이제 공개 미리 보기에서 제공되는 데이터 분류

참고: 이 내용은 2022. 2. 2에 게시된 컨텐츠(Data Classification Now Available in Public Preview)에서 번역되었습니다.
조직은 Snowflake에 고객 개인 정보와 같은 민감한 데이터를 믿고 맡깁니다. 이러한 정보를 적절하게 통제하는 것은 매우 중요합니다. 우선 조직에서는 어떤 데이터를 보유하고 있는지, 그 데이터가 어디에 있는지, 누가 그 데이터에 액세스할 수 있는지 알고 있어야 합니다.데이터 분류는 조직이 이러한 문제를 해결하는 데 도움을 줍니다. 하지만 조직은 이러한 데이터 분류에 어려움을 겪습니다. 느리고 오류가 쉽게 발생하는 수동 프로세스 또는 필요한 것보다 많은 것을 제공하고 지나치게 비싸며 추가 관리가 필요한 타사 도구에 의존하기 때문입니다. 반면 어떤 조직은 민감한 정보가 포함되어 있다고 의심되면 데이터에 자물쇠를 겁니다. 이로 인해 통찰력을 도출하고 고객의 필요를 충족하기 위한 데이터 분석 능력이 없어집니다. Snowflake의 데이터 분류는 기본적으로 민감하다고 여겨질 수 있는 개인 정보를 분류하여 이러한 문제를 해결합니다. 수동 프로세스나 타사 도구에 대한 의존성을 없앱니다. 또한 이는 다양한 Snowflake의 기본 거버넌스 기능과 통합됩니다. 따라서 고객 통찰력을 제어되고 통제되는 방식으로 도출하기 위해 데이터를 활용할 수 있습니다. 조직은 이를 통해 고객의 필요를 충족하는 동시에 신뢰를 얻을 수 있습니다.
오늘 저희는 데이터 분류가 이제 공개 미리 보기에서 제공됨을 발표할 수 있어 기쁩니다. 데이터 분류는 민감하다고 여겨질 수 있는 개인 정보를 위해 정형 데이터에 있는 열을 분석합니다. 또한 이러한 데이터를 분류하는 데 도움이 되도록 고객에게 사전에 정의된 Snowflake 시스템 태그를 제공합니다. Snowflake의 다른 거버넌스 기능과 함께 사용하면 조직은 고객의 개인 정보가 적절하게 통제되고 있음을 확실시할 수 있습니다. Snowflake의 분류는 플랫폼에 내장되어 있습니다. 따라서 추가 비용이 들지 않으며 추가 도구를 관리할 필요가 없습니다. 이를 통해 조직은 자체적인 데이터에 대해 알 수 있기에 제어되고 통제되는 방식으로 프로세스 속도를 높이고 분석 가치를 사용할 수 있습니다. Snowflake의 데이터 분류를 통해 분류되었다면 조직은 이 데이터에서 검색하기 위해 INFORMATION_SCHEMA에서 정의된 쿼리를 쉽게 실행할 수 있습니다. 또한 이를 Snowflake의 기본 데이터 거버넌스 기능에 포함되어 있는 역할 기반 정책으로 보호하고 액세스 기록으로 액세스를 감사할 수 있습니다.
“Snowflake의 데이터 분류는 저희가 전체 데이터 플랫폼에 걸쳐 PII 데이터를 더 믿을 만하게 관리하는 데 도움이 되었습니다!”
