
JAN 31, 2025|22 min read

Snowflake Cortex Search delivers exceptional search quality out of the box, outperforming current enterprise search tools such as Azure AI Search, Elasticsearch, and AWS OpenSearch on a broad set of benchmarks covering scenarios such as product, email, technical, and web search by up to 15% better NDCG@10. It's incredibly easy to use, requiring only a single SQL query to deploy, and allows for rapid iteration and improvement. Cortex Search is the ideal solution for businesses looking to unlock the full potential of their data without the need for complex configurations or specialized expertise.
Imagine this: You have a treasure trove of unstructured data that you know is brimming with insights that could revolutionize your business. However, you can’t unlock what you can’t find. Your insights in your data might as well be needles in the haystack of your documents. Nowhere will this problem be more amplified than in today's world, where AI applications increasingly rely on retrieval-augmented generation (RAG). Without proper retrieval, how is an LLM supposed to reason about it?
Here's the hard truth: Building search systems that deliver accurate, relevant and insightful results is incredibly difficult. Whether you're fine-tuning product search to surface the right item, ensuring email search quickly retrieves the right message or powering AI-driven insights, search is never as simple as it seems. Anyone who relies on search in their business knows that search is a hard problem. It often feels like you need a team of data scientists with Ph.D.s in search algorithms just to get started. Cortex Search changes that equation, making it easy to deploy high-quality search across all your data — whether searching a product catalog, an email archive or a knowledge base powering the latest AI applications.
At Snowflake, our customers have gold in their data, but using that data shouldn't require a team of Ph.D.s. That's why we built Snowflake Cortex Search — a game-changing search solution that's both incredibly powerful and refreshingly simple to use. With Cortex Search, you get exceptional search quality right out of the box, with no tuning, tweaking or hand-wringing required. Also, unlike other vendors, we believe hybrid and rerank search should come standard and work out of the box without additional configuration or upsells.
This is how we set it up: We rank benchmarks on a diverse set of four public data sets with Cortex Search and a leading cloud enterprise search offering, with each data set representing a real-world challenge our customers face. This includes a mix of data sets measuring performance on both pure search and RAG use cases, similar to what we see in our customer base. Further details on data set selection and examples of documents can be found in the appendix.
Data Set |
Workload Type |
Domain |
Number of Documents |
NIST’s TREC Deep Learning Track (2019-2020) |
Information Discovery |
General Search |
8,841,823 |
EnronQA |
Knowledge Worker Chat |
Email/Knowledge Worker |
103,638 |
NIST’s TREC Product Search Track (2023-2024) |
Product Search |
E-Commerce/Product Search |
1,118,658 |
Arxiver |
Information Discovery |
Technical Information Discovery |
138,381 |
Table 1: We use a variety of data sets to represent the wide range of data that we hear customers care about.
Notably, we choose not to use the popular MTEB or BEIR benchmarks for this exercise so that we can avoid overfitting. While the MTEB (which uses a subset BEIR to evaluate retrieval quality) leaderboard has done a great job of providing a unified ranking for embedding models, the fully open nature of the leaderboard makes it difficult to evaluate true model quality out of the box, as it is common for models to overfit to the benchmark data sets. Moreover, when evaluating these top-performing MTEB models we commonly find that huge performance gaps very quickly disappear and cease to exist when exploring customers’ workloads. In other words, in our experience, good performance on MTEB does not necessarily indicate good performance on real-life workloads.
Search performance can be great out of the box, but more often than not you need to run some experiments and variations in the document structure and verify how they impact retrieval quality. With Cortex Search this is dead simple. Bring your data into a Snowflake table and create search services with variations of your data set structure. You do not need to worry about scale or provisioning, as the dynamic scale of Snowflake’s AI Data Cloud will do the heavy lifting. Other services simply don’t do this, and at every step of the way you need to provision additional services and ensure their scale is sufficient for your needs. When dealing with data sets with millions of documents such as TREC Product Search or TREC Deep Learning, Cortex Search can generate production-ready services in under an hour, while enterprise search services and Mosaic AI Vector Search require days to evaluate the same corpus.
