


Blog
Beschleunigung von scikit-learn und pandas in Snowflake mit GPUs
Erfahren Sie, wie Sie mit GPUs die Modellentwicklung für scikit-learn, pandas, UMAP und HDBSCAN beschleunigen können – ohne Codeänderungen.
Beschleunigen Sie maschinelles Lernen mit verteilten GPUs oder CPUs auf derselben Plattform wie Ihre kontrollierten Daten. Optimieren Sie die Modellentwicklung sowie MLOps für Echtzeit- und Batch-Workflows ohne manuellen Konfigurations- oder Wartungsaufwand für die Infrastruktur – alles über eine einzige, zentrale Benutzeroberfläche.


Übersicht
Entwickeln, implementieren und überwachen Sie ML-Features und -Modelle auf einer vollständig integrierten Plattform, die Tools, Echtzeit- und Batch-Workflows und skalierbare Rechenressourcen mit den Daten zusammenführt.

Vereinheitlichen Sie Modell-Pipelines durchgängig mit jedem beliebigen Open-Source-Modell auf derselben Plattform, auf der sich auch Ihre Daten befinden.

Skalieren Sie ML-Pipelines über CPUs oder GPUs mit integrierten Infrastrukturoptimierungen – keine manuelle Anpassung oder Konfiguration erforderlich.

Entdecken, verwalten und kontrollieren Sie Features und Modelle in Snowflake über den gesamten Lebenszyklus hinweg.




ML-Workflow
Modellentwicklung
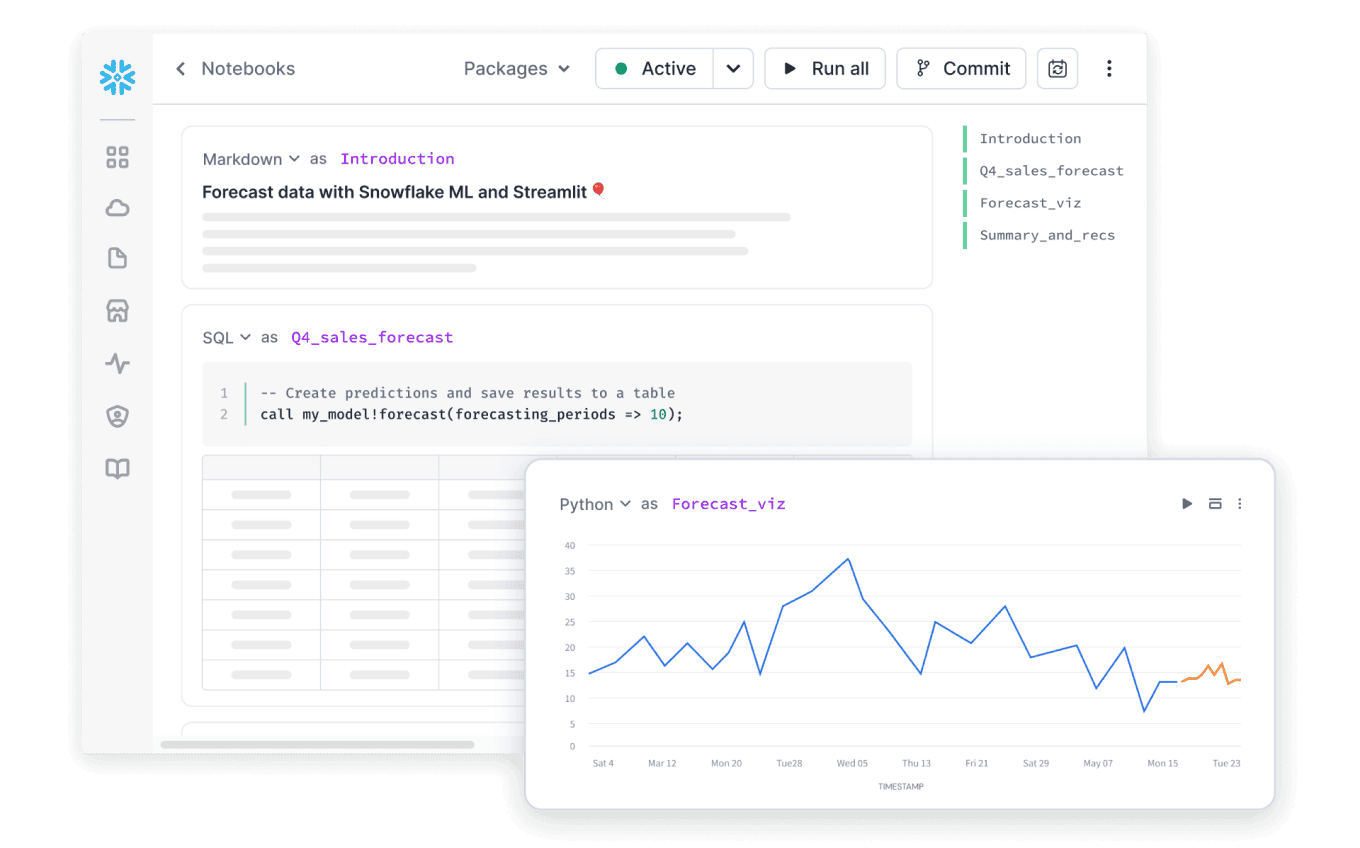
Optimieren Sie das Laden von Daten und verteilen Sie das Modelltraining mit ML Jobs – direkt aus Snowflake Notebooks oder einer IDE Ihrer Wahl.

