SnowflakeのDocument AIで複雑なドキュメントから実行可能なインサイトを引き出す

今日の企業は、シンプルな請求書から複雑な法的契約書、詳細な複数の列テーブルを含む技術マニュアルまで、膨大な量の多様なドキュメントを活用しています。こうしたドキュメントを手作業で処理すると、時間がかかり、リソースを大量に消費するだけでなく、エラーも発生しやすくなります。また、面倒なタスクのために従業員の15~25%もの時間が失われています。
長年にわたって、企業はこれらの問題を解決するためにRPA、OCR、ワークフローツールに目を向けてきました。しかし、こうしたソリューションは多くの場合、メンテナンスやスケーリングが硬直的で複雑であるだけではなく、とりわけ個々のビジネスチームがそれぞれで孤立して導入する傾向にありました。
その解決策はAI活用の自動化にあり、コストを10分の1に削減できます。しかし、こうしたドキュメントの複雑さと多様性は大きな課題となっています。また、リッチな情報を含む構造化ドキュメントをフラットテキストとして扱う基本的なツールで処理すると、重要なビジネスコンテキストが失われ、アナリティクスやAIの有効性が損なわれます。
こうした課題を克服するためには、ドキュメントに含まれる関連情報を簡単、自動、正確に抽出するための一元化されたプラットフォームを提供する、インテリジェントなドキュメント処理(IDP)システムやDocument AIが必要です。
