
We are excited to announce the availability of data pipelines replication, which is now in public preview. In the event of an outage, this powerful new capability lets you easily replicate and failover your entire data ingestion and transformations pipelines in Snowflake with minimal downtime.
Turnkey data pipelines replication and failover
Snowflake provides a best-in-class experience for data engineering workloads. Thousands of customers leverage external stages, internal stages, Snowpipes, and storage integrations to develop ingest pipelines, which are critical to ensure that users and applications have access to the most recent, accurate data.
Being able to instantly failover and seamlessly resume data pipelines during an outage is critical for businesses that prioritize high availability and data integrity. Until now, customers either had to take on the tedious task of manually recreating these crucial objects or developing custom scripts. To achieve zero data loss, customers have to replay their data pipelines and ensure de-duplication of data in their application layer. These steps not only introduced complexity but also increased the likelihood of user errors occurring during an outage, leading to high recovery times, which is suboptimal for mission-critical workloads. Now, Snowflake will ensure you get idempotent loads even after you failover, so you can replay your pipelines with minimal effort.
This new functionality in Snowflake now enables the replication and failover of storage integrations, Snowpipe, internal stages, external stages, and load history. When you now failover to a secondary region due to an outage, your data pipelines will resume and continue to ingest data while guaranteeing idempotent loads, thereby allowing customers to achieve zero data loss. This further simplifies the business continuity experience in Snowflake by removing complex custom tooling and workarounds in place, and allows customers to achieve lower recovery point objective (RPO) and recovery time objective (RTO).
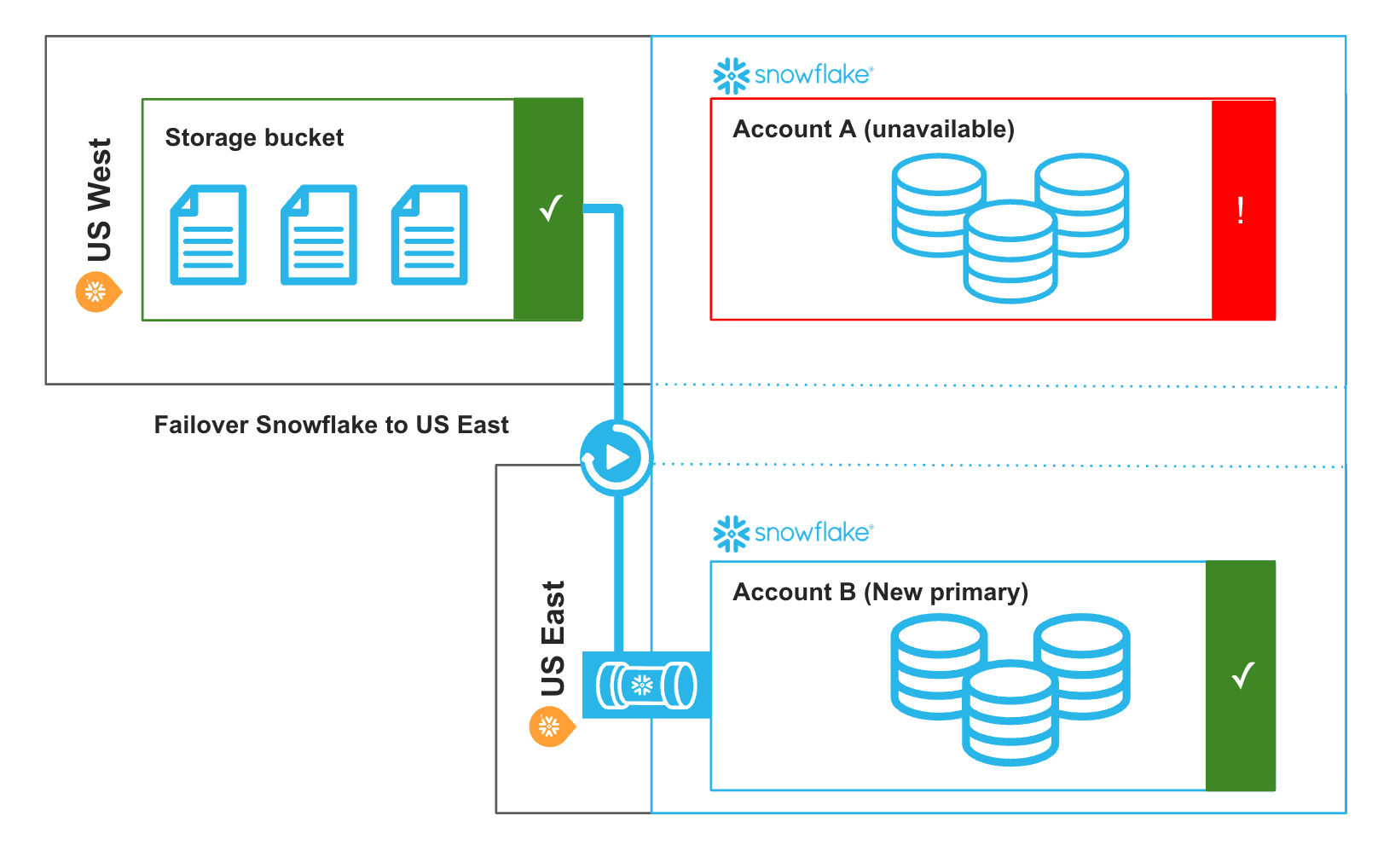
Let’s take an example where primary ‘Account A’ is in the US West region. This account has an auto-ingest pipe configured to continuously load data from the same storage bucket into a database in Snowflake. During normal operations, replication is configured to periodically replicate the pipeline objects from Account A to Account B (secondary in US East). When an incident occurs that impacts availability of Account A, you can now failover to your secondary Snowflake account that is located in US East. On failover, the auto-ingest pipe will automatically begin to load data with idempotent guarantees, ensuring zero data loss.
Snowflake is committed to further simplifying the cross-region and cross-cloud replication experience. With this new feature, Snowflake is making it easier than ever for customers to configure and operationalize replication at scale, allowing you to safeguard your critical workloads from outages. We can’t wait for you to try out this new feature and see how it can streamline your business continuity experience.
Get started
Data pipeline replication and failover is available in public preview in all Snowflake regions. To get started today, you can review the documentation here.






