Neue Innovationen für Data Warehouse, Data Lake und Data Lakehouse in der Data Cloud


Im Technologie-Umfeld des Datenmanagements haben sich über die Jahre verschiedene Architekturmuster herausgebildet, die jeweils sorgfältig auf bestimmte Anwendungsfälle und Anforderungen zugeschnitten sind. Zu diesen Mustern gehören sowohl zentralisierte Speichermuster wie Data Warehouse, Data Lake und Data Lakehouse als auch verteilte Muster wie Data Mesh. Diese Architekturen zeichnen sich jeweils durch eigene Stärken und Schwächen aus. In der Vergangenheit wurden Tools und kommerzielle Plattformen oft für ein bestimmtes Architekturmuster entwickelt. Für Organisationen war es daher schwierig, sich an veränderte Geschäftsanforderungen anzupassen. Das hatte natürlich auch Auswirkungen auf die Datenarchitektur.
Wir bei Snowflake vertreten nicht die Auffassung, dass die Vorgabe eines bestimmten Musters den Interessen aller Kunden entspricht. Stattdessen bieten wir unseren Kunden eine Plattform, auf der sie Architekturen entwickeln können, die auf dem basieren, was in ihrer Organisation funktioniert, auch wenn sich das im Laufe der Zeit ändert. Bei unseren Kunden hat sich das Gesetz von Conway sehr oft bewahrheitet. Alles kann sich ändern: die Anwendungsfälle, die Bedürfnisse und die Technologie. Daher sollte die Dateninfrastruktur skalierbar sein und sich mit den Änderungen weiterentwickeln. Wir möchten unseren Kunden eine große Auswahl und viele Anpassungsmöglichkeiten bieten, ohne dabei unsere Grundprinzipien wie Sicherheit und Governance, herausragende Performance und Einfachheit aus den Augen zu verlieren.
So haben beispielsweise Kunden, die einen zentralen Speicher für umfangreiche und vielfältige Daten benötigen (zum Beispiel JSON, Textdateien, Dokumente, Bilder und Videos), ihren Data Lake mit Snowflake entwickelt. Viele Kunden mit unternehmensweitem Daten-Repository, in dem die Tabellen stark für SQL optimiert sind, sowie hochgradig parallelen Business-Intelligence-Workloads und -Berichten haben ein Data Warehouse auf Snowflake entwickelt. Kunden, die eine Mischung aus beiden Varianten benötigen, um verschiedene Tools und Sprachen zu unterstützen, haben sich für ein Data Lakehouse entschieden. Da es vielen Kunden lieber ist, wenn die Teams ihre Daten selbst verwalten und sich beim Infrastrukturmanagement an Standards halten (anstatt sich auf ein zentrales Datenteam zu verlassen), nutzen sie Snowflake als Plattform für ihr Data Mesh.
Unsere neu angekündigten Funktionen sind Antworten auf die ständig wachsenden Anforderungen an das Datenmanagement, damit wir unsere Kunden in all diesen Fällen unterstützen können.
Apache Iceberg– die Lösung für ein OpenDataLakehouse
Die Data Lakehouse-Architektur kombiniert die Vorteile der Skalierbarkeit und Flexibilität von Data Lakes mit der Governance, der Durchsetzung von Schemata und den transaktionalen Eigenschaften von Data Warehouses. Von Anfang an wurde die Plattform von Snowflake als ein Service bereitgestellt, der aus optimiertem Speicher, elastischen Multi-Cluster-Rechenressourcen und Cloud-Diensten besteht. Unser Tabellenspeicher, den wir 2015 auf den Markt gebracht haben, ist ein vollständig verwaltetes, auf einem Objektspeicher implementiertes Tabellenformat. Es ähnelt den Open-Source-Lösungen wie Apache Iceberg, Apache Hudi und Delta Lake, die derzeit auf dem Markt sind. Da das Tabellenformat von Snowflake vollständig verwaltet ist, werden Funktionen wie Verschlüsselung, transaktionale Konsistenz, Versionsverwaltung und Time Travel automatisch bereitgestellt.
