Guia avançado para ter acesso a insights geoespaciais no Snowflake
Nas três últimas publicações do blog voltadas para dados geoespaciais, apresentamos os conceitos básicos de dados geoespaciais, como eles funcionam no mundo mais amplo dos dados e como eles funcionam especificamente no Snowflake com base em nosso suporte nativo para GEOGRAPHY, GEOMETRY e H3. Esses artigos são ideais para ter um primeiro contato, se familiarizar aos poucos e talvez até mesmo despertar o interesse em você de se tornar um especialista no assunto. Há muito mais que você pode fazer com dados geoespaciais em sua conta Snowflake! No entanto, pode ser difícil ir de uma fase em que você diz: "Agora eu entendo os conceitos"; para uma fase em que você diga: "Como eu posso gerir os meus primeiros casos de uso?"
O mundo do processamento de dados geoespaciais é vasto e complexo, e estamos aqui para simplificá-lo para você. É por isso que criamos o Snowflake Quickstart para guiar você por vários exemplos de recursos geoespaciais em contextos reais. Embora esses exemplos usem dados representativos do Snowflake Marketplace ou dados que disponibilizamos gratuitamente para você no Amazon S3, eles podem ser aplicados à sua conta Snowflake, aos dados e aos casos de uso para fornecer insights valiosos à sua comunidade de usuários. Este blog mostra como fazer isso, mas confira o próprio quickstart se você quiser ver o código real.
Transformando os dados de localização em tipos de dados geoespaciais
Vamos começar com um resumo rápido: os dados de localização estão em toda parte. É bem provável que sua conta Snowflake tenha dados baseados no tempo. Do mesmo modo, é bem provável que sua conta Snowflake também tenha dados baseados em local, já que a maioria dos dados transacionais contém alguns elementos de quem, o que, quando e onde.
Em sua forma mais simples, os dados de localização são geralmente conhecidos como uma variedade de campos numéricos e de texto que contêm o que chamamos de endereços e incluem itens como ruas, cidades, estados, municípios, municípios, códigos postais (CEPs) e países. Para usuários humanos é bem fácil ler e entender essas linhas. No entanto, em formato de texto, elas são em grande parte apenas informações que buscamos quando precisamos delas e nada mais. Às vezes, esses campos de texto também podem ser acompanhados por campos de latitude e longitude. Esses campos são excelentes porque agora podemos fazer mais com os dados de localização (e colocá-los como ponto no globo terrestre). Isso é útil porque podemos integrar todos esses pontos no recurso de mapeamento de uma ferramenta de inteligência de mercado (business intelligence, BI) e mostrar a qual país ou território o ponto pertence, ou podemos integrar esses pontos em uma grade espacial como o H3. Embora vários parceiros de BI da Snowflake ofereçam suporte ao trabalho com dados de latitude e longitude, o Snowflake oferece suporte integrado para transformar seus dados de latitude e longitude em uma grade espacial H3, permitindo cálculo e visualização rápidos (como veremos mais adiante).
Mas podemos dar um passo à frente e transformar esses dados de latitude e longitude em um tipo de dado GEOGRAPHY ou GEOMETRY. Podemos usar o primeiro quando precisamos de uma representação do "globo" elíptico da Terra e o último quando precisamos de uma representação do "mapeamento" plano de um local mais localizado. Além disso, podemos criar esses tipos de dados com diversas funções.
Agora, isso pode não parecer muito, mas com esses dois tipos de dados, podemos começar a criar uma série de pontos em uma linha, conectar várias linhas em um polígono e representar locais complexos como uma série de linhas e polígonos. Podemos realizar cálculos complexos e associações de relacionamento entre esses tipos de objetos e começar a descobrir insights que não sabíamos que estavam disponíveis com um simples campo de "endereço". Você pode perguntar: "Mas e se eu tiver apenas o campo de endereço textual?" Nesse caso, damos boas-vindas à nossa primeira aventura: a geocodificação. "Geo-o quê??"
Geocodificação e geocodificação inversa
A geocodificação é o ato de levar seus dados de endereços textuais e transformá-los em um tipo geoespacial para descobrir casos de uso que de outra forma você não poderia oferecer. E, é claro, também é possível usar isso em outra direção, transformando seus tipos de dados geoespaciais menos legíveis em um conjunto de campos de localização mais legível para o ser humano. É possível realizar essas duas transformações com parceiros especializados da Snowflake, como a Mapbox e a TravelTime, que são Snowflake Native Apps disponíveis no Snowflake Marketplace. Recomendamos esses provedores para obter a geocodificação normal e inversa com mais precisão. No entanto, às vezes, você precisa equilibrar exatidão com o custo ou demonstrar o retorno do investimento (ROI) antes de poder investir dinheiro. Portanto, vamos falar sobre como começar a usar a geocodificação normal e inversa diretamente no Snowflake.
Neste caso de uso, usaremos dois conjuntos de dados do Snowflake Marketplace: Worldwide Address Data, uma biblioteca de dados de endereços globais aberta e gratuita; e um conjunto de dados de tutorial da nossa parceira CARTO, que tem uma mesa de restaurante com uma única coluna street_address. Se você fosse usar esse exemplo nos seus dados, a tabela de restaurantes do tutorial seria substituída por sua tabela. Será necessário realizar algumas preparações de dados nessas duas tabelas, o que você pode ver no quickstart.
A geocodificação de autoatendimento Snowflake inclui três etapas:
1. Usar um LLM para transformar uma cadeia de endereços completa em uma matriz JSON com suas partes como atributos. Nesta etapa, você usará a função SNOWFLAKE.CORTEX.COMPLETE, que usa um modelo Mixtral-8x7B hospedado pelo Snowflake para realizar a conversão usando um conjunto detalhado de instruções que você fornece como parte da chamada funcional. Consulte o quickstart para escolher o tamanho adequado de armazenamento para executar essa função em escala.
