
注:本記事は(2021年12月1日)に公開された(No One Size Fits All: Make the Right Data Mesh for You)を翻訳して公開したものです。
データ組織においては、万能な仕組みは存在しません。以前のブログでハブアンドスポークモデルについて説明しました。このような中央に拠点を置く(CoE)モデルは、中央集権型の組織構成と捉えられがちです(恐らく「中央」という単語の影響でしょう)。しかし、ハブアンドスポークモデルでは、スポーク内で実施できるまたは実施すべきことをハブに集める必要は一切ありません。私としては、CoEは調整メカニズムの役割を果たしていると考えています。CoEのCを調整(Coordination)のCに置き換えましょう。幸い、CoEの頭字語はそのまま使用できます。
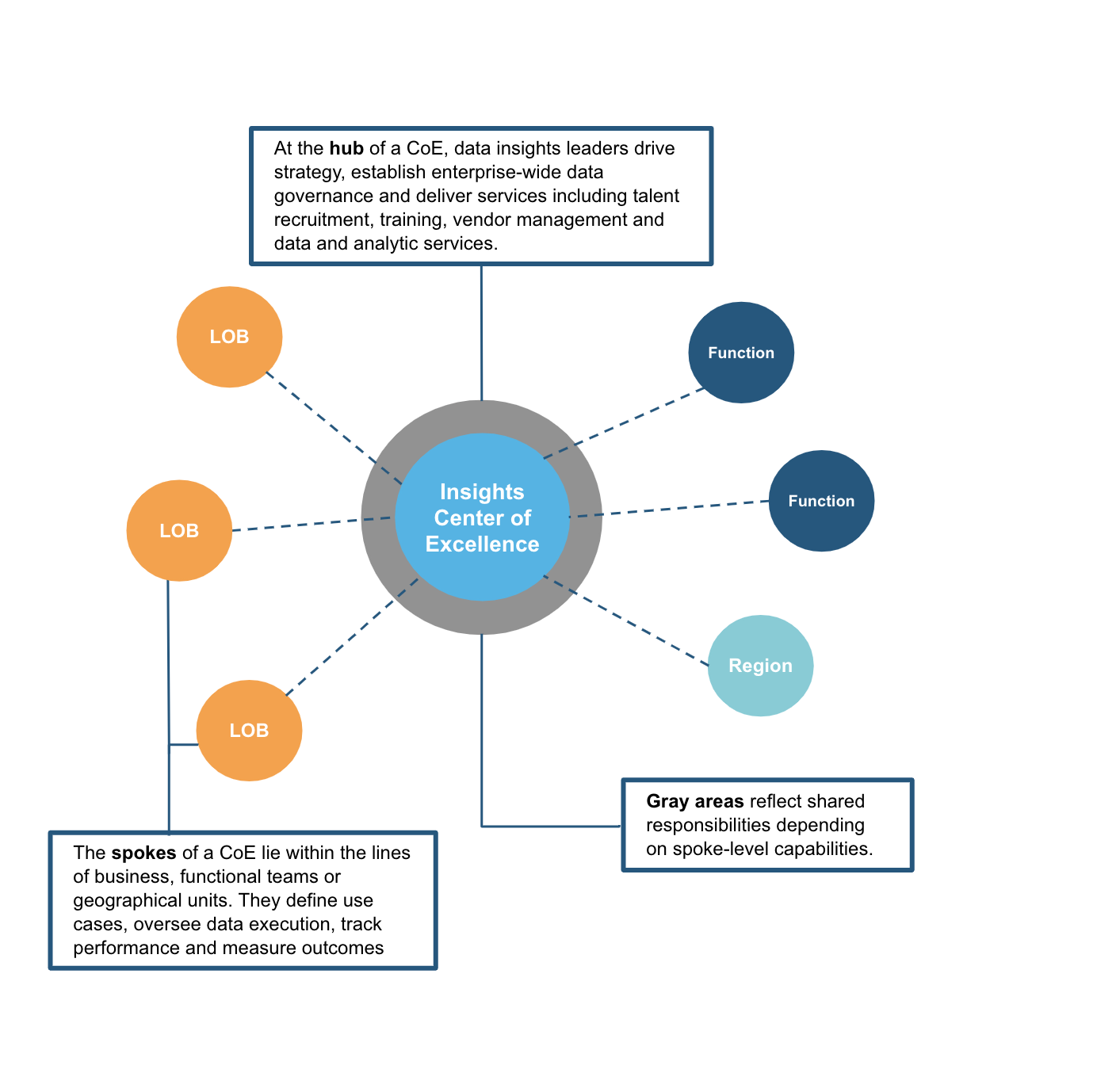
成熟度の向上による求心力の創造
すべてのスポークが等しく成熟しているとは限りません。また、成熟度は時間を経ることで変化します。問題は、どのように責任を分配するかです。より多くの自律性を求めるまたは必要な事業部門や職務もあります。たとえば、顧客データの取得や使用においてマーケティングチームの成熟度が増すにつれ、彼らはより密接に顧客データプラットフォーム(CDP)を管理し、マーケティングアウトリーチやキャンペーンのターゲティングやアトリビューションを最適化するために、独自のアジェンダを構築したいと考えるようになるかもしれません。また、プロダクトチームは、製品の機能向上、需要予測、顧客への直接的なインサイトの提供のために、製品データの分析機能を構築するかもしれません。彼らは、パイプラインにおけるデータエンジニアリングチームへの依存度や、分析における中央のBIチームやデータサイエンスチームへの依存度を低減したいと考えています。別のシナリオとしては、地域組織の1つが買収した企業が独自のデータインフラストラクチャーや専門知識を保有していて、その独立性を維持したいと考えるケースもあります。
