JUN 12, 2024

データサイエンスとMLワークロードを拡張する際、組織は大規模で堅牢な実稼働MLパイプラインを構築するという課題に頻繁に直面します。よくある問題として、開発チームと実稼働チーム間の重複作業や、トレーニングで使用する機能とサービススタック内の機能の不一致が挙げられます。これらはパフォーマンスの低下につながります。多くのチームは特徴量ストアを利用し、一貫した最新のML特徴量セットを維持する一元化されたレポジトリを作成します。しかし、多くの場合、特徴量オーサリングのための追加のインフラストラクチャーの管理、更新パイプラインの構築と維持、一貫した新しい特徴量にアクセスするためのワークフローの確立が複雑になります。その結果、チームは仮設のソリューションやカスタマイズされたソリューションに予想以上に多くの時間を費やすことになります。
本日、Snowflake特徴量ストアの一般提供を発表いたします。このネイティブソリューションは、Snowflake MLのエンドツーエンドワークフローと同じプラットフォーム上に存在し、データ、特徴量、モデルにシームレスに統合されるため、大規模なMLパイプラインを簡単かつ効率的に生産できます。特徴量ストアは、パイプラインの冗長性と重複を排除し、エンタープライズグレードのセキュリティとガバナンスを備えた最新かつ一貫性のある正確な特徴量を利用できるようにします。
Snowflake特徴量ストアの主な機能は次のとおりです。
PythonまたはSQLで一般的な特徴量変換を簡単にオーサリング
バッチソースとストリーミングソースの両方からの新しいデータに対する自動化された効率的な機能更新
ASOF JOINを使用して時間整合的な特徴量を取得し、トレーニングデータセットを生成するためのシンプルなAPI
きめ細かいロールベースのアクセス制御(RBAC)とガバナンス
dbtなどのツールでのユーザー維持特徴量パイプラインのサポート
モデルレジストリおよびその他のSnowflake ML機能との完全な統合
Snowsight UIから特徴量とエンティティを一元管理し、簡単に検索と発見を行えるようにする
組み込みのエンドツーエンドMLリネージ(プレビュー機能)
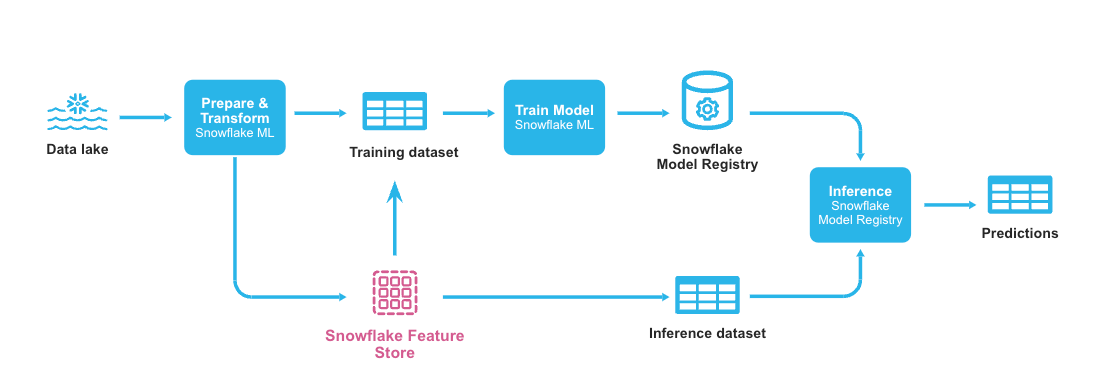
Snowflake特徴量ストアは、Snowflakeモデルレジストリおよびその他のSnowflake ML機能と完全に統合されており、Snowflakeにおける完全なエンドツーエンドのML開発および運用ソリューションを実現します。このワークフローの概略図を次に示します。