— Eric Jalbert, 선입 데이터 인프라 엔지니어, HomeX
작동 방법
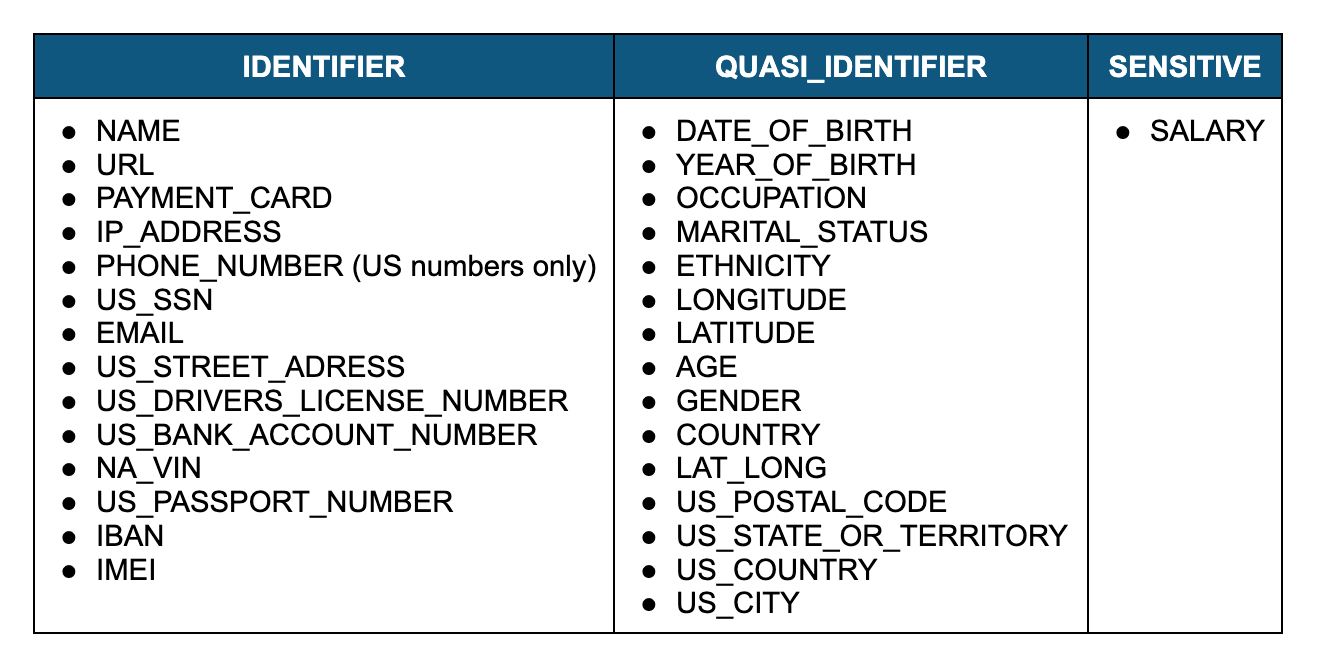
데이터 분류는 테이블에 있는 콘텐츠와 열 메타데이터를 분석합니다. 그런 다음 민감한 것으로 간주될 수 있는 개인 정보의 적절한 카테고리를 결정하는 데 도움이 되도록 이러한 정보를 사전 구축된 머신 러닝 모델에 제공합니다. 따라서 더 많은 보호나 제한된 액세스가 필요합니다. 또한 결과를 시스템 태그로 적용합니다. Snowflake는 계속해서 더 많은 카테고리를 추가할 것입니다. 따라서 고객에게 적은 양의 추가 입력으로 더 많은 기능을 제공합니다. 그런데 민감하다고 여겨지는 개인 정보는 무엇일까요? 이는 개인과 연결 지을 수 있는 모든 정보입니다. 민감도는 데이터와 잠재적인 위해에 따라 달라질 수 있습니다. 그룹화할 수 있는 네 가지의 일반적인 카테고리는 다음과 같습니다.
- 이름 및 전화번호와 같은 개인의 고유한 속성인 직접 식별자
- 성별 및 우편번호를 연령과 합치는 것처럼 합쳤을 때 개인을 식별하는 준식별자
- 신용 카드 또는 차량 공유 데이터와 같은 거래 및 시공간 패턴
- 개인을 식별하지는 않지만 질병 상태와 같이 개인이 공개하고 싶지 않아 하는 정보인 민감한 속성
Snowflake 분류는 직접 식별자, 준식별자 및 민감한 속성에만 집중합니다.
