
FEB 03, 2026|約5分で読めます

何十年もデータ分野で働いてきた私たちにとって、「コンテキストレイヤー」への関心が最近爆発的に高まっていることは、私たちの正しさが証明されたように感じられます。同時に、非常に興味深い現象でもあります。これらは新しい概念ではありません。コンピューターサイエンスの基礎となる原則です。セマンティックレイヤーが再び注目を集めているのには理由があります。それは、ほとんどの企業が同じ不都合な現実に直面しているからです。モデルは賢く見えます。しかし、依然として自信満々に間違った回答を出力します。
モデルは大幅に賢くなっており、今後も改善され続けます。そのため、このような失敗はモデルの推論の問題ではありません。ボトルネックとなるのは「適切なコンテキスト」です。
制御されたデモ環境では、エージェントは非常に優秀に見えることがあります。しかし、エンタープライズでは状況が異なります。ビジネス概念が断片化し、ルールが暗黙で、履歴が欠落し、「真実」がシステム間で争われることもある環境で、エージェントは動作を強いられます。
アナリストの実際の仕事は、マルチステップで、複数領域にまたがり、政治的な側面も伴います。ビジネスリーダーは、単なるSQLクエリを求めているわけではありません。彼らは理由や課題、解決策について質問します。ビジネスリーダーが求めるのは、単なるSQLクエリではありません。「なぜ」「何が」を問うのです。
「何が変わったのかを見つけ、その理由を説明し、どうすべきかを提案してほしい」
「2つの定義を比較し、矛盾を解消して、役員会議向けの報告書を作成してほしい」
「異常を調査し、その原因となった運用イベントと関連付けてほしい」
ここで、次のようなエンタープライズの現実が浮き彫りになります。
意味のサイロ化:「顧客」の意味は、システムによって異なります。
「なぜ」の欠落:ウェアハウスは“状態”は記録しますが、その状態に至った意思決定や議論は記録しません。
暗黙のルール:会計カレンダー、適格基準、承認ポリシー、および禁止されているメトリクスは、多くの場合分散しています。また、特定のグループ内だけで共有されていることも少なくありません。
対立する真実:財務システムとCRMはどちらも「信頼できる」とされながら、内容が一致しないことがあります。
そのため、主な疑問は「モデルはSQLを生成できるか」から変化しています。現在の疑問は、「エージェントは企業の意味、ポリシー、履歴の範囲内で動作し、それを証明できるか」というものです。
まず、いくつかのコア概念を確立します。