すでに多くのお客様が、さまざまな業界やユースケースの特徴量ストアをMLワークフローで使用しています。
Scene+は、カナダのロイヤルティプログラムです。Snowflake特徴量ストアを大規模データセットに使用し、以前のソリューションから大幅にパフォーマンスが向上しています。
Scene+は、機械学習を活用して、当社のプロパティ全体で関連性の高いメンバー体験を提供しています。これには、膨大な量のデータを扱う必要があります。Snowflake特徴量ストアのシンプルさを活用することで、処理時間を66%短縮できました。モデル・ユニバースと特徴を結合するために必要なのは、わずか4行のコードブロックだけです。従来の方法では、長いPythonスクリプトや入力ファイル、追加の依存スクリプトを書く必要がありましたが、Snowflake Feature Storeを使用することで大幅に簡素化できました。"
小売業界では、Snowflakeのパートナーであるキューブリック社も特徴量ストアを導入し、カスタマーエクスペリエンスを向上させるモデルを生産しています。
グローバルラグジュアリーファッションおよびライフスタイル企業が、Kubrickと提携してSnowflake特徴量ストアを導入し、顧客体験とパーソナライゼーションを向上させるモデルをホリデーシーズンに展開しました。このMLOpsソリューションにより、生産までのリードタイムを25%短縮し、処理速度を3〜10倍に高速化しました。”
生成AIユースケースでは特徴量ストアも使用されています。リモート、オンライン、対面式学習のリーダーであるStrideは、phDataと提携し、生徒と教師に正確かつ安全な支援を提供するRAGアプリにSnowflake特徴量ストアを導入しました。
特徴量ストアを利用したシンプルなMLワークフローを以下に示します。
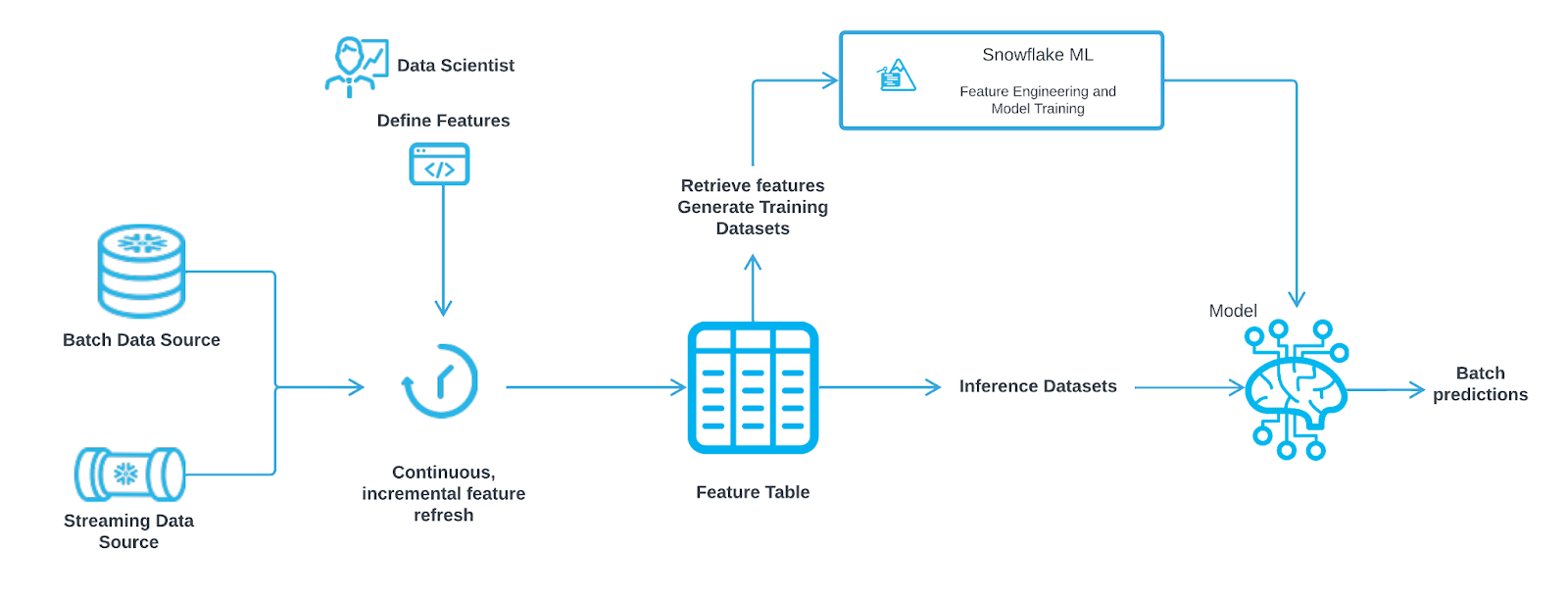
その主な構成要素を見てみましょう。
Snowparkセッション、データベース名、スキーマ名、デフォルトウェアハウスを指定することで、特徴量ストアを簡単に作成したり、既存の特徴量ストアに接続したりできます。特徴量ストアとは、Snowflakeのバックエンドにあるスキーマです。
from snowflake.ml.feature_store import FeatureStore, CreationMode
fs = FeatureStore(
session=session,
database="MY_DB",
name="MY_FEATURE_STORE",