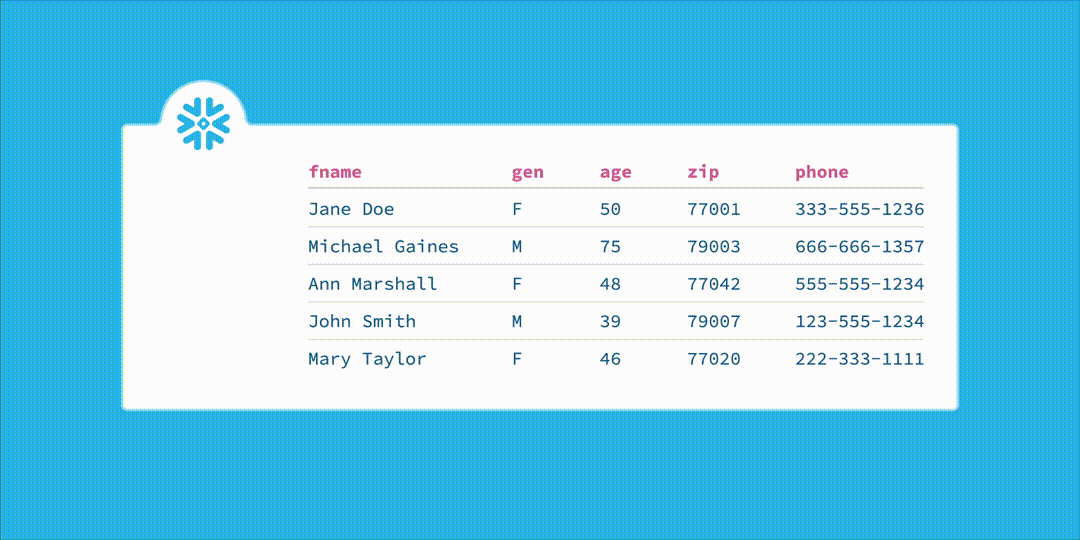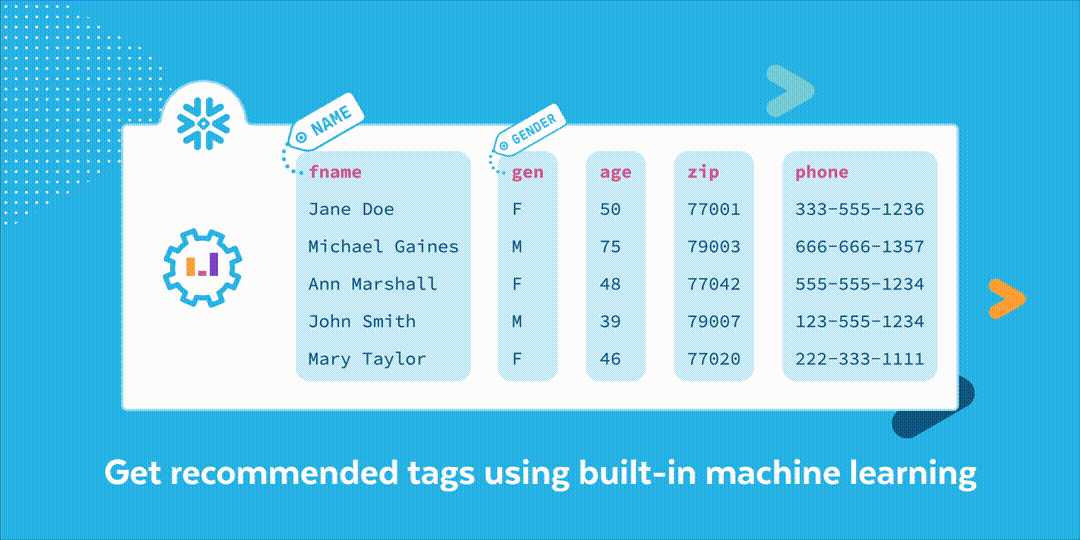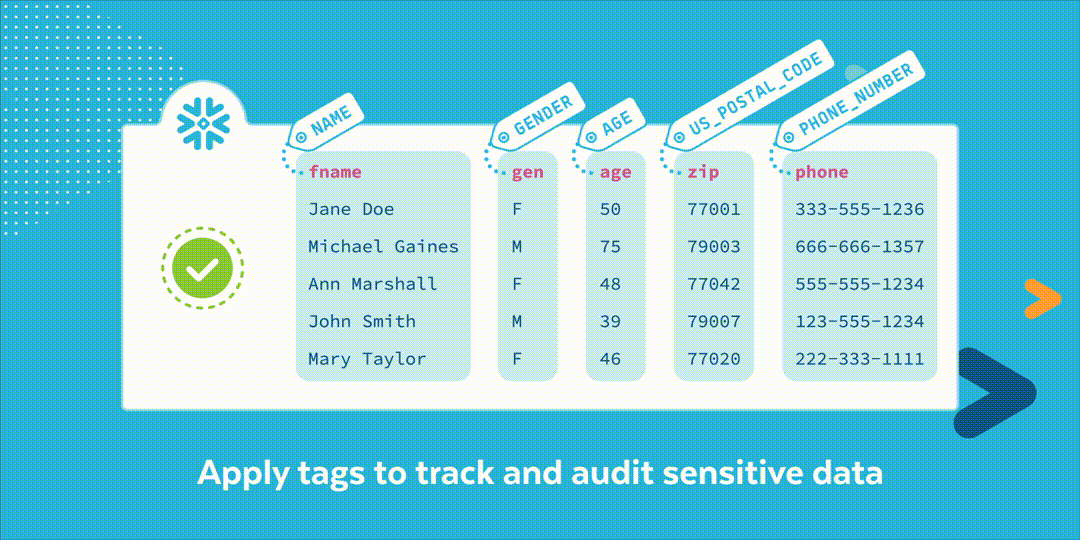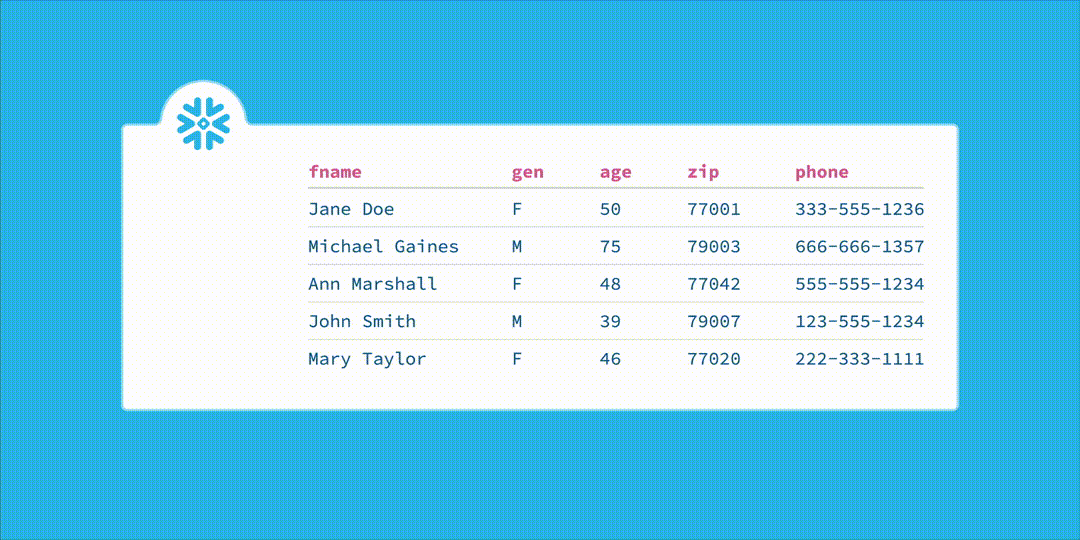
테이블 분석이 끝났다면 시스템 태그를 위한 값이 반환됩니다. 시스템 태그는 Snowflake에서 정의하고 Snowflake 데이터베이스 공유에서 제공되는 객체 태그입니다. 분류는 semantic_category 및 privacy_category와 같이 두 개의 태그를 사용합니다. 시맨틱 카테고리는 열의 셀에 포함된 내용과 관련되어 있습니다. 예를 들어 여기에는 이름, 성별, 연령, 전화번호 및 이메일이 포함됩니다. 개인 정보 보호 카테고리는 열에 포함되는 개인 정보의 종류와 관련되어 있습니다. 여기에는 식별자, 준식별자 및 민감한 것이 포함되어 있습니다.