アナリティクスセマンティックモデル:アナリティクスのためのインターフェイスです。メトリクス、ディメンション、エンティティを定義し、物理データにマッピングします。これにより、ユーザーはスキーマやSQLを知る必要がなくなります。
リレーションシップおよびIDレイヤー(エンタープライズでは「オントロジー」と呼ばれることが多い):ドメイン間の概念、関係、ルールを機械可読な形式で表現したものです。これには、ID解決、同義語の処理、制約も含まれます。これにより、クロスドメインの統合が安全かつ明示的になります。(これは、OWL/RDF、キュレーションされた結合グラフ、または管理されたデータプロダクトへの概念のバインディングになる場合があります)
業務手順:作業の進め方を指定する、バージョン管理された運用プレイブックです。これには、ルーティング、承認、例外処理、ポリシーの適用が含まれます。
根拠とプロビナンス:回答の背後にあるトレース情報です。使用されたソース、適用された変換、データソースのリネージが含まれます。また、競合するソースが採用または拒否された理由も含まれます。
ポリシーとエンタイトルメント:ユーザー(またはその代理として動くエージェント)が、何を取得、計算、開示できるかを定める、機械的に強制適用できるルールです。
セマンティックモデルとオントロジーは新しいものではありません。企業は何十年にもわたり、一貫した意味を追求してきました。その手段として、BIセマンティックレイヤー、マスターデータ管理(MDM)、カタログ、ナレッジグラフを活用してきました。オントロジーは、ライフサイエンスやヘルスケアなどの領域でも成熟しています。これらの分野では、複雑な生物医学の概念と標準化された臨床用語が、自然にグラフ状の世界を形成しています。また、セマンティックレイヤーとオントロジーへの関心が急増していることも明らかです(図 1を参照)。
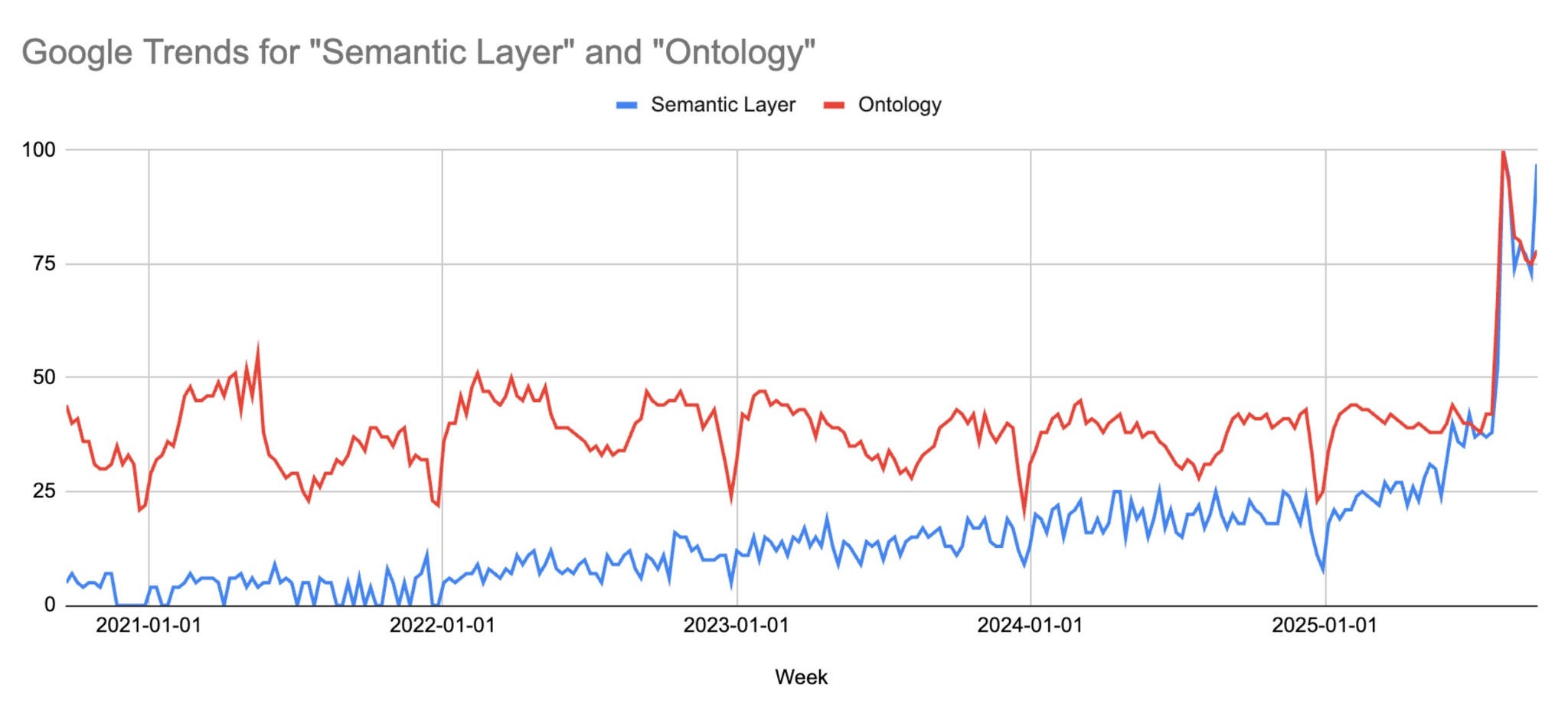
このタイミングは理にかなっています。なぜなら、これらはいくつかの特定の側面でLLM搭載エージェントを補完するからです。たとえば、以下のとおりです。
LLMは意図を解釈し、曖昧な状況でも推論することができます。しかし、通常はエンタープライズのコンテキストが欠落しています。セマンティックモデルとオントロジーは、そのコンテキストを再利用可能な形式でエンコードします。
LLMの出力は確率的です。一方、セマンティックアーティファクトは根拠があり、検証可能です。