default_warehouse="MY_WH",
creation_mode=CreationMode.CREATE_IF_NOT_EXIST,
)特徴量ビューは特徴量ストアの主要な抽象化です。同じスケジュールでコンピュートおよび維持される、論理的に関連する特徴量の集まりで構成されます。Snowflake特徴量ストアでは、SnowparkデータフレームまたはSQL変換を使用して、あらゆるソース データ(テーブル、ビュー、共有など)から特徴量ビューを作成できます。ソーステーブル(またはビュー)またはデータ変換データフレーム内の列は特徴量として認識される。さらに、特徴量ビューには、トレーニング時または推論時の特徴量検索に使用される結合キーと、時間による特徴量値の変化を取得するためのタイムスタンプ列を含むエンティティーが含まれている必要があります。
エンティティの定義:
from snowflake.ml.feature_store import Entity
entity = Entity(
name="CUSTOMER",
join_keys=["CUSTOMER_ID"],
desc="customer entity"
)
fs.register_entity(entity)特徴量ビューの定義:
from snowflake.ml.feature_store import FeatureView
managed_fv = FeatureView(
name="Customer_Order_History_Features",
entities=[entity],
feature_df=my_df, # a Snowpark DataFrame
timestamp_col="ts", # optional timestamp column name in the dataframe
refresh_freq="5 minutes", # optional parameter specifying how often feature view refreshes
desc="features about customers order history" # optional description string.
)
registered_fv: FeatureView = fs.register_feature_view(
feature_view=managed_fv,
version="1"
