Build an End-to-End ML Workflow in Snowflake
Overview
In this guide, you'll learn how to build and deploy a complete machine learning workflow entirely within Snowflake ML. You'll work through a mortgage lending prediction use case, implementing each stage of the ML lifecycle from feature engineering to model deployment and monitoring.
This tutorial showcases Snowflake's ML capabilities, including:
- Feature Store for defining and managing features
- Snowflake ML APIs for model training and hyperparameter optimization
- Model Registry for versioning and lifecycle management
- ML Observability for tracking performance and drift
What You'll Learn
- How to build a model in Snowflake Notebooks on Container Runtime
- How to deploy a model for inference seamlessly with Snowflake Model Registry
- How to monitor a model during production with ML Observability
What You'll Build
You'll build a complete mortgage lending prediction system that:
- Engineers features from loan application data
- Trains baseline and optimized XGBoost models
- Registers models with metadata and metrics
- Monitors model performance over time
- Provides model explanations using SHAP values
What You'll Need
- Access to a Snowflake account with ACCOUNTADMIN access. Sign up for a 30-day free trial account, if required.
- Basic understanding of Python and machine learning concepts
Setup
Firstly, run this SQL setup script to create the necessary objects:
-- Using ACCOUNTADMIN, create a new role for this exercise USE ROLE ACCOUNTADMIN; SET USERNAME = (SELECT CURRENT_USER()); SET ALLOW_EXTERNAL_ACCESS_FOR_TRIAL_ACCOUNTS = TRUE; CREATE OR REPLACE ROLE E2E_SNOW_MLOPS_ROLE; -- Grant necessary permissions to create databases, compute pools, and service endpoints to new role GRANT CREATE DATABASE on ACCOUNT to ROLE E2E_SNOW_MLOPS_ROLE; GRANT CREATE COMPUTE POOL on ACCOUNT to ROLE E2E_SNOW_MLOPS_ROLE; GRANT CREATE WAREHOUSE ON ACCOUNT to ROLE E2E_SNOW_MLOPS_ROLE; GRANT BIND SERVICE ENDPOINT on ACCOUNT to ROLE E2E_SNOW_MLOPS_ROLE; -- grant new role to user and switch to that role GRANT ROLE E2E_SNOW_MLOPS_ROLE to USER identifier($USERNAME); USE ROLE E2E_SNOW_MLOPS_ROLE; -- Create warehouse CREATE OR REPLACE WAREHOUSE E2E_SNOW_MLOPS_WH WITH WAREHOUSE_SIZE='MEDIUM'; -- Create Database CREATE OR REPLACE DATABASE E2E_SNOW_MLOPS_DB; -- Create Schema CREATE OR REPLACE SCHEMA MLOPS_SCHEMA; -- Create compute pool CREATE COMPUTE POOL IF NOT EXISTS MLOPS_COMPUTE_POOL MIN_NODES = 1 MAX_NODES = 3 INSTANCE_FAMILY = CPU_X64_M; -- Using accountadmin, grant privilege to create network rules and integrations on newly created db USE ROLE ACCOUNTADMIN; -- GRANT CREATE NETWORK RULE on SCHEMA MLOPS_SCHEMA to ROLE E2E_SNOW_MLOPS_ROLE; GRANT CREATE INTEGRATION on ACCOUNT to ROLE E2E_SNOW_MLOPS_ROLE; USE ROLE E2E_SNOW_MLOPS_ROLE; -- Create an API integration with Github CREATE OR REPLACE API INTEGRATION GITHUB_INTEGRATION_E2E_SNOW_MLOPS api_provider = git_https_api api_allowed_prefixes = ('https://github.com/Snowflake-Labs') API_USER_AUTHENTICATION = (TYPE = SNOWFLAKE_GITHUB_APP) enabled = true comment='Git integration with Snowflake Demo Github Repository.';
Create workspace
Now we can navigate to the Workspaces tab in Snowsight to create a git based workspace!