歴史的に、セマンティックアーティファクトの構築にはコストがかかり、時間とともにずれが生じやすいという課題がありました。しかし、自然言語インターフェイスとエージェントツールにより、その生成、キュレーション、最新状態の維持が容易になっています。
同時に、「オントロジー」は最終目標ではありません。目標は、高品質なデータエージェントです。自然言語が実用的な入り口になることで、システムが提供すべきものが変化します。もはや、質問をSQLに変換するだけでは不十分です。エージェントには、セマンティクス、ID、制約、ポリシー、プロビナンスにまたがるコンテキストレイヤーが必要です。
これが転換点です。
モデルにより、「テキストからデータへ」の変換が現実的になりました。
エージェントのコンテキストにより、エージェント型アナリティクスの信頼性が高まります。
セマンティックアナリティクスモデルは、メトリクスと定義を標準化します。これにより、ドメイン内で信頼性の高いアナリティクスを提供するのに最適です。エージェントが明示的な関係空間、ID解決、結合可能性、制約を持つことで、クロスドメインの作業が信頼できるものになります。これらは、正式なオントロジー、キュレーションされた結合グラフ、または概念からアナリティクスオブジェクトへのバインディングとして実装されます。
実用的な焦点は、役立つ場面でオントロジーやセマンティックレイヤーを活用することです。ただし、企業の現実においてエージェントが適切に機能するために、実際に必要なものに最適化する必要があります。
信頼性の高いマルチステップのエージェント型アナリティクスに移行するには、ガバナンスの効いたセマンティクス、明示的な関係、監査可能な意思決定に根ざした推論が必要です。エンタープライズレベルのエージェントには、これらのレイヤーを組み合わせて連携させる必要があります。
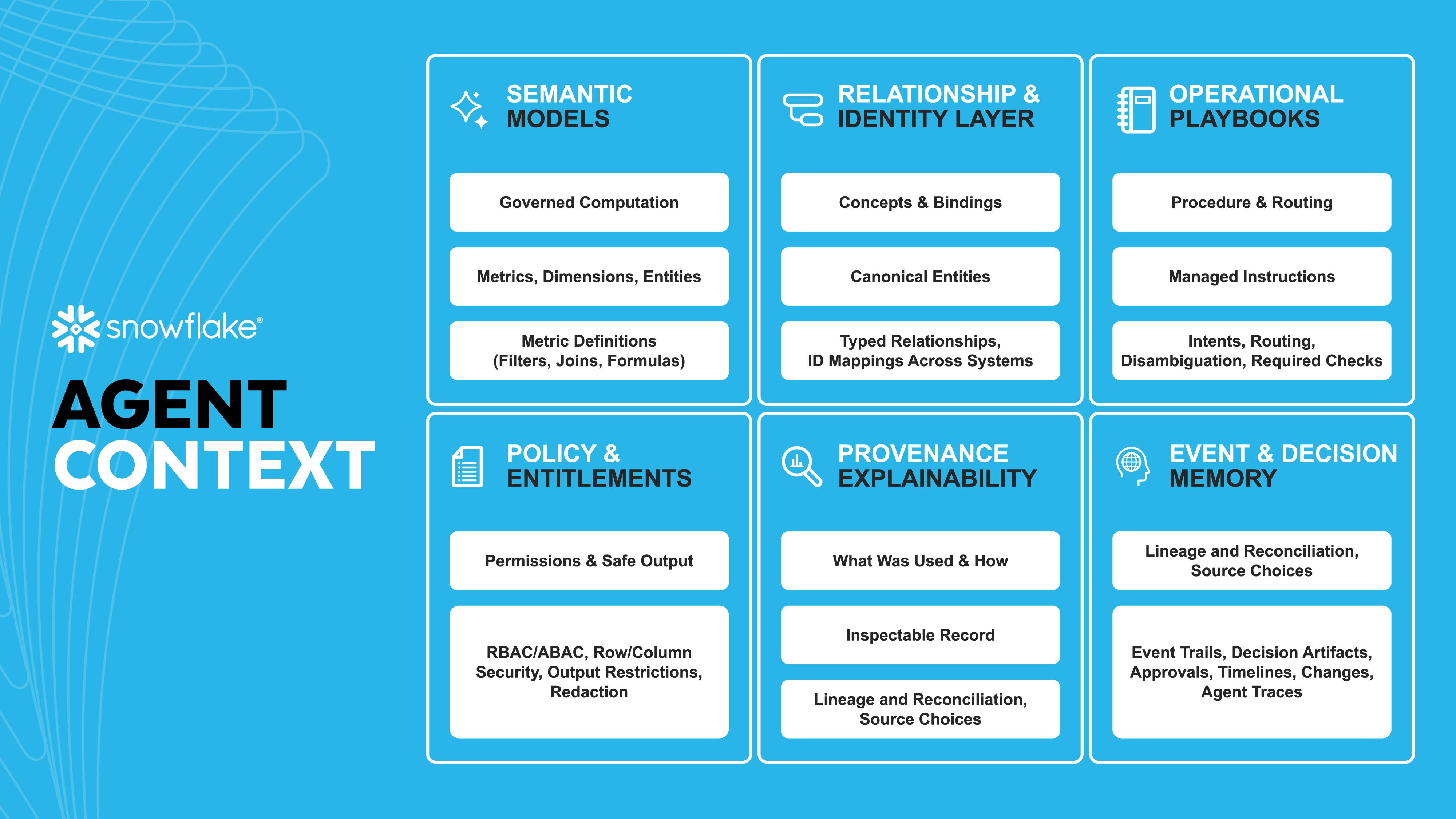
アナリティクスレイヤーは、物理データにマッピングされたメトリクス、ディメンション、エンティティを提供します。メトリクスの定義(フィルター、結合、数式)は1か所に保存されます。これらはエージェントのエクスペリエンス全体で再利用されます。セマンティックビューは、アナリティクスレイヤーに対するキュレーションおよびガバナンスされたインターフェイスとして機能します。これにより、安全なアナリティクスも確保されます。
「収益」や「NRR」などの自然言語による質問は、特定のメトリクス定義にマッピングされる必要があります。これには、適切なフィルター(例:「商談成立のみ」)、デフォルトの時間枠、許可された粒度が含まれます。