)feature_dfは、特徴量定義を含むSnowpark DataFrameオブジェクトです。Snowparkは、多くの一般的な特徴量変換を簡単に定義できるヘルパー関数を提供します。たとえば、以下のコードスニペットは、1日のスライド期間における顧客の注文合計とカウントの3か月と6か月の集計を指定しています。
def custom_column_naming(input_col, agg, window):
return f"{agg}_{input_col}_{window.replace('-', 'past_')}"
my_df = customer_orders_df.analytics.time_series_agg(
aggs={"ORDER TOTAL": ["SUM, "COUNT"]},
windows=["-3MM", "-6MM"],
sliding_interval="1D",
group_by=["CUSTOMER_ID"],
time_col="ORDER_DATE",
col_formatter=custom_column_naming
)timestamp_colは、ポイントインタイムの正しい特徴量値を取得するトレーニングに必要なエンティティキーを含むテーブルと結合するために使用するタイムスタンプ列の名前です。
Snowflake特徴量ストアの主なメリットは、動的テーブルを使用して、データおよび特徴量エンジニアリングパイプラインとバックフィル管理の複雑さを自動化し、抽象化することです。多くの特徴量ストアソリューションでは、最初の入力とその後の特徴量値の「更新」を実行するために、すべてのデータと特徴量エンジニアリングロジックを作成する責任があります。これらのステップは、特徴量ストアの外で手動でスケジュールおよび管理する必要があります。
Snowflakeマネージド特徴量ビューでは、これらすべてが宣言的に処理されます。データフレーム/SQLを使用して、すべての履歴の特徴量を計算するロジックを定義します。その宣言型ロジックの増分処理はSnowflakeが行います。これらのマネージド特徴量ビューを使用するには、refresh_freqを指定するだけです。refresh_freqは、特徴量の更新頻度と、その特徴量をソーステーブルからどの程度最新にする必要があるかを定義します。Snowflakeが管理する特徴量ビューは、新しい特徴量ストアのサポートにより、Snowsight UIから監視できます。
ほとんどの場合は、このようなマネージド特徴量ビューを使用しますが、外部ツールを使用して実行される、自社が管理する特徴量パイプラインを使用するシナリオもあります。この場合は、refresh_freqを省略して特徴量ビューを作成します。これにより、取得時に計算されるユーザー管理の特徴量ビューが作成されます。