While Cortex Search is built around the notion of sensible defaults and high out-of-the-box performance, how can it be directly compared to other services, which commonly have dozens of knobs and configurations? For Cortex Search, all product usage is measured strictly out of the box. This means creating the search services from the native corpora without any form of tuning or modification.
Service |
Keyword Search |
Vector Embeddings |
Reranking |
Snowflake Cortex Search |
Cortex Search Proprietary |
Proprietary Reranker/ Voyage Rerank-2 |
|
Azure AI Search Service |
Lucene |
||
Databricks Mosaic AI Vector Search |
Unknown |
Table 2: A description of what embedding models and reranking models are used in quality evaluation. As Databricks does not have any form of a reranker, we leverage Azure’s hosted Cohere Rerank 3.
For the competing enterprise search services, we evaluate the leading enterprise search service’s pure out-of-the-box performance with its keyword search and then follow its suggestions to implement hybrid search combining keyword and vector retrieval with Reciprocal Rank Fusion; we then rerank the top results using the service’s paid add-on, a semantic reranker. For embeddings, we follow the enterprise search service’s recommendations and benchmark with OpenAI’s text-embedding-3-large and text-embedding-3-small. While our experiments focus on Azure, as its service is Lucene-based for keywords and vector search is nearly identical across services, we expect other enterprise search services such as Elasticsearch and OpenSearch to perform nearly identically. Additionally, we evaluate strict out-of-the-box performance of Databricks’ Mosaic AI Vector Search; we use its out-of-the-box hybrid search and benchmark with its bge-large and bge-small models. As Mosaic AI Vector Search offers no form of reranker, its results are evaluated without one.
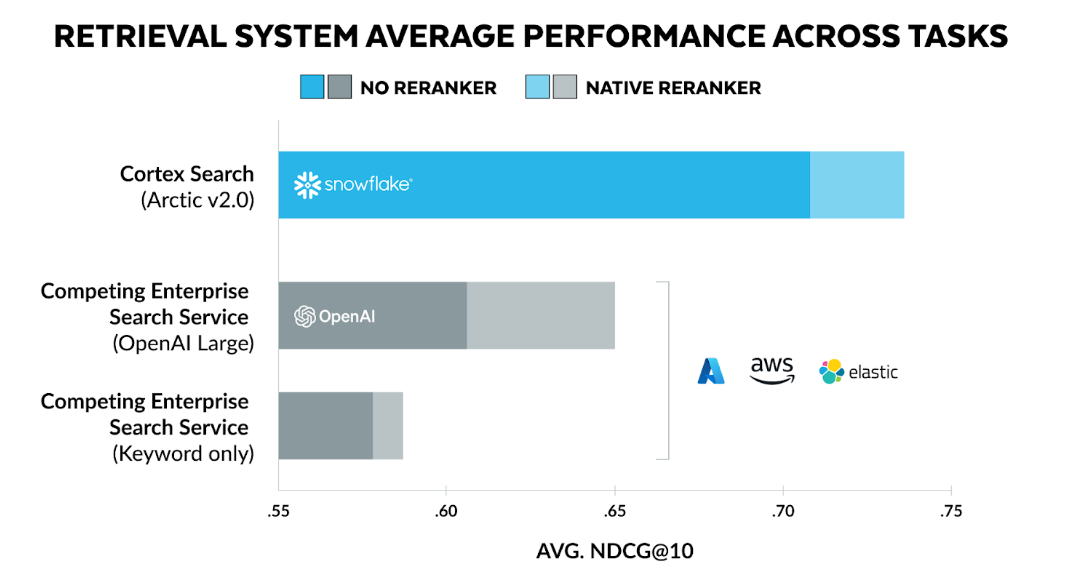
Our expanded benchmarks, featuring a diverse range of embedding models, don't just confirm Cortex Search's quality advantage — they amplify it. Let's dive into the results, where we focus on retrial quality using the industry standard Normalized Discounted Cumulative Gain (NDCG) @10 (meaning the NDCG for the top 10 documents).