From the workspace drop down, choose create from Git repository:
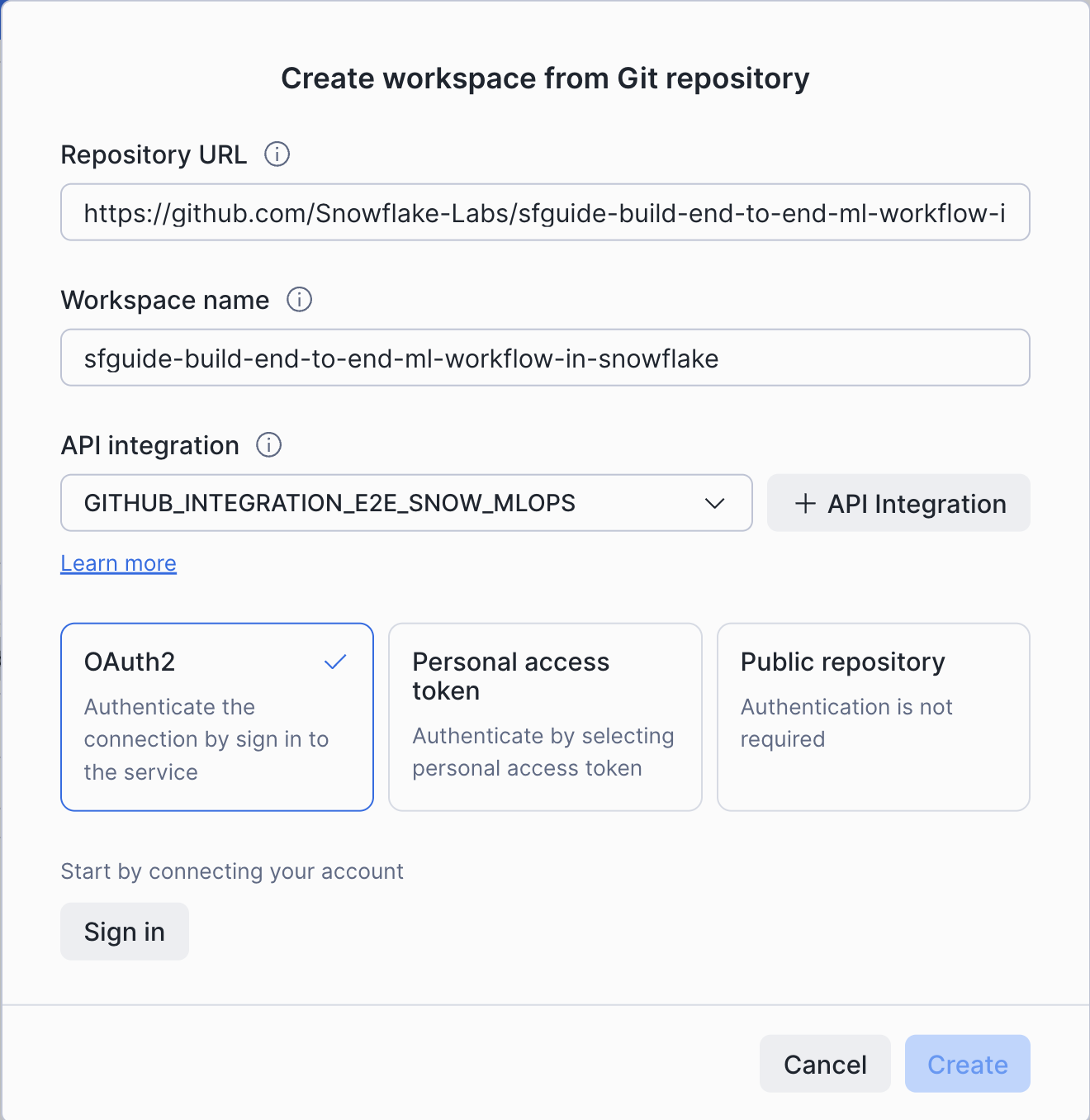
Create the workspace based on the repository url https://github.com/Snowflake-Labs/sfguide-build-end-to-end-ml-workflow-in-snowflake.git