2. Criar uma coluna simples de latitude e longitude geoespacial no Worldwide Address Data.
- O ST_POINT é usado para criar a coluna geoespacial a partir da latitude e da longitude.
- Os dados desnecessários são removidos da tabela Worldwide Address Data com base em valores de latitude e longitude inadequados.
3. Usar JAROWINKLER_SIMILARITY para confirmar os endereços. Para isso, será necessário unir as duas tabelas em algumas colunas, relacionando a coluna de nomes de rua a uma função JAROWINKLER_SIMILARITY, pois não é de se estranhar que os nomes de ruas tragam pequenas diferenças dependendo da fonte. Por isso, definimos “95” como o nosso limite de similaridade na chamada de função.
É importante observar aqui que esse método não tem uma precisão perfeita. O quickstart mostra mais detalhadamente o nível de precisão alcançado e algumas das razões por que esse método não é perfeito. No entanto, é importante notar a diferença de custo entre esse método e um serviço de geocodificação dedicado. Esse método é uma ótima forma de atender às necessidades mais simples ou criar protótipos que justifiquem serviços de geocodificação mais dedicados com requisitos mais complicados.
Para realizar geocodificação inversa ou produzir um endereço a partir de um tipo de dado geoespacial, vamos criar um procedimento armazenado que faça três coisas: cria uma tabela de resultados, seleciona linhas que não foram processadas e encontra o endereço mais próximo correspondente usando um loop com uma pesquisa de raio crescente até encontrar um resultado. Você pode executar esse procedimento do mesmo modo que todos os procedimentos no Snowflake, passando os argumentos apropriados como definidos no topo do código do procedimento, que você pode ver no quickstart.
Incluir geocodificação aos dados de endereços adiciona mais potencial para o uso desses dados de modo mais relevante. Vamos descobrir como você pode usar esses dados geocodificados.
Previsão com dados geoespaciais
A previsão é uma atividade comum com os dados de séries temporais, já que existem modelos confiáveis de ML desenvolvidos para inserir dados históricos e prever uma janela de dados futuros com base em tendências históricas. O Snowflake inclui um modelo integrado de previsão de ML chamado SNOWFLAKE.ML.FORECAST que pode ser facilmente usado para essa atividade. Embora seja possível fazer previsões de séries temporais em qualquer dado baseado no tempo, enriquecer essa previsão com dados de localização adiciona outra dimensão de valor ao processo de previsão.
Existem dois conjuntos de dados usados no quickstart: dados de corridas de táxi da cidade de Nova York fornecidos pela CARTO e dados de eventos fornecidos pela PredictHQ. Você pode considerar os dois conjuntos de dados da seguinte forma: os dados de corridas de táxi são como qualquer outro dado baseado em séries temporais que você tenha sobre algo que acontece em um momento e lugar determinados. É provável que você tenha esse tipo de dados em sua organização. Os dados do evento adicionam mais contexto a um elemento baseado no tempo nos seus dados. Neste exemplo, os dados de eventos podem informar qualquer aumento ou redução no número de corridas de táxi esperado na cidade de Nova York. Outros tipos de dados contextuais que você pode ter incluem períodos abertos ou fechados, períodos promocionais recorrentes, eventos públicos, entre outros. Seja o que for, os dados contextuais podem ajudar a adicionar mais precisão a uma previsão, já que melhora, qualquer dia/hora com uma expectativa crescente ou decrescente.
A atividade de previsão inclui quatro etapas:
1. Usar uma grade espacial para calcular uma série temporal de embarques de passageiros de táxi para cada célula da rede.
Você usará a grade espacial H3 para dividir Nova York em células com base na localização de embarque.
É possível localizar um local de embarque dentro de uma célula, transferindo a latitude e a longitude e convertendo-o em uma célula H3.
Depois, é possível agregar o número de locais de embarque em cada célula da cidade de Nova York por horas do dia usando as funções TIME_SLICE e H3_POINT_TO_CELL_STRING do Snowflake.
Por fim, você precisará "preencher" as distâncias por hora em um local com 0 (zero) registros de embarque. Isso é necessário para a previsão de séries temporais.
2. Enriquecer os dados da série temporal por hora com dados de eventos.
Isso adiciona colunas de “recursos” aos dados acima, marcando cada linha como um feriado escolar, feriado público ou evento esportivo com base na participação nos dados do evento.
Cabe notar que você pode adicionar qualquer outro “recurso” que faça sentido aos dados do evento. Feriados escolares, feriados públicos e eventos esportivos são apenas exemplos realistas desse cenário.
3. Criar um modelo, um conjunto de dados de treinamento e um conjunto de dados de previsão.
Antes de realizar previsões, o modelo SNOWFLAKE.ML.FORECAST requer uma etapa de treinamento. Assim, os seus dados da Etapa 2 precisam ser divididos em duas tabelas de cada vez: uma para treinamento e outra para previsão.
A partir daí, você criará um modelo, com uma das entradas sendo a tabela de dados de treinamento que estabeleceu acima. Você também identificará colunas-chave, como a coluna do tempo, a métrica a ser prevista e, neste caso, os dados de localização que deseja fazer a previsão.
4. Executar o modelo e visualizar a precisão das previsões.
Após o treinamento do modelo, ele pode ser chamado, indicando outro conjunto de dados a ser usado para previsão.
As previsões podem ser transmitidas para uma tabela e depois comparadas aos dados reais para avaliar a precisão. É possível fazer isso de várias maneiras, mas o quickstart sugere o uso de um symmetric average absolute percentage error (SMAPE).