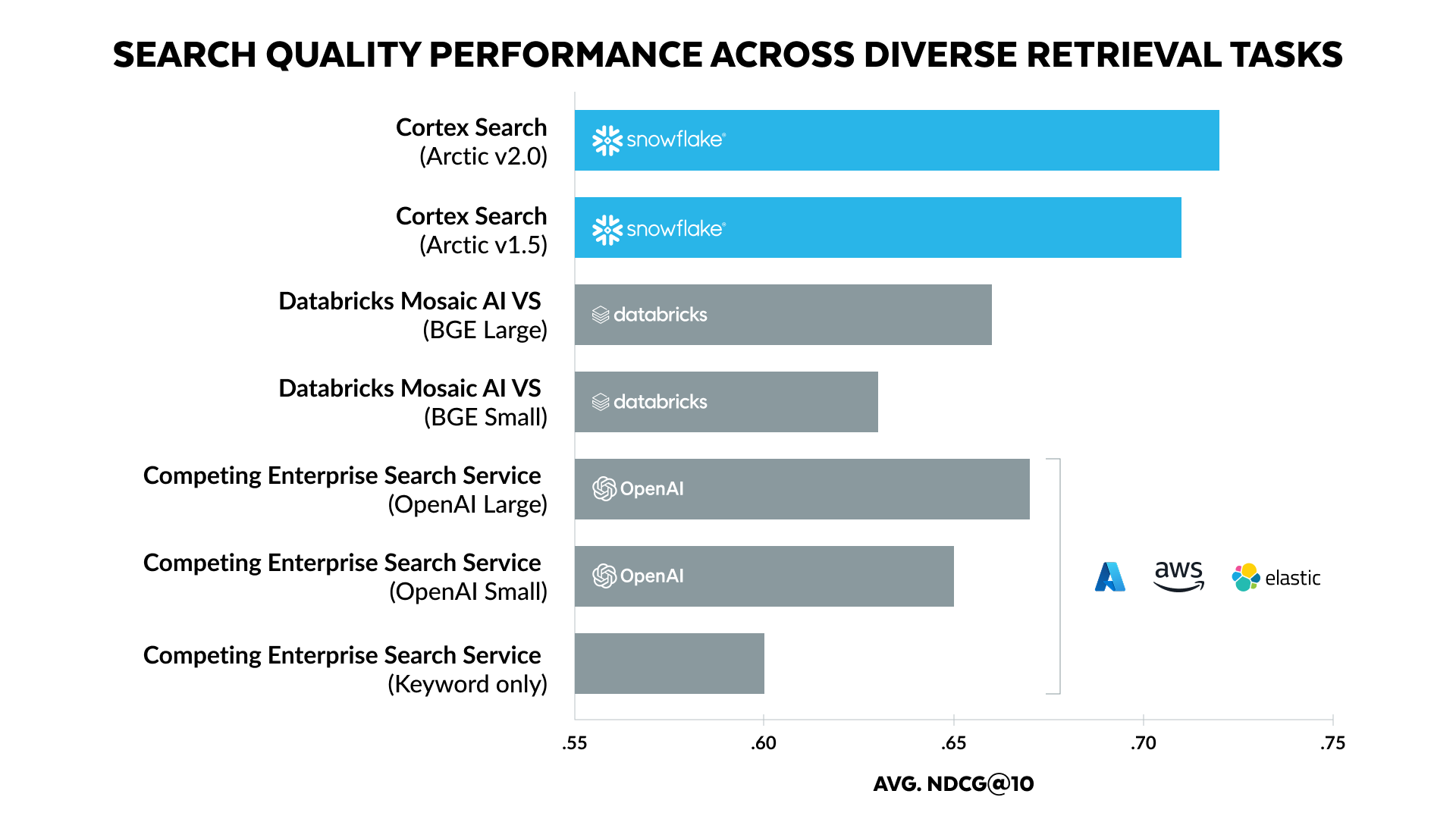
As shown in Figure 3 and Table 3, Cortex Search delivers unmatched search quality, outperforming competing enterprise search solutions across multiple search tasks. Notably, Cortex Search (Arctic v2.0) achieves an average NDCG@10 of 0.72, surpassing the competing enterprise search service using OpenAI Large embeddings (0.67) and Mosaic AI Vector Search (0.66) by a significant margin.