特徴量ストアの主な目的は、一貫性のあるトレーニングデータセットの生成を簡略化することです。特徴量ストアは、ワークフローに応じて2つの形式のトレーニングデータを生成するAPIを提供します。いずれの場合も、Snowflake特徴量ストアはタイムスタンプとASOF JOIN関数を使用して正しいポイント イン タイムの値の取得を処理し、効率的かつスケーラブルに複数のビューから特徴量を結合し、時間の一貫した結果を生成します。
Snowflakeデータセットは、機械学習ワークフロー専用に設計された新しいスキーマレベルのオブジェクトです。Snowflakeデータセットは、バージョン別に整理されたデータセットを保持しており、それぞれが不変性、効率的なデータアクセス、PyTorchやTensorFlowなどの一般的なディープラーニングフレームワークとの相互運用性が保証されたデータのマテリアライズドスナップショットを保持しています。データセットは、特徴量ストアから以下のように簡単に作成できます。
my_dataset = fs.generate_dataset(
name="CUSTOMER_ORDER_DATASET",
spine_df=MySourceEntityKeyDataFrame,
features=[customer_order_features, customer_demographic_features],
version="v1", # optional
spine_timestamp_col="TS", # optional
spine_label_cols=["LABEL1", "LABEL2"], # optional
include_feature_view_timestamp_col=False, # optional
desc="customer order dataset for training customer life time value model", # optional
)トレーニング データは、scikit-learnやSnowpark MLなどのクラシックMLライブラリでトレーニングするためのSnowpark DataFrameとして作成することも、外部の機械学習フレームワークにロードすることもできます。
training_set = fs.generate_training_set(
spine_df=MySourceDataFrame,
