




„Wir wollten aus Performancegründen zu Snowpark wechseln und die Umstellung war wirklich einfach. Für die Umwandlung unseres PySpark-Codes in Snowpark mussten wir einfach nur einen Importbefehl ändern.“
Principal Data Engineer
Homegenius
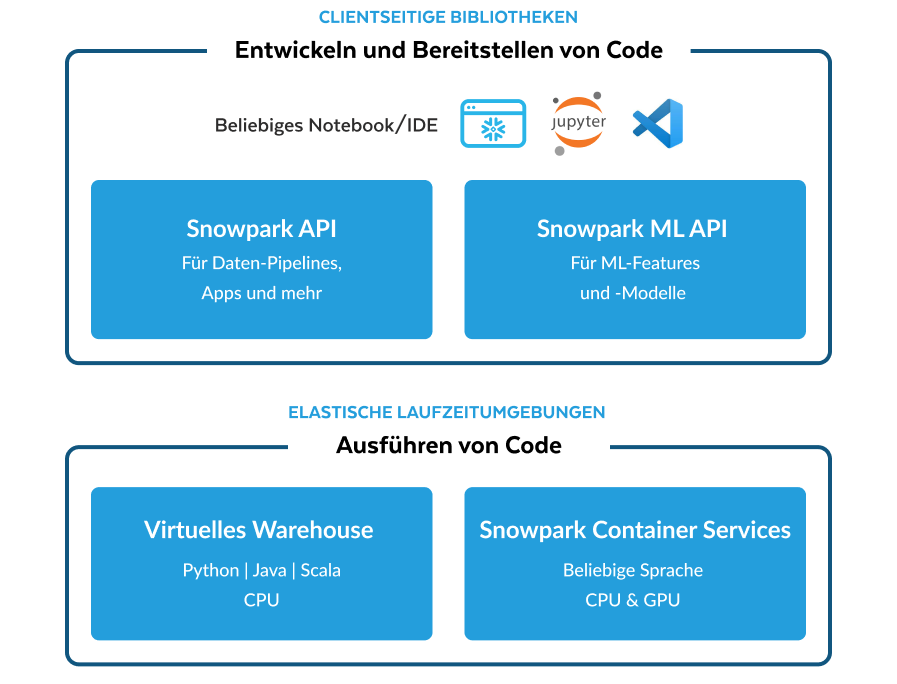
Ein Reihe von Bibliotheken und Code-Ausführungsumgebungen, die Python und weitere Programmiersprachen parallel zu Ihren Daten in Snowflake ausführen.

Bringen Sie Python- und anderen Code zu Ihren kontrollierten Daten in Snowflake.
Wartungsfreie elastische Skalierbarkeit ohne Gemeinkosten.
Konsistente Governance-Kontrollen und Sicherheit für Unternehmen.
Verwenden Sie DataFrames – Spark oder skalierbarem pandas nachempfunden –, um Abfragen zu schreiben oder Daten umzuwandeln (in Public Preview).
Über diese Python-Bibliothek erhalten Sie Zugang zu einheitlichen APIs, mit denen Sie Modelle und Features entwickeln und ausführen können, die den gesamten ML-Lebenszyklus in Snowflake ML abdecken.
Mithilfe von User-Defined Functions und Stored Procedures können Sie benutzerdefinierten Python-, Java- oder Scala-Code schreiben und ausführen. Nutzen Sie integrierte Packages aus dem Anaconda-Repository.
Sie können Container-Images (in Public Preview) in von Snowflake verwalteter Infrastruktur registrieren, bereitstellen und ausführen.
Transformieren Sie mit Python Rohdaten in modellierte Formate für Daten-Pipelines
Im Vergleich zu einer verwalteten Spark-Lösung erzielen Kunden mit Snowpark im Durchschnitt eine 4,6-mal höhere Performance und 35 % Kosteneinsparungen.1
Transformation von Daten in Snowflake, die mit Ihrem Data Lake, Warehouse oder Ihren Iceberg Tables verknüpft sind.
Erstellen und operationalisieren Sie End-to-End ML-Workflows mit Snowpark ML
Nutzen Sie Python-Frameworks wie Scikit-learn und XGBoost für die Vorverarbeitung, das Feature Engineering und das Training von Modellen, die in Snowflake ML bereitgestellt und verwaltet werden können, ohne Daten bewegen zu müssen.
Entwickeln Sie ML-Modelle und GenAI-LLMs in jeder beliebigen Programmiersprache, erstellen Sie daraus ein Container-Image und stellen Sie es für maximale Flexibilität bei der Entwicklung in konfigurierbaren CPUs und GPUs bereit.
* Stand: April 2024




















„Die Möglichkeit, Data Science Tasks wie Feature Engineering direkt dort auszuführen, wo sich die Daten befinden, ist ein riesiger Vorteil. Unsere Arbeit ist dadurch viel effizienter geworden und macht auch mehr Spaß.“
Data Science Lead
EDF
1 Basierend auf Produktions-Anwendungsfällen von Kunden und Proof-of-Concept-Projekten, in denen die Geschwindigkeit und die Kosten von Snowpark im Vergleich zu verwalteten Spark-Services zwischen November 2022 und Januar 2024 verglichen werden. Alle Ergebnisse basieren auf tatsächlichen Kundenergebnissen mit realen Daten und repräsentieren keine fiktiven, als Benchmarks verwendeten Datasets.

