FEB 03, 2026|約8分で読めます
MLスタックのモダナイゼーション:エージェント型、マルチモーダル、リアルタイムのワークフローを発表

従来型の機械学習(ML)は、サプライチェーンの最適化からリアルタイムの不正検知まで、中核的なビジネス価値を促進する予測インサイトのバックボーンとして機能し、今日のAIランドスケープにおいて引き続き不可欠です。しかし、実験から実稼働に至るまでの道のりは依然として困難です。エコシステム全体でツールが断片化しており、複雑なセットアップ、最適化のための複数回の反復、継続的なメンテナンスが必要です。Snowflakeは、ビジネスニーズに合わせて拡張できる統合されたセキュリティと加速されたワークフローを実現するために、お客様のデータと緊密に統合されたモダンMLプラットフォームを提供することにコミットしています。
このたび、Snowflake MLのモデルワークフローで以下の機能を利用できるようになりました。
Snowflake Notebook(一般提供中)のJupyterベースの環境から、Cortex Code in Snowsight(近日中に一般提供中)を使用して、シンプルな自然言語プロンプトを使用してフル機能のMLパイプラインの開発を自動化
ネイティブに統合された実験追跡(一般提供中)を利用して、トレーニング実行全体にわたってトップ成果を簡単に特定、共有、再現することで、最適なパフォーマンスのモデルを効率的に展開
オンラインSnowflake特徴量ストア(一般提供中)とオンラインML推論(一般提供中)でミリ秒単位の低レイテンシー予測を実現し、パーソナライズされたレコメンデーションや不正検知などのリアルタイムユースケースを強化
マルチモーダルモデルの推論ワークロードの実行(パブリックプレビュー)により、画像や音声などの非構造化データによる大規模推論が可能
エージェント型モデル開発
