
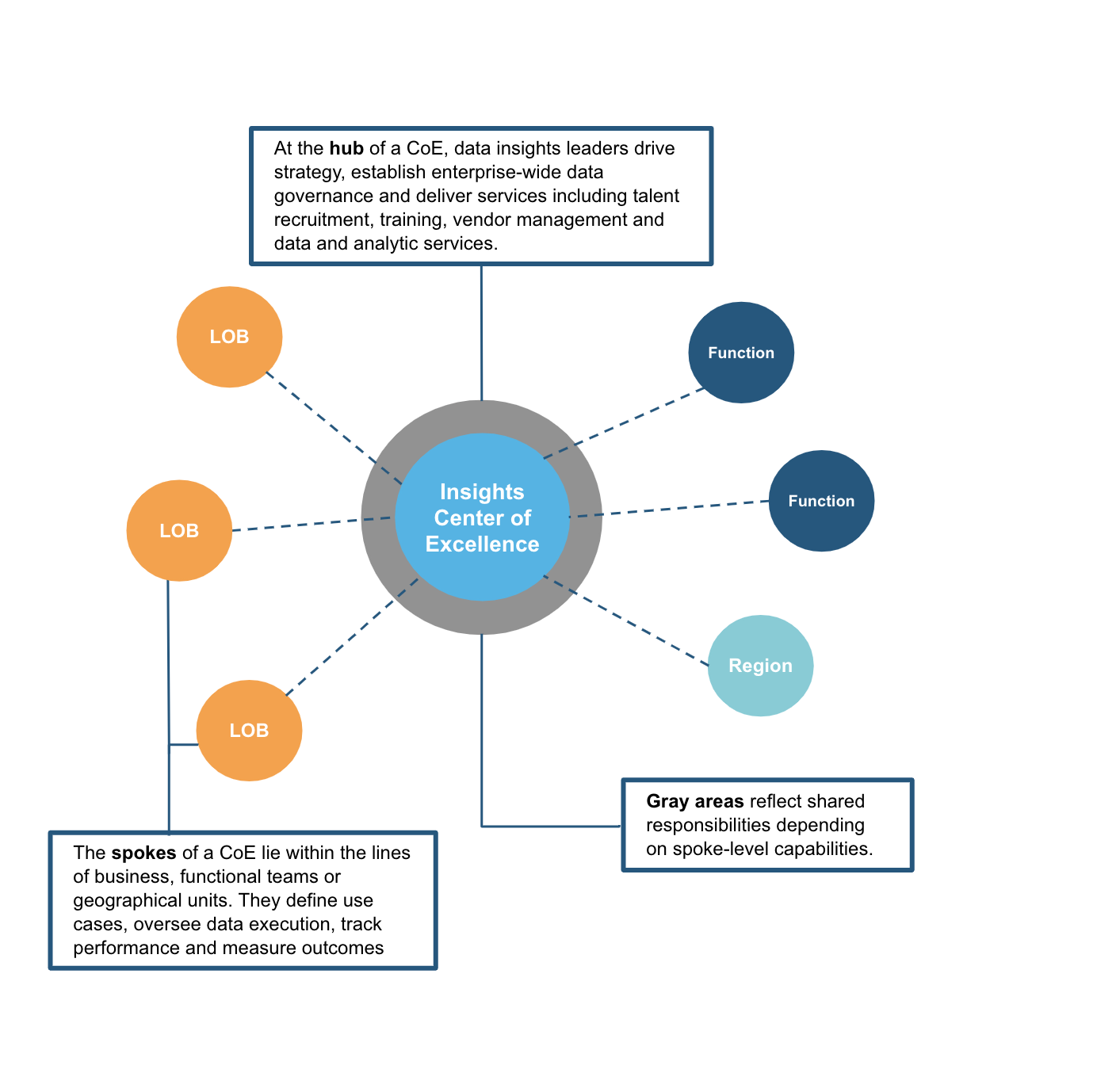
There is really no one size fits all when it comes to the structure of a data organization. In an earlier blog, I described a hub-and-spoke organizational model. These centers of excellence tend to be thought of as centralized organizational structures (likely due to the word “center” in the name). However, with a hub-and-spoke model, no one has to centralize anything that can or should be done within the spokes. I like to think of the CoE as more of a coordinating mechanism. Let’s call it Coordination of Excellence. Fortunately, we can keep the CoE acronym.
