Additional thanks to co-writers Greg Rahn, Product Management and Shige Takeda, Engineering.
A key priority for us at Snowflake is expanding the choices of tools that developers and analysts have that can take advantage of Snowflake’s unique capabilities. A few months ago we announced support for R with our R dplyr package, which combines Snowflake’s elasticity with SQL pushdown capabilities, allowing R enthusiasts to execute their favorite R functions efficiently against large sets of semi-structured and structured data (get Snowflake’s dplyr package at Github).
Today we are thrilled to announce the general availability of a native Python connector for Snowflake. The Python connector is a pure Python package distributed through PyPI and released under the Apache License, Version 2.0.
We want to thank the many customers and partners who worked closely with us during the technology preview of the connector. That assistance helped us to prioritize key features and refine the connector based on real-world usage. Ron Dunn of Ajilius, a data warehouse automation solution provider, commented “The early availability of a Python adapter showed Snowflake’s commitment to integration, and the deep engagement of the team through the beta process was evidence of their strong developer support.”
What’s in the Connector?
Undoubtedly, Python has emerged as one of the most popular languages that developers are choosing for modern programming and is one that many of our customers have told us they use. With the release of a native Python connector, we are delivering an elegant and simple way of executing Python scripts against Snowflake, combining the power and expressiveness of Python with the unique capabilities of the Snowflake Elastic Data Warehouse service. Some of the key capabilities of the connector:
- Support for Python 2 (2.7.9 or higher) and Python 3 (3.4.3 or higher).
- Native Python connector for all platforms including OS X, Linux, and Windows.
- Easy installation through Python’s pip package management system, without the need for a JDBC or ODBC driver.
- Implementation of Python’s DB API v2.
- Support for connecting to Snowflake and executing DDL or DML commands.
- Support for COPY command (for parallel loading) and encrypted PUT & GET methods.
- Support for date and timestamp data types.
- Improved error handling.
Putting the Connector to Work: Automatic, scheduled loading via AWS Lambda and Python
Data loading is one of the challenges that we heard customers complain about frequently when describing their traditional data warehouse environments. Do any of these questions sound familiar to you?
- How to set up a load server(s)?
- How to configure networking to connect the load server with the data warehouse?
- How to maintain and schedule load scripts?
- How to scale with increasing loads?
Using Snowflake, these tedious tasks are not necessary anymore or greatly simplified and automated. By combining Python via our Python connector with AWS Lambda, users have a simple and powerful way to load data into Snowflake without the need for configuring servers or networking.
To illustrate, let’s use the example of how to easily operationalize steps to get data out of MongoDB and and to automatically invoke scheduled loading of JSON data arriving in S3 into Snowflake. We will show how to achieve this by using scheduled Lambda events to issue regular, incremental loads via Python and the Python connector.
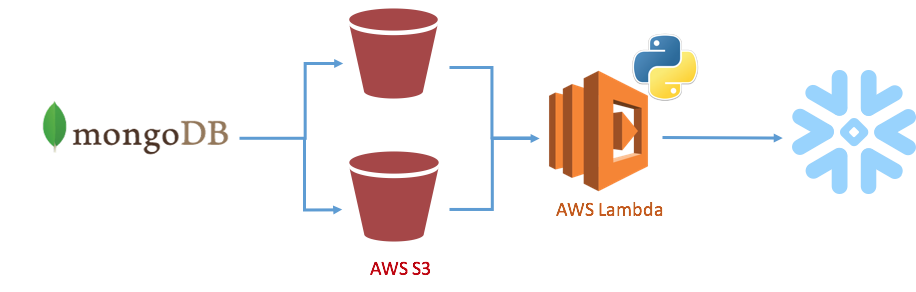
In a nutshell, a user just needs to perform the following steps to enable automatic data loading into Snowflake using Python and AWS Lambda:
STEP 1: Export JSON data from MongoDB into Amazon S3
To get data out of MongoDB, simply use the export functionality provided by MongoDB:
mongoexport --db <dbname> --collection <data> --out out.jsonPlease note that you need to transform the exported data into valid JSON by removing the BSON-specifics (MongoDB’s extended JSON format). For example, you can use this conversion script to convert extended JSON into JSON. Once exported, you can upload the data into an AWS S3 bucket using any of the available methods.
STEP 2: Set up Python environment for AWS Lambda
To set up AWS Lambda to allow execution of Python scripts, a user has to first create a virtual Python deployment environment for AWS Lambda and install the Python connector. You can find the corresponding shell scripts at our github location.
The Python connector itself is supported on all OS platforms and is published at the following PyPI location. Simply run the PIP command:
pip install --upgrade snowflake-connector-python STEP 3: Develop a Python-based loading script
In the following example, we demonstrate a simple Python script that loads data from an non-Snowflake S3 bucket into Snowflake. The script leverages the new Snowflake Connector for Python:
- First, import the the Python connector for Snowflake:
import snowflake.connector
- Then, set up your Snowflake account information and credentials for your S3 bucket:
ACCOUNT = '<your account name>' USER = '<your user name>' PASSWORD = '<your password>' AWS_ACCESS_KEY_ID = '<your access key for S3 bucket>' AWS_SECRET_ACCESS_KEY = '<your access key for S3 bucket>' - Connect to Snowflake, and choose a database, schema, and virtual warehouse :
cnx = snowflake.connector.connect ( user=USER, password=PASSWORD, account=ACCOUNT, database=myDB, schema=mySchema, warehouse=myDW ) - Create a table for your JSON data and load data into Snowflake via the copy command. Note that you don’t need to define a schema; simply use the variant column type:
cnx.cursor().execute("create JsonTable (col1 variant)") sql = """copy into JsonTable FROM s3://<your_s3_bucket>/data/ credentials = (aws_key_id='<aws_access_key_id>', aws_secret_key=('<aws_secret_access_key>')) file_format=(type=JSON)""" cnx.cursor().execute(sql)
To create a basic Lambda handler function, please see the corresponding lambda handler shell script in our github location.
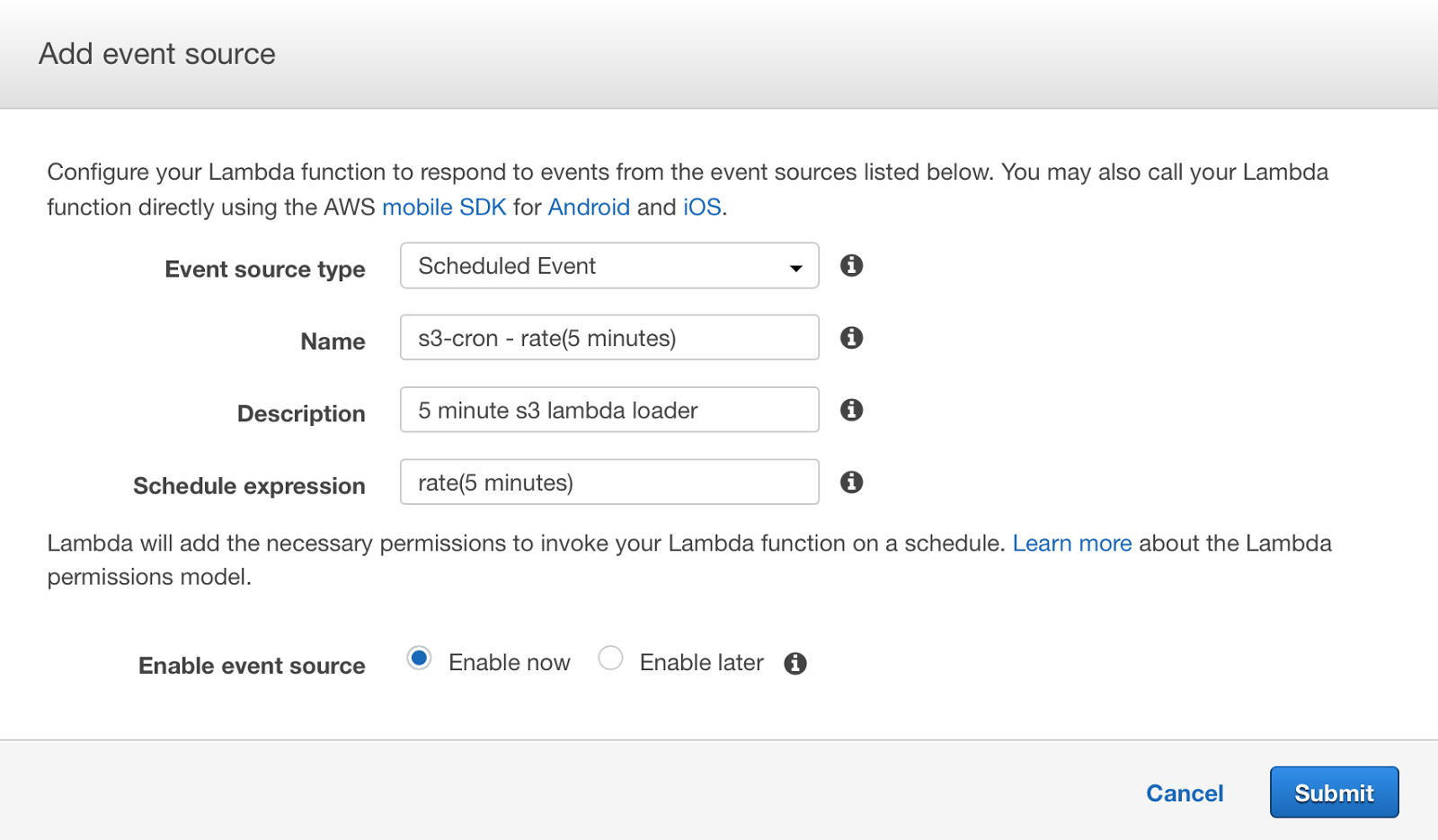
STEP 4: Set-up a scheduled AWS Lambda event for Amazon S3
The last step is to configure Lambda for scheduled events to be fired with Amazon S3 as event source. For example, a user can schedule a Lambda event to be fired at a particular time during the day or every 5 minutes. As of today the maximum execution time for each Lambda invocation is 300 seconds. That is, the load has to complete within this time window. Please also note that scheduled events are only supported by the AWS Lambda console (see below). More information about AWS Lambda can be found here.
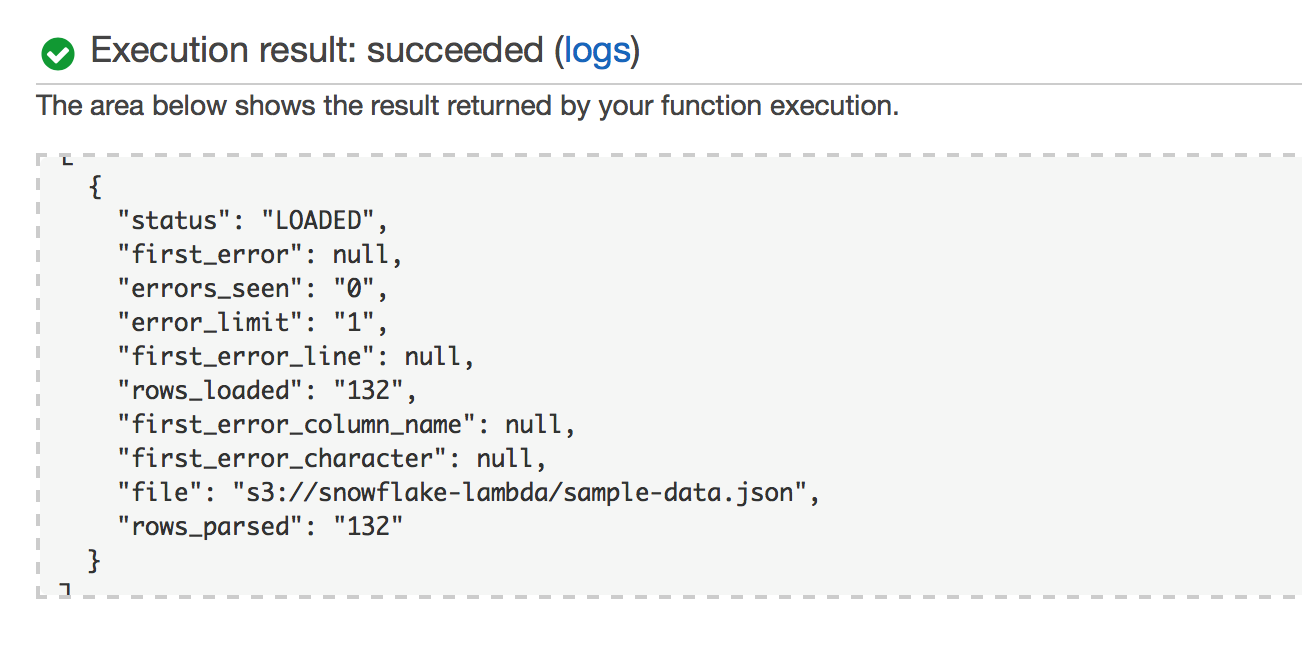
That’s it! We now have an automated way to take data exported from MongoDB and load it into Snowflake. In our example here, the output from the Lambda function shows that we loaded 132 rows into Snowflake.