O gráfico a seguir mostra como é o resultado dessa comparação em uma célula H3, com o modelo de previsão tendo uma taxa de precisão bastante alta:
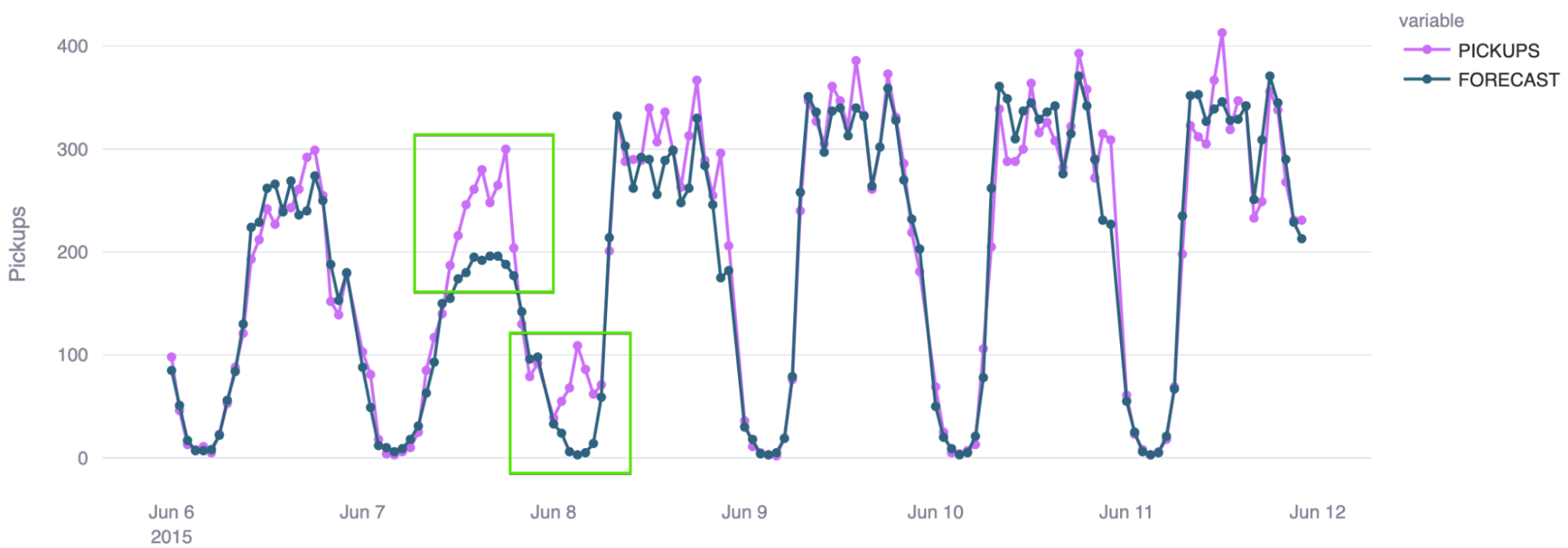
A previsão de séries temporais no Snowflake pode ser uma ferramenta eficaz e pode ser aprimorada ainda mais por sua capacidade de agrupar locais em uma determinada célula em uma grade espacial e prever essa célula, em vez de tentar prever cada local individualmente, o que é demasiado granular.
Usar a H3 para visualizar sentimento por localização
No exemplo de geocodificação acima, você usou um LLM para ajudar a transformar os dados em um formato diferente, mas também pode usá-lo para avaliar dados textuais com base na positividade ou negatividade da linguagem usada no texto. Isso é valioso para avaliar o sentimento das pessoas em uma determinada situação, seja como feedback em relação a produtos ou serviços ou o nível de visualização favorável da sua marca. O segredo para isso é que você pode transformar o texto bruto em uma medição ordinal e, em seguida, analisar se há fatores de localização nessa medição. Vamos ver como podemos fazer isso no Snowflake.
Do ponto de vista dos dados, três itens principais são necessários:
Um evento ou uma transação de algum tipo
Comentário em texto bruto sobre o evento
A localização desse evento
Tudo isso pode estar em um único sistema (por exemplo, os clientes realizam um pedido em um app e comentam sobre seu nível de satisfação com o processo de encomenda) ou em diferentes sistemas (por exemplo, um cliente faz um pedido de um produto e depois publica nas redes sociais sobre o quanto gostou do produto que recebeu). O quickstart usa dados sintéticos de entregas, nos quais inclui o feedback do cliente sobre como foi a experiência de entrega.
A visualização desse feedback por localização envolve duas etapas:
1. Avaliar o sentimento de feedback sobre cada entrega.
Primeiro, você usará o SNOWFLAKE.CORTEXT.COMPLETE como antes, mas desta vez, a instrução que você está dando ao LLM é avaliar o texto e atribuí-lo com uma etiqueta de categoria textual, como "Very Positive".
Em seguida, você converterá esses rótulos de categoria textual em números que poderão ser agregados em várias entregas em uma área comum.
2. Visualizar o sentimento agregado por localização usando H3.
Em vez de pré-calcular as pontuações de localização como fizemos na previsão de séries temporais, vamos criar um app que vai agregar pontuações de sentimento às células H3 em execução.
O Streamlit app usará ST.PYDECK_CHART para planejar e colorir as células H3 com base em dados quantitativos de sentimento.