Snowflakeでは、開発者の生産性を向上させるモダン開発体験に継続的に投資しています。本日、Snowflake Notebookの新しい統合開発環境(IDE)エクスペリエンスと統合されるエージェント型ML機能の発売により、実稼働MLの概念を刷新します。
MLパイプラインのためのCortex Code
データサイエンティストは、MLワークフローの開発とトラブルシューティングに長いサイクルを費やしているため、運用上のボトルネックが発生し、実稼働に移行するMLモデルが減少します。Snowflakeは現在、Snowflake NotebookのMLワークフローのために、Cortex Code in Snowsight(近日中に一般提供)からMLワークフローにエージェント型AIを導入し、シンプルな自然言語プロンプトから自律的に反復、調整、完全に実行可能なMLパイプラインを生成しています。
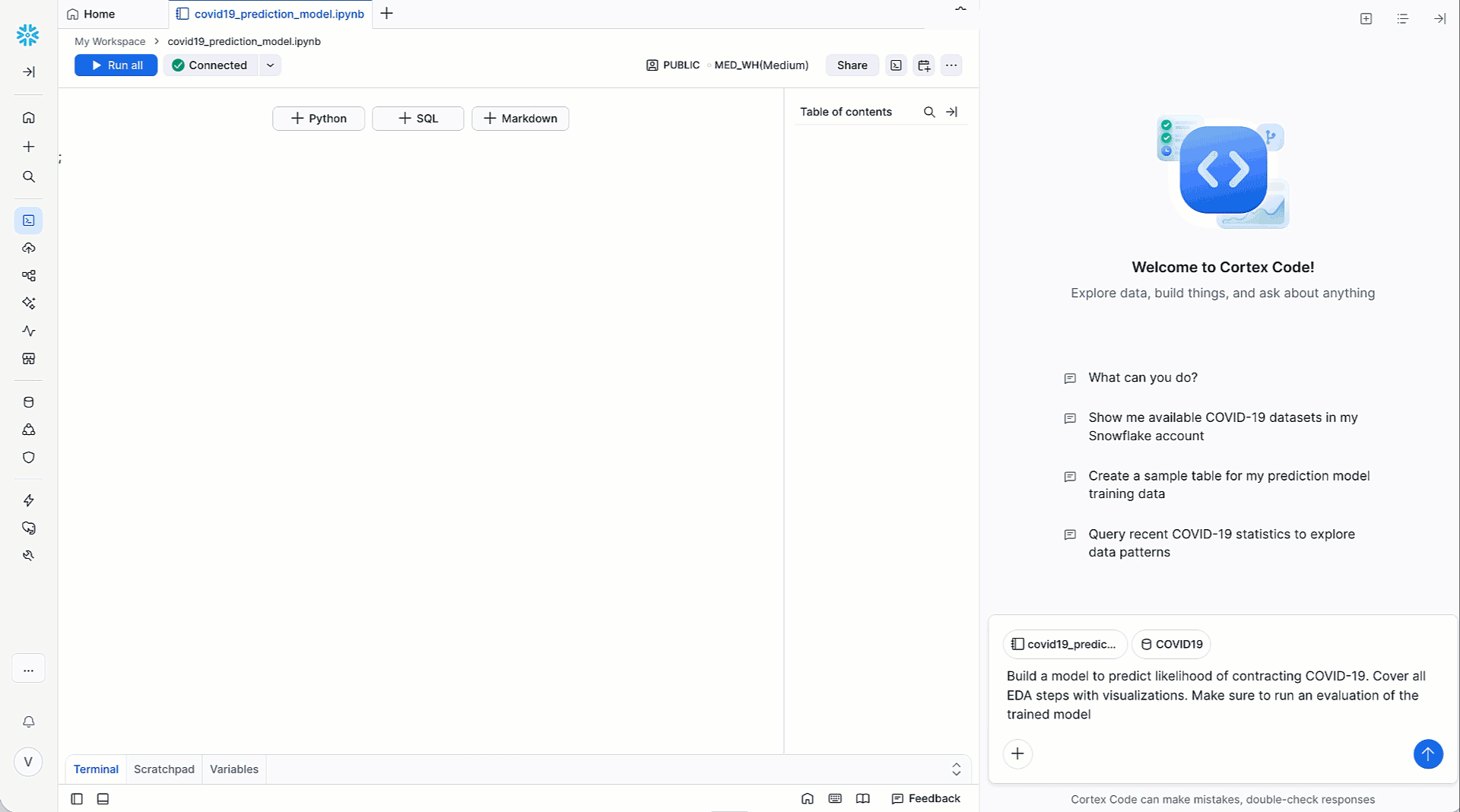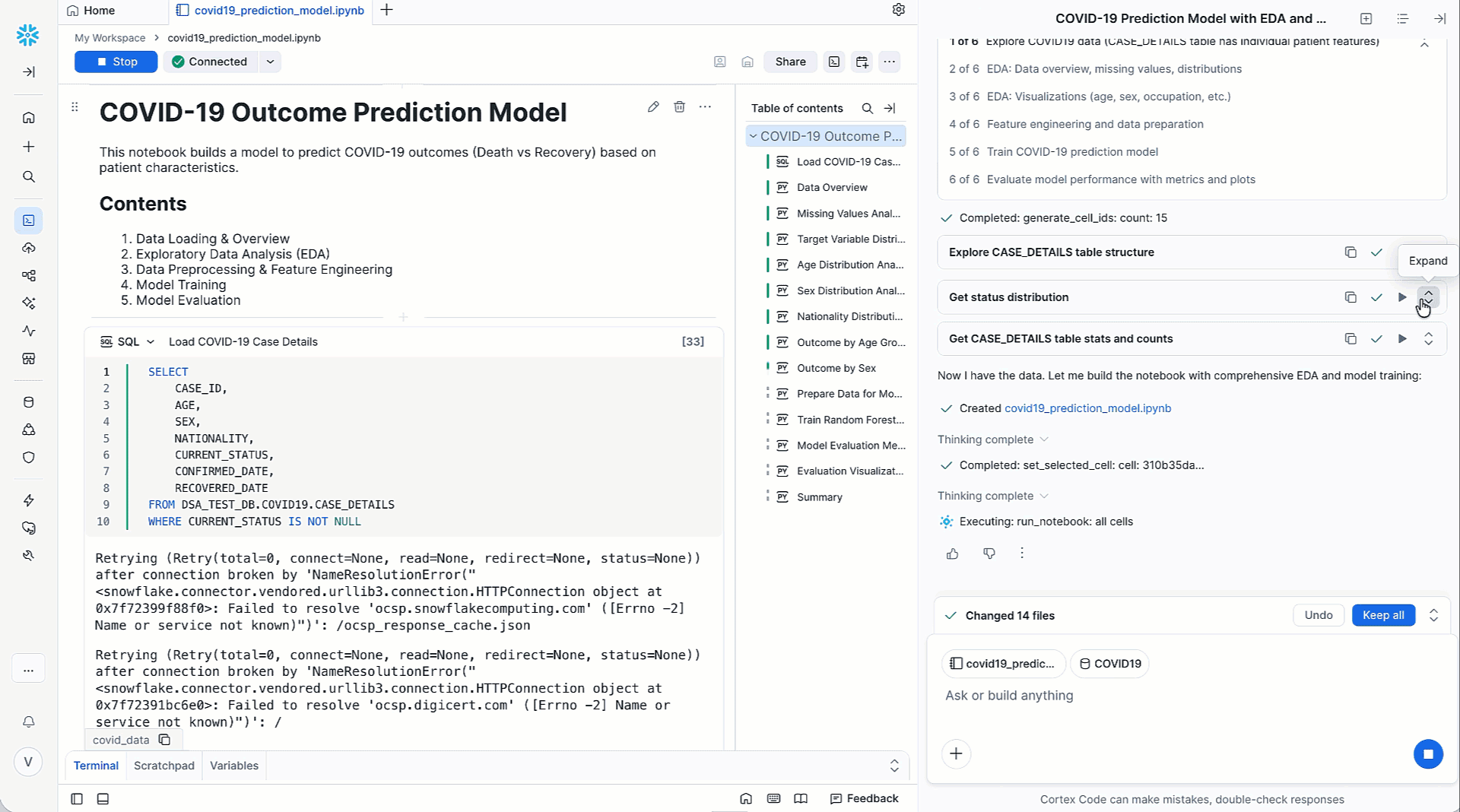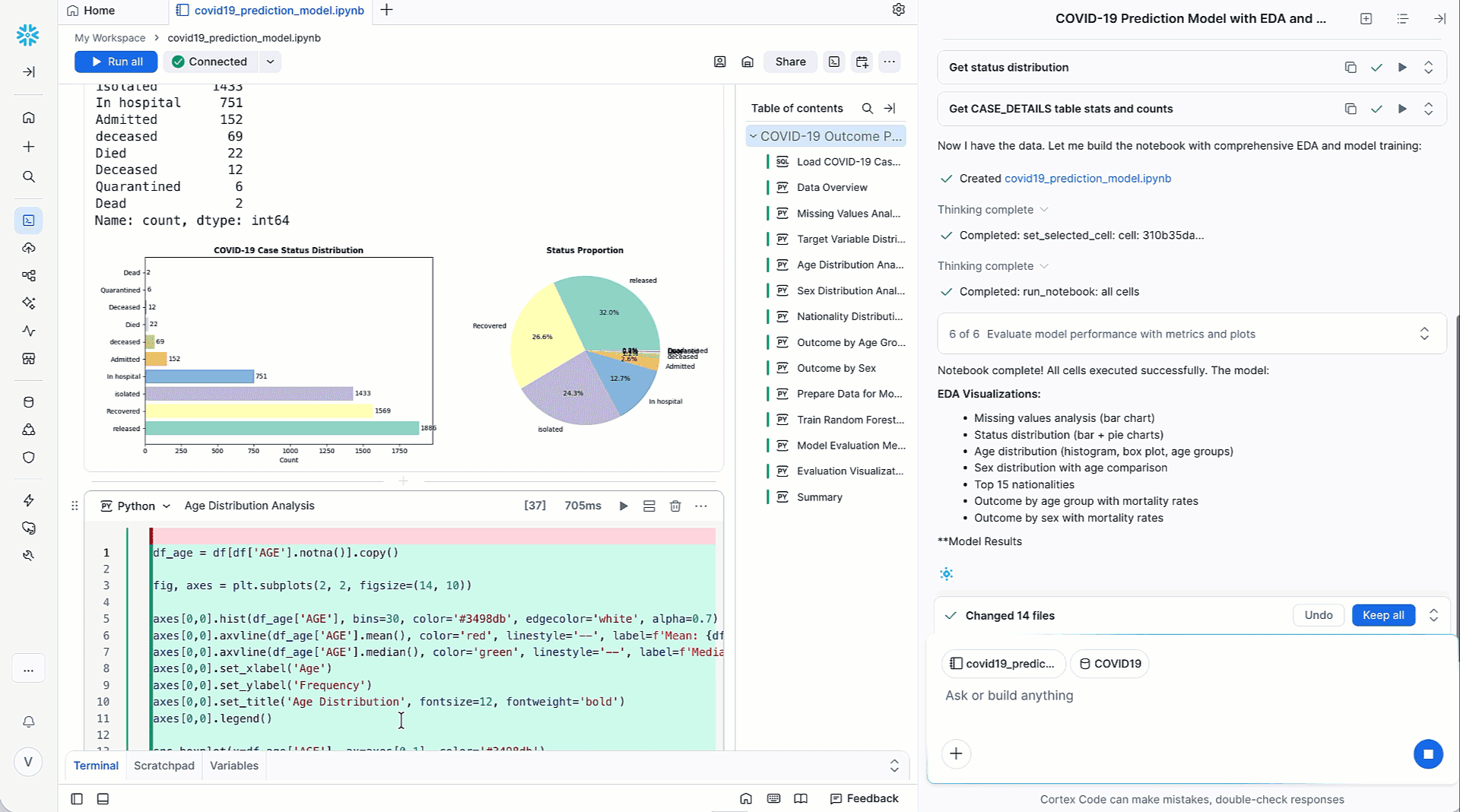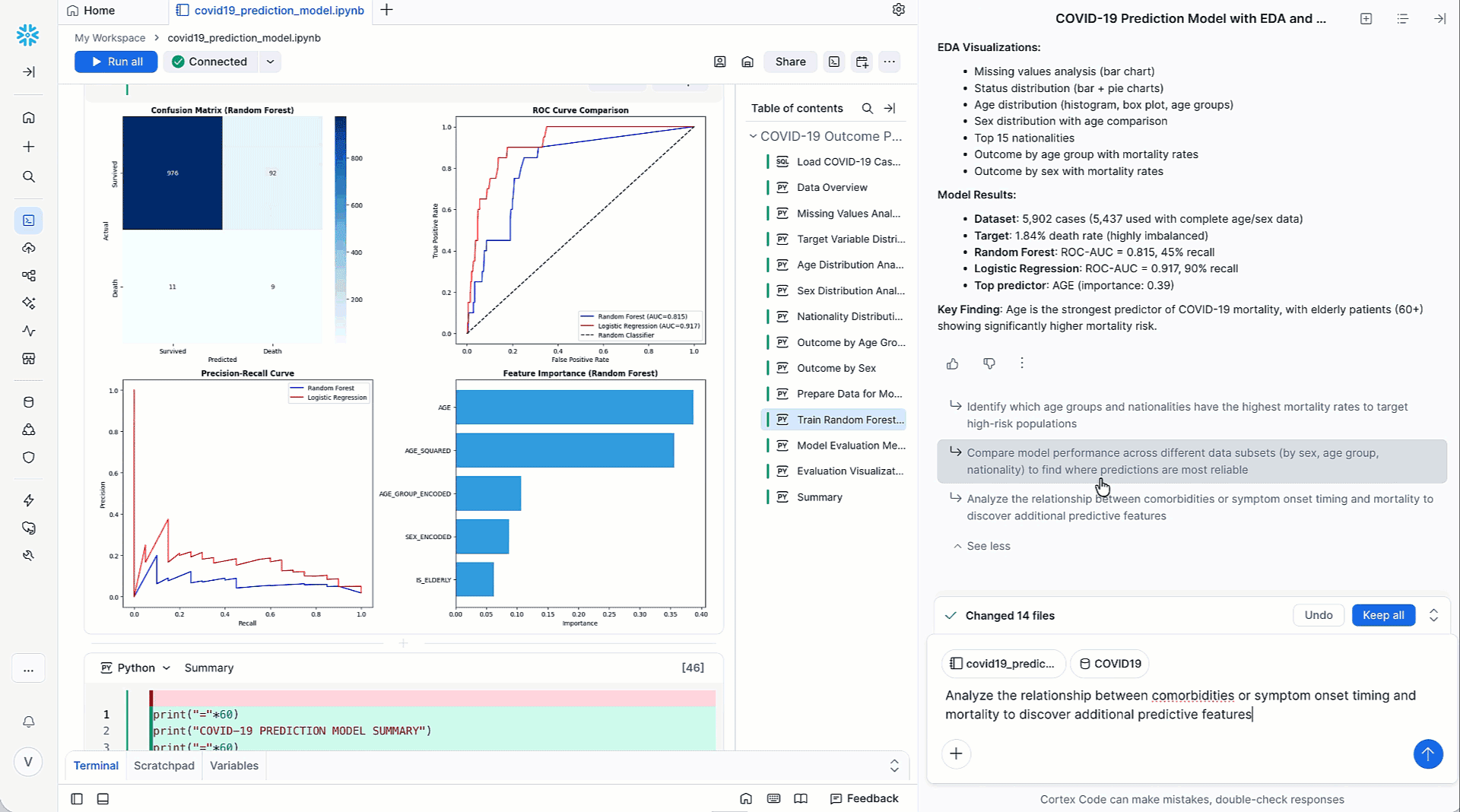
Cortex Codeは、MLワークフローに関連する問題を、データ分析、データ準備、特徴量エンジニアリング、トレーニングなどの個別のステップに分割します。Cortex Codeは、多段階の推論、コンテキスト理解、アクション実行などの高度な技術を組み合わせ、Snowflake Notebookから簡単に実行できるフル機能のMLパイプラインの形で検証済みのソリューションを提供します。Cortex Codeは、改善案の提示やユーザーによるフォローアップを通じて、ユーザーが次の最適なバージョンに簡単にイテレーションできるようにします。データサイエンスチームは、この面倒な作業を自動化することで、通常は実験やデバッグに費やす時間を節約し、より影響力のあるイニシアチブに集中できます。
Snowflake Notebook