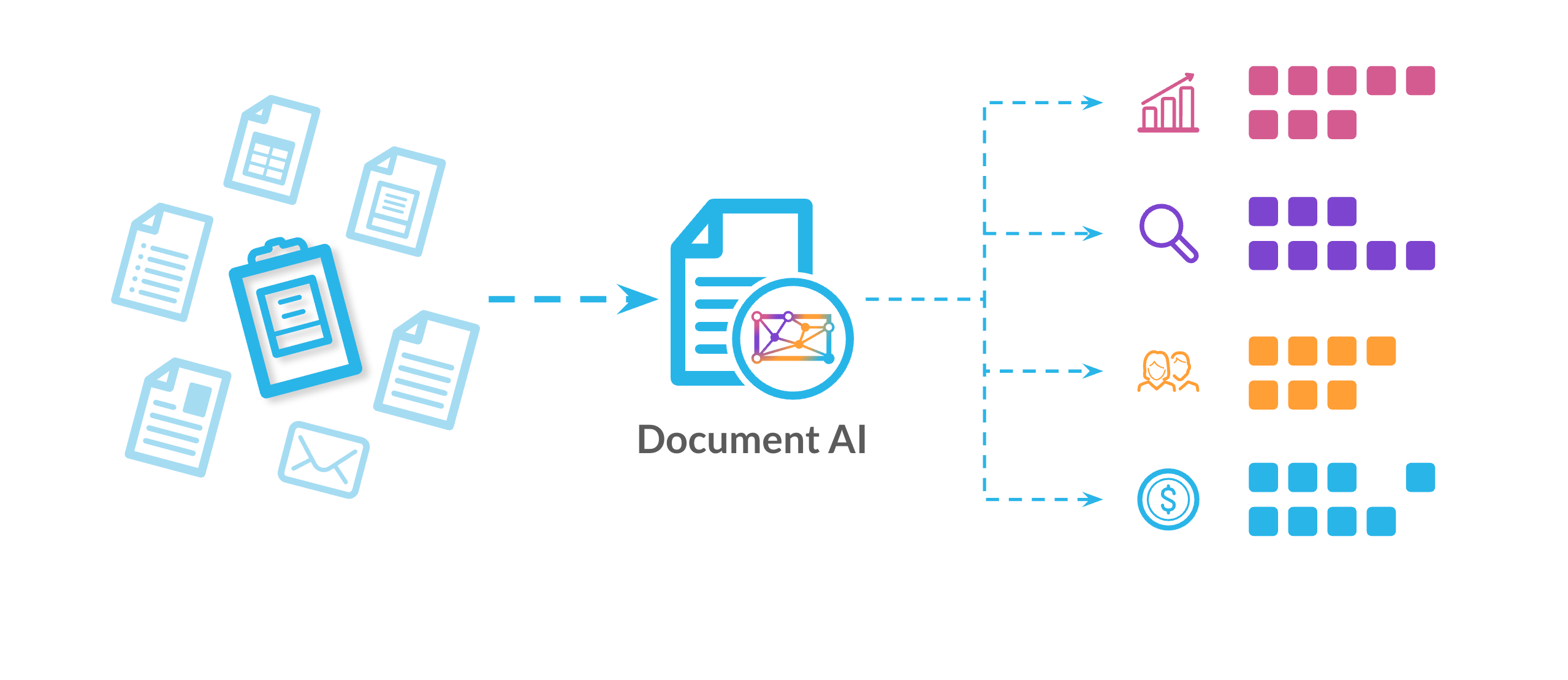
Document AIによるSnowflakeでのエンドツーエンドのインテリジェントなドキュメント処理
Snowflakeは、AIデータクラウド内でシームレスに統合された、ドキュメントインテリジェンスのための包括的なエンドツーエンドプラットフォームを提供します。これにより、セキュアでガバナンスの確保された単一の環境内で、取り込み、抽出、検証、適用までのドキュメント処理のライフサイクル全体を管理できます。
このエコシステムのコアコンポーネントであるSnowflake Cortex AIは、インテリジェントなアプリケーションのためのビルディングブロックを提供します。これらのビルディングブロックには、次のような機能があります。
- コンポーザブルフレームワーク:Snowflakeネイティブのインターフェイス、関数、LLM、Pythonロジックを組み合わせて、カスタマイズされたワークフローを実現
- エンドツーエンドのライフサイクルサポート:ドキュメントデータの取り込み、抽出、検証、適用をすべてSnowflake内で実行
- マルチフォーマット互換性:PDF、画像、手書きスキャンなど、10種類以上のフォーマットを変換なしに処理