Next, create a service to run the notebook on the compute pool created by the setup:
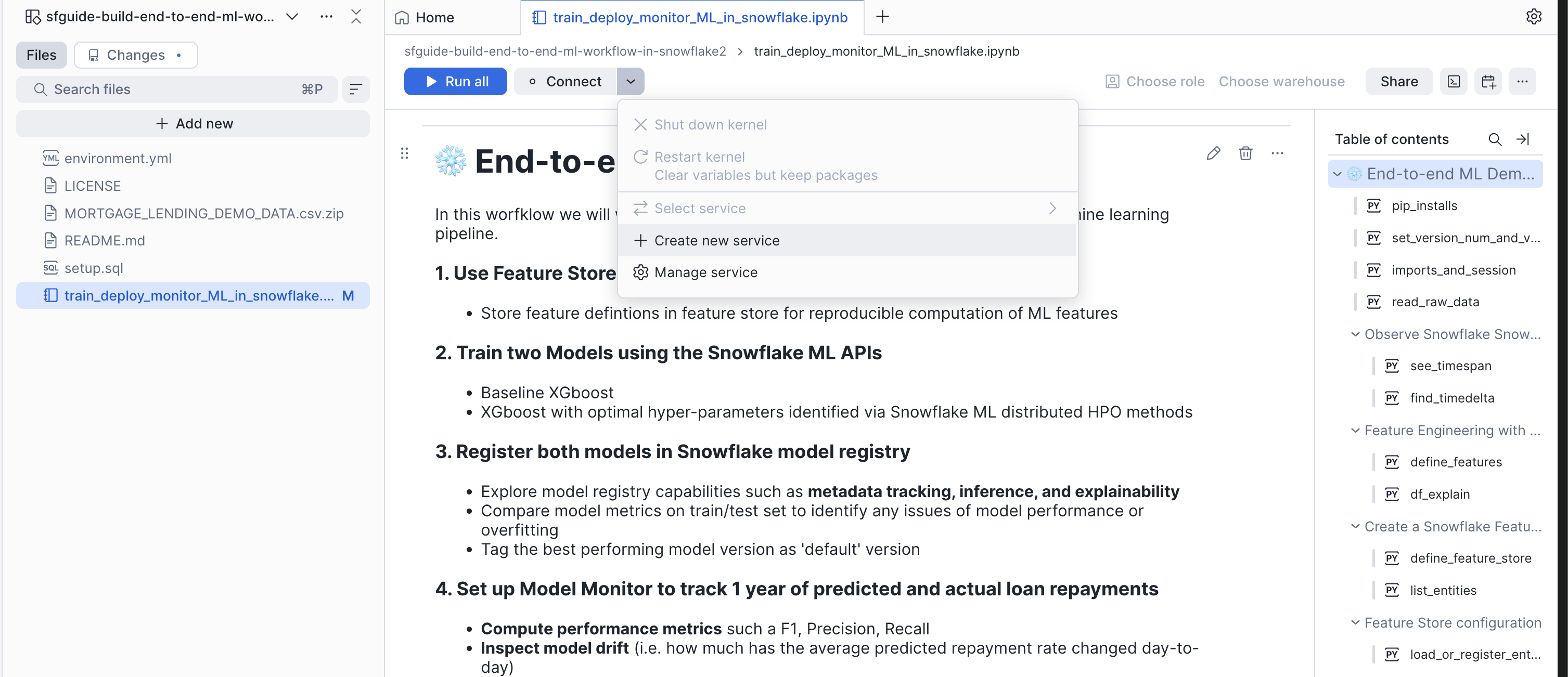
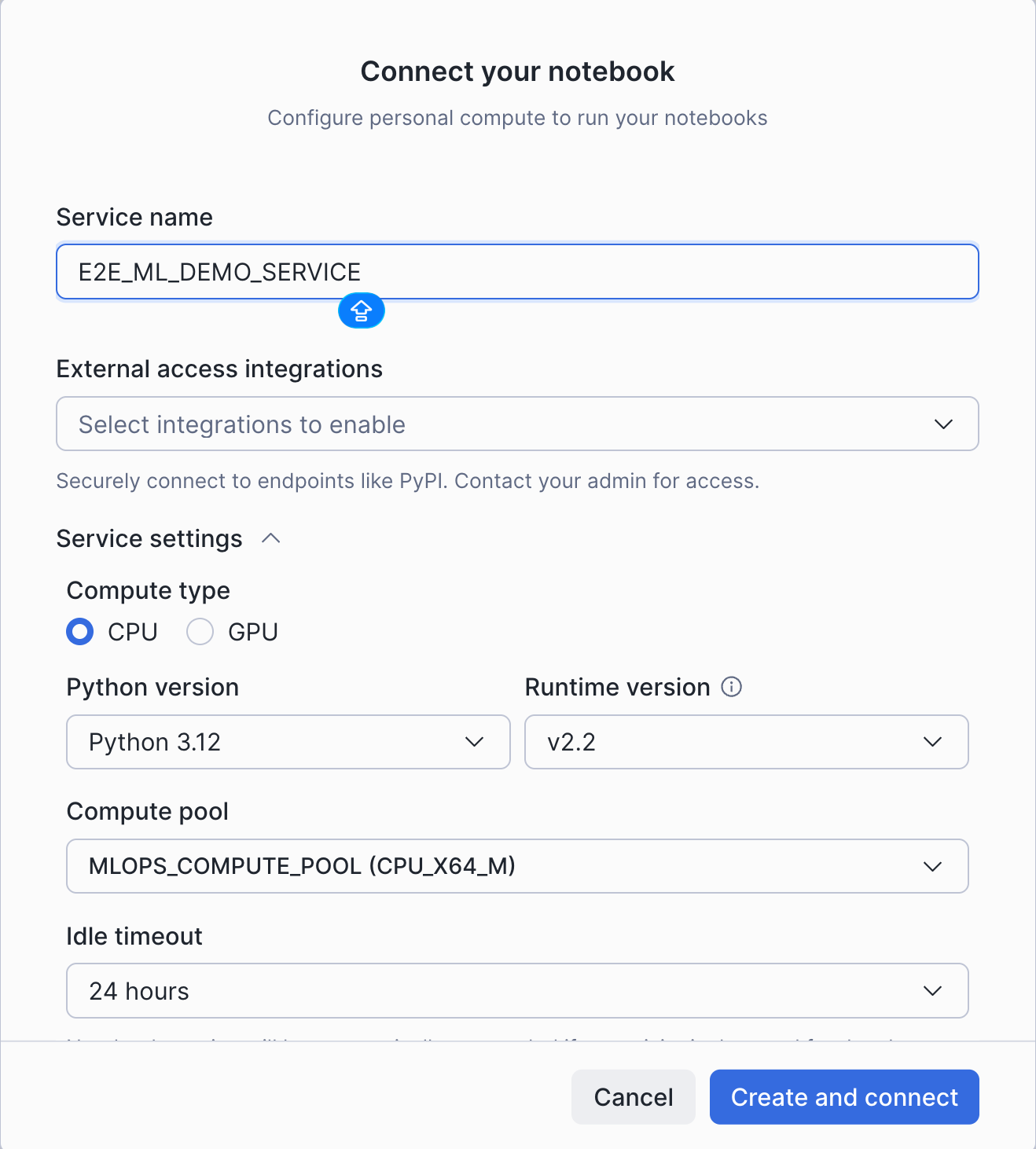
Be sure to run this with the newly created role E2E_SNOW_MLOPS_ROLE and warehouse E2E_SNOW_MLOPS_WH!