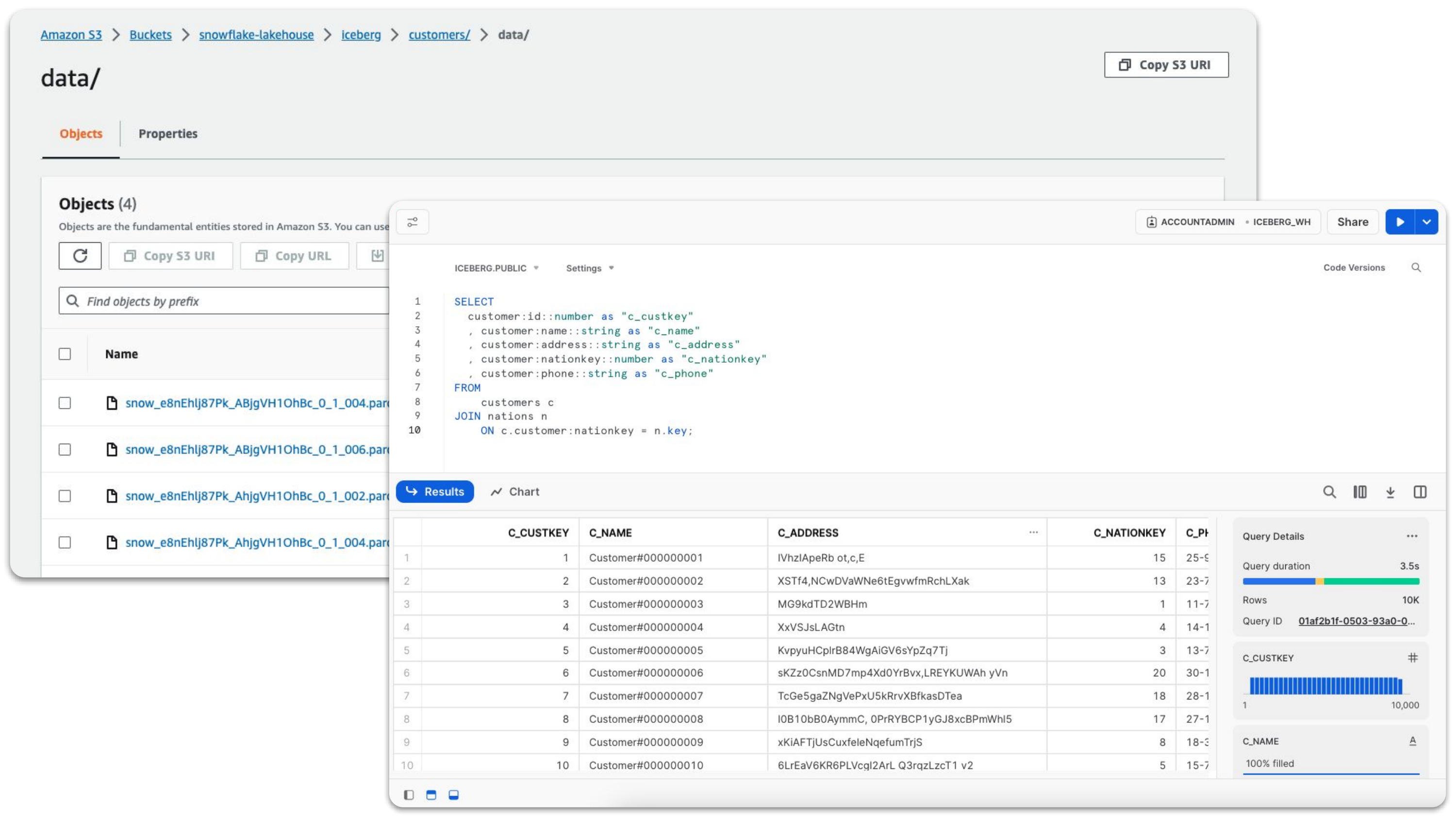
Während viele Kunden die Einfachheit eines vollständig verwalteten Speichers und einer zentralen, mehrsprachigen, multi-clusterfähigen Rechenressource für viele verschiedene Workloads schätzen, möchten manche lieber ihren eigenen Speicher über Open-Source-Formate verwalten. Deshalb unterstützen wir auch Apache Iceberg. Es gibt zwar noch andere Open-Source-Tabellenformate, aber wir betrachten Apache Iceberg aus vielen Gründen als führenden Open-Source-Standard für Tabellenformate und unterstützen daher vorrangig dieses Format, da es für unsere Kunden am wichtigsten ist.