- 構造化データと非構造化データ:ドキュメントデータを構造化されたSnowflakeソースと直接整合
- マルチモーダルインテリジェンス:テキスト、レイアウト、テーブル、画像を組み合わせて使用し、完全かつ正確に理解
- ヒューマンインザループ対応:レビューワークフロー、例外処理、検証ロジックを簡単に追加
- カスタムモデルトレーニング:統合されたサポートにより、抽出モデルのファインチューニングや事前トレーニング済みのモデルの使用が可能
- ネイティブ展開、一元的なガバナンス:Snowflakeの組み込みのセキュリティと可観測性により、すべてをプラットフォーム内で実行
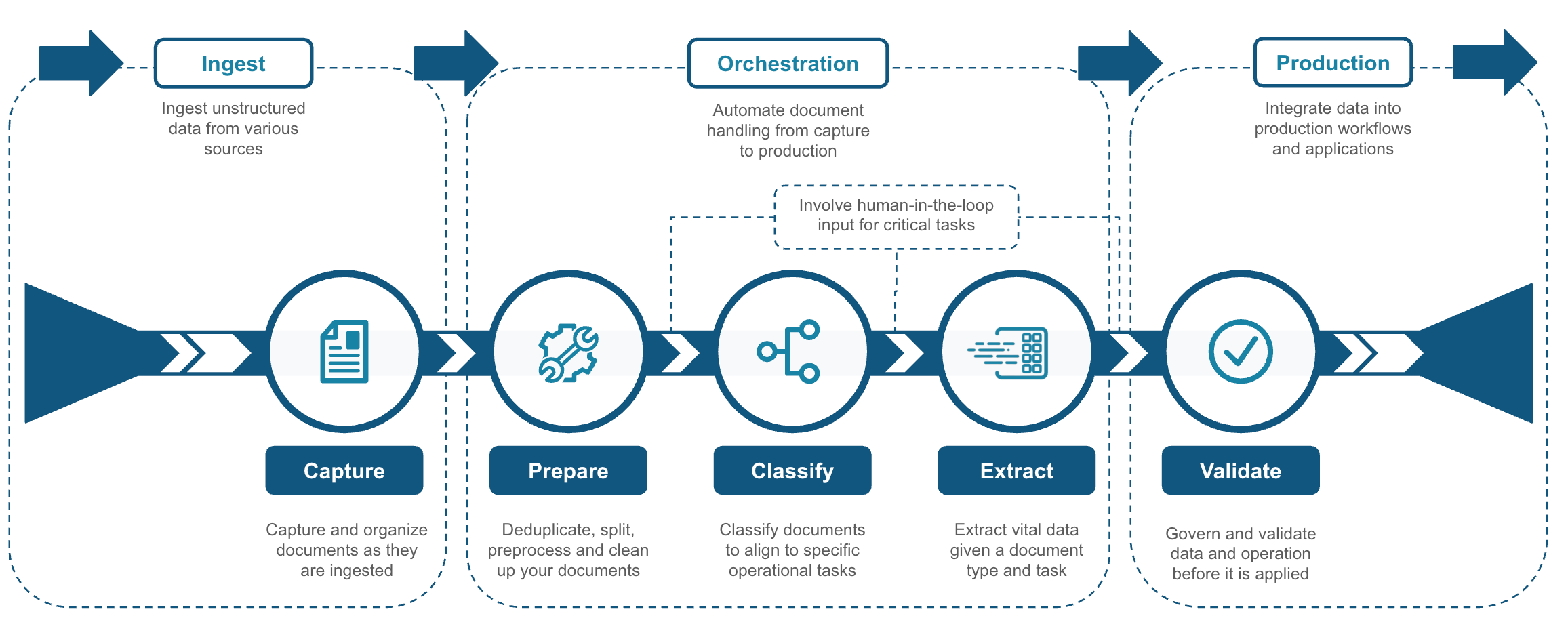
エキサイティングな新しいイノベーション
最近、Snowflakeはドキュメント処理機能を強化し、組織内のドキュメントインテリジェンスを今までにないレベルに向上するように支援しています。
- AI_EXTRACTは、ドキュメント、画像、テキストからあらゆる情報を抽出するための最も効率的でスケーラブルな方法を提供する、新しいAISQL関数です。Snowflakeの最新専有モデルArctic-Extractを搭載し、29言語をサポートしています。
- PARSE_DOCUMENT LAYOUTモードでは、抽出時に複雑なビジネスドキュメントのリッチな構造が維持され、エンタープライズの検索拡張生成(RAG)を改善します。