Feature-Management
Erstellen, verwalten und stellen Sie ML-Features bereit – mit kontinuierlicher, automatisierter Aktualisierung für Batch- oder Streaming-Daten in unter 30 Millisekunden mithilfe des Snowflake Feature Store.
Verbessern Sie die Auffindbarkeit, Wiederverwendbarkeit und Governance von Features über das gesamte Training und die Inferenz hinweg.
Suchen Sie ganz einfach nach Features und verfolgen Sie diese in der gesamten Pipeline visuell nach – über die integrierte Feature Store-Benutzeroberfläche.
Produktion
Stellen Sie Modelle in unter 100 Millisekunden bereit, um Online-Anwendungsfälle mit niedriger Latenz wie personalisierte Empfehlungen und Betrugserkennung zu unterstützen.

„Früher dauerte es eine halbe Stunde, all diese Modelle zu trainieren und Vorhersagen zu erzeugen. Das zentralisierte Snowflake-Modell ist superschnell: Prognosen für Hunderttausende Kund:innen sind binnen weniger Minuten generiert. Diese Geschwindigkeit und Einfachheit ebnen unserem Unternehmen den Weg zu zusätzlichen Möglichkeiten wie Simulationen und Szenarioprognosen.“
Dan Shah
Manager of Data Science


„Indem wir in Snowflake vollständig automatisierte Echtzeit-Gebührenschätzungen mit einer Genauigkeit von 97 bis 99 % bereitstellen, können wir die Kostentransparenz steigern und das Vertrauen in Abrechnungs- und Berichtsprozesse stärken.“
Venkata Kalyan Sanaboyina
Senior Engineering Lead

Erfahren Sie mehr über die integrierten Funktionen für Entwicklung
und Produktion in Snowflake ML
Erste Schritte
End-to-End-ML
Ja, Data Scientists und ML Engineers können Modelle mit verteilter Verarbeitung auf CPUs oder GPUs entwickeln und bereitstellen. Möglich wird dies durch die zugrunde liegende, moderne, Ray-basierte Container-Infrastruktur, auf der die Snowflake ML-Plattform aufbaut.
Ja, Snowflake ML verarbeitet sowohl Online- als auch Batch-Workloads. Für Echtzeitanforderungen stehen unser Online-Feature Store und die Online-Modellinferenz allgemein zur Verfügung, um Anwendungsfälle wie personalisierte Empfehlungen, Betrugserkennung, Preisoptimierung und Anomalieerkennung zu unterstützen.
Nein, Sie können Modelle, die an beliebigen Orten extern entwickelt wurden, mit Snowflake-Daten in der Produktion ausführen. Während der Inferenz können Sie von integrierten MLOps-Funktionen wie ML-Beobachtbarkeit und RBAC-Governance profitieren.
Ja, Snowflake ML ist vollständig mit jeder Open-Source-Bibliothek kompatibel. Greifen Sie über pip sicher auf Open-Source-Repositorys zu und importieren Sie beliebige Modelle von Hubs wie Hugging Face.
Snowflake arbeitet nach einem verbrauchsabhängigen Preismodell. Sie finden die neueste Credit-Pricing-Tabelle hier.
Ja, Sie können jeden unserer ML-Quickstarts direkt über die kostenlose Testversion ausprobieren.