분류는 또한 확률과 대체를 보고합니다. 확률은 분류가 정확할 가능성이며 대체는 우세한 일치를 찾을 수 없는 경우 기타 잠재적 일치를 나열합니다. 시스템에서 정의한 저장 프로시저를 사용하여 사용자는 결과를 보고 태그 적용을 결정할 수 있습니다. 이러한 태그의 값은 Snowflake에서 지원하는 카테고리 세트로 제한됩니다. 이러한 값은 단순히 Snowflake에서 정의한 객체 태그이기 때문입니다. 계정 사용량에 있는 Tag_References 및 태그 뷰와 같이 객체 태그와 관련된 모든 기능은 이러한 시스템 태그에도 적용됩니다.
데이터 분류가 끝났다면 조직은 Snowflake의 동적 데이터 마스킹과 같은 정책을 설정할 수 있습니다. 이를 통해 액세스가 필요한 사람에게만 권한이 부여됨을 확실시합니다. 액세스는 계정 사용량 뷰 Access_History를 쿼리하여 감사할 수 있습니다. GDPR 데이터 삭제 사용 사례를 위해 조직은 계정 사용량 뷰 Tag_References를 쿼리하여 예를 들어 이메일이 데이터에 존재할 수도 있는 모든 인스턴스를 찾은 다음 제공된 이메일을 삭제하기 위해 이메일과 같은 특정 열을 가진 객체를 찾을 수 있습니다.
예: 고객 PII 데이터 식별 및 보호
데이터 분류 작동 방법을 선보이기 위해 StyleMeUp이라는 가상 소매업체를 사용하겠습니다. StyleMeUp에는 방금 Snowflake로 로딩된 고객에 대한 여러 민감한 필드가 있습니다.
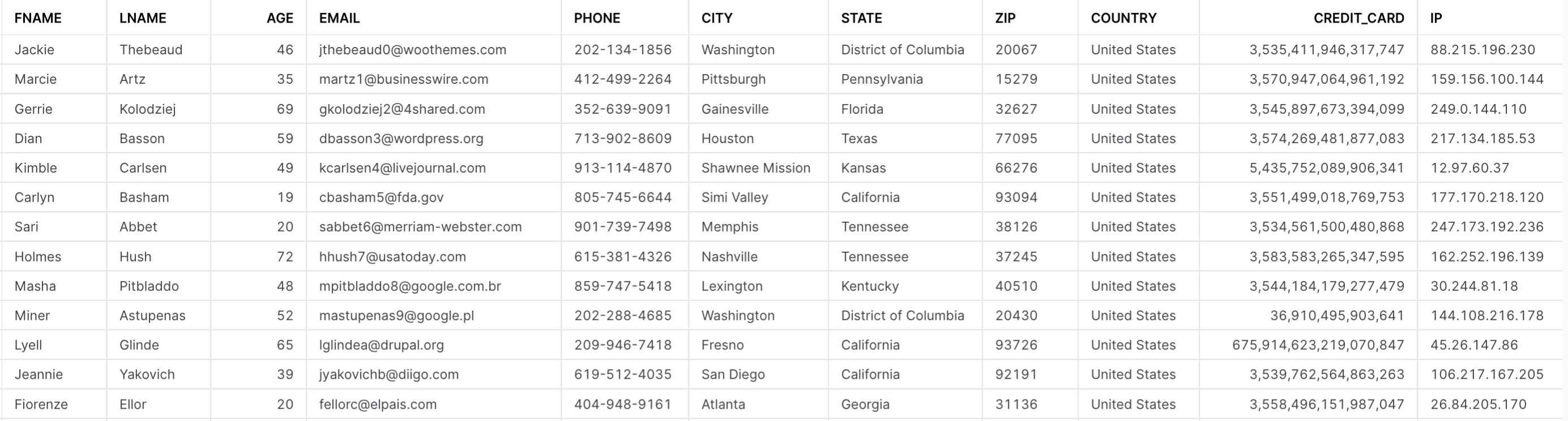
StyleMeUp은 이 데이터가 적절하게 통제되고 있는지와 올바른 인원만 필요한 필드에 대한 액세스가 있는지를 확실시하고자 합니다. 예를 들어 청구 부서는 StyleMeUp 고객의 이름, 주소 및 신용 카드 정보만 필요합니다. 우선 StyleMeUp은 보유하고 있는 정보를 알고 있어야 합니다. 따라서 Snowflake의 데이터 분류를 사용합니다.
