ユースケース
ストリーミングとバッチの サイロを解決
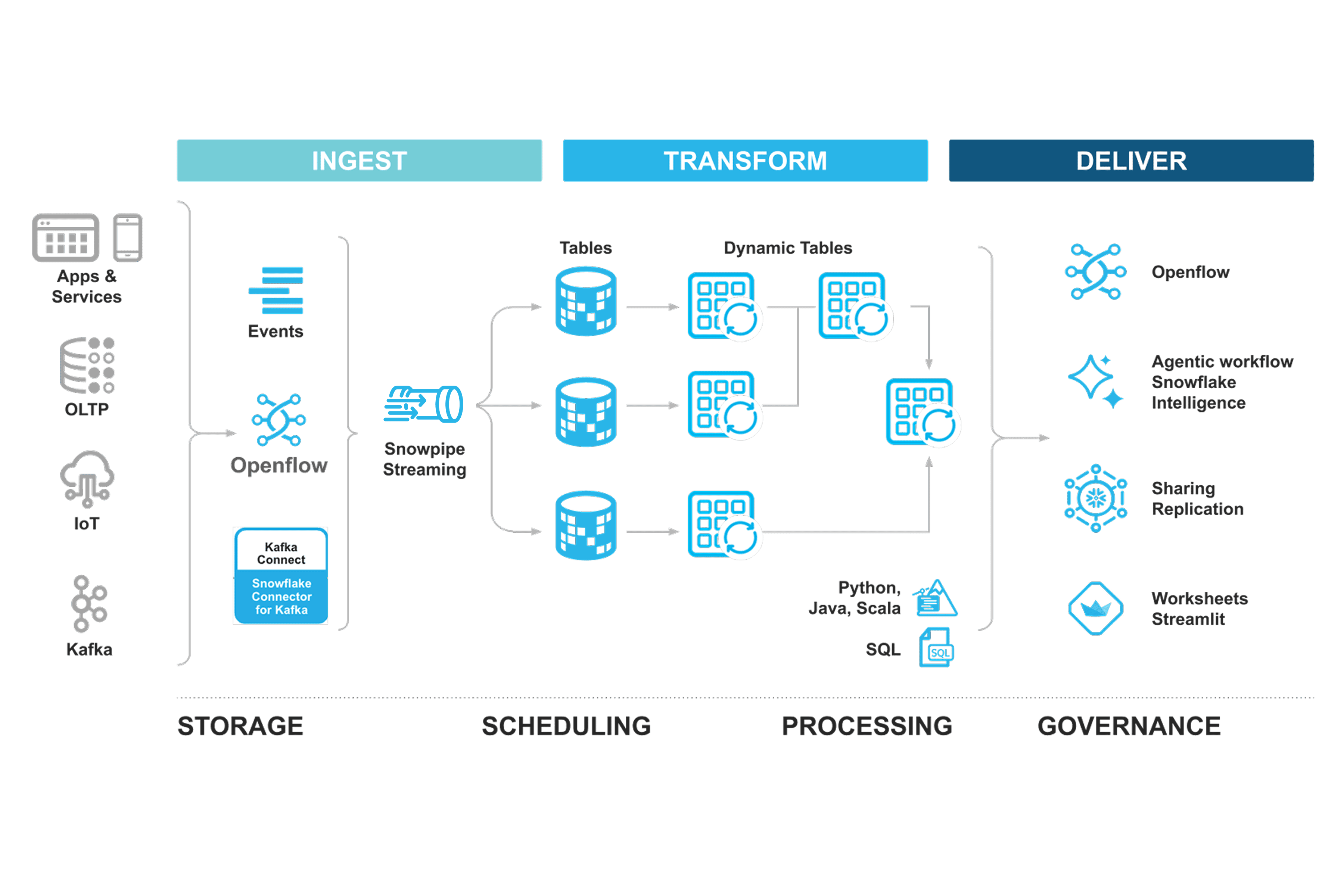
ストリーミングとバッチのパイプラインを分離する必要がなくなりました。取り込みと変換が、単一のシステムに統合されます。



1つのシステムでデータパイプラインを簡素化
ストリームとバッチの取り込みと処理のパイプラインを1つのアーキテクチャに統合します。履歴データの存在する場所で、低レイテンシーでデータのストリーミングと処理を実行できます。Snowflake Openflowによる事前構築済みのストリーミングコネクタでデータを簡単に取り込みSQLを使用して、ダイナミックテーブルで多数のユースケースのストリーミングデータを処理します。
無駄なコンピュートを排除してコストを最適化
行セットのストリーミング取り込みは、同じボリュームのファイル取り込みと比較して50%も安価です。ダイナミックテーブルは、増分リフレッシュまたはフルリフレッシュによるパフォーマンスガイダンスを提供してより効率的な変換を実施し、コンピュートの無駄を回避します。
AIデータクラウドを活用する
Snowflake Horizonカタログとの深い統合を通じて、ストリーミングデータとAIアセットをセキュアに保護し、信頼できるセキュリティとガバナンスを維持します。
高スループット、低レイテンシーのストリーミングデータ
- Snowflake Openflowは、Apache Kafka†、Amazon Kinesis†、Kafka Sink*などのストリーミングソースに直接接続できるため、ストリーミングデータをSnowflakeに流し込み、ストリーミングシステムに戻すことができます。
- Snowpipe Streamingの次世代アーキテクチャは、テーブルあたり最大10 GB/秒のスループットをサポートし、予測可能な取り込みベースの料金モデルを提供します。これにより、大規模なワークフロー実行における費用対効果が向上します。

単一のパラメータ変更でレイテンシー調整が可能
- ダイナミックテーブルを使用することで、SQLまたはPythonを使用してデータ変換を宣言的に定義できます。Snowflakeが依存関係を管理し、鮮度の目標に基づいて結果を自動的にマテリアライズします。ダイナミックテーブルが動作するのは前回のリフレッシュ以降に変更されたデータに対してのみです。そのため、大量のデータと複雑なパイプラインがシンプルになり、コスト効果が向上します。
- ビジネスニーズが変化しても、単一のレイテンシーパラメータを変更してバッチパイプラインをストリーミングパイプラインに切り替えるだけで容易に適応できます。
オープンレイクハウスにストリーミング機能を取り込む
- Snowflakeのストリーミング機能はApache Icebergフォーマットと連携し、汎用性の高い処理オプションによりオープンレイクハウスアーキテクチャを簡単に構築できます。
- Snowflake Openflowは、Apache Icebergフォーマットでデータを保持し、Apache Polarisベースのカタログをサポートします。さらに、Snowflakeの外部マネージドおよびアンマネージドのApache Icebergテーブルの両方に対して、ダイナミックテーブルを用いた低レイテンシーの宣言型処理を構築できます。


「私たちはビジネスの構築方法よりもビジネスの内容の方に注力することができるようになりました」
—Dan Shah氏
データサイエンス担当マネージャー
- 1週間移行後に130個のダイナミックテーブルが実稼働するまでにかかった期間
- 65%DatabricksからSnowflakeに切り替えたことによるコスト削減率

開発者 関連リソース
Snowflakeのクイックスタートチュートリアルで手順を確認するか、近日中に開催されるウェビナーに参加して、Snowflakeダイナミックテーブルの使用を開始できます。