Question:
“What is NRR for the last two quarters, split by Enterprise vs Commercial?”
Semantic view usage:
- Metric: NRR (definition includes cohort and renewal logic)
- Dimensions: Quarter, Segment
- Default filters: exclude internal/test accounts
- Time logic: last 2 fiscal quarters
Result:
- NRR by quarter and segment
- Metric definition reference (NRR vX)
- Query parameters used (time window, segment mapping)
このレイヤーは、正規のエンティティ(顧客、アカウント、インシデントなど)と、それらの間の型付きの関係を定義します。さらに、データ世界へのバインディング(ID、セマンティックオブジェクト、テーブル)も定義します。これには、システム間のシノニムやエイリアスの処理、およびIDマッピングも含まれます。クロスドメインの質問では多くの場合、異なる識別子を持つシステム間で、現実世界の同じエンティティをリンクする必要があります(例:CRMのアカウントIDとサポート組織のIDなど)。このレイヤーは、そのマッピングを提供します。また、ドメインを接続するために必要な関係構造も提供します。
社内実験において、回答に複数のセマンティックビューを必要とするクエリセットを作成しました。最終的な回答の精度、合計レイテンシー、ツールの呼び出し回数によってパフォーマンスを測定しました。エージェントにプレーンテキストの「データオントロジー」(結合キー、テーブルの粒度、カーディナリティやファンアウトのヒント)を追加するだけで、ベストプラクティスのベースラインと比較してパフォーマンスが向上することがわかりました。具体的には、最終的な回答の精度が20%向上し、平均ツール呼び出し回数が約39%減少し、エンドツーエンドのレイテンシーが約20%改善しました。
クエリセットは以下のとおりです。
Question:
“Show open escalations for accounts in my book of business and the ARR at risk for each.”