Cortex Codeは、Snowflake Notebookから直接、実稼働ワークフローの構築と反復に活用できます。Snowflake Notebookの次世代開発がワークスペースで一般提供されました。これらのJupyterベースのノートブックでは、既存のノートブック、スクリプト、モデルトレーニングをSnowflakeの統合プラットフォームに持ち込むことができます。また、ワークスペース内で、任意のライブラリ、Jupyterランタイム機能、使い慣れたIDE属性、ファイルベースの編成を維持できます。
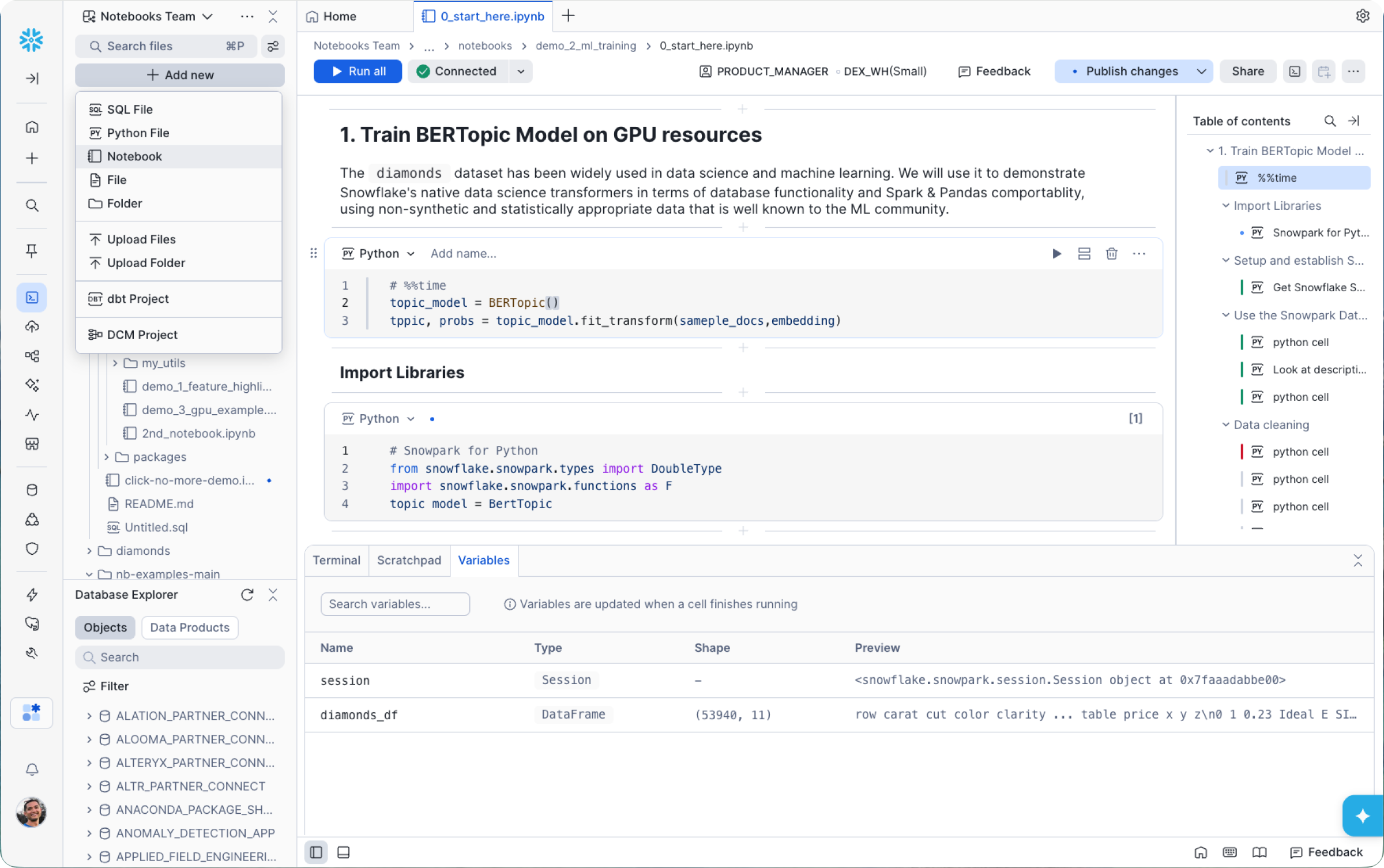
この新しい開発体験では、以下の機能が拡張されています。
マネージドJupyter/IPythonカーネル:Notebookは現在、SnowflakeマネージドのJupyter/IPythonカーネル上で実行されており、マジックや既存のノートブックとの互換性が確保されています。これには、SQL、Python、Markdownのコードの実行、セル間でのデータ転送の容易化が含まれます。各セルの下にある結果エクスプローラーで、テーブルと可視化ビルダーを使用して結果を確認できます。
ワークスペースネイティブ組織:Notebookは、SQLファイル、dbtプロジェクト、Pythonユーティリティ、Snowflakeでの開発に使用するその他のアセットとともにワークスペースで直接作成できるようになりました。これにより、すべてを1か所に集約し、マルチファイルのワークフローを自然に行えるようになります。必要に応じて、ロジックをヘルパーにリファクタリングし、フローを小さなコンポーネントに分割してつなぎ合わせることができます。また、新しいターミナルと変数エクスプローラーにより、より迅速で生産的な開発ループが実現します。