Search Service |
Average |
Web Search |
Email Search |
Information Discovery |
Product Search |
Cortex Search (Arctic v1.5) |
0.71 |
0.71 |
0.71 |
0.74 |
0.67 |
Cortex Search (Arctic v2.0) |
0.72 |
0.71 |
0.76 |
0.75 |
0.67 |
Databricks Mosaic AI VS (BGE Large) |
0.66 |
0.67 |
0.70 |
0.64 |
0.63 |
Databricks Mosaic AI VS (BGE Small) |
0.63 |
0.64 |
0.67 |
0.63 |
0.60 |
Competing Enterprise Search Service — Keyword Only |
0.60 |
0.46 |
0.79 |
0.72 |
0.44 |
Competing Enterprise Search Service — OpenAI Large |
0.67 |
0.49 |
0.83 |
0.86 |
0.48 |
Competing Enterprise Search Service — OpenAI Small |
0.65 |
0.46 |
0.83 |
0.84 |
0.47 |
Table 3: Performance of search services across tasks and models. All services are run within a hybrid format with native reranking services enabled whenever possible.
When comparing against leading enterprise search services, we find Cortex Search has a nearly 8% gap, even though the service uses an additional paid reranker. Moreover, looking at performance on individual data sets, we find that Cortex Search leads in web and product searches while slightly lagging in email and information discovery.
These aren't just abstract numbers; they translate to real-world impacts:
Better product discovery: In ecommerce, higher search quality means customers find what they're looking for faster, leading to increased sales and customer satisfaction. Cortex Search's dominance in the TREC Product Search benchmark demonstrates its ability to drive real business value in this critical area.
Deeper insights: In knowledge-intensive domains such as technical research, higher-quality search unlocks deeper understanding and accelerates innovation. Cortex Search's strong performance on the Arxiver data set showcases its ability to surface the most relevant and insightful information from complex technical documents.
More effective communication: In email and collaboration scenarios, better search helps users quickly find the information they need to make informed decisions and communicate effectively. Cortex Search's consistent performance on the EnronQA data set highlights its ability to navigate the nuances of human language and retrieve the most relevant information.