Relationship/identity usage:
- Canonical entity: Customer
- CRM mapping: Customer ↔ CRM.AccountId
- Support mapping: Customer ↔ Support.OrgId
- Relationships:
Customer HAS SupportCases
Customer HAS Contracts (with ARR)
Plan:
1) Find accounts in territory (CRM)
2) Map CRM.AccountId → Customer
3) Map Customer → Support.OrgId → open escalations
4) Map Customer → Contract/ARR (finance semantic object)
5) Join results at Customer grain
これは、エージェントが特定のインテントを処理する方法を記述したマネージドな命令セットです。これには、信頼できるソースへのルーティング、必要な曖昧さ回避の手順、必要なチェック(例:「価格設定は認定テーブルを使用すること」、「勝率は使用禁止」など)が含まれます。
一部の質問には、一貫したプロシージャによる処理が必要です。プレイブックは、ユーザーやチャネル(エージェント、BIアシスタント、組み込みアプリ)全体で標準的なアプローチを提供します:
Question:
“What is the price for Product X for a customer in EMEA?”
Playbook: Pricing Inquiry
Steps:
1) Confirm context: customer segment, contract type, effective date
2) Route to authoritative pricing semantic object (certified)
3) Apply region/currency rules for EMEA
4) Return price + effective date + source usedこのレイヤーは、回答がどのように生成されたかを示す検査可能な記録を提供します。これには、選択されたセマンティックオブジェクト、適用されたフィルター、実行された結合、確立されたタイムスタンプや鮮度が含まれます。競合が発生した場合は、どのソースが選択されたか、および使用されたルールを含めることができます。
ユーザーは多くの場合、「それはどのように計算したのか」や「別のレポートと異なるのはなぜか」といった追加の質問をします。プロビナンスは、これらの質問に答えるための一貫した基盤を提供します。
Question:
“What is churn for Q4, and why does it differ from last week’s report?”
Provenance returned:
- Metric: Churn_Rate (definition v2.4)
- Filters: excludes involuntary churn
- Time window: FYQ4 (fiscal calendar)
- Sources: billing_events (as-of timestamp), customer_status snapshot
- Differences vs last week:
definition changed v2.3 → v2.4
backfill applied to billing_eventsこのレイヤーは、ビジネスエンティティにリンクされたイベントの証跡と意思決定のアーティファクトを保存します。これには、承認、インシデントのタイムライン、変更イベント、関連するチケットやスレッドが含まれます。このメモリは、アナリティクス(正しい結合方法など)、ビジネス概念(メトリクス計算の変更など)、照合(競合がある場合にどの情報を信頼すべきか)などの形式で組み込むことができます。これにより、「なぜ」という質問に対する証拠が提供されます。多くのワークフローでは、現在の状態だけでなく、運用履歴に基づいた説明が求められます。
Question:
“Why was a 20% discount approved for Acme, and who approved it?”
