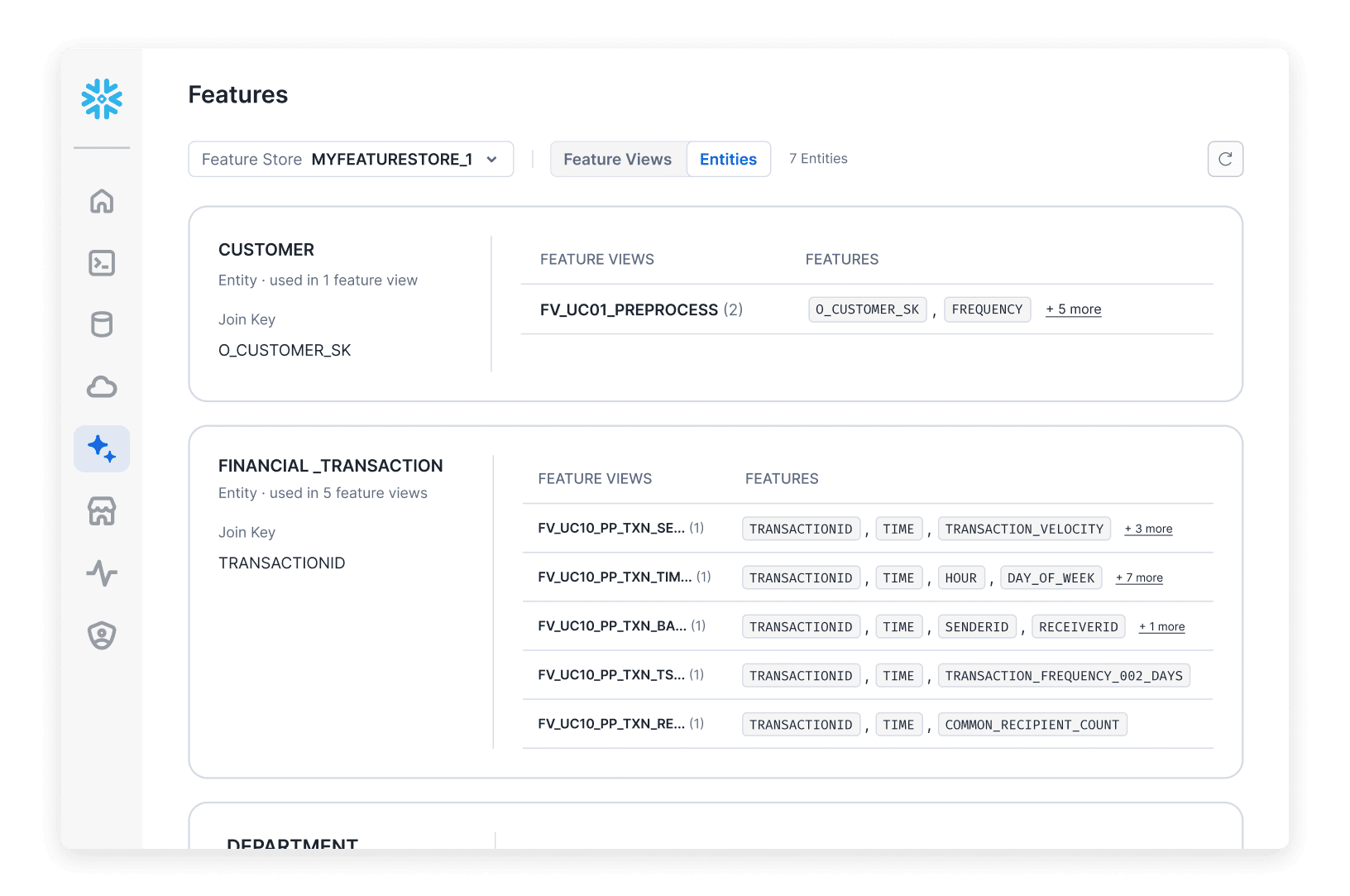
Erstellen, verwalten und stellen Sie ML-Features bereit – mit kontinuierlicher, automatisierter Aktualisierung für Batch- oder Streaming-Daten in unter 20 Millisekunden mithilfe des Snowflake Feature Store.
Verbessern Sie die Auffindbarkeit, Wiederverwendbarkeit und Governance von Features über das gesamte Training und die Inferenz hinweg.
Suchen Sie ganz einfach nach Features und verfolgen Sie diese in der gesamten Pipeline visuell nach – über die integrierte Feature Store-Benutzeroberfläche.