Growing Maturity Creates Centripetal Forces
Not all spokes are equally mature, and maturity levels can change over time. The question then is how to distribute responsibilities. Some business units or functions want or need more autonomy. For example, as the marketing team becomes more mature in the capture and use of customer data, it might want to more closely manage its customer data platform (CDP) and develop its own agenda for optimizing marketing outreach, campaign targeting and attribution. Or a product team builds the capability to analyze product data to improve product features, forecast demand and even deliver insights directly to customers. They want to be less dependent on a central data engineering team for pipelines or a central BI or data science team for analysis. Another scenario could be that an acquisition in one of the regional organizations has its own data infrastructure and expertise, and wants to maintain a degree of independence.
WARNING: In these scenarios, the creation of departmental data silos or even shadow IT must be avoided.

Instead, the answer is to meet these centripetal forces with coordination, not necessarily centralization. And, that’s what the CoE hub was initially intended to do with coherent data governance policies, common definitions and formats, standard data literacy and other training, shared best practices and other coordinated functions and services. Let those data producers and consumers who can “own” their data pipelines and data use. They prioritize and execute their use cases within a well-governed data ecosystem.
For others who don’t have the skills or maturity levels, the CoE might have a bench of experts to loan out and embed in spokes. For example, HR might want to improve recruiting, increase employee retention or optimize benefits packages. At a recent conference in Stockholm, the CDO of Bombardier Recreational Products advocated this kind of hybrid organizational model.
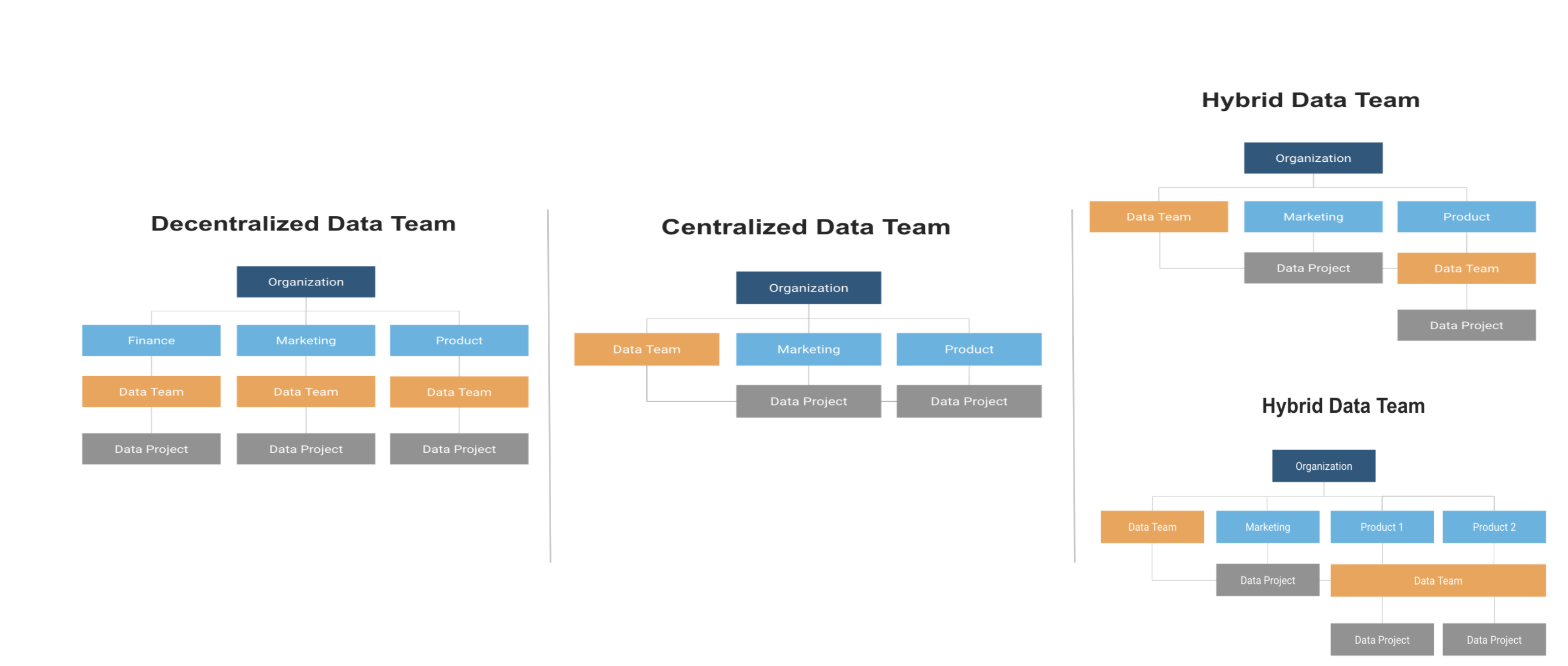
While the sputnik graphic above is illustrative, what would this look like in an org chart? In a decentralized model each function or business unit would have its own data team. This model offers proximity to the business units, yet often results in silos of uncoordinated policies and practices. A centralized model suggests that the hub drives data projects, managing priorities and enforcing policies. In a hybrid model a central data team would help with data projects for some functions where others would have their own teams. In a similarly hybrid model, a functional data team might serve the needs of two groups. In the hybrid model, the central team would act as a CoE to coordinate a coherent set of policies and best practice sharing.