警告:これらのシナリオにおいては、部署におけるデータのサイロ化やシャドーITの発生を回避する必要があります。

この状況を解決するのは、これらの求心力に対し、必ずしも中央集権的ではない調整で対応することです。これこそが、首尾一貫したデータガバナンスポリシー、共通の定義や形式、標準的なデータリテラシーおよびその他のトレーニング、共有されたベストプラクティスやその他の協調的機能やサービスに基づき、CoEハブが当初目指したものです。データパイプラインやデータを「所有」できるデータのプロデューサーやコンシューマーに利用してもらいましょう。彼らは、統制されたデータエコシステム内のユースケースに優先順位をつけ、実行してくれます。
そのようなスキルや成熟度のない人には、CoEが専門家を派遣したり、スポークに組み込んだりすることができます。たとえば、人事部門では求人状況の改善、従業員定着率の向上、福利厚生の最適化などが求められると言えるでしょう。ストックホルムで開催された最近の会議で、Bombardier Recreational ProductsのCDOは、このようなハイブリッドな組織モデルを提唱しました。
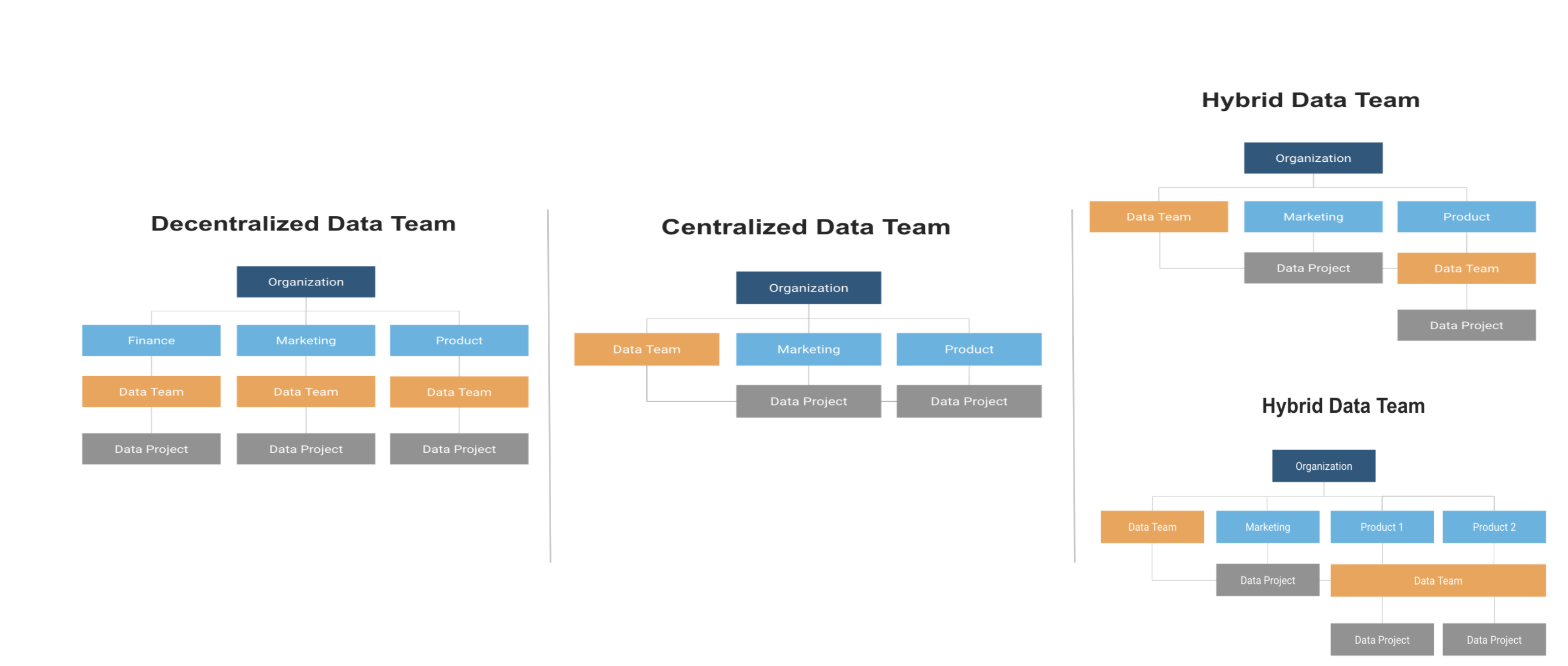
上のスプートニク型の図でも説明していますが、これを組織図に置き換えるとどうなるでしょうか。分散型モデルでは、各部署や事業部門が独自のデータチームを保有しています。このモデルでは事業部門との密な関係が示されていますが、これは調整の取れていないポリシーや慣習のサイロ化に陥りがちです。中央集権型モデルでは、優先順位の管理やポリシーの実行を伴う、ハブによるデータプロジェクトの遂行が提案されています。ハイブリッドモデルでは、データプロジェクトに対し、中央のデータチームがサポートをする部署もあれば、部署独自のチームで対応する場合もあります。同様に、ハイブリッドモデルではある部署のデータチームが2つのグループのニーズに対応することもあります。ハイブリッドモデルでは、中央のチームが一貫したポリシーセットやベストプラクティスの共有を調整するCoEの役割を果たします。
データメッシュの有効活用