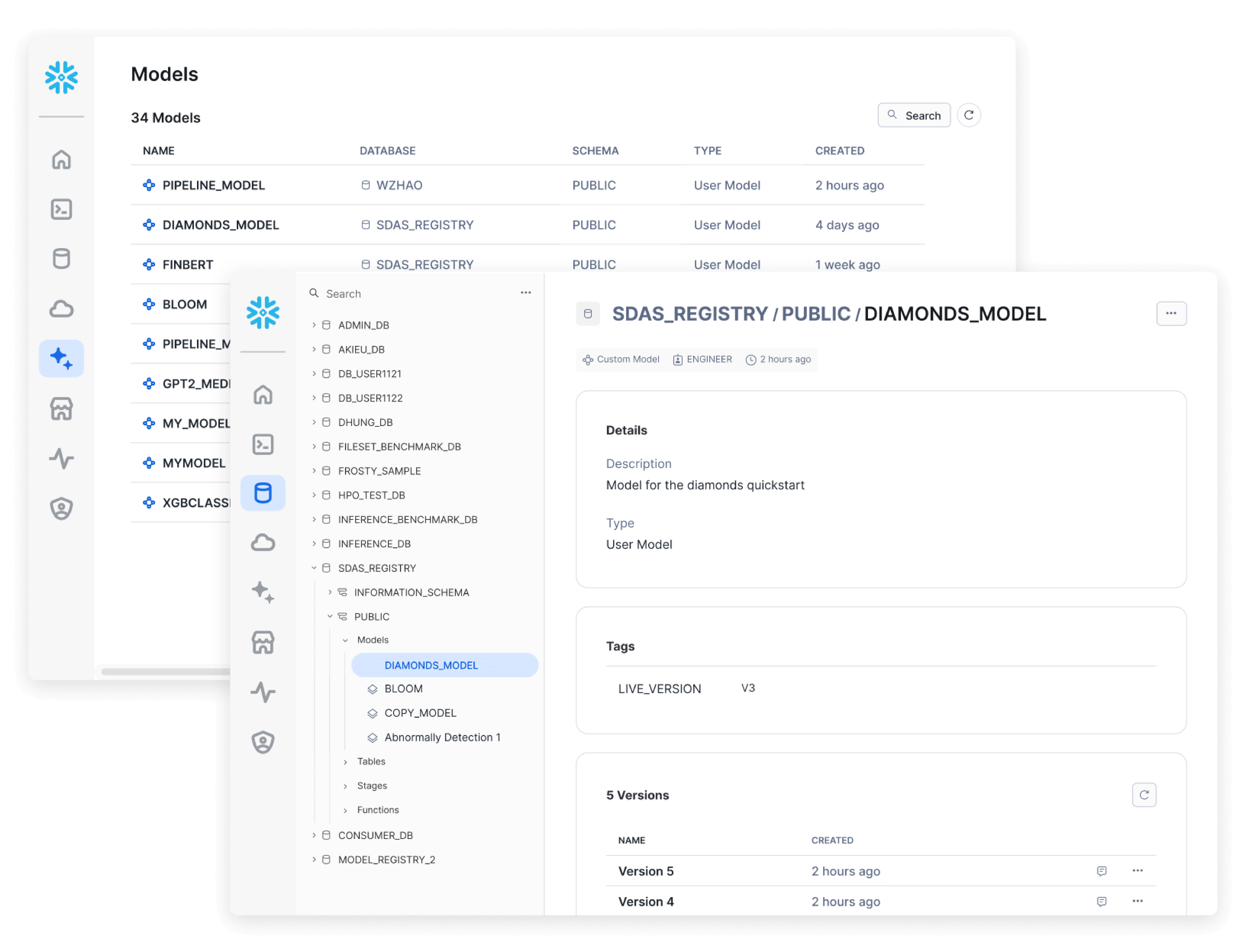
Modellmanagement
Registrieren Sie Modelle beliebigen Ursprungs in der Snowflake Model Registry und stellen Sie diese für Batch- oder Echtzeit-Prognosen auf Basis von Snowflake-Daten mit CPUs oder GPUs bereit.
Erreichen Sie Antwortzeiten von unter 100 Millisekunden bei der Modellbereitstellung, um Online-Anwendungsfälle mit niedriger Latenz zu unterstützen, einschließlich Customer Lifetime Value und Betrugserkennung.
„Früher dauerte es eine halbe Stunde, all diese Modelle zu trainieren und Vorhersagen zu erzeugen. Das zentralisierte Snowflake-Modell ist superschnell: Prognosen für Hunderttausende Kund:innen sind binnen weniger Minuten generiert. Diese Geschwindigkeit und Einfachheit ebnen unserem Unternehmen den Weg zu zusätzlichen Möglichkeiten wie Simulationen und Szenarioprognosen.“
Dan Shah
Manager of Data Science

„Dass alles in Snowflake ML vereint ist und nahtlos funktioniert, ohne dass man sich Gedanken über Sicherheit oder Governance machen muss, sorgt für einen enormen Produktivitätsschub.“
Tuhin Ghosh
Head of Data Science der Platform Product Group bei Coinbase

Erfahren Sie mehr über die integrierten Funktionen für Entwicklung
und Produktion in Snowflake ML
Erste Schritte
End-to-End-ML
Haben Sie Fragen zu Snowflake ML? Wir haben die Antworten. Hier sind einige der am häufigsten gestellten Fragen, die Ihnen helfen zu verstehen, wie es funktioniert und wie Sie starten können.
Ja, Data Scientists und ML Engineers können Modelle mit verteilter Verarbeitung auf CPUs oder GPUs entwickeln und bereitstellen. Möglich wird dies durch die zugrunde liegende, moderne, Ray-basierte Container-Infrastruktur, auf der die Snowflake ML-Plattform aufbaut.
Ja, Snowflake ML verarbeitet sowohl Online- als auch Batch-Workloads. Für Echtzeitanforderungen stehen unser Online-Feature Store und die Online-Modellinferenz allgemein zur Verfügung, um Anwendungsfälle wie personalisierte Empfehlungen, Betrugserkennung, Preisoptimierung und Anomalieerkennung zu unterstützen.
Nein, Sie können Modelle, die an beliebigen Orten extern entwickelt wurden, mit Snowflake-Daten in der Produktion ausführen. Während der Inferenz können Sie von integrierten MLOps-Funktionen wie ML-Beobachtbarkeit und RBAC-Governance profitieren.
Ja, Snowflake ML ist vollständig mit jeder Open-Source-Bibliothek kompatibel. Greifen Sie über pip sicher auf Open-Source-Repositorys zu und importieren Sie beliebige Modelle von Hubs wie Hugging Face.
Snowflake arbeitet mit einem verbrauchsabhängigen Preismodell. Entdecken Sie die aktuelle Credit Pricing Table.
Ja, Sie können jeden unserer ML-Quickstarts direkt über die Testversion ausprobieren.