Initialize Snowflake Session and Variables
Set up your environment variables and initialize your Snowflake session:
#Update this VERSION_NUM to version your features, models etc! VERSION_NUM = '0' DB = "E2E_SNOW_MLOPS_DB" SCHEMA = "MLOPS_SCHEMA" COMPUTE_WAREHOUSE = "E2E_SNOW_MLOPS_WH" import pandas as pd import numpy as np import sklearn import math import pickle import shap from datetime import datetime import streamlit as st from xgboost import XGBClassifier # Snowflake ML from snowflake.ml.registry import Registry from snowflake.ml.modeling.tune import get_tuner_context from snowflake.ml.modeling import tune from entities import search_algorithm #Snowflake feature store from snowflake.ml.feature_store import FeatureStore, FeatureView, Entity, CreationMode # Snowpark session from snowflake.snowpark import DataFrame from snowflake.snowpark.functions import col, to_timestamp, min, max, month, dayofweek, dayofyear, avg, date_add, sql_expr from snowflake.snowpark.types import IntegerType from snowflake.snowpark import Window #setup snowpark session from snowflake.snowpark.context import get_active_session session = get_active_session()
Load and Prepare Data
Load the mortgage lending demo data:
try: print("Reading table data...") df = session.table("MORTGAGE_LENDING_DEMO_DATA") df.show(5) except: print("Table not found! Uploading data to snowflake table") df_pandas = pd.read_csv("MORTGAGE_LENDING_DEMO_DATA.csv.zip") session.write_pandas(df_pandas, "MORTGAGE_LENDING_DEMO_DATA", auto_create_table=True) df = session.table("MORTGAGE_LENDING_DEMO_DATA") df.show(5)
IMPORTANT:
- Make sure your Snowflake account has the necessary privileges to create tables and execute ML operations
- Ensure your warehouse is properly sized for ML workloads
Feature Engineering
In this section, we'll create features from our raw mortgage lending data using Snowpark APIs.
Create Feature Transformations
First, let's examine the time range of our data:
df.select(min('TS'), max('TS'))
Now, let's create a dictionary of feature transformations:
#Create a dict with keys for feature names and values containing transform code feature_eng_dict = dict() #Get current date and time current_time = datetime.now() df_max_time = datetime.strptime(str(df.select(max("TS")).collect()[0][0]), "%Y-%m-%d %H:%M:%S.%f") #Find delta between latest existing timestamp and today's date timedelta = current_time- df_max_time #Timstamp features feature_eng_dict["TIMESTAMP"] = date_add(to_timestamp("TS"), timedelta.days-1) feature_eng_dict["MONTH"] = month("TIMESTAMP") feature_eng_dict["DAY_OF_YEAR"] = dayofyear("TIMESTAMP") feature_eng_dict["DOTW"] = dayofweek("TIMESTAMP") #Income and loan features feature_eng_dict["LOAN_AMOUNT"] = col("LOAN_AMOUNT_000s")*1000 feature_eng_dict["INCOME"] = col("APPLICANT_INCOME_000s")*1000 feature_eng_dict["INCOME_LOAN_RATIO"] = col("INCOME")/col("LOAN_AMOUNT") county_window_spec = Window.partition_by("COUNTY_NAME") feature_eng_dict["MEAN_COUNTY_INCOME"] = avg("INCOME").over(county_window_spec) feature_eng_dict["HIGH_INCOME_FLAG"] = (col("INCOME")>col("MEAN_COUNTY_INCOME")).astype(IntegerType()) feature_eng_dict["AVG_THIRTY_DAY_LOAN_AMOUNT"] = sql_expr("""AVG(LOAN_AMOUNT) OVER (PARTITION BY COUNTY_NAME ORDER BY TIMESTAMP RANGE BETWEEN INTERVAL '30 DAYS' PRECEDING AND CURRENT ROW)""") df = df.with_columns(feature_eng_dict.keys(), feature_eng_dict.values()) df.show(3)
Create a Snowflake Feature Store
Now, let's create a Feature Store to track our engineered features:
fs = FeatureStore( session=session, database=DB, name=SCHEMA, default_warehouse=COMPUTE_WAREHOUSE, creation_mode=CreationMode.CREATE_IF_NOT_EXIST )
Register Entity and Feature View
Define an entity for our loan data:
#First try to retrieve an existing entity definition, if not define a new one and register try: #retrieve existing entity loan_id_entity = fs.get_entity('LOAN_ENTITY') print('Retrieved existing entity') except: #define new entity loan_id_entity = Entity( name = "LOAN_ENTITY", join_keys = ["LOAN_ID"], desc = "Features defined on a per loan level") #register fs.register_entity(loan_id_entity) print("Registered new entity")
Create a feature view with our engineered features:
#Create a dataframe with just the ID, timestamp, and engineered features feature_df = df.select(["LOAN_ID"]+list(feature_eng_dict.keys())) #define and register feature view loan_fv = FeatureView( name="Mortgage_Feature_View", entities=[loan_id_entity], feature_df=feature_df, timestamp_col="TIMESTAMP", refresh_freq="1 day") #add feature level descriptions loan_fv = loan_fv.attach_feature_desc( { "MONTH": "Month of loan", "DAY_OF_YEAR": "Day of calendar year of loan", "DOTW": "Day of the week of loan", "LOAN_AMOUNT": "Loan amount in $USD", "INCOME": "Household income in $USD", "INCOME_LOAN_RATIO": "Ratio of LOAN_AMOUNT/INCOME", "MEAN_COUNTY_INCOME": "Average household income aggregated at county level", "HIGH_INCOME_FLAG": "Binary flag to indicate whether household income is higher than MEAN_COUNTY_INCOME", "AVG_THIRTY_DAY_LOAN_AMOUNT": "Rolling 30 day average of LOAN_AMOUNT" } ) loan_fv = fs.register_feature_view(loan_fv, version=VERSION_NUM, overwrite=True)
Dataset Generation and Preprocessing
Generate Dataset from Feature View
Now that we have our features registered, let's generate a dataset for model training:
ds = fs.generate_dataset( name=f"MORTGAGE_DATASET_EXTENDED_FEATURES_{VERSION_NUM}", spine_df=df.select("LOAN_ID", "TIMESTAMP", "LOAN_PURPOSE_NAME","MORTGAGERESPONSE"), features=[loan_fv], spine_timestamp_col="TIMESTAMP", spine_label_cols=["MORTGAGERESPONSE"] ) ds_sp = ds.read.to_snowpark_dataframe() ds_sp.show(5)
Preprocess Data for Model Training
Let's encode categorical variables and prepare our data for training:
import snowflake.ml.modeling.preprocessing as snowml from snowflake.snowpark.types import StringType OHE_COLS = ds_sp.select([col.name for col in ds_sp.schema if col.datatype ==StringType()]).columns OHE_POST_COLS = [i+"_OHE" for i in OHE_COLS] # Encode categoricals to numeric columns snowml_ohe = snowml.OneHotEncoder(input_cols=OHE_COLS, output_cols = OHE_COLS, drop_input_cols=True) ds_sp_ohe = snowml_ohe.fit(ds_sp).transform(ds_sp) #Rename columns to avoid double nested quotes and white space chars rename_dict = {} for i in ds_sp_ohe.columns: if '"' in i: rename_dict[i] = i.replace('"','').replace(' ', '_') ds_sp_ohe = ds_sp_ohe.rename(rename_dict) # Split data into train and test sets train, test = ds_sp_ohe.random_split(weights=[0.70, 0.30], seed=0) train = train.fillna(0) test = test.fillna(0) # Convert to pandas for model training train_pd = train.to_pandas() test_pd = test.to_pandas()
Baseline Model Training
Train a Baseline XGBoost Model
Let's train a simple XGBoost classifier as our baseline model:
#Define model config xgb_base = XGBClassifier( max_depth=50, n_estimators=3, learning_rate = 0.75, booster = 'gbtree') #Split train data into X, y X_train_pd = train_pd.drop(["TIMESTAMP", "LOAN_ID", "MORTGAGERESPONSE"],axis=1) y_train_pd = train_pd.MORTGAGERESPONSE #train model xgb_base.fit(X_train_pd,y_train_pd)
Evaluate Baseline Model Performance
Let's check how our baseline model performs on the training data:
from sklearn.metrics import f1_score, precision_score, recall_score train_preds_base = xgb_base.predict(X_train_pd) f1_base_train = round(f1_score(y_train_pd, train_preds_base),4) precision_base_train = round(precision_score(y_train_pd, train_preds_base),4) recall_base_train = round(recall_score(y_train_pd, train_preds_base),4) print(f'F1: {f1_base_train} \nPrecision {precision_base_train} \nRecall: {recall_base_train}')
Model Registry and Evaluation
Create a Model Registry
Let's create a Snowflake Model Registry to track our models:
from snowflake.ml.registry import Registry # Define model name model_name = f"MORTGAGE_LENDING_MLOPS_{VERSION_NUM}" # Create a registry to log the model to model_registry = Registry(session=session, database_name=DB, schema_name=SCHEMA, options={"enable_monitoring": True})
Register Baseline Model
Now, let's register our baseline model in the registry:
base_version_name = 'XGB_BASE' try: mv_base = model_registry.get_model(model_name).version(base_version_name) print("Found existing model version!") except: print("Logging new model version...") mv_base = model_registry.log_model( model_name=model_name, model=xgb_base, version_name=base_version_name, sample_input_data = train.drop(["TIMESTAMP", "LOAN_ID", "MORTGAGERESPONSE"]).limit(100), comment = """ML model for predicting loan approval likelihood. This model was trained using xgboost classifier. Hyperparameters used were: max_depth=50, n_estimators=3, learning_rate = 0.75, algorithm = gbtree. """, ) mv_base.set_metric(metric_name="Train_F1_Score", value=f1_base_train) mv_base.set_metric(metric_name="Train_Precision_Score", value=precision_base_train) mv_base.set_metric(metric_name="Train_Recall_score", value=recall_base_train)