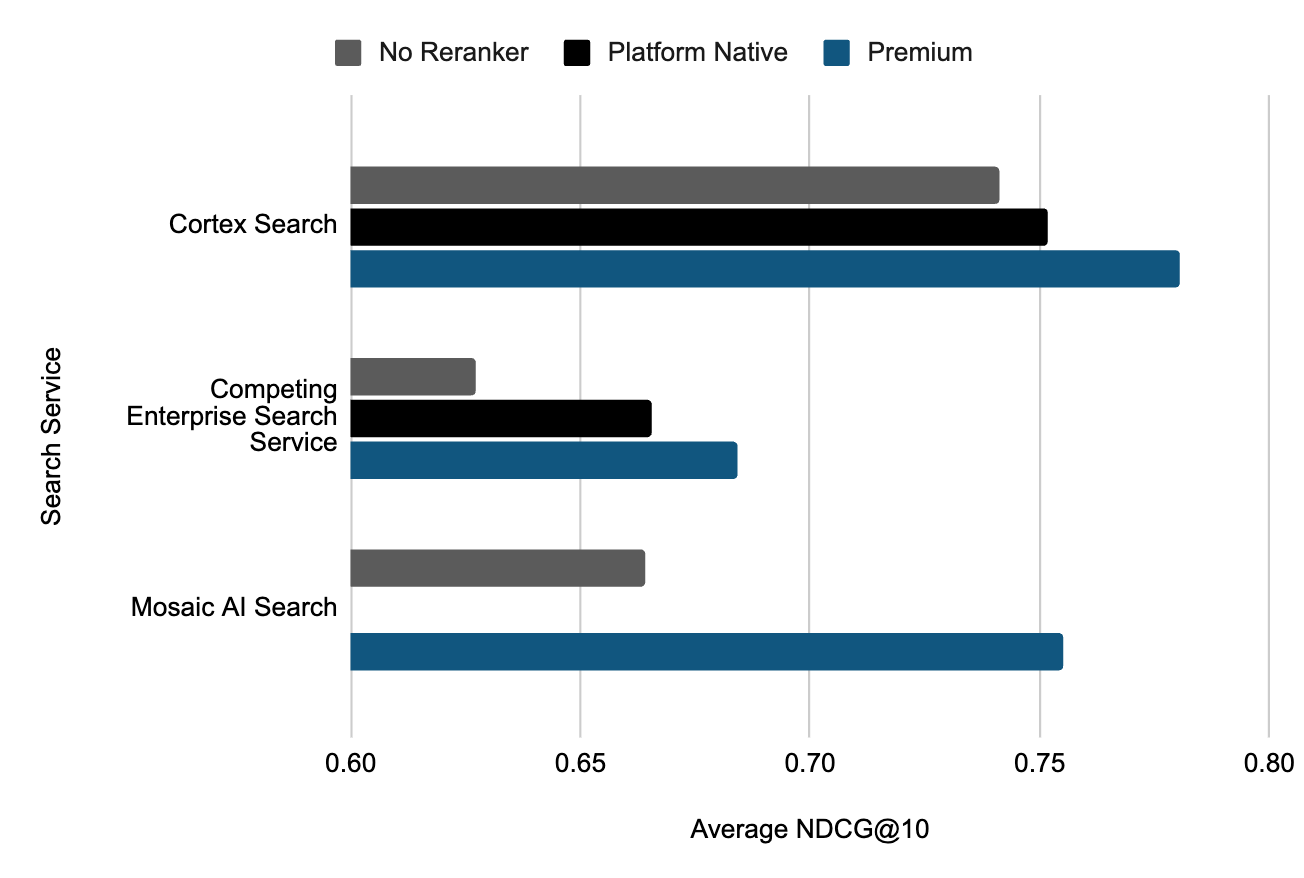
While most of our customers are happy with our out-of-the-box search performance, we understand that some workloads are quality-bound and every improvement in NDCG is hugely important. To qualify this, we evaluate the impact of using additional reranking services by comparing Snowflake’s hosted Voyage-2 reranking model to the suggested premium reranker from leading enterprise search services, Cohere’s Rerank 3. For each service, we rerank the top 16 results of the hybrid retrieval results without the service-native reranking engine.
At Snowflake we try to make sure that our customers have access to the best set of models. This is why we invested in Voyage AI and serve Snowflake partner models natively. In our evaluation we find that Voyage’s models outperform not only our own in-house models but state-of-the-art open source models and other reranking services such as Cohere’s Rerank 3.
Search Service |
Reranker |
Average |
Web Search |
Email Search |
Information Discovery |
Product Search |
Cortex Search |
None |
0.74 |
0.76 |
0.70 |
0.85 |
0.65 |
Cortex Search |
Platform Native |
0.75 |
0.71 |
0.76 |
0.86 |
0.67 |
Cortex Search |
Premium |
0.78 |
0.80 |
0.77 |
0.87 |
0.69 |
Competing Enterprise Search Service |
None |
0.63 |
0.46 |
0.79 |
0.81 |
0.45 |
Competing Enterprise Search Service |
Platform Native |
0.67 |
0.49 |
0.83 |
0.86 |
0.48 |
Competing Enterprise Search Service |
Premium |
0.68 |
0.65 |
0.76 |
0.83 |
0.50 |
Mosaic AI Search |
None |
0.66 |
0.67 |
0.70 |
0.64 |
0.63 |
Mosaic AI Search |
Premium |
0.75 |
0.71 |
0.82 |
0.87 |
0.62 |
Table 4: The impact of variation of reranker on NDCG@10 across data sets. For Cortex Search and the competing enterprise search service, the retrieval is hybrid and the embedding models are Arctic v2.0 and OpenAI’s text-embedding-3-large. The platform-native Reranker is Azure’s Semantic Ranker along with Cortex Search’s proprietary reranker, while premium reranking comes in the form of Azure’s hosted Cohere Rerank 3 and Snowflake’s hosted Voyage AI Rerank-2.