Veja um exemplo de análise de percepção por localização das lojas:
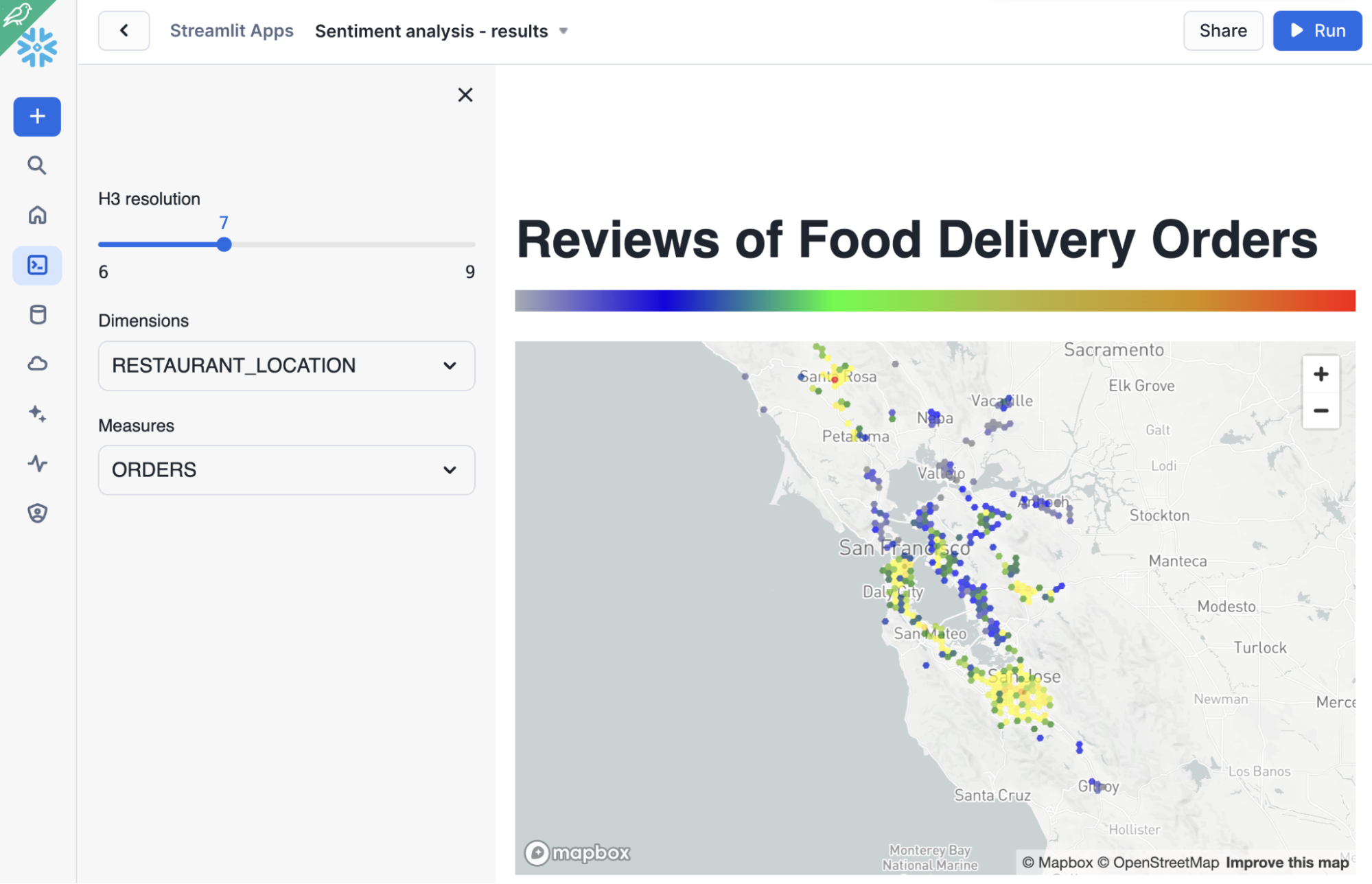
Mas, o mais importante é que o app permite explorar os dados de forma mais livre, pois estamos calculando tudo em tempo real. Como isso funciona? Veja a imagem em destaque abaixo:
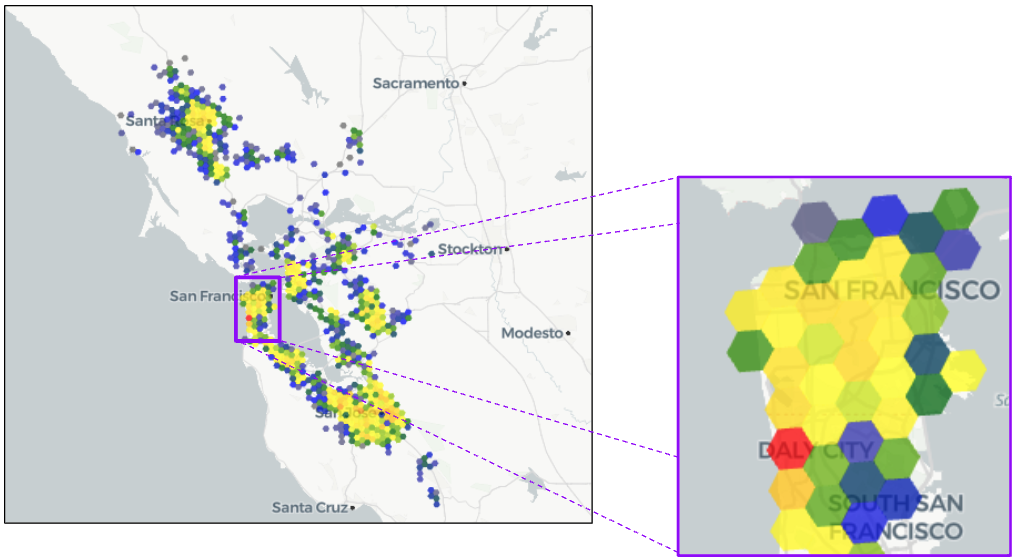
E se quisermos ter uma visão mais refinada da península de São Francisco? Usar o cursor do app para mudar a resolução H3 de 7 para 8 nos dá uma imagem mais clara:
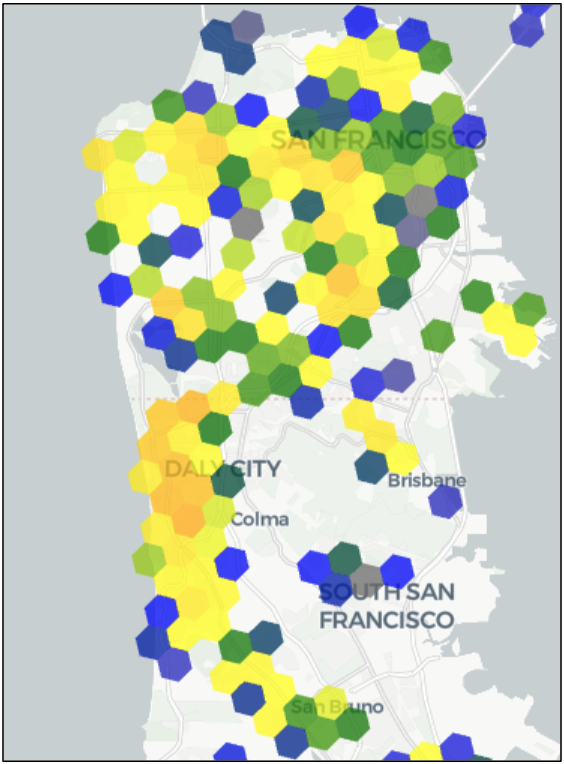
Agora, podemos ver mais claramente onde estão as falhas, os pontos fortes e as áreas de preocupação. Contar com esse recurso em tempo real para obter mais resolução de localização é como passar de uma TV SD para uma TV HD, uma TV de 4K para uma TV de 8K. Isso é como ter uma imagem mais clara do que estamos tentando ver.
H3 é um método rápido e avançado de obter clareza sobre a localização das métricas. E ao combiná-lo com um LLM, podemos transformar texto não adicional em um resultado mensurável. Esse é um recurso extremamente eficaz, e você pode aplicá-lo de várias maneiras dentro da sua organização!
Análise de vizinhos mais próximos com varreduras (raster) e shapefiles
Embora muitas empresas obtenham seus dados de localização de fontes de dados padrão de onde outros dados também vêm, aqueles que trabalham profundamente com dados geoespaciais sabem que os dados também podem vir de formatos e arquivos especializados. Para os não iniciados, um resumo rápido é que a maioria dos dados geoespaciais abordados neste e em outras publicações de blog até o momento são dados vetoriais (ponto, linha e polígono). Um formato comum usado para armazenar dados vetoriais em um arquivo é um shapefile, mas os shapefiles geralmente são abertos com aplicações de GIS dedicados, não lidos por bancos de dados. Os dados de varreduras diferem dos dados vetoriais em que são representados como uma grade de células (cabe pensar em uma imagem pixelada). Geralmente, os dados de varreduras são armazenados em arquivos GeoTIFF, que, uma vez mais, não são normalmente lidos por bancos de dados. Cada vetor e varredura têm seus casos de uso próprios e, às vezes, você precisa acessar ambos. O quickstart lida com isso, sem complicações.