Iceberg Tables (demnächst in Public Preview) ist ein Tabellenmodell, das die unkomplizierte Verwaltung und die Leistungsfähigkeit von Snowflake auch für extern gespeicherte Daten in einem Open-Source-Format ermöglicht. Iceberg Tables erleichtert außerdem das Onboarding und reduziert dabei die Kosten, weil keine Daten im Voraus erfasst werden müssen. Damit Kunden flexibel bleiben, wie sie Snowflake in ihre Architektur integrieren, können sie Iceberg Tables entweder mit Snowflake oder einem externen Dienst wie AWS Glue als Katalog für Tabellen konfigurieren, um Metadaten nachzuverfolgen. Die Konvertierung auf Snowflake erfolgt dabei mit einem einfachen einzeiligen SQL-Befehl für eine reine Metadatenoperation.
Unabhängig von der Katalogkonfiguration bleibt vieles bei allen Iceberg-Tabellen gleich:
- Die Daten werden extern in dem vom Kunden bereitgestellten Storage Bucket gespeichert.
- Die Abfrage-Performance von Snowflake ist im Durchschnitt mindestens doppelt so hoch wie die von External Tables.
- Viele weitere Funktionen wie Data Sharing, rollenbasierte Zugriffskontrollen, Time Travel, Snowpark, Object Tagging, Row Access Policies und Masking Policies sind ebenfalls möglich.
Weitere Vorteile ergeben sich, wenn Iceberg Tables mit Snowflake als Tabellenkatalog für die Verwaltung von Metadaten arbeiten:
- Durchführbarkeit von Schreiboperationen wie INSERT, MERGE, UPDATE und DELETE mit Snowflake
- Automatische Speicherwartungsoperationen wie Komprimierung, Ablauf von Snapshots und Löschen von verwaisten Dateien
- (optional) Automatisches Clustering zur Beschleunigung von Abfragen