As shown in Table 4 above, we see that both search services benefit from expanded reranking with more competent models; however, Cortex Search’s use of Voyage’s rerank model helps grow the gap to nearly 13% over the competing enterprise search service and to over 15% over Mosaic AI Vector Search!
Let's be honest: Powerful technology is useless if it's too complicated to use. That's where Cortex Search truly shines. For Snowflake customers, deploying Cortex Search is as easy as writing a single SQL query. That's it. No complex configurations, no wrestling with multiple interfaces, no managing external dependencies. Cortex Search automatically handles all the heavy lifting — embedding your data, configuring the hybrid search stack and delivering high-quality results — while you sit back and enjoy the ride.
Setting up even a rudimentary search configuration in a leading enterprise search tool’s AI search requires using multiple UIs, writing custom scripts and dealing with the headaches of managing external dependencies such as OpenAI embedding end points. Our tests reveal that embedding a data set on a competitor could take a whopping 32 hours, while the entire Cortex Search pipeline was completed in a mere 16 minutes. That's the difference between waiting for days or getting results in the time it takes to enjoy a coffee break.
In the fast-paced world of data, the ability to quickly iterate and improve is crucial. Search quality isn't a static target; it's a journey of continuous refinement. Cortex Search empowers you to be an agile search explorer. You can test new document representations with a simple SQL command, leveraging Snowflake's elastic infrastructure to create parallel embeddings and deploy new search services at lightning speed (often in under 15 minutes).
Azure's more rigid embedding process, in comparison, can take days or even weeks to complete, which makes it more difficult to experiment and innovate. When we experimented with longer context documents for the TREC Product Search data set, Cortex Search finished the pipeline in under an hour, while Azure needed nearly a week to achieve comparable results. Faster results on Snowflake mean more time to refine and innovate.
Snowflake Cortex Search isn't just another search solution; it's a paradigm shift. It's a powerful testament to what's possible when cutting-edge retrieval technology is combined with an unwavering focus on user experience. Whether you're launching a new search service or striving to optimize an existing one, Cortex Search empowers you to achieve superior results with less time, less effort and greater confidence.
Don't settle for a low-quality search that leaves valuable insights hidden in the depths of your data. Choose Cortex Search and unlock the true potential of your information. Try it today and experience the Snowflake difference — where quality, simplicity and value converge to create search magic.
NIST’s TREC Deep Learning Track 2019-2020: Marrying the widely used and studied MSMARCO passage corpus with the reliability of the National Institute of Standards and Technologies’ evaluation on a large corpus of 8.8 million short text passages, these data sets demonstrate performance on the vast and unpredictable landscape of general web search.
EnronQA: In the nuanced world of email and knowledge worker queries, where context is king, this data set focuses on answering precise user queries on the trove of over 100,000 emails released as part of the Enron trials.
NIST’s TREC Product Search 2023-2024: In the high-stakes arena of ecommerce and product search, where precision equals profit, this data set features over 1 million products and queries ranging from broad to highly specific.
This data set is built to emulate the workloads that information workers experience every day finding pieces of information buried in their inboxes. EnronQA leverages the emails released as part of the Enron trials and generates synthetic queries that can be answered only by finding the correct document. We turn this into a retrieval corpus by taking all emails as the corpora and selecting 500 queries from the dev and test portion of the data set and evaluating them as follows.
The corpus has 103,638 documents, each of which is an email as shown below.
Subject: RE: Cornerstone, MidAmerica
Sender: [email protected]
Recipients: ['[email protected]', '[email protected]', '[email protected]']
File: germany-c/bankrupt/31.