Making Sense Of The Data Mesh
On the other side of the playground, however, there seems to be a different but related discussion happening around data architectures and organizations. The relatively new Data Mesh concept has challenged thinking about centralization of the data function, and argued for a decentralization of data architecture and ownership. But what does that mean for the organizational structure? The recent blog, Data Mesh: is the argument a strawman?, suggests that the current discussion confounds the two issues: organizational structure and infrastructure architecture.
As the blog points out, the primary problem addressed by the Data Mesh concept is the bottleneck created by centralized data ownership. A single team supports the pipeline needs from multiple source domains to multiple data consumers. As an intermediary, this team is overwhelmed by requests and lacks both the domain knowledge and the use case requirements to “effectively and accurately transform” the data. And, that central team structure disintermediates the data producers from the downstream processing and use. The Data Mesh concept advocates domain ownership of the data. Those who best understand the data sources, and can work directly with potential data consumers, deliver more appropriate data products and services. Yet the change in the ownership of data pipelines, and the introduction of the concept of data products, doesn’t necessarily dictate one specific architecture.
The strawman argument offers a potentially useful analogy that contrasts two competing architectures, which both allow for decentralized data ownership.
If we consider the analogy of families living in separate identical houses versus several families living in a single large shared house, the level of ownership that can be achieved is somewhat different. In the former, our ability to shape and mould our dwelling is much higher, with less need for compromise, than if we were sharing the same building; this comes at a greater risk of divergence from the standards we wish to enforce, however. Perhaps the true goal would be closer to an apartment block, where standardised access controls are in place, access and location is the same, and yet each individual unit can be tailored to the needs of that owner. This is where I see a central data platform fully enabling domain level ownership of their data, whilst ensuring that standardisation and governance is not an unwieldy challenge.
Yet, that argument is itself a strawman because the Data Mesh concept does not prescribe independent or identical houses. But let’s think more about the proposed alternative, the apartment building. Would all apartments be the same? More importantly, as discussed above, some teams might not need or want their own apartment or have the expertise to maintain their own apartment. Maybe that apartment building has a dormitory or a shared apartment for people without the resources or need for their own apartment, like student accommodation.
Or maybe the better analogy is an office building. Not all companies have their own. Some will. But, they won’t likely build their own. Most companies rent office space based on their needs, and those needs might change over time. Maybe the best analogy is a dynamic office space like WeWork. Companies share space and services to start with but they might occupy their own floor and manage more of their own services as they mature. They also might temporarily need more space for customer or partner meetings. They need a flexible space that can accommodate spikes in demand, and scale as they grow. Access policies and usage rights of the space are common and coordinated across the building. That’s perhaps the best analogy for data architecture.
Data infrastructure would be offered as a service. A CoE would maintain that infrastructure, or work closely with IT to maintain it, and would establish the policies that govern its use. More mature data domains would use those services to develop and maintain their data pipelines, creating data products that their consumers or others could use. However, there would also be teams without their own space. They might share with another organization, or they might just occupy space from time to time, relying on the central services.