- Document AIのテーブル抽出機能により、ドキュメント内のテーブルから構造化された列データを抽出し、すぐに分析できるようになりました。
では、それぞれのレイヤーを詳しく見ていきましょう。
ドキュメント処理パイプラインの大規模なプログラマティックな構築と実行
つまり、AI_Extractは、多様な非構造化データをエンタープライズ規模で構造化形式に変換するためのSQL API推論ソリューションです。テキスト、画像、ドキュメントなどのソースから構造化情報を抽出し、標準フォーマットに統合して効率的なアナリティクスを実現できます。
この機能は、Snowflakeの次世代ドキュメント理解モデルであるArctic-Extractによって強化されており、画像、テキスト、レイアウトの情報を1回のパスで処理できるため、推論とトレーニングの時間が短縮します。
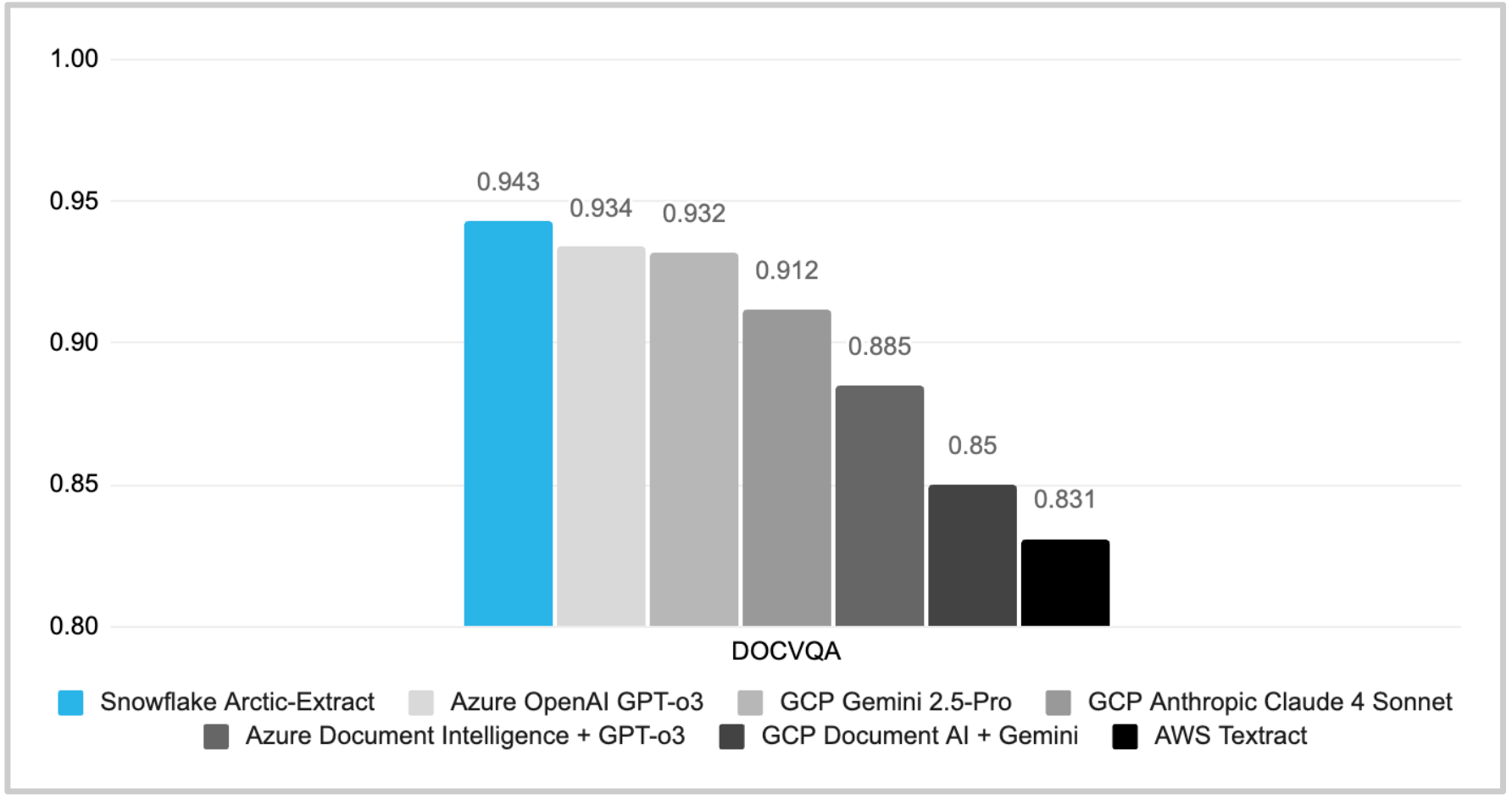
AI_EXTRACTのAPIファーストアプローチは、「コードとしてのインフラストラクチャ」の実践を可能にします。ユーザーは、UIを使用することなく、プログラムでデータを抽出し、特定のドキュメントの抽出プロンプトを動的に定義できます。これにより、さまざまなベンダーからの請求書など、さまざまな形式のドキュメントを柔軟に扱えるようになります。29言語のサポート、日付や通貨などの変数データ形式のインテリジェントな正規化などの追加機能も備えています。