=====================================
Cornerstone has an ISDA which was terminated effective 11/28/01. They have two outstanding invoices (possibly others that I am not aware of) in the amounts of $1,747,664.00 and $234,418.54. Other outstanding invoices must be related to physical transactions.
Legal's termination log contains the following comment: "Cornerstone will make no further payments or delivery."
Hope this helps.
-----Original Message-----
From: Germany, Chris
Sent: Monday, April 01, 2002 9:17 AM
To: Dicarlo, Louis; Boyt, Eric
Cc: Hamic, Priscilla
Subject: FW: Cornerstone, MidAmerica
It looks like Cornerstone Propane, L.P. has not paid their December invoice for physical or financial. Is there anything going on with them that you guys are aware of?
-----Original Message-----
From: Hamic, Priscilla
Sent: Monday, April 01, 2002 9:05 AM
To: Germany, Chris
Subject: Cornerstone, MidAmerica
Neither of these companies have paid us for December 2001 gas. MidAmerica is probably holding payment for forward value, I don't know about Cornerstone. Both had invoices sent to them for December sales. Attached is Cornerstone's SAP balance. Call me if you need any further information.
<< OLE Object: Picture (Metafile) >>
Priscilla Hamic
Enron North America Corp.
Tel: 713-345-3736
Fax: 713-646-8420
E-mail: [email protected]
=====================================
We evaluate on subsets of 1,000 queries from dev and test split, selected at random.
Queries look like the below:
What region and trading desk have been affected by the incorrect deal entry, according to the email from JMF to Alex McElreath?
According to Kate Symes's email, what action was taken on deal numbers 597244 and 597245, and who took that action?
This is a data set that simulates what ecommerce workloads may experience.
The TREC Product Search Track has focused on evaluating the broad performance of retrieval systems focused on the ecommerce domain. The corpus comprises 1,118,658 Amazon products originating from the KDD Cup 2022 (ESCI). Products feature a variety of attributes such as brand, category or addition size and color metadata.
The corpus has 1,118,658 documents, each of which is an item from Amazon. This data set is a filtered version of the 2022 KKD Cup. We experiment with two corpus versions. We take a short corpus, which just joins the product title and description, along with a long one, which includes additional fields such as brand, bullet points, categories, etc.
{"doc_id": 276523, "text": "Title: New Audio Video AV Cable to 3 RCA for Sony Playstation PS / PS2 / PS3 DESCRIPTION: Product Description New Audio Video AV Cable to 3 RCA for Sony PlayStation PS / PS2 / PS3 Description: Connect your PS1, PS2, PS2 Slim or PS3 to any TV/ Monitor with RCA composite inputs Connectors: PS AV to RCA video, left & right audio To use it with PS3 console, please make sure to reset the Video Output option on the console in order for the cables to work. Cable Length: 1.8M / 6' Package Includes: 1 x AV Cable Product Description New Audio Video AV Cable to 3 RCA for Sony PlayStation PS / PS2 / PS3 Description: Connect your PS1, PS2, PS2 Slim or PS3 to any TV/ Monitor with RCA composite inputs Connectors: PS AV to RCA video, left & right audio To use it with PS3 console, please make sure to reset the Video Output option on the console in order for the cables to work. Cable Length: 1.8M / 6' Package Includes: 1 x AV CableTEMPLATE: pc_accessory CATEGORIES: ['Video Games', 'Legacy Systems', 'PlayStation Systems', 'PlayStation 3', 'Accessories', 'Cables & Adapters', 'Cables'] BULLET POINTS: ['Make sure this fits by entering your model number.', 'High quality generic (non-OEM) Audio Video AV Cable to RCA, For PlayStation PS / PS2 / PS3', 'Connect your PS1, PS2, PS2 Slim or PS3 to any TV/ Monitor with RCA composite inputs', 'Connectors: PS AV to RCA video, left & right audio', 'To use it with PS3 console, please make sure to reset the Video Output option on the console in order for the cables to work.', \"Cable Length: 1.8M / 6'\"] ATTRIBUTES: {'Connector Type': 'RCA', 'Connector Gender': 'Male-to-Male', 'Cable Type': 'Composite', 'Brand': 'coolxan', 'Compatible Devices': 'Gaming Console'}"}
2024 queries: “headphone for android phone” or "airplane model kit" or "hand grip for switch"
2023 queries: “Oil rubbed bronze outdoor wall mount lighting fixtures twin pack” or “adidas women's bomber jacket”
Arxiver Search is a new data set we created to simulate how deep technical users might search in corpora of dense technical content such as installation manuals, chemical reaction descriptions or other complex literature relevant to their job.