Gitに裏付けられたシームレスなコラボレーション:Gitに裏付けられたワークスペースにより、Snowflakeと直接の分岐、コミット、差分など、リポジトリ全体にわたってシームレスに作業できるようになりました。また、Gitが好みのワークフローでない場合は、共有ワークスペースが代替案として、組み込みのバージョン管理と変更追跡機能を備えた、ロールベースのアクセス制御された一連のファイルに対するコラボレーションを提供します。
Snowflakeコンテナランタイム(CPUおよびGPU):Snowflakeの新しいエクスペリエンスは、Snowflakeコンテナランタイム上でのみ実行されます。Snowflakeコンテナランタイムは、Snowparkコンテナサービス上で直接実行される、データサイエンスと機械学習のための事前構築された環境です。これにより、人気の高いMLフレームワークと複数のPythonバージョンが提供され、コンピュートリソースを分散することでトレーニングとデータロードが高速化します。プロトタイプ作成に使用するランタイムバージョンは、スケジュール設定や実稼働に使用するランタイムバージョンと同じであり、よくある「ノートパソコンではうまくいきましたが ... 」 という問題点が解消されています。
データとAIのコンサルティングのリーダー企業であるAIMpoint Digitalなどのグローバル企業は、実稼働可能な開発ワークフローを推進するためにSnowflake Notebookを使用しています。
「Snowflake ノートブックの一般提供(GA)は、開発者体験において革命的な瞬間と言えます。私たちは、ダイナミックプライシングからグラフベースのユーザー行動予測に至るまで、クライアント向けのML(機械学習)ワークロードの開発と本番環境への導入(プロダクション化)を容易に行うことができました。Workspaces(ワークスペース)でのノートブック開発により、共通コードを中央集約化しつつ、その上で各開発者が個別に構築するものを分散化することが可能になります。Python から SQL セルを参照したり、その逆を行ったりできること、そしてノートブックをパラメータ化できることは、まさにパラダイムシフトです。