複雑なマルチモーダルドキュメントのレイアウト認識解析
貸借対照表などの財務書類を分析する際には、内容の流れに従ってテーブルや列に表示される数字を理解することが不可欠です。たとえば、従来の文書処理では、データは正しく抽出できても、債務状況や金利について詳述する重要な脚注が完全に欠落していました。結果として「長期負債」などの項目と、その数値を絞り込むための対応する説明との間の重要なつながりが失われてしまいます。この場合、抽出した値を使用する分析やAIシステムの機能は、表面レベルのデータ程度しか活用できません。
PARSE_DOCUMENT LAYOUTモードは、このような課題に特化した設計になっています。ドキュメントの正確なレイアウトを保存することで、ドキュメントに含まれるテーブル、画像、複雑なレイアウトなど、必要な情報に関連するコンテキストを把握できます。これにより、処理中に複雑なテーブルを含むSECファイリングなどのドキュメントの整合性が維持されます。
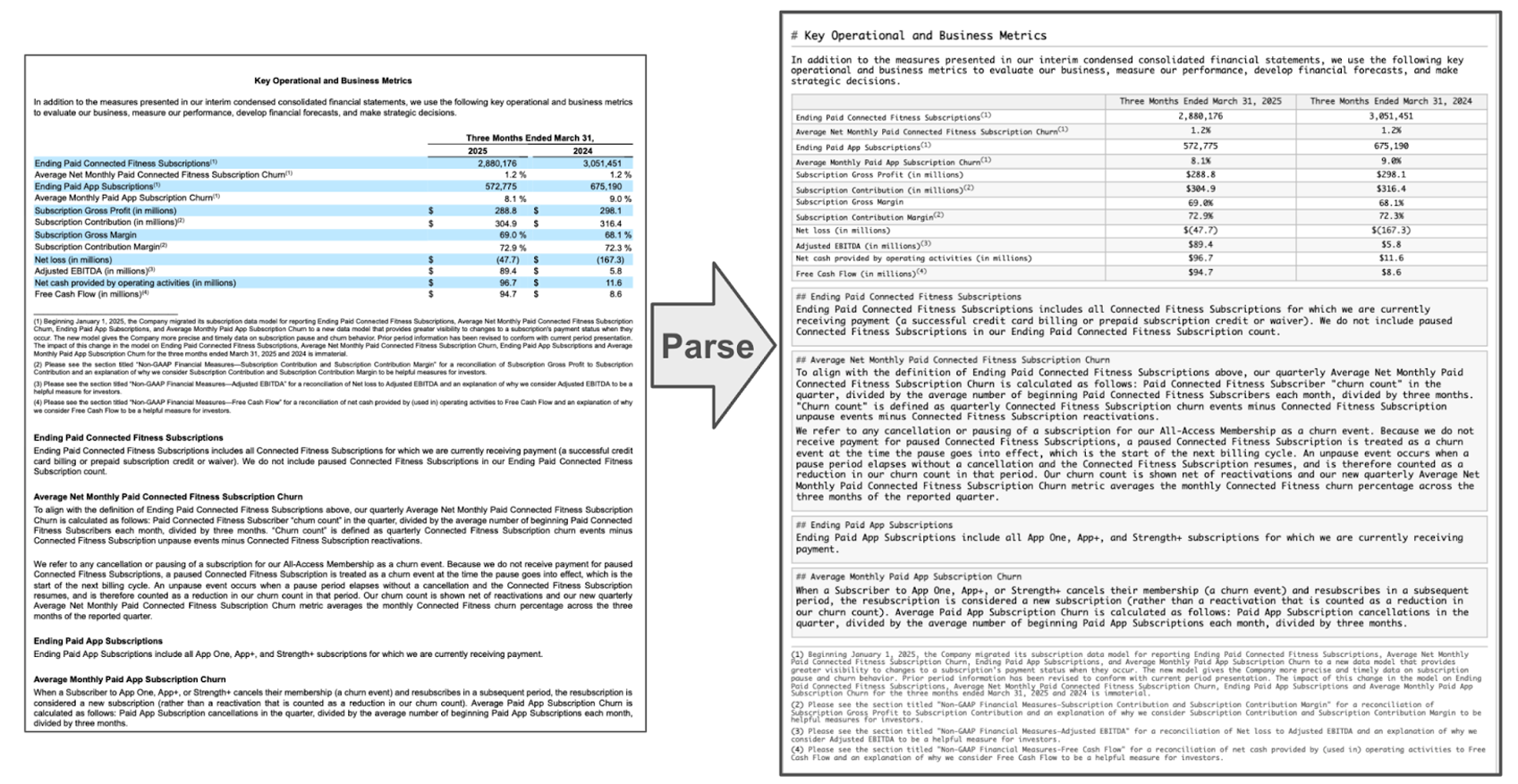
その結果、単なるデータ検索のレベルではなく、ドキュメントに対して詳細なアナリティクス問い合わせを実行できます。ここでは総資産の価値を尋ねるだけでなく、以下のようにさらに具体的な問い合わせが可能になりました。