New search data set derived from the recently released Arxiver data set that features 138,381 arXiv documents posted in the last few months.
Example document: Title: Revisiting Multimodal Representation in Contrastive Learning: From Patch and Token Embeddings to Finite Discrete Tokens Abstract: Contrastive learning-based vision-language pre-training approaches, such asCLIP, have demonstrated great success in many vision-language tasks. These methods achieve cross-modal alignment by encoding a matched image-text pair with similar feature embeddings, which are generated by aggregating information from visual patches and language tokens. However, direct aligning cross-modal information using such representations is challenging, as visual patches and text tokens differ in semantic levels and granularities. To alleviate this issue, we propose a Finite Discrete Tokens (FDT) based multimodal representation. FDT is a set of learnable tokens representing certain visual-semantic concepts. Both images and texts are embedded using shared FDT by first grounding multimodal inputs to FDT space and then aggregating the activated FDT representations. The matched visual and semantic concepts are enforced to be represented by the same set of discrete tokens by a sparse activation constraint. As a result, the granularity gap between the two modalities is reduced. Through both quantitative and qualitative analyses, we demonstrate that using FDT representations in CLIP-style models improves cross-modal alignment and performance in visual recognition and vision-language downstream tasks. Furthermore, we show that our method can learn more comprehensive representations, and the learned FDT capture meaningful cross-modal correspondence, ranging from objects to actions and attributes. Authors: Yuxiao Chen, Jianbo Yuan, Yu Tian, Shijie Geng, Xinyu Li, Ding Zhou, Dimitris N. Metaxas, Hongxia Yang
Queries are generated using an LLM, building our experience in https://arxiv.org/abs/2405.07767 and our work on the TREC Deep Learning Track. We make short queries, which are three to seven words long and topically focused, and long queries, which are 7-15 words long and are expert queries focused on a deep concept but more conversational in nature.
Short: “modeling language for distribution shifts,” “magnetic levitation of Yttrium Iron Garnet sphere,” “Federated Learning debugging tools”
Long: “What factors influence surface electron confinement in two-dimensional metal-organic porous networks?,” "Optimizing sparse tensor cores for deep learning models"
Our final data set builds on the incredibly well-optimized MSMARCO data set. In this data set, we look at performance on the overly optimized MSMARCO dev portion and the more academic TREC Deep Learning tasks. We expect both embedding models to essentially perform nearly perfectly on the dev task but not so much on the Deep Learning Track queries, as this data set does not have a commercial license and thus is not viable for training a commercial model.
The MSMARCO corpus consists of 8,841,823 documents coming from a commercial search engine, Bing. The documents are short, focused and designed to answer questions.
{"doc_id": "0", "text": "The presence of communication amid scientific minds was equally important to the success of the Manhattan Project as scientific intellect was. The only cloud hanging over the impressive achievement of the atomic researchers and engineers is what their success truly meant; hundreds of thousands of innocent lives obliterated."}%
Dev queries (55,578 queries)
Queries factoid style. Queries that can be answered by exactly one document. Each query has at most one label.
“what is pay range for warehouse specialist in minneapolis,” “cost of endless pools/swim spa”
TREC Deep Learning 2019 (43 queries)
Queries come from the same distribution of Bing but have many more labels per query generated by professional assessors at NIST
“where is sugar lake lodge located,” “meaning of heat capacity”
TREC Deep Learning 2020 (54 queries)
Another set of Bing queries selected to be harder
Same evaluation as 2019
“who owns barnhart crane,” “why do hunters pattern their shotguns?”