Create Production Tag and Apply to Model
Let's create a tag for our production model:
#Create tag for PROD model session.sql("CREATE OR REPLACE TAG PROD") #Apply prod tag m = model_registry.get_model(model_name) m.comment = "Loan approval prediction models" #set model level comment m.set_tag("PROD", base_version_name)
Evaluate Baseline Model on Test Data
Let's see how our baseline model performs on the test data:
reg_preds = mv_base.run(test, function_name = "predict").rename(col('"output_feature_0"'), "MORTGAGE_PREDICTION") preds_pd = reg_preds.select(["MORTGAGERESPONSE", "MORTGAGE_PREDICTION"]).to_pandas() f1_base_test = round(f1_score(preds_pd.MORTGAGERESPONSE, preds_pd.MORTGAGE_PREDICTION),4) precision_base_test = round(precision_score(preds_pd.MORTGAGERESPONSE, preds_pd.MORTGAGE_PREDICTION),4) recall_base_test = round(recall_score(preds_pd.MORTGAGERESPONSE, preds_pd.MORTGAGE_PREDICTION),4) #log metrics to model registry model mv_base.set_metric(metric_name="Test_F1_Score", value=f1_base_test) mv_base.set_metric(metric_name="Test_Precision_Score", value=precision_base_test) mv_base.set_metric(metric_name="Test_Recall_score", value=recall_base_test) print(f'F1: {f1_base_test} \nPrecision {precision_base_test} \nRecall: {recall_base_test}')
Hyperparameter Optimization
Our baseline model shows signs of overfitting, with performance dropping significantly from training to test data. Let's use Snowflake's distributed hyperparameter optimization to improve our model.
Set Up Hyperparameter Optimization
X_train = train.drop("MORTGAGERESPONSE", "TIMESTAMP", "LOAN_ID") y_train = train.select("MORTGAGERESPONSE") X_test = test.drop("MORTGAGERESPONSE","TIMESTAMP", "LOAN_ID") y_test = test.select("MORTGAGERESPONSE") from snowflake.ml.data import DataConnector from snowflake.ml.modeling.tune import get_tuner_context from snowflake.ml.modeling import tune from entities import search_algorithm #Define dataset map dataset_map = { "x_train": DataConnector.from_dataframe(X_train), "y_train": DataConnector.from_dataframe(y_train), "x_test": DataConnector.from_dataframe(X_test), "y_test": DataConnector.from_dataframe(y_test) } # Define a training function def train_func(): # A context object provided by HPO API to expose data for the current HPO trial tuner_context = get_tuner_context() config = tuner_context.get_hyper_params() dm = tuner_context.get_dataset_map() model = XGBClassifier(**config, random_state=42) model.fit(dm["x_train"].to_pandas().sort_index(), dm["y_train"].to_pandas().sort_index()) f1_metric = f1_score( dm["y_train"].to_pandas().sort_index(), model.predict(dm["x_train"].to_pandas().sort_index()) ) tuner_context.report(metrics={"f1_score": f1_metric}, model=model) tuner = tune.Tuner( train_func=train_func, search_space={ "max_depth": tune.randint(1, 10), "learning_rate": tune.uniform(0.01, 0.1), "n_estimators": tune.randint(50, 100), }, tuner_config=tune.TunerConfig( metric="f1_score", mode="max", search_alg=search_algorithm.RandomSearch(random_state=101), num_trials=8, max_concurrent_trials=4, ), )
Run Hyperparameter Optimization
#Train several model candidates (note this may take 1-2 minutes) tuner_results = tuner.run(dataset_map=dataset_map) #Select best model results and inspect configuration tuned_model = tuner_results.best_model
Evaluate Optimized Model
Let's evaluate our optimized model on both training and test data:
#Generate predictions xgb_opt_preds = tuned_model.predict(train_pd.drop(["TIMESTAMP", "LOAN_ID", "MORTGAGERESPONSE"],axis=1)) #Generate performance metrics f1_opt_train = round(f1_score(train_pd.MORTGAGERESPONSE, xgb_opt_preds),4) precision_opt_train = round(precision_score(train_pd.MORTGAGERESPONSE, xgb_opt_preds),4) recall_opt_train = round(recall_score(train_pd.MORTGAGERESPONSE, xgb_opt_preds),4) print(f'Train Results: \nF1: {f1_opt_train} \nPrecision {precision_opt_train} \nRecall: {recall_opt_train}') #Generate test predictions xgb_opt_preds_test = tuned_model.predict(test_pd.drop(["TIMESTAMP", "LOAN_ID", "MORTGAGERESPONSE"],axis=1)) #Generate performance metrics on test data f1_opt_test = round(f1_score(test_pd.MORTGAGERESPONSE, xgb_opt_preds_test),4) precision_opt_test = round(precision_score(test_pd.MORTGAGERESPONSE, xgb_opt_preds_test),4) recall_opt_test = round(recall_score(test_pd.MORTGAGERESPONSE, xgb_opt_preds_test),4) print(f'Test Results: \nF1: {f1_opt_test} \nPrecision {precision_opt_test} \nRecall: {recall_opt_test}')