ストアドプロシージャのスケジューリングに追われる日々は過去のものとなりました。ノートブックは、ML、AI、あるいはエンジニアリングのいずれにおいても、ダイナミックなワークフローに究極の柔軟性をもたらします。」
Christopher Marland
Snowflake Practice Lead, Aimpoint Digital
Snowflake Notebookを始めるには、このトピックモデリングクイックスタートをお試しください。
実験追跡
Snowflake NotebookとCortex Codeを使用して構築とイテレーションを行った後は、ネイティブに統合されている実験追跡(現在一般提供中)を使用して、未加工の仮説から高パフォーマンスのモデルに迅速に移行できます。これにより、MLチームは、トレーニング実行全体にわたって最も優れたパフォーマンスのモデルの特定、共有、再現を体系的に行えるようになります。これにより、コラボレーションが簡素化され、再現性が向上し、企業全体にわたってモデルの反復が加速します。Snowflakeの実験追跡の最新リリースでは、大規模なトレーニング実行時に生成された数百万のメトリクスを、モデルパラメータ、アーティファクト、メタデータとともにシームレスに記録できます。
多くの企業が実験追跡を使用して、モデルトレーニングの重要な情報の保存、追跡、比較を行っています。この中には、公益事業とその顧客がクリーンで分散型のエネルギーの未来を創るために活用しているEnergyHubも含まれます。
「Snowflake Experiment Trackerを早期に導入した企業として、このツールが当社のニーズを十分に満たしつつ、別のMLFlowサーバーを保守・管理する手間を解消してくれることを実感しています。既存のSnowflakeプラットフォーム上でML(機械学習)実験のトラッキングを一元化できたことは、運用面において大きな成果(大きな勝利)です。加えて、Snowflakeはフィードバックに対して非常に迅速かつ柔軟に対応してくれており、驚くべきスピードで機能強化を進めています。」