Nesse cenário, usaremos duas fontes de dados, um mapa de altitude armazenado como uma varredura GeoTIFF e dados de temperatura/precipitação armazenados em um shapefile, para usar os dois conjuntos de dados para prever a presença de águas subterrâneas. No entanto, na realidade, esses são apenas arquivos representativos para mostrar como podemos acessar esses tipos de arquivos no Snowflake e, enfim, usá-los em uma análise específica. Se você tiver GeoTIFF ou shapefiles em sua organização, poderá usar esses métodos para levar seus dados ao Snowflake.
A combinação dessas duas fontes de dados para realizar uma análise dos dados mais próximos envolve três etapas:
1. Carregar o arquivo GeoTIFF.
Você usará a biblioteca Rasterio Python para criar funções que extraem os metadados de GeoTIFF, avaliar as faixas presentes no GeoTIFF e, por fim, ler e converter o centroide cada pixel em dados vetoriais (pontos).
Depois, avaliar os metadados e converter os pontos em um tipo de dados no SRID adequado.
Por fim, você reduz o grande número de pixels para um tamanho mais gerenciável convertendo os pontos em células H3.
2. Carregar o shapefile.
Você usará a biblioteca Fiona Python e o recurso Dynamic File Access do Snowflake para criar funções que leem os metadados e os dados do shapefile.
A partir daí, você avaliará a natureza dos dados do shapefile e como eles são representados para que possa criar uma consulta para carregá-la em uma tabela com as colunas e os tipos de dados certos.
Assim como na Etapa 1, você reduz o número de linhas para um tamanho mais gerenciável convertendo os pontos em células H3.
O quickstart também mostra uma maneira alternativa de visualizar esses dados, mas é uma etapa opcional.
3. Calcular o ponto climático mais próximo de cada ponto de elevação, usando um dos dois métodos descritos no quickstart.
Observação: cada método envolve a filtragem de duas tabelas até a área de foco, como descrito no quickstart.
O primeiro método é autônomo dentro do Snowflake e requer uma consulta que combina ST_DWITHIN com uma função de janela QUALIFY. No entanto, esse método pode requerer processamento intenso.
O segundo método envolve o uso do SedonaSnow Snowflake Native App, que dá acesso à função ST_VORONOIPOLYGONS. Os polígonos de Voronoi podem ser uma maneira mais eficiente de agrupar pontos mais próximos uns aos outros, mas para obter acesso a uma função desse tipo, você precisará instalar o app SedonaSnow.
Não é raro no mundo dos dados geoespaciais precisar acessar dados de arquivos não tradicionais. Felizmente, a flexibilidade do Snowflake permite trabalhar com esses arquivos e ainda assim acessar esses dados valiosos para suas análises.