データアーキテクチャおよびデータ組織の別の側面として、上記とは異なるものの関連のあるトピックがあります。比較的新しいデータメッシュという概念は、データの中央集権化に異を唱える考え方で、データアーキテクチャやオーナーシップの分散化を提唱しています。では、組織構造とは何を指すのでしょうか。最近のブログ、データメッシュ:筋違いの議論?では現在の議論が2つの問題、組織構造とインフラストラクチャーアーキテクチャが混同されているのでは、と提示しています。
このブログでも指摘されているように、データメッシュ概念で取り上げられている主な課題は、中央集権的なデータオーナーシップによるボトルネックです。これは、1つのチームが、複数のソースドメインから複数のデータコンシューマーに至るすべてのパイプラインニーズに対応するから生じるものです。このチームは、仲介役としてリクエストの対応に忙殺されることになり、データを「有効かつ正確に変換する」ためのドメインの知識やユースケース要件の双方が欠如することになります。さらに、この中央集権型チームの構成により、データプロデューサーはダウンストリームの処理や使用から切り離されます。データメッシュの概念が提唱するのは、データのドメインオーナーシップです。データソースを一番理解していて潜在的なデータ使用者と直接連携できる人が、より的確なデータプロダクトやサービスを提供できるということです。しかし、データパイプラインのオーナーシップの変更と、データプロダクト概念の導入は、必ずしも1つの特定のアーキテクチャを決定づけるものではありません。
この議論では、双方が分散型データオーナーシップを許容する2つの競合するアーキテクチャを対比させた、役に立ちそうなたとえ話を示しています。
それぞれそっくりに作られた別々の家に住む家族と、1つの大きなシェアハウスに住む複数の家族、といったたとえを考えた場合、達成できるオーナーシップレベルには何らかの差異が発生します。前者では、住居に手を加える権力ははるかに大きくなり、同じ家屋を共有している場合よりも妥協の必要性は少なくなります。しかしこれは、施行したい基準から逸脱する大きなリスクを抱えています。恐らく、目指すべき真の形は、標準化されたアクセス制御が整備されており、アクセスやロケーションは同一でありながら個々のユニットはオーナーのニーズに応じてカスタマイズ可能な、アパートに近いものかもしれません。これこそ、標準化やガバナンスが手に負えない程の問題とならないよう注意しながら、データのドメインレベルでのオーナーシップを完全に有効化できるセントラルデータプラットフォームだと思います。
しかし、この議論自体が筋違いだと思うのは、データメッシュ概念が、独立したまたはそっくりの家屋を表したものではないからです。ここで、提示されたもう1つの形、アパートについてもう少し考えてみましょう。すべてのアパートは同一でしょうか。さらに重要な点として、前述したようにチームの中には自身のアパートを必要としない、あるいは欲しがっていないところや、自身のアパートを維持する専門知識を有していないところがあります。もしかするとアパートには、リソースや自身のアパートを必要としない人のために、学生寮のような、ドミトリーやシェアルームが用意されているかもしれません。
あるいは、オフィスビルにたとえるのが良いかもしれません。すべての企業が自社ビルを持っているわけではありません。中には自社ビルを所有する会社もありますが、それも自らが建てているわけではありません。ほとんどの企業はニーズに応じてオフィススペースを借りており、そのニーズは時とともに変化します。もしかすると一番良いたとえはWeWorkのような動的なオフィススペースかもしれません。企業は、スペースやサービスを共有するところから始め、成熟度が増すにつれ、フロアを貸し切ったり独自サービスの管理領域を増やしたりするようになります。また、顧客やパートナーとの会議のために一時的に追加スペースが必要となるかもしれません。需要の急増や成長に応じたスケーリングに対応できるような、柔軟なスペースを必要としています。スペースに対するアクセスポリシーや使用権は共通でビル全体で調整されています。これこそがデータアーキテクチャの最適なたとえと言えるでしょう。
データインフラストラクチャーはサービスとして提供されています。CoEはインフラストラクチャーを維持しているか、維持のためにITと密接に連携しており、使用を統制するポリシーを構築します。成熟度の高いデータドメインは、彼らのコンシューマーや他者が使用できるデータプロダクトを作成しながら、これらのサービスを利用してデータパイプラインの開発、維持を行います。しかし、自身のスペースを持たないチームも存在します。そのようなチームは別の組織とスペースを共有したり、セントラルサービスに依存しながら、適宜スペースを使用するかもしれません。
スプートニク型のデータメッシュへの応用
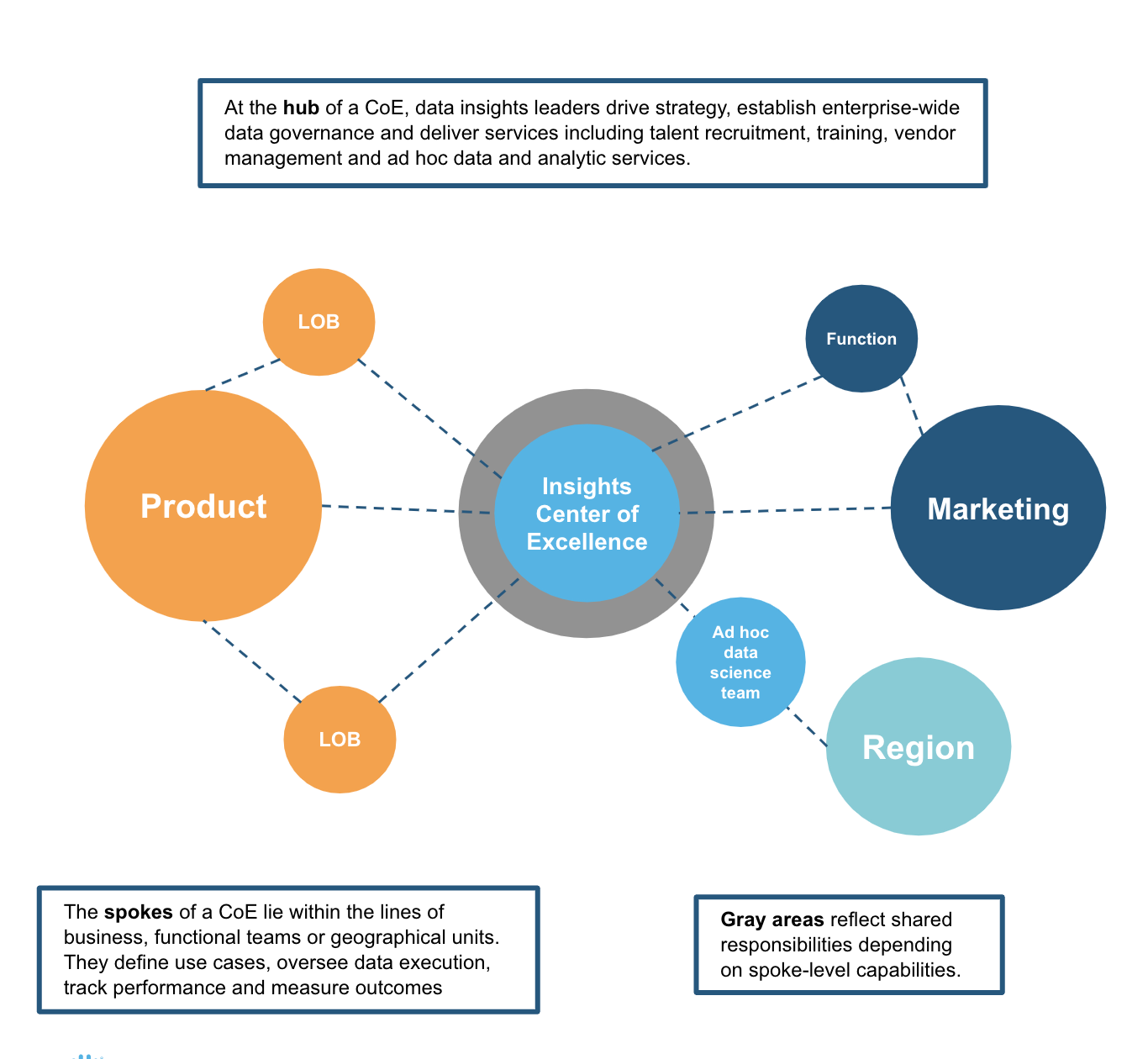
上のスプートニク型の図に話を戻すと、共通のインフラストラクチャーやポリシーを調整するCoEまたはメカニズムがあります。また、事業部門や他の部署を表すスポークがあります。いくつかのスポークはデータドメインであり、他はコンシューマードメインの場合があります。また、上図の例のマーケティングやプロダクトなど、両方の機能を備えたスポークもあります。マーケティングチームやプロダクトチームは、共通のインフラストラクチャーの活用、共通のガバナンスポリシーの順守、データパイプラインやプロダクトの構築、組織全体における使用の有効化を行いながら、自身のデータドメインを管理します。成熟度や能力がそれほど高くないスポークは、必要とするデータサービスについて、マーケティングやプロダクトといった他のドメインに依存することになるでしょう。また、一般的なデータサイエンス「ドメイン」(ニーズや優先順位に基づいて割り当てられたリソースプール)によって提供されているアドホックなデータサービスに依存するドメインもありそうです。
まとめ:あらゆるものに対応する万能策はありません。また、今必要とするサイズは、将来必要となるサイズや形とは異なるかもしれません。組織構造やデータアーキテクチャは組織全体のスキル、リソースやデータ、アナリティクスのニーズを反映したものでなくてはなりません。そして、何かを選択する際には、前述した将来の変化のすべてに対応できるものを選択する必要があります。