- Apache Spark zum Lesen von Iceberg Tables mit dem Iceberg Catalog SDK von Snowflake, ganz ohne Rechenressourcen von Snowflake
Erweiterte Unterstützung für semistrukturierte und unstrukturierte Daten in DataLakes
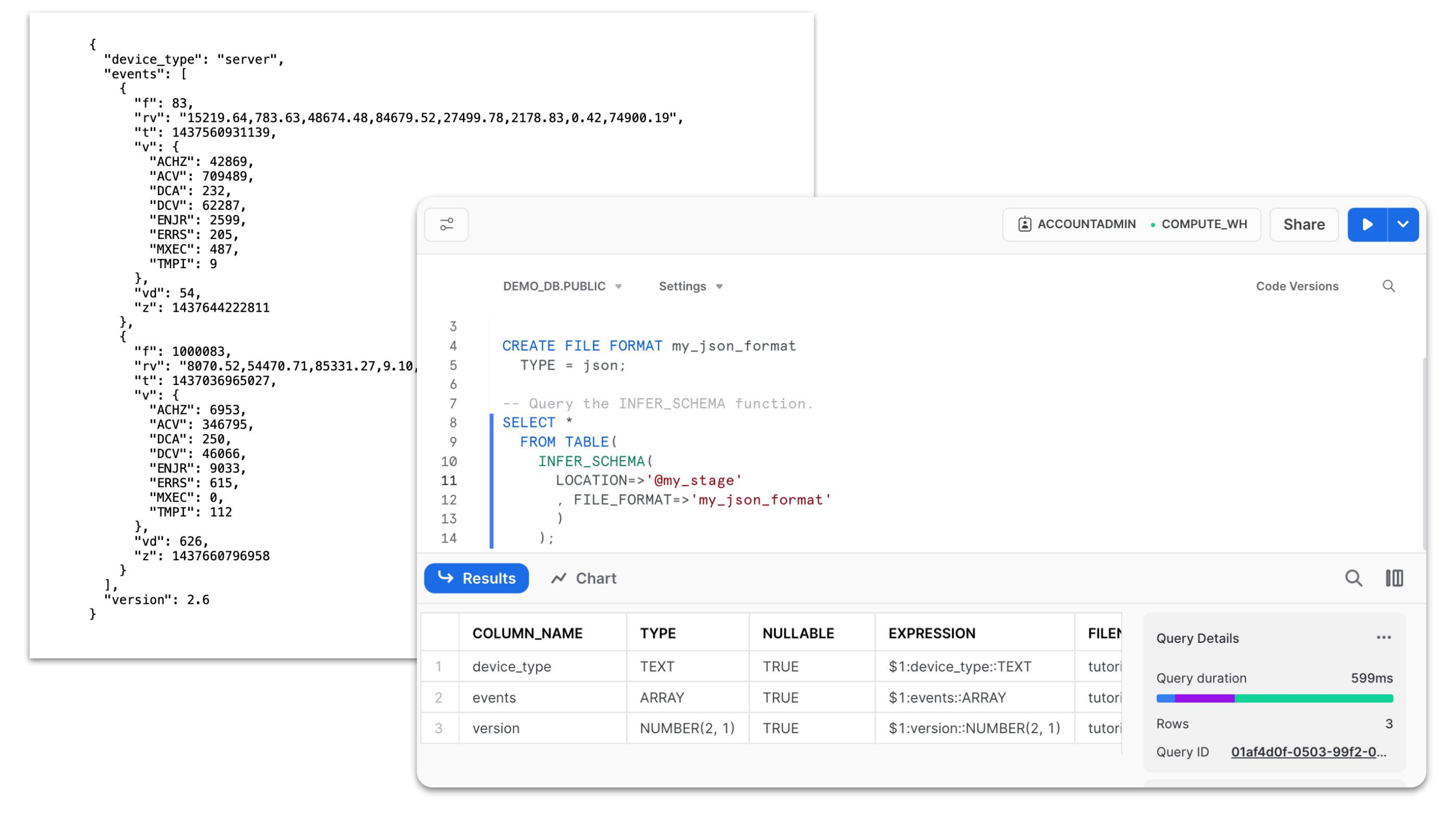
Ein Data Lake ist ein attraktives Architekturmuster, da ein Objektspeicher praktisch jedes Dateiformat mit jedem Schema in großem Umfang zu relativ geringen Kosten speichern kann. Es werden keine Schemata im Voraus definiert. Die Benutzer:innen entscheiden selbst, welche Daten und Schemata sie für ihren Anwendungsfall benötigen. Snowflake unterstützt seit Langem Datentypen und Dateiformate für semistrukturierte Daten wie JSON, XML und Parquet, seit Kurzem auch die Speicherung und Verarbeitung von unstrukturierten Daten wie PDF-Dokumenten, Bildern, Videos und Audiodateien. Wir haben neue Funktionen zur Unterstützung dieser Datentypen und Anwendungsfälle, sowohl für Dateien in einem von Snowflake verwalteten Speicher (interner Stagingbereich) als auch für Dateien in einem externen Objektspeicher (externer Stagingbereich).
Wir haben die Unterstützung für semistrukturierte Daten um eine unkomplizierte Möglichkeit zur Ableitung des Schemas von JSON- und CSV-Dateien in einem Data Lake erweitert (demnächst allgemein verfügbar). Im Laufe der Zeit entwickelt sich das Schema für semistrukturierte Daten immer weiter. In Systemen, die Daten generieren, entstehen neue Spalten mit zusätzlichen Informationen. Daher müssen die nachgelagerten Tabellen entsprechend weiterentwickelt werden. Daher bieten wir nun zusätzlichen Support für die Weiterentwicklung von Tabellenschemata an (demnächst allgemein verfügbar).