Dr. Wiliam Franklin
Principal Machine Learning Scientist, EnergyHub
リアルタイム配信
Snowflakeやその他の外部プラットフォームでモデルをトレーニングしたら、Snowflakeデータで推論するために簡単に展開して予測結果を生成できます。Snowflakeは、実稼働可能な新しいオンラインML機能を一般提供中で導入し、パーソナライズされたレコメンデーションや不正検知などのリアルタイムのユースケースを公開しています。追加のインフラストラクチャや複雑な設定は不要です。開発者は、バッチとオンラインのMLのユースケースをシングルプラットフォームに統合することで、機密データを外部プラットフォームにエクスポートする際のレイテンシー、コスト、セキュリティのリスクを排除できるようになりました。
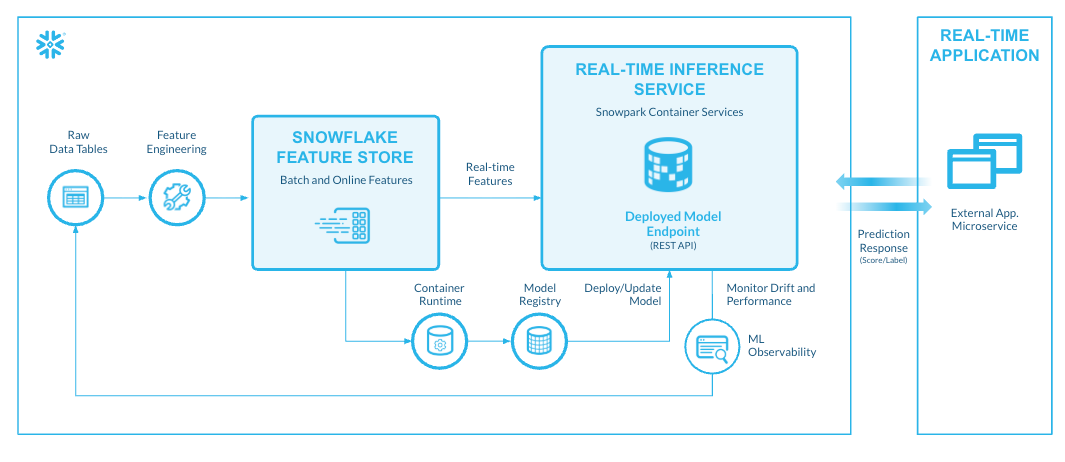
Snowflake特徴量ストア
Snowflake特徴量ストアからのオンライン特徴量提供の一般提供を開始しました。Snowflake特徴量ストアは、データサイエンティストとMLエンジニアがモデルのトレーニングと推論のためのML特徴量を作成、保存、管理、提供するための統合ソリューションです。Snowpark MLライブラリからアクセスできるPython API、特徴量の定義、管理、取得のためのSQLインターフェイス、特徴量のメタデータ管理と継続的な特徴量処理のためのマネージドインフラストラクチャで構成されています。Snowflake特徴量ストアは、オンライン特徴量提供機能を備え、バッチと低レイテンシーのオンラインユースケースのための統合ソリューションとして機能し、30ミリ秒で特徴量を提供します。