Sputnik Meets The Data Mesh
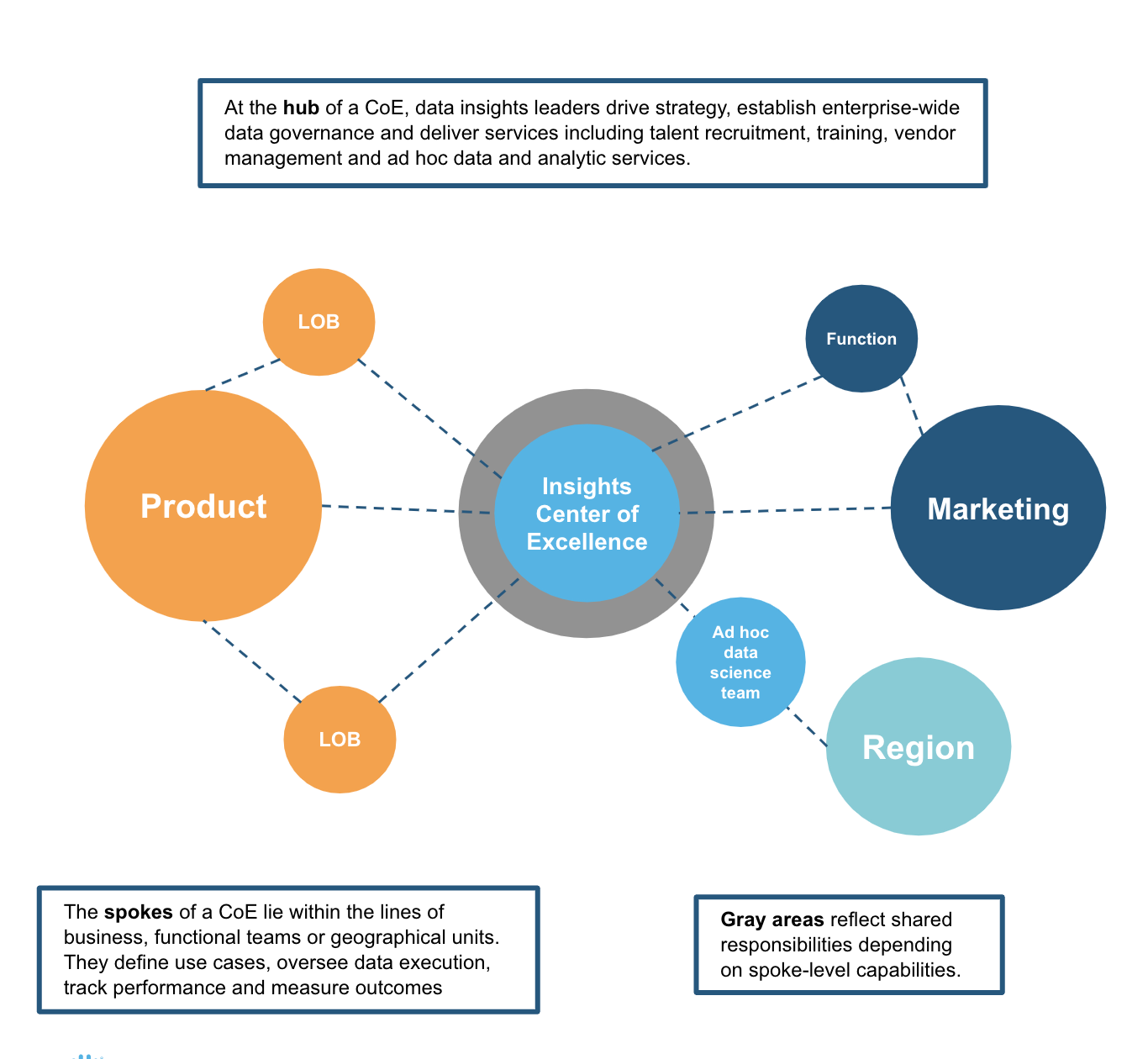
Bringing this back to the sputnik diagram above, we’ve got the CoE or a mechanism for coordinating common infrastructure and policies and we have spokes which represent business units or other functional areas. Some of the spokes might be data domains; others might be consumer domains. Some might be both, like the Marketing and Product spokes in the example above. The Marketing and Product teams manage their own data domains, leveraging a common infrastructure, respecting common governance policies, building data pipelines and products, and enabling their consumption across the organization. Less mature or less skilled spokes might rely on another domain, like Marketing or Product, for the data services they need. And, others might rely on the ad hoc data services offered by a general data science “domain” – a pool of resources allocated based on need and priority.
BOTTOM LINE: One size does not fit all. And, the size you need now might not be the size or shape you need later. Your organizational structure and data architecture must reflect the skills, resources and data and analytics needs across your organization. And, the choices you make should be able to accommodate future changes in all of the above.