- 「負債」のテーブルに記載されている債券の満期日と金利は?
- メモの情報によると、今四半期の「のれん」金額の増加の主な要因は何ですか?
- 収益認識に関する企業の会計方針を、損益計算書の前に記載されているとおりに要約してください。
ドキュメントからの正確なテーブル抽出
情報に基づいたビジネス上の意思決定を行うためには、契約書、請求書、その他の財務諸表などの複雑なドキュメントを頻繁に分析する必要があります。よくある例としては、年次10-Kレポートがあります。このレポートには、財務パフォーマンスに関する詳細なデータが複雑なテーブルに編成されているため、自動抽出は大きな課題となっています。また、手動での抽出は遅く、エラーが発生しがちで、リソースを大量に消費します。
SnowflakeのDocument AIは、新しいテーブル抽出機能を使用してこの課題に正面から取り組んでいます。たとえば、2025年世界経済見通し改訂版では、ほぼ同一の構造を持つ複数のテーブルが使用されています。
次の画像に示すように、Document AIはドキュメントから正しいテーブルを識別し、ネストしたヘッダーや行も含めて構造化された形式ですべてのデータを抽出するゼロショット抽出を実行します。基盤となるモデルは、ファインチューニングなしに複雑なレイアウトを処理できるほど強力です。