features=[customer_order_features, customer_demographic_features],
save_as="training_data_20240101", # optional
spine_timestamp_col="TS", # optional
spine_label_cols=["LABEL1", "LABEL2"], # optional
include_feature_view_timestamp_col=False, # optional
)同様に、特徴量ストアでは、retrieve_feature_valuesを使用したモデル推論のための特徴量データの直接取得がサポートされており、実稼働可能な増分バッチ推論パイプラインを簡単にオーサリングおよびスケジューリングできます。
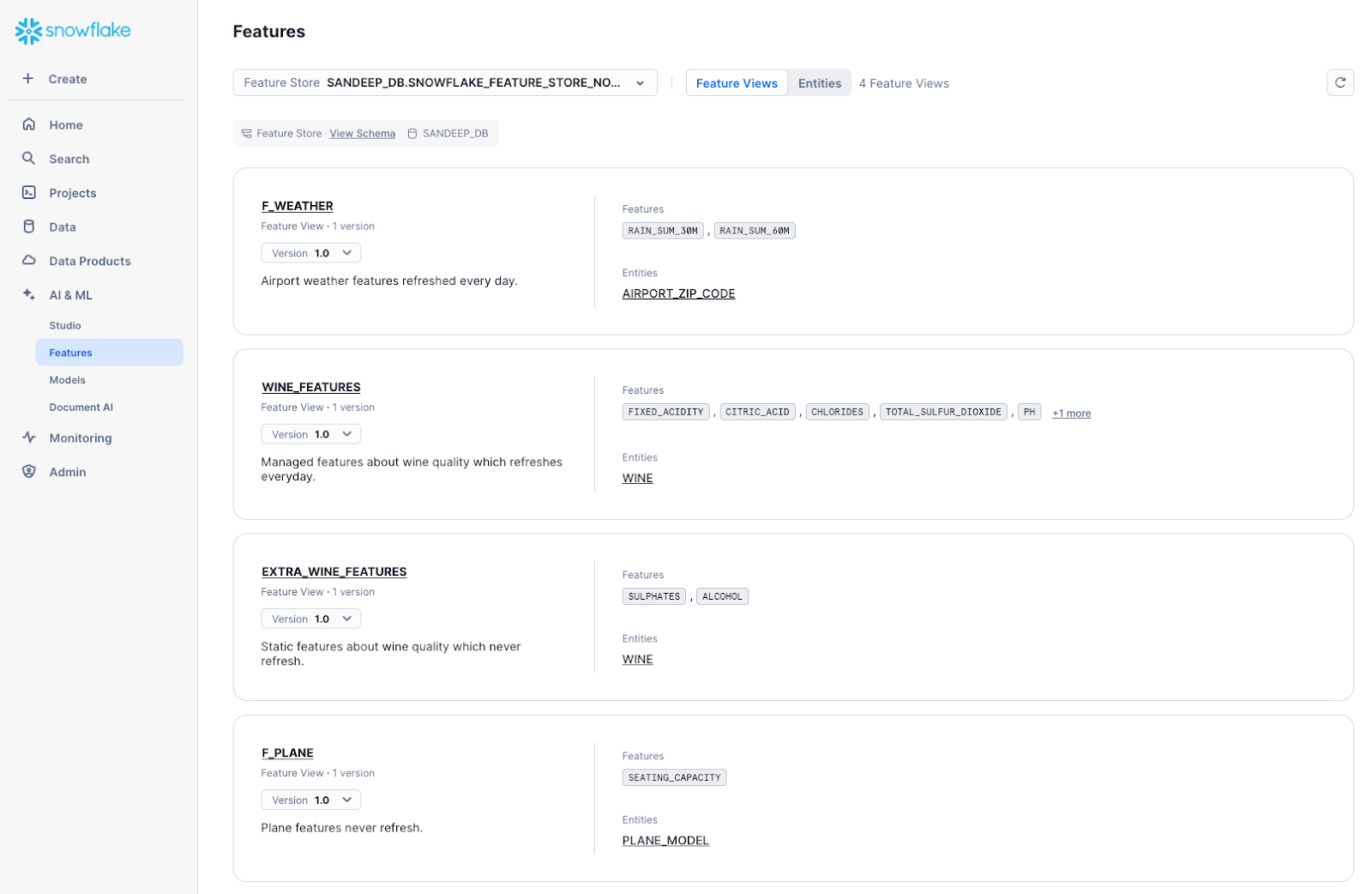
特徴量ストアはSnowsight UI内で利用でき、特徴量ビューとそのバージョン、基礎エンティティ、個々の特徴量列、関連する特徴量メタデータを簡単に閲覧、検索、管理できます。
Snowflake特徴量ストアは、スキーマ、動的テーブル、ビューなどの標準的なデータベースオブジェクトを使用します。Snowflakeのオブジェクトタギングは、これらのデータベースオブジェクトを特徴量ストアに属し、それらの間の関係を維持するために使用されます。特徴量ストアとその内部にあるオブジェクトへのアクセスを制御するには、標準のSnowflake RBACが使用されます。一般的な特徴量ストアの実装では、2つのロールが定義されます。生産者と消費者。プロデューサーは特徴量ビューを作成および変更できます。コンシューマーは特徴量ビューを読み取ることができます。各ロールの権限の詳細については、このページを参照してください。また、これらのロールを簡単に構成できるシンプルなユーティリティAPIとSQLスクリプトも提供しています。特徴量パブリッシャーは、Snowflakeデータシェアリングを使用してアカウント内およびアカウント間で特徴量を共有することもできます。
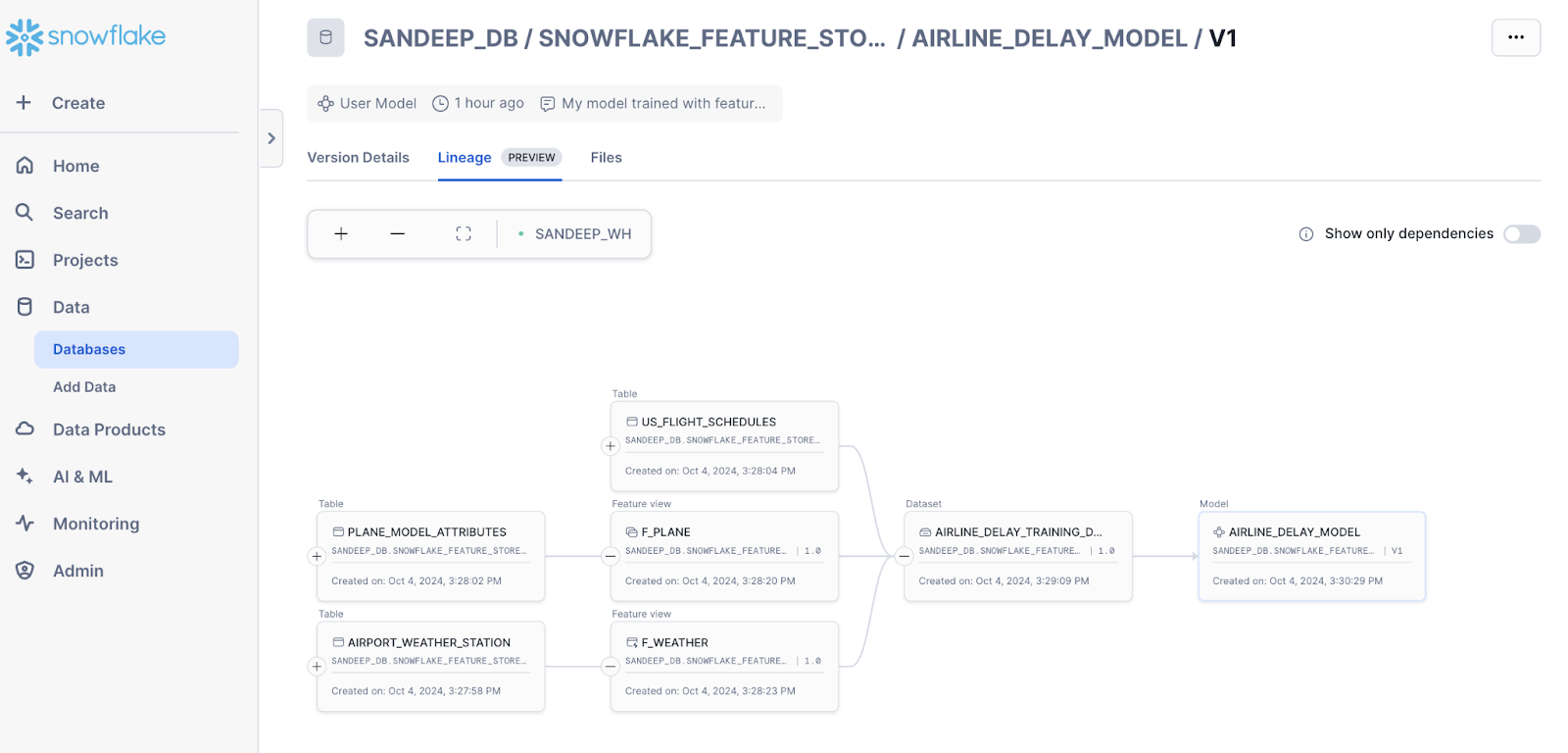
Snowflake MLには、特徴量ストアへの統合を備えた組み込みのMLリネージ機能(プレビュー提供中)が含まれています。これにより、ソースデータテーブル、特徴量ビュー、データセット、MLモデルなど、パイプライン内のすべてのMLアーティファクトの系統と、Snowflake Horizon Catalogが提供するすべてのデータ系統およびガバナンスを可視化できます。