Evidence retrieved:
- approval workflow record (request, approvers, timestamps)
- approver notes / justification field
- linked deal desk ticket
- relevant policy threshold reference (if applicable)
Answer includes:
- approvers + timestamps
- stated justification
- links/IDs to supporting artifacts巧妙なプロンプトがエージェントロジーに取って代わることができると考えがちです。実際には、プロンプトのみに依存するシステムは規模が拡大すると破綻します。これらのシステムは不透明で監査が困難なうえ、時間の経過とともに挙動がずれていきます。
エージェントロジーのアプローチにより、耐久性がありガバナンスの効いたアーティファクトが得られます。
レビュー可能でバージョン管理されたロールアウトを伴う変更管理
説明可能なルーティングの決定、結合、および定義を伴う監査可能性
BIツールとエージェントを支える単一のセマンティック基盤による相互運用性
ルールがベストエフォートの指示ではなく、強制力のある制約となるガバナンス
概念を一度モデル化すれば、重複することなくさまざまなコンテキストで再利用できる再利用性
Cortex Codeのような強力なエージェントの台頭により、エージェントコンテキストを構築および作成するタスクがより実現可能になりました。ほとんどのビジネスセマンティックレイヤーが困難であった理由は単純です。構築にコストがかかります。また、すぐに陳腐化します。さらに、ビジネスのスピードに合わせて進化しません。しかし、AIエージェントを使用すると、ワークフローをはるかにシンプルにすることができます。エージェントはドキュメント、ナレッジグラフ、オントロジー、チャット、その他の記録システムを読み取ります。これにより、コンテキストを作成し、最新の状態に保つことができます。
非常にシンプルなAIエージェントのワークフローは次のようになります。
エージェントとキュレーションされたセマンティックレイヤーから始めます。これには既存のダッシュボードとクエリ履歴を活用します。
既存のソースからエージェントコンテキストのレイヤーを追加します。これには、既存のテーブルのメタデータ、過去のクエリと使用パターン、ドキュメント、プレイブック、既存のオントロジー、コードパイプラインが含まれます。これにより、すでに非常に強力なエージェントが作成されるはずです。
実際の使用パターンから学習します。
シノニム、マッピング、欠落している関係などの改善を提案します。
承認ループに人間を組み込み続けます。
カバレッジを拡大しながら、継続的にコストを削減します。
今後、この分野は次のように進化すると予想されます。
モデルがコモディティ化するにつれて、優れたアーキテクチャはモデルではなく「エージェントコンテキスト」をコアプロダクトとして扱うようになります。
最も成功するエージェントは、オントロジーのような単一のアーティファクトのインデックス作成ではなく、解決すべきビジネス上の問題に焦点を当てます。
セマンティックモデルは引き続き、ガバナンスの効いたメトリクスと信頼できるドメインアナリティクスの基盤となります。エージェントがこのコンテキストの主要なコンシューマーになるにつれて、これらのレイヤーを最新かつ整合性のとれた機械可読な状態に保つ必要性が高まります。これにより、レイヤーは静的なドキュメントのアーティファクトから、生きた形で継続的に管理される資産へと変化します。
Cortex CodeのようなAIエージェントを活用した、エージェントコンテキストレイヤーの生成と継続的な進化への投資が増加するでしょう。
導入が拡大するにつれて、クロスプラットフォームの相互運用性を促進する標準が登場すると予想されます。これにより、LLMがツールやエコシステム全体で一貫してこれらのコンテキストレイヤーを解釈し、運用しやすくなります。Open Semantic Interchange(OSI)のような取り組みは、この種の相互運用性を可能にすることを目的としています。
全体として、メタデータとカタログのイニシアチブに対する関心が再び高まると考えています。これらのレイヤーは、人間とエージェントによって共同で維持されることが増えるでしょう。
複雑なコンテキストとクロスドメインのオーケストレーションを必要とするエージェントを構築しているデータエグゼクティブの方は、当社の最新の開発成果をぜひご覧ください。
次世代の表現力豊かなセマンティックレイヤーとSnowflake Intelligenceに共同で取り組んでいただける戦略的デザインパートナーを募集しています。弊社と共同でCortex Agentsの構築とイテレーションを行うことに関心をお持ちの場合は、簡単なフォームに記入して、お客様のユースケースがプログラムに適しているかどうかをご確認ください。