Register Optimized Model
#Log the optimized model to the model registry optimized_version_name = 'XGB_Optimized' try: mv_opt = model_registry.get_model(model_name).version(optimized_version_name) print("Found existing model version!") except: print("Logging new model version...") mv_opt = model_registry.log_model( model_name=model_name, model=tuned_model, version_name=optimized_version_name, sample_input_data = train.drop(["TIMESTAMP", "LOAN_ID", "MORTGAGERESPONSE"]).limit(100), comment = "snow ml model built off feature store using HPO model", ) mv_opt.set_metric(metric_name="Train_F1_Score", value=f1_opt_train) mv_opt.set_metric(metric_name="Train_Precision_Score", value=precision_opt_train) mv_opt.set_metric(metric_name="Train_Recall_score", value=recall_opt_train) mv_opt.set_metric(metric_name="Test_F1_Score", value=f1_opt_test) mv_opt.set_metric(metric_name="Test_Precision_Score", value=precision_opt_test) mv_opt.set_metric(metric_name="Test_Recall_score", value=recall_opt_test)
Update Default Model and Production Tag
#Set the optimized model to be the default model version model_registry.get_model(model_name).default = optimized_version_name #Update the PROD tagged model to be the optimized model version m.unset_tag("PROD") m.set_tag("PROD", optimized_version_name)
Model Explainability
Snowflake offers built-in explainability capabilities for models logged in the Model Registry. Let's generate SHAP values to understand how input features impact our models' predictions.
Generate SHAP Values
#Create a sample of records for explanation test_pd_sample=test_pd.rename(columns=rename_dict).sample(n=2500, random_state = 100).reset_index(drop=True) #Compute shapley values for each model base_shap_pd = mv_base.run(test_pd_sample, function_name="explain") opt_shap_pd = mv_opt.run(test_pd_sample, function_name="explain")
Visualize Feature Importance
import shap # Summary plot for base model shap.summary_plot(np.array(base_shap_pd.astype(float)), test_pd_sample.drop(["LOAN_ID","MORTGAGERESPONSE", "TIMESTAMP"], axis=1), feature_names = test_pd_sample.drop(["LOAN_ID","MORTGAGERESPONSE", "TIMESTAMP"], axis=1).columns) # Summary plot for optimized model shap.summary_plot(np.array(opt_shap_pd.astype(float)), test_pd_sample.drop(["LOAN_ID","MORTGAGERESPONSE", "TIMESTAMP"], axis=1), feature_names = test_pd_sample.drop(["LOAN_ID","MORTGAGERESPONSE", "TIMESTAMP"], axis=1).columns)
Analyze Feature Impact
Let's analyze how specific features impact our models' predictions:
#Merge shap vals and actual vals together for easier plotting all_shap_base = test_pd_sample.merge(base_shap_pd, right_index=True, left_index=True, how='outer') all_shap_opt = test_pd_sample.merge(opt_shap_pd, right_index=True, left_index=True, how='outer') import seaborn as sns import matplotlib.pyplot as plt # Analyze income impact asb_filtered = all_shap_base[(all_shap_base.INCOME>0) & (all_shap_base.INCOME<250000)] aso_filtered = all_shap_opt[(all_shap_opt.INCOME>0) & (all_shap_opt.INCOME<250000)] fig, axes = plt.subplots(1, 2, figsize=(10, 6)) fig.suptitle("INCOME EXPLANATION") sns.scatterplot(data = asb_filtered, x ='INCOME', y = 'INCOME_explanation', ax=axes[0]) sns.regplot(data = asb_filtered, x ="INCOME", y = 'INCOME_explanation', scatter=False, color='red', line_kws={"lw":2},ci =100, lowess=False, ax =axes[0]) axes[0].set_title('Base Model') sns.scatterplot(data = aso_filtered, x ='INCOME', y = 'INCOME_explanation',color = "orange", ax = axes[1]) sns.regplot(data = aso_filtered, x ="INCOME", y = 'INCOME_explanation', scatter=False, color='blue', line_kws={"lw":2},ci =100, lowess=False, ax =axes[1]) axes[1].set_title('Opt Model') plt.show()
Model Monitoring Setup
Let's set up model monitoring to track our models' performance over time.