다음 명령을 사용하여 StyleMeUp은 각 열에서 시스템 태그를 위한 추천 값을 받습니다.
결과는 단 몇 초 만에 JSON 형식으로 반환됩니다.

결과를 검토하고 수락했습니다. 따라서 시스템 태그, semantic_category 및 privacy_category가 다음 명령을 사용하여 위에 있는 각 열을 위한 값으로 적용됩니다.
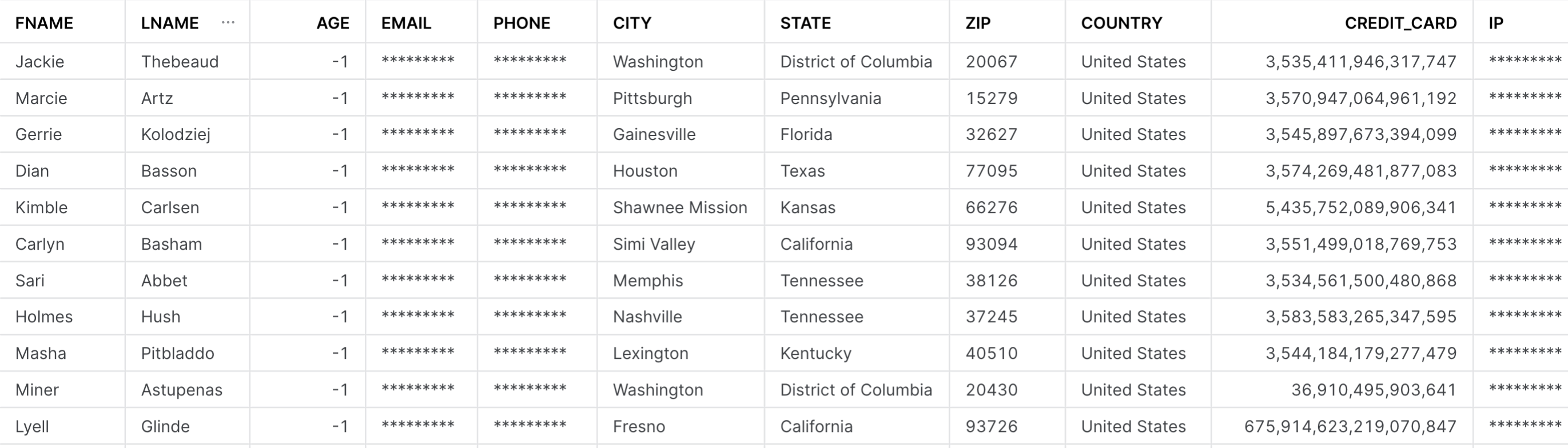
이제 StyleMeUp은 Tag_References view 뷰를 쿼리하여 어떤 열이 CUSTOMER_INFO 테이블에 있는지 확인할 수 있습니다.
StyleMeUp은 청구 부서가 마스킹되지 않은 FNAME, LNAME, CITY, STATE, ZIP, COUNTRY 및 CREDIT_CARD 열만 볼 수 있도록 이 테이블에 마스킹 정책을 적용할 것입니다.
또한 분류로 개인 정보 찾기가 더 쉬워집니다. 이는 GDPR 데이터 삭제 요청 충족을 지원할 수 있습니다. 예를 들어 StyleMeUp이 고객으로부터 [email protected] 이메일 주소와 더불어 자신의 데이터를 삭제해 달라는 요청을 받았습니다.
StyleMeUp은 Tag_References 뷰를 쿼리하여 이메일이 포함된 모든 테이블을 찾을 수 있습니다.

EMAIL로 분류된 열이 있는 하나의 테이블 CUSTOMER_INFO를 찾습니다. 그런 다음 StyleMeUp은 다음을 사용하여 테이블에서 요청된 정보를 삭제할 수 있습니다.
오늘 시작하십시오
이 빠른 시작 가이드에 따라 데이터 분류와 더불어 다양한 Snowflake의 기본 거버넌스 기능을 시도해 보십시오. 이 가이드는 Snowflake를 통한 PII 데이터 처리 및 보호 방법을 단계별로 안내합니다. 또한 제품 설명서는 여기에서 찾을 수 있습니다.
저자