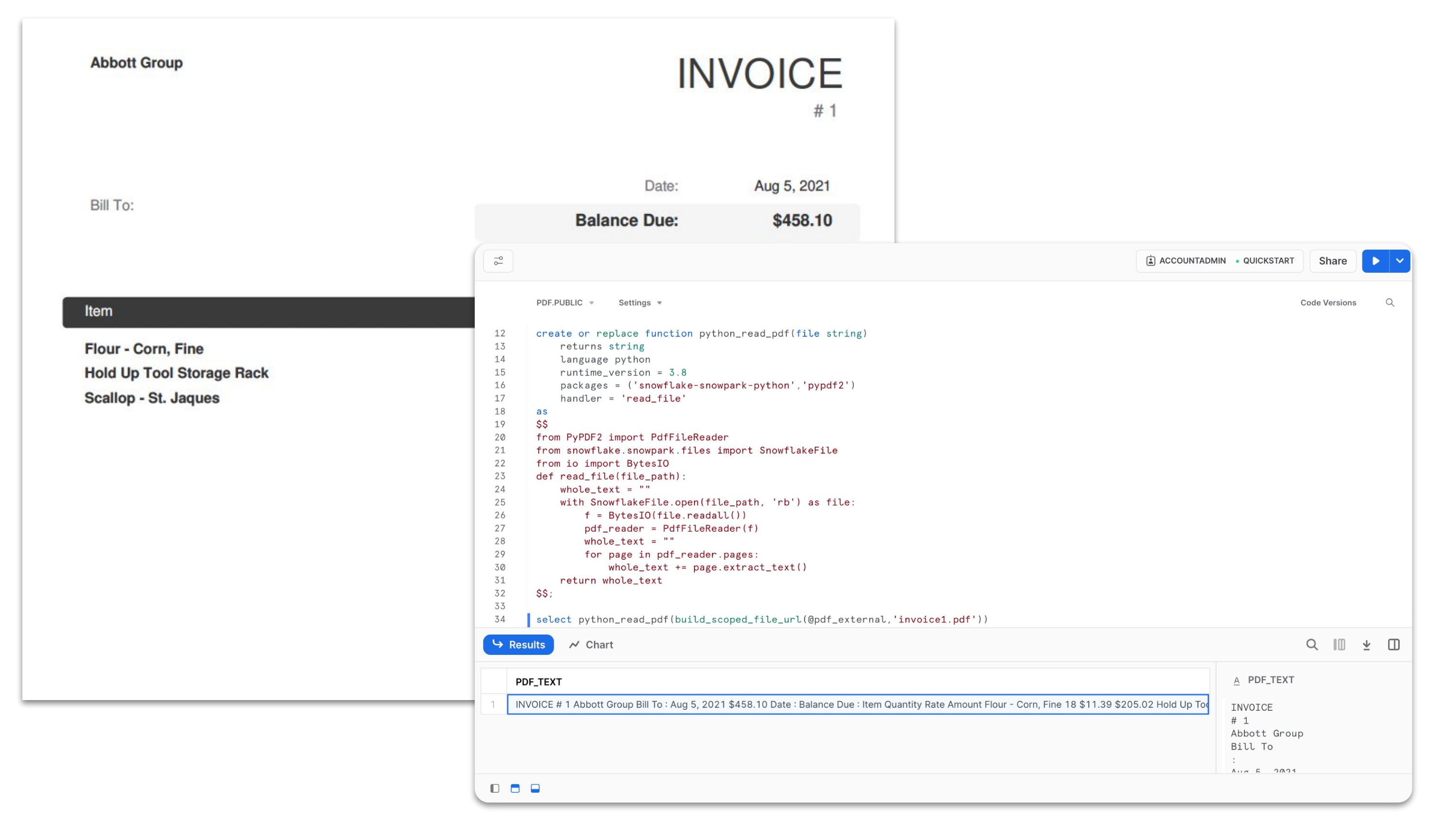
Für Anwendungsfälle mit Dateien wie PDF-Dokumenten, Bildern, Videos und Audiodateien können Sie jetzt auch mit Snowpark für Python und Scala (allgemein verfügbar) alle Arten von Dateien dynamisch verarbeiten. Data Engineers und Data Scientists können die Vorteile der schnellen Engine von Snowflake mit sicherem Zugriff auf Open-Source-Bibliotheken zur Verarbeitung von Bildern, Video, Audio etc. nutzen.
Schnelleres, moderneres SQL für Data Warehouses
SQL ist bei Weitem die gebräuchlichste Sprache für Data Warehouse-Workloads, und wir werden die Möglichkeiten der Datenverarbeitung mit SQL immer weiter ausreizen. Mit der neuen Unterstützung für AS OF JOINs (demnächst in Private Preview) können Datenanalyst:innen jetzt wesentlich einfachere Abfragen mit kombinierten Zeitreihendaten schreiben. Diese Anwendungsfälle kommen häufig in den Bereichen Finanzdienstleistungen, IoT und Feature Engineering vor, wo Joins auf Basis von Zeitstempeln nicht exakt übereinstimmen, sondern mit dem nächstgelegenen Vorgänger- oder Nachfolgedatensatz durchgeführt werden. Wir verbessern auch die Unterstützung für erweiterte Analytik in Snowflake. Die Erhöhung der maximalen Dateigröße beim Laden steht schon bald in Private Preview bereit. Sie können dann große Objekte (bis zu 128 MB) laden, wie sie beispielsweise oft bei der Verarbeitung natürlicher Sprache, der Bildanalyse und der Stimmungsanalyse vorkommen.