Mapas interativos
Também é comum no mundo do GIS interagir com interfaces de usuário desenvolvidas para dados de localização. Essas aplicações vão além do que normalmente é possível realizar em uma ferramenta de inteligência de mercado (BI) para apresentar mais dados com recursos sofisticados de camada e outras interações específicas de localização. Uma ferramenta de código aberto é chamada de Kepler.gl.. No entanto, em vez de ter que implementar sua própria Kepler.gl, você pode simplesmente instalar o Dekart no Snowflake Marketplace e ter acesso imediato à Kepler.gl e aos recursos mais avançados de visualização de localização da ferramenta. Executar Kepler.gl em um Snowflake Native App usando o Snowpark Container Services também garante que seus dados nunca saíam do Snowflake. Vamos ver um exemplo do quickstart.
Neste caso de uso, vamos criar um mapa interativo para ver a densidade de estações de carregamento de veículos elétricos (EV), que vai identificar áreas onde talvez valha a pena adicionar mais estações. Esse exemplo requer que você combine três conjuntos de dados: fronteiras de países, rotas de transporte e locais (carregadores de EV, por exemplo), mas é possível substituir facilmente as rotas de transporte e os locais das estações de EV por outros dois conjuntos de dados de localização na sua organização. Depois de seguir a configuração no quickstart, você realizará as três ações a seguir.
Usar uma consulta para definir uma camada de delimitação:
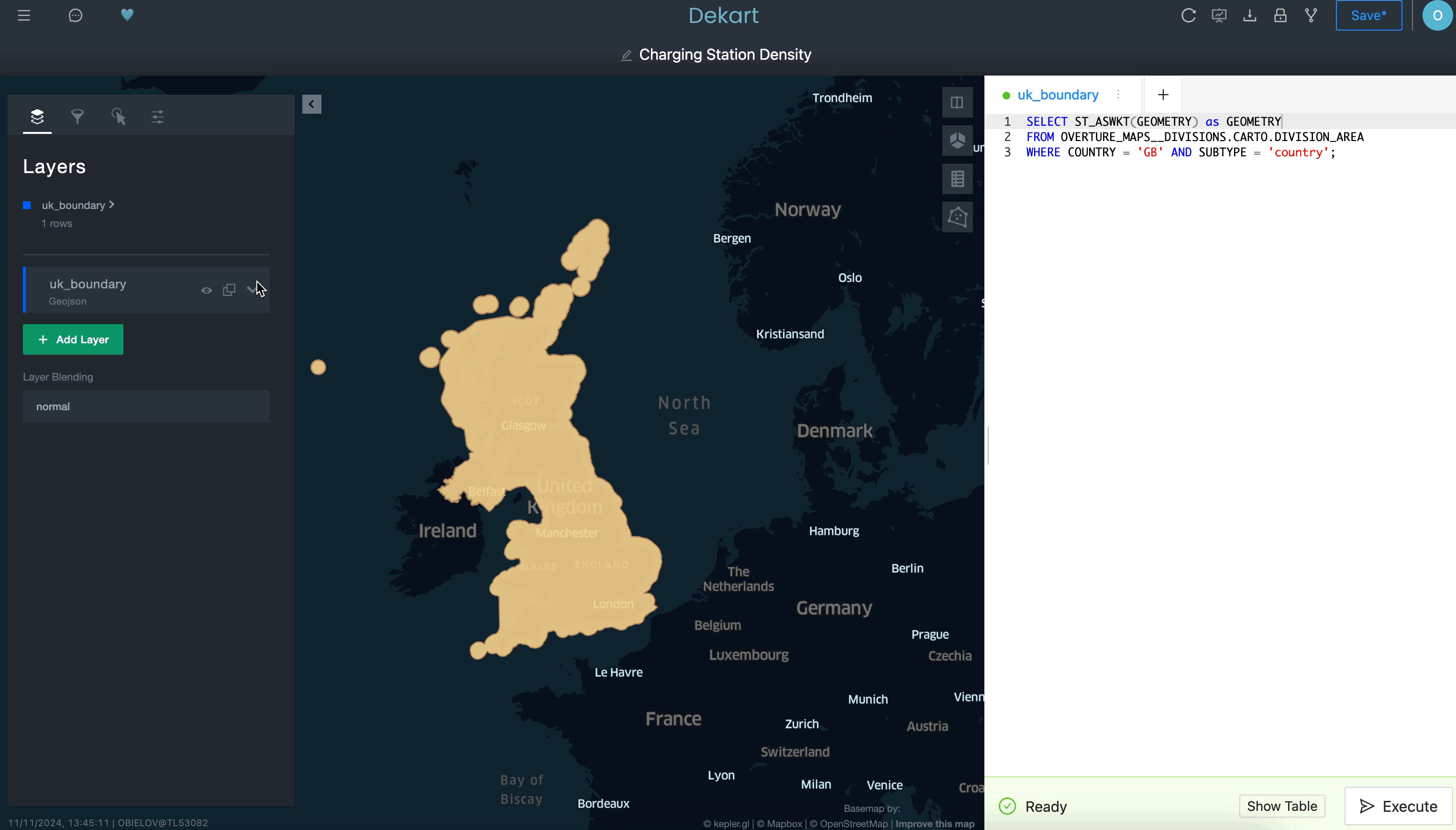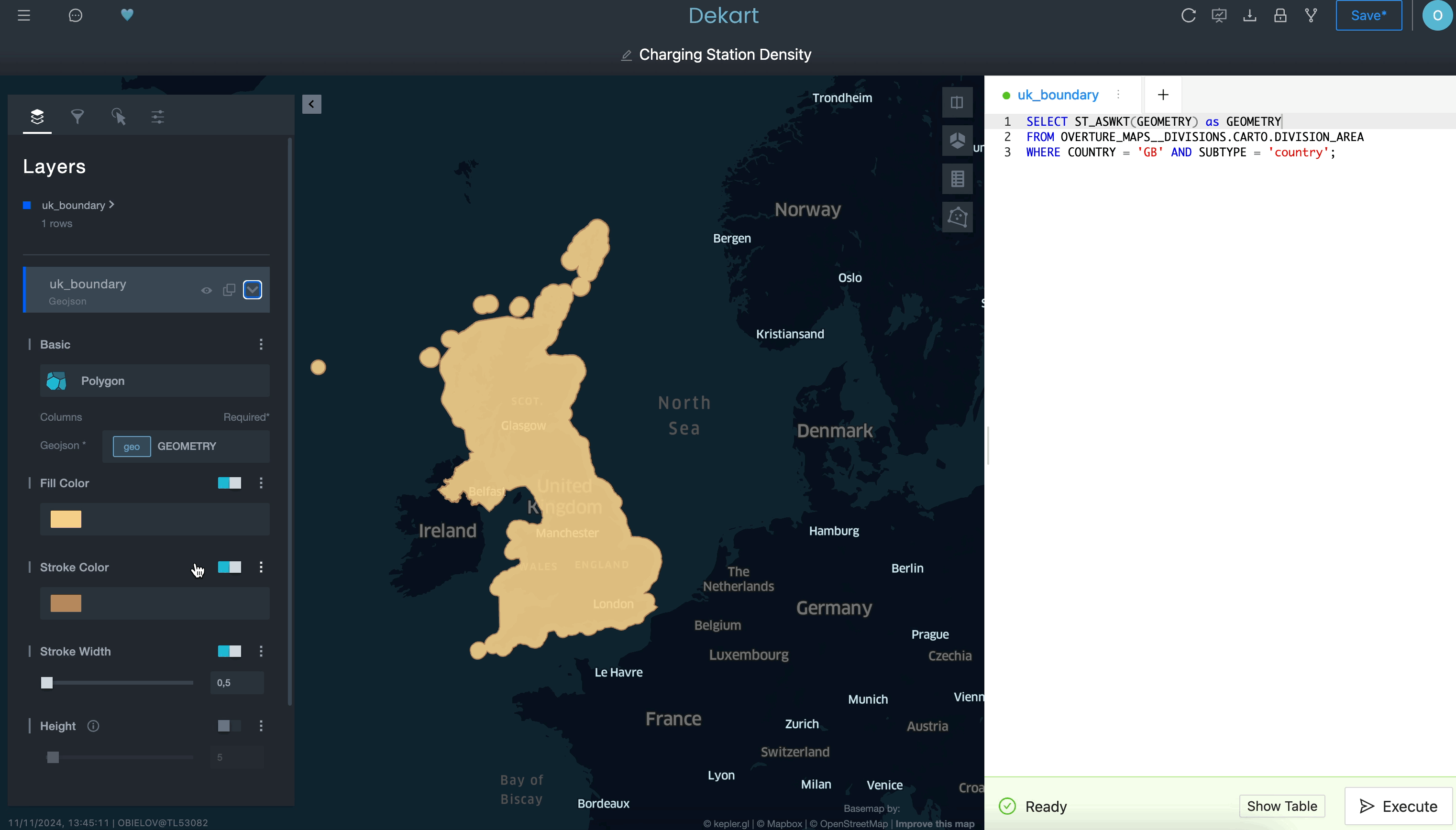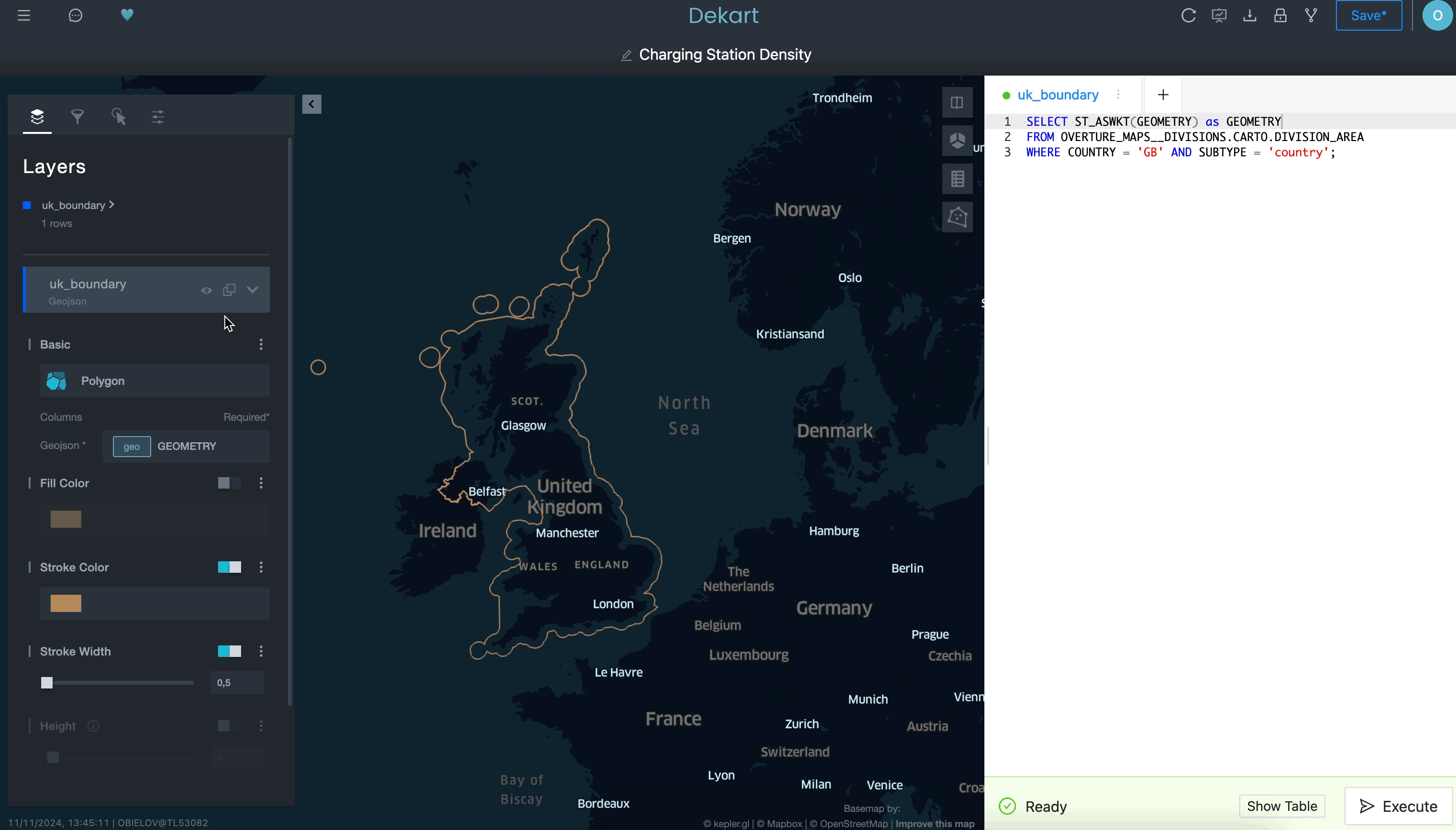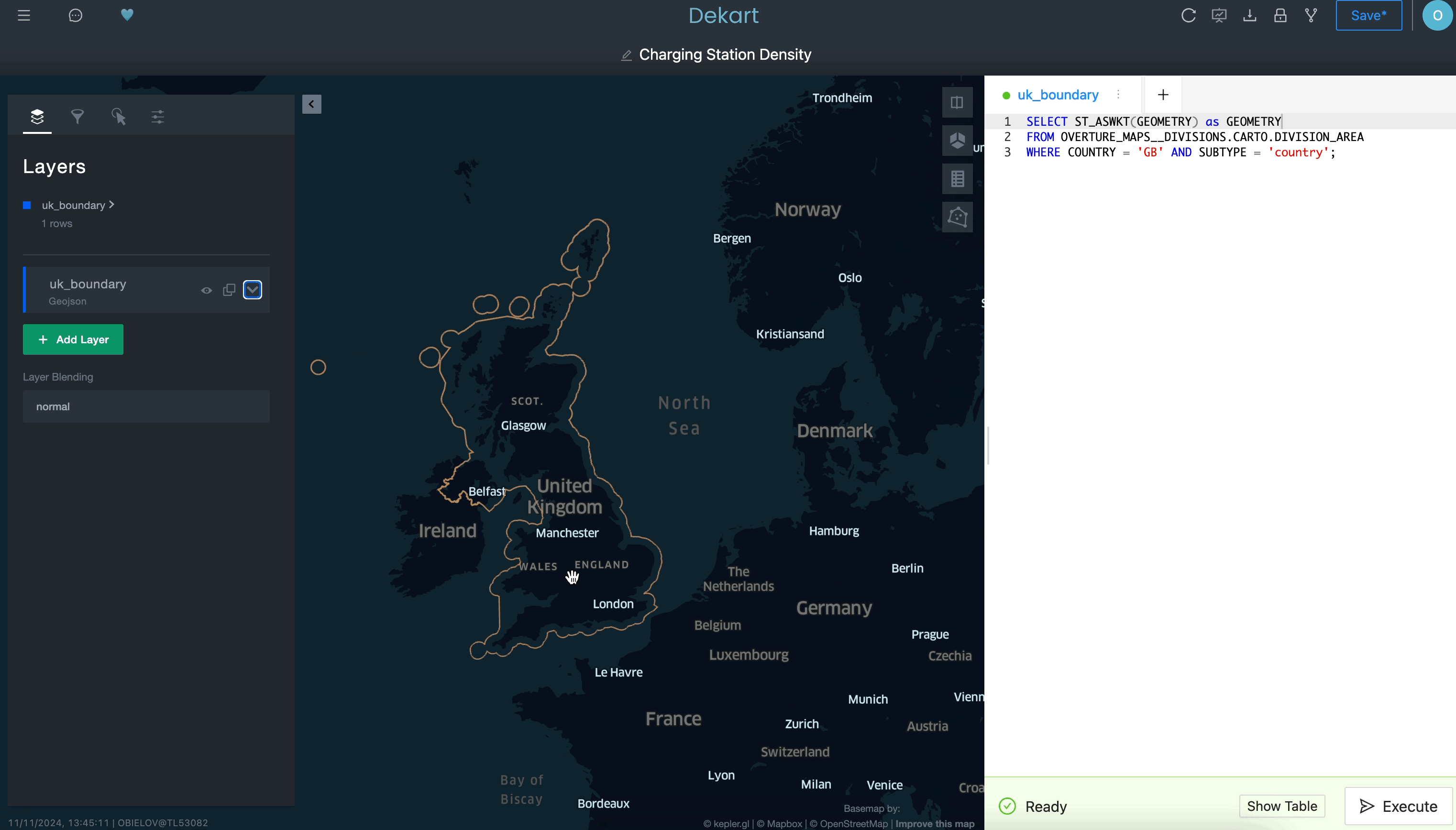
Usar uma segunda consulta para recuperar as rotas de transporte como uma segunda camada:
