
JUN 02, 2025|約1分で読めます

最近、私たちはヘルスケア・ライフサイエンス業界の新規のお客様との協力を開始しました。このお客様は、SQL ServerからSnowflakeへのパイプラインのためにDebeziumに多額の投資をしていました。見かけ上は、この選択は理に適っていました。Debeziumは、分散型変更データキャプチャ(CDC)の業界標準です。オープンソースで堅牢であること、そして何より、ライセンス料がかかりません。
しかし、Debeziumの「ゼロ円」という価格設定は、「飲んで終わりの無料ビール」ではなく、「手間のかかる無料の子犬」のようなものでした。初期の節約分は、Kafka Connectクラスターの運用管理という複雑な作業や、スキーマ進化に伴う絶え間ない摩擦によって、あっという間に相殺されてしまったのです。お客様は結局のところ、インフラストラクチャは豊かですが、データは乏しい「現状維持」のために、エンジニアリング時間を費やしていました。
お客様は、専門のエンジニアチームが常にモニタリングやメンテナンスを務める必要のない、ほぼリアルタイムのソリューションを必要としていました。その結果、アーキテクチャ全体をSnowflake Openflowに移行することを決定しました。
その目標は驚くほど、圧倒的にシンプルでした。それは、SQL ServerのデータをSnowflakeへほぼリアルタイムで同期することでした。レイテンシーの時間枠は1~5分であり、これはスピードだけでなく、ミッションにはレジリエンスとスケーラビリティ、そして何より管理しやすいパイプラインが必要でした。
Debeziumのメンテナンスが耐えられなくなった理由を理解するには、移動しているデータ量を調べることが重要です。これは単一テーブルの同期ではなく、お客様のアナリティクスにとって、生命線となる、絶え間ないデータの移動でした。
以下に、プロジェクトの膨大な規模を数字でごく簡単に示します。
この規模では、旧設計にわずかな不具合が生じただけでも、大規模なバックログが発生していました。従来の方法では、30分間の停止に追いつくには、何時間もの手作業が必要でした。お客様は、常時モニタリングすることなくこのボリュームを扱えるシステムを必要としていました。
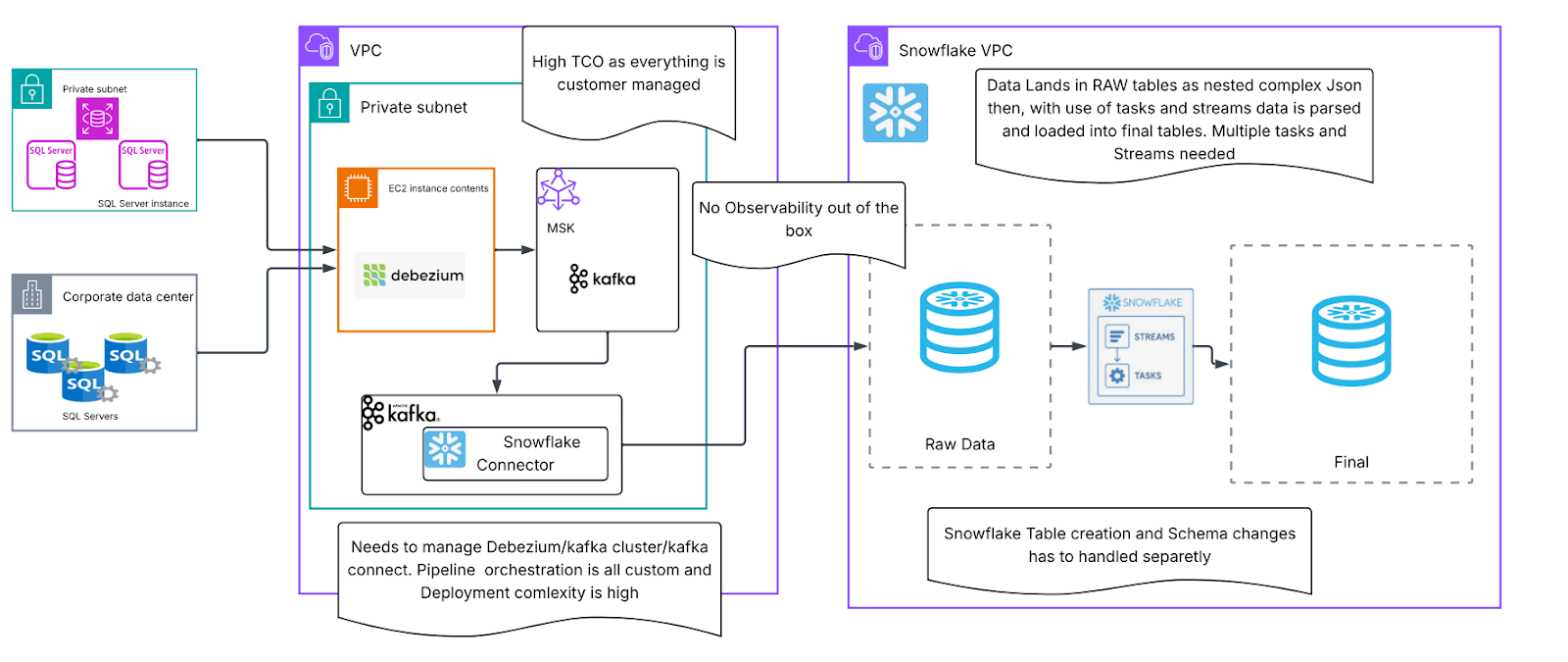
移行前のデータは、ソースから最終的なアナリストダッシュボードまで、長い複雑な過程をたどっていました。ワークフローは次のようになっていました。
図 1の各矢印は、潜在的な障害点を表しています。Kafka Connectの作業に遅延が発生すると、データに遅れが生じていました。Snowflakeタスクが失敗した場合、生テーブルは解析されていないデータで膨れ上がっていました。単にデータを移動するだけでなく、相互依存するサービスの複雑なエコシステムも管理することになっていたのです。
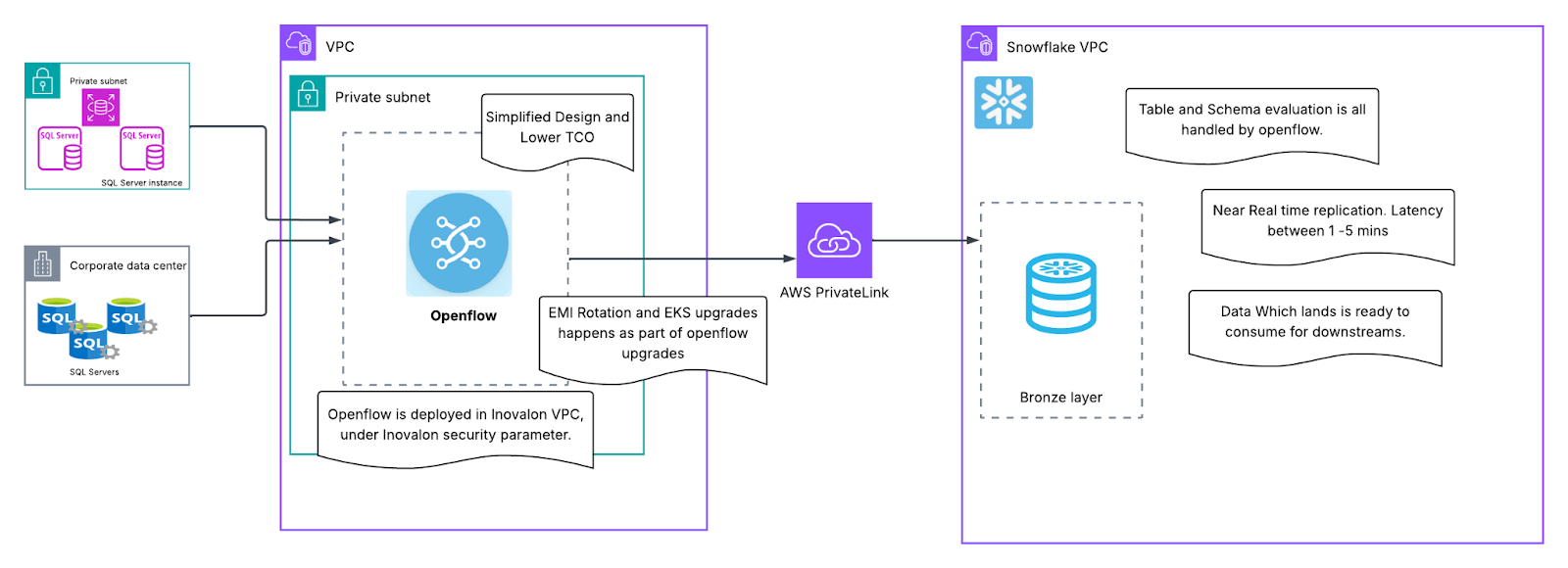
図 1が運用オーバーヘッドを示すとすれば、図 2は直行便のようなシンプルな構成を示しています。Openflowを導入したことで、アーキテクチャ上の「ノイズ」が解消されました。Debezium、MSK、Kafka Connect、Snowflakeの手動タスクによるマルチホップリレーではなく、SQL ServerからSnowflakeへの直接のアプローチに移行しました。
DebeziumとOpenflowを、お客様の実稼働セットアップでの実際の運用メトリクスで比較してみましょう。
| 比較要素 | Debezium | Openflow |
|---|---|---|
| CDCメカニズム | CDC(重度) | 変更追跡(軽度) |
| SQL Serverのオーバーヘッド | 高い | 低い |
| パイプラインオーケストレーション | カスタム/手動 | Snowflakeマネージド |
| 展開の複雑さ | 非常に高い | 低~中程度 |
| スキーマメタデータ | Kafkaメッセージに埋め込まれたスキーマメタデータで構造的なCDCイベントを生成する | Snowflake内でスキーマメタデータを自動的に管理 |
| Snowflakeでのテーブル作成 | 手動で処理 | コネクタによる自動管理 |
| スキーマの進化 | スキーマの変更を手動で検出して適用する必要がある | コネクタによる自動管理 |
| データフロー | SQL Server -> Kafkaトピック -> Kafka Connect -> 未加工テーブル -> カスタム結合タスク -> 最終テーブル | SQL Server -> Snowflake最終テーブル |