Wir arbeiten weiterhin an Performance-Verbesserungen und Kosteneinsparungen für unsere Kunden. Durch die neuen Optimierungen profitieren Kunden in vielerlei Hinsicht von besserer Performance zu geringeren Kosten:
- Ad-hoc-Abfragen in Warehouses mit speicherintensiven ML-Anwendungsfällen sind jetzt mit dem Query Acceleration Service für Snowpark Optimized Warehouses (allgemein verfügbar) noch schneller und kostengünstiger.
- Durch Top-K Pruning (demnächst allgemein verfügbar) sind SELECT-Anweisungen mit ORDER BY- und LIMIT-Klauseln schneller, insbesondere bei großen Tabellen.
- Die Wartungskosten für die Materialized View werden durch neue Effizienzsteigerungen des Warehouse (allgemein verfügbar) um mehr als 50 % gesenkt.
- Abfragen mit nicht-deterministischen Funktionen wie ANY_VALUE(), MODE() etc. profitieren ab sofort von einem Ergebnis-Cache zur Steigerung der Performance. Unsere Analyse ergab, dass bestimmte Abfragemuster bei den betroffenen Abfragen zu einer Reduzierung der Job Credits um 13 % führten (allgemein verfügbar).
- INSERT-Anweisungen sind jetzt durch die Unterstützung im Query Acceleration Service schneller (in Private Preview).
- Eine neue Funktion hilft bei der Einschätzung der anfänglichen und laufenden Wartungskosten für das automatische Clustering einer bestimmten Tabelle (in Private Preview).
Das ist erst der Anfang
All diese neuen Funktionen stehen für unsere Kunden in einer zentralen Plattform bereit, sodass sie mit der Data Cloud weiterhin ganz nach Wunsch ihre Architektur entwickeln und anpassen können. Den Zugang zu den Funktionen in Private Preview können Sie beim zuständigen Snowflake Account Manager beantragen. Bei den Funktionen in Public Preview oder allgemein verfügbaren Funktionen lesen Sie bitte die Versionshinweise und die Dokumentation, um mehr zu erfahren und erfolgreich zu starten.
Weitere Informationen zur Unterstützung der in diesem Blogbeitrag beschriebenen Architekturmuster durch Snowflake finden Sie auf unseren Seiten über Data Warehouse, Data Lake, Data Lakehouse und Data Mesh.
Sie möchten diese Funktionen in Aktion sehen? Sehen Sie sich die Snowday-Session an.
Zukunftsgerichtete Aussagen
Diese Pressemitteilung enthält explizite und implizite Aussagen über die Zukunft, einschließlich Aussagen über (i) die Geschäftsstrategie von Snowflake, (ii) die Produkte, Dienste und Technologieangebote von Snowflake, einschließlich derjenigen, die sich in der Entwicklung befinden oder noch nicht allgemein verfügbar sind, (iii) Marktwachstum, Trends und Wettbewerbsüberlegungen und (iv) die Integration, Interoperabilität und Verfügbarkeit der Produkte von Snowflake mit und auf Plattformen Dritter. Diese zukunftsgerichteten Aussagen unterliegen einer Reihe von Risiken, Ungewissheiten und Annahmen, unter anderem jenen Risiken, die in den von uns bei der Securities and Exchange Commission eingereichten Unterlagen aufgeführt sind. Angesichts dieser Risiken, Unsicherheiten und Annahmen kann es sein, dass die tatsächlichen Ergebnisse erheblich und in nachteiliger Weise von den Erwartungen bzw. Implikationen der zukunftsgerichteten Aussagen abweichen. Diese Aussagen entsprechen ausschließlich dem Wissensstand zum Zeitpunkt der erstmaligen Veröffentlichung. Sofern nicht gesetzlich vorgeschrieben, unterliegt Snowflake keinerlei Verpflichtung, die Aussagen in dieser Pressemitteilung zu aktualisieren. Daher sollten Sie sich nicht auf zukunftsgerichtete Aussagen als Prognosen zukünftiger Ereignisse verlassen.
Alle Informationen über zukünftige Produkte in dieser Pressemitteilung sind lediglich als Hinweis auf die allgemeine Produktausrichtung gedacht. Der tatsächliche Zeitpunkt der Bereitstellung von Produkten, Merkmalen oder Funktionen kann von den Angaben in dieser Pressemeldung abweichen.