Save Training and Test Data
train.write.save_as_table(f"DEMO_MORTGAGE_LENDING_TRAIN_{VERSION_NUM}", mode="overwrite") test.write.save_as_table(f"DEMO_MORTGAGE_LENDING_TEST_{VERSION_NUM}", mode="overwrite")
Create Inference Stored Procedure
from snowflake import snowpark def demo_inference_sproc(session: snowpark.Session, table_name: str, modelname: str, modelversion: str) -> str: reg = Registry(session=session) m = reg.get_model(model_name) mv = m.version(modelversion) input_table_name=table_name pred_col = f'{modelversion}_PREDICTION' # Read the input table to a dataframe df = session.table(input_table_name) results = mv.run(df, function_name="predict").select("LOAN_ID",'"output_feature_0"').withColumnRenamed('"output_feature_0"', pred_col) final = df.join(results, on="LOAN_ID", how="full") # Write results back to Snowflake table final.write.save_as_table(table_name, mode='overwrite',enable_schema_evolution=True) return "Success" # Register the stored procedure session.sproc.register( func=demo_inference_sproc, name="model_inference_sproc", replace=True, is_permanent=True, stage_location="@ML_STAGE", packages=['joblib', 'snowflake-snowpark-python', 'snowflake-ml-python'], return_type=StringType() )
Run Inference on Training and Test Data
CALL model_inference_sproc('DEMO_MORTGAGE_LENDING_TRAIN_0','MORTGAGE_LENDING_MLOPS_0', 'XGB_BASE'); CALL model_inference_sproc('DEMO_MORTGAGE_LENDING_TEST_0','MORTGAGE_LENDING_MLOPS_0', 'XGB_BASE'); CALL model_inference_sproc('DEMO_MORTGAGE_LENDING_TRAIN_0','MORTGAGE_LENDING_MLOPS_0', 'XGB_OPTIMIZED'); CALL model_inference_sproc('DEMO_MORTGAGE_LENDING_TEST_0','MORTGAGE_LENDING_MLOPS_0', 'XGB_OPTIMIZED');
Create Model Monitors
CREATE OR REPLACE MODEL MONITOR MORTGAGE_LENDING_BASE_MODEL_MONITOR WITH MODEL=MORTGAGE_LENDING_MLOPS_0 VERSION=XGB_BASE FUNCTION=predict SOURCE=DEMO_MORTGAGE_LENDING_TEST_0 BASELINE=DEMO_MORTGAGE_LENDING_TRAIN_0 TIMESTAMP_COLUMN=TIMESTAMP PREDICTION_CLASS_COLUMNS=(XGB_BASE_PREDICTION) ACTUAL_CLASS_COLUMNS=(MORTGAGERESPONSE) ID_COLUMNS=(LOAN_ID) WAREHOUSE=E2E_SNOW_MLOPS_WH REFRESH_INTERVAL='1 hour' AGGREGATION_WINDOW='1 day'; CREATE OR REPLACE MODEL MONITOR MORTGAGE_LENDING_OPTIMIZED_MODEL_MONITOR WITH MODEL=MORTGAGE_LENDING_MLOPS_0 VERSION=XGB_OPTIMIZED FUNCTION=predict SOURCE=DEMO_MORTGAGE_LENDING_TEST_0 BASELINE=DEMO_MORTGAGE_LENDING_TRAIN_0 TIMESTAMP_COLUMN=TIMESTAMP PREDICTION_CLASS_COLUMNS=(XGB_OPTIMIZED_PREDICTION) ACTUAL_CLASS_COLUMNS=(MORTGAGERESPONSE) ID_COLUMNS=(LOAN_ID) WAREHOUSE=E2E_SNOW_MLOPS_WH REFRESH_INTERVAL='12 hours' AGGREGATION_WINDOW='1 day';
Query Model Drift Metrics
SELECT * FROM TABLE(MODEL_MONITOR_DRIFT_METRIC( 'MORTGAGE_LENDING_BASE_MODEL_MONITOR', -- model monitor to use 'DIFFERENCE_OF_MEANS', -- metric for computing drift 'XGB_BASE_PREDICTION', -- column to compute drift on '1 DAY', -- day granularity for drift computation DATEADD(DAY, -90, CURRENT_DATE()), -- end date DATEADD(DAY, -60, CURRENT_DATE()) -- start date ))
Conclusion And Resources
You just walked through a guided experience building and deploying a complete end-to-end machine learning workflow within Snowflake ML for a mortgage lending prediction case. The workflow covers feature engineering with Snowflake Feature Store, model training and hyperparameter optimization using Snowflake ML APIs, model logging and management with Snowflake Model Registry, and model performance tracking and drift detection via ML Observability.
Ready for more? After you complete this quickstart, you can try one of the following additional examples:
Related Resources
This content is provided as is, and is not maintained on an ongoing basis. It may be out of date with current Snowflake instances