Snowflake特徴量ストアは、Snowflakeのデータ、特徴量、モデルにシームレスに統合されているため、大規模MLパイプラインを簡単かつ効率的に生産できます。これにより、特徴量パイプラインの冗長性と重複が解消され、エンタープライズグレードのセキュリティとガバナンスのケイパビリティを備えた、一貫性のある最新の正確な機能を利用できます。特徴量ストアサービスのためのSnowsightの一元的なUIにより、特徴量やモデルの検索と発見、リネージを通じたデータフローの可視化が容易になります。
Snowflake特徴量ストアのオンライン特徴量提供を今すぐ始めるには、このクイックスタートをお試しください。
オンラインML推論
オンラインML推論も一般提供が開始され、100ミリ秒未満でSnowflakeモデルレジストリからモデルをリアルタイム推論できるようになりました。
実稼働ワークロードの厳しい要求に対応するために、オンラインML推論はインテリジェントな自動スケーリング、低レイテンシーのパフォーマンス、包括的な可観測性を統合されたワークフローに統合します。これは、コスト効率の高いパフォーマンスから始まります。当社のオートスケーリングロジックは、膨大なトラフィックの急増を瞬時に処理し、需要が低下するとゼロにスケーリングします。これにより、オーバープロビジョニングされたGPUの高額なオーバーヘッドが解消されます。重要なこととして、トラフィックランプが復旧すると、システムは即時に応答するように設計されており、モデルは迅速にスケールアップして100ミリ秒未満のパフォーマンスを維持できます。
展開のレジリエンシーも同様に高く、ユーザーは自動ローリングアップデートによって新しいバージョンに移行できます。これにより、アプリケーションのトラフィックが落ちることはありません。また、容易なバージョンロールバックによる安全性も確保されています。また、フルカットオーバーにコミットする前に、製品バージョンから切り離された並列環境でパフォーマンスを監視することで、シャドウモードを活用して新しいモデルを安全に検証することもできます。