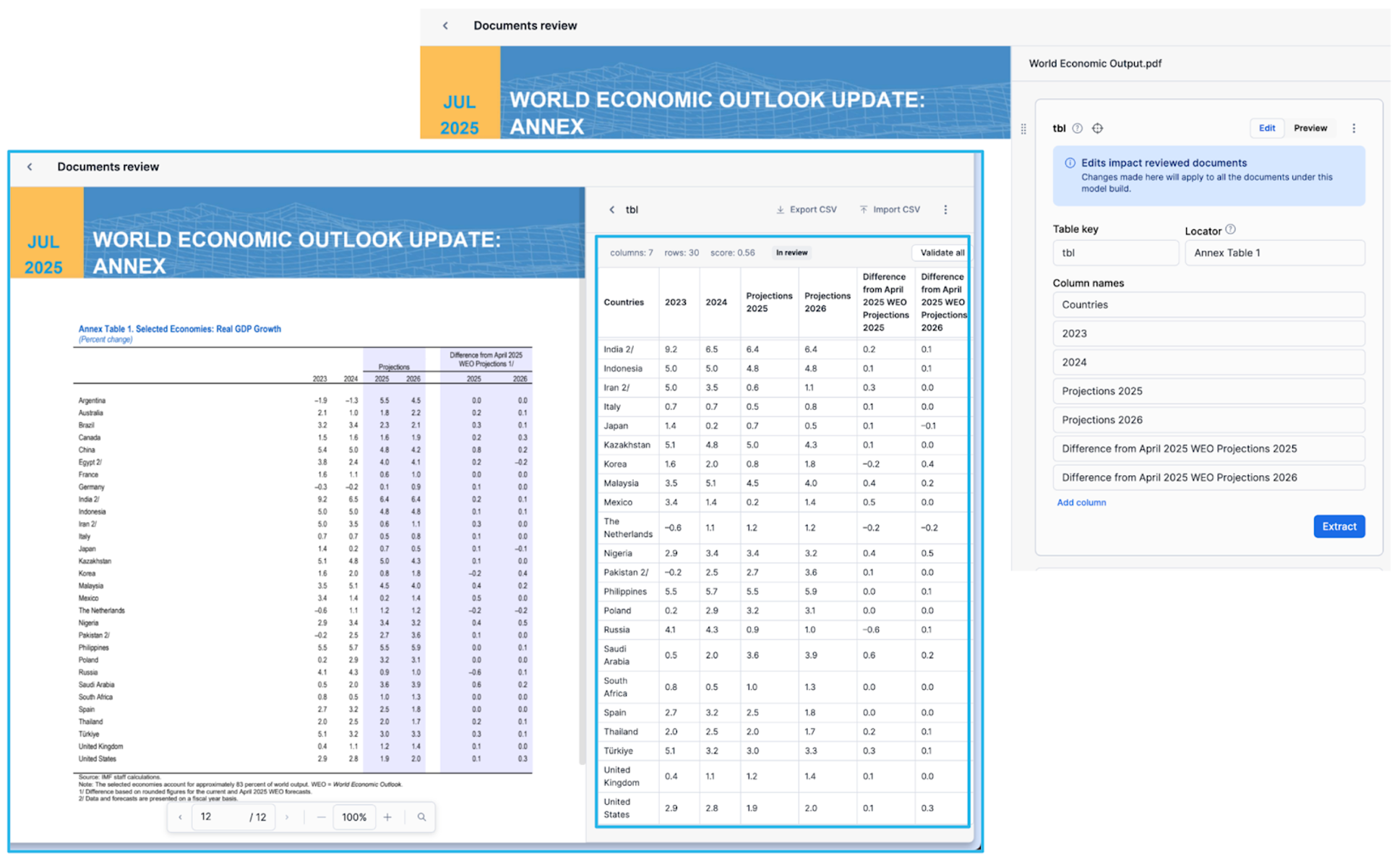
ゼロショット抽出だけでなく、スキーマを定義して自然言語で目的の列を指定することで、スキーマベースの抽出を使用することもできます。 類似のフォーマットの複数のテーブルを含むドキュメントでは、「Locator」フィールドを使用して、正しいテーブルを一意に特定してターゲティングできます。つまり、Document AIのテーブル抽出では、モデルの注釈付けとファインチューニングを実行して抽出の精度を改善できます。
Snowflakeのドキュメントインテリジェンス入門
複雑なドキュメントの処理は、遅くてエラーが起こりやすく、リソースを大量に消費する手動タスクではなくなりました。硬直的で重要なビジネスコンテキストが欠落した従来の自動化ソリューションは、過去のものとなっています。Snowflake Cortex AIは、ドキュメントインテリジェンスのための包括的なエンドツーエンドのプラットフォームを提供し、セキュアでガバナンスが確保された単一の環境内でドキュメント処理のライフサイクル全体を管理できます。
ここをクリックして、Cortex AIを使用して検索拡張生成(RAG)ベースのLLMアシスタントを構築する方法を学んでいただけます。また、今すぐ30日間無料トライアルをお試しください。
著者