| 結合と変換 | JSONのフラット化とCDC行の結合に必要なSnowflakeのカスタムタスク | コネクタによる自動管理 |
| 責任境界 | DebeziumはKafkaへのイベントのみを処理するため、ダウンストリーム処理の構築とメンテナンスが必要 | Openflowが処理するエンドツーエンドのパイプライン |
| オブザーバビリティ | カスタム | すぐに使用可能 |
ここでは、DebeziumとOpenflowの実際のコスト比較を示しています。
| 比較要素 | Debezium | Openflow |
|---|---|---|
| ライセンスコスト | オープンソース、コネクタのライセンス料なし | Openflowの個別のプロダクトライセンスは不要 |
| インフラストラクチャのコスト | Kafkaエコシステムが必要:MSK/Kafkaブローカー + Kafka Connectの作業員 | お客様のVPCにOpenflow BYOCを展開する必要があるが、クラウドのフォーメーションにより自動化される。 |
| 運用コスト | Kafkaのスケーリング、メンテナンス、モニタリングによって非常に高い。別途、L2サポートチームが管理する必要あり。 | 比較的低い。Openflow BYOCの展開は、Snowflakeとお客様が共同で責任を負い、Snowflakeはすべてのステップを自動化する。 |
| Snowflakeの費用 | ストレージ、ウェアハウス、Snowpipe/Snowflakeシンクコネクタ | ストレージ、ウェアハウス、Snowpipe Streaming、Openflowコンピュート |
DebeziumからOpenflowへの移行は、単にツールを変更するだけではありません。エンジニアリングの時間を解放します。Kafkaという「仲介役」を排除したことで、お客様はインフラストラクチャのコストを節減できただけでなく、常時モニタリングすることなく拡張できるレジリエンスの高い自己修復パイプラインを獲得しました。
現在、「インフラストラクチャが豊富でデータに乏しい」状態になっている場合は、スタックをシンプルに再構築する時期かもしれません。
ステップを進める方法は、次のとおりです。