また、Snowflakeは、統合された可観測性によってレイテンシー、スループット、エラーレートをすぐに可視化して、すべてのリクエストと応答をSnowflakeテーブルに直接記録して詳細なデバッグと長期監査を可能にします。
マルチモーダルモデルの推論
さらに、Hugging Faceなどのハブによるオープンソースのマルチモーダルモデルに対するSnowflakeの推論サポートにより、大規模なオンライン推論やバッチ推論を簡単に実行できるようになりました。非構造化データの推論サポートは現在パブリックプレビュー中で、画像、動画、音声などのデータタイプに対応しています。この機能により、複雑なパイプラインやデータ移動なしに、Snowflake上でオブジェクト検知、視覚的なQ&A、自動音声認識などのAIユースケースを活用できるようになります。
Snowflakeは、リアルタイム処理とバッチ処理の両方のニーズに対応しています。ユーザーは、REST APIを介してマルチモーダルモデルをサービスとして展開してオンライン推論を実行したり、Snowflakeモデルレジストリに記録してすぐにバッチ呼び出ししたりできます。Snowflakeの分散コンピュートレイヤーを利用することで、チームは使い慣れた環境から離れることなく、大規模なデータセットに対して大規模な推論タスクを実行できます。
さっそく始める
Snowflake MLは、エージェント機能、オンライン機能、マルチモーダル機能における最新のイノベーションにより、ガバナンスが確保されたデータと同じプラットフォーム上で、機械学習のプロトタイプから実稼働までのプロセスを加速します。
製品ドキュメントをご覧になり、30日間の無料トライアルからこの入門クイックスタートでSnowflake MLを今すぐお試しください。
著者



あなたにおすすめ

FEB 03, 2026|約1分で読めます

FEB 03, 2026|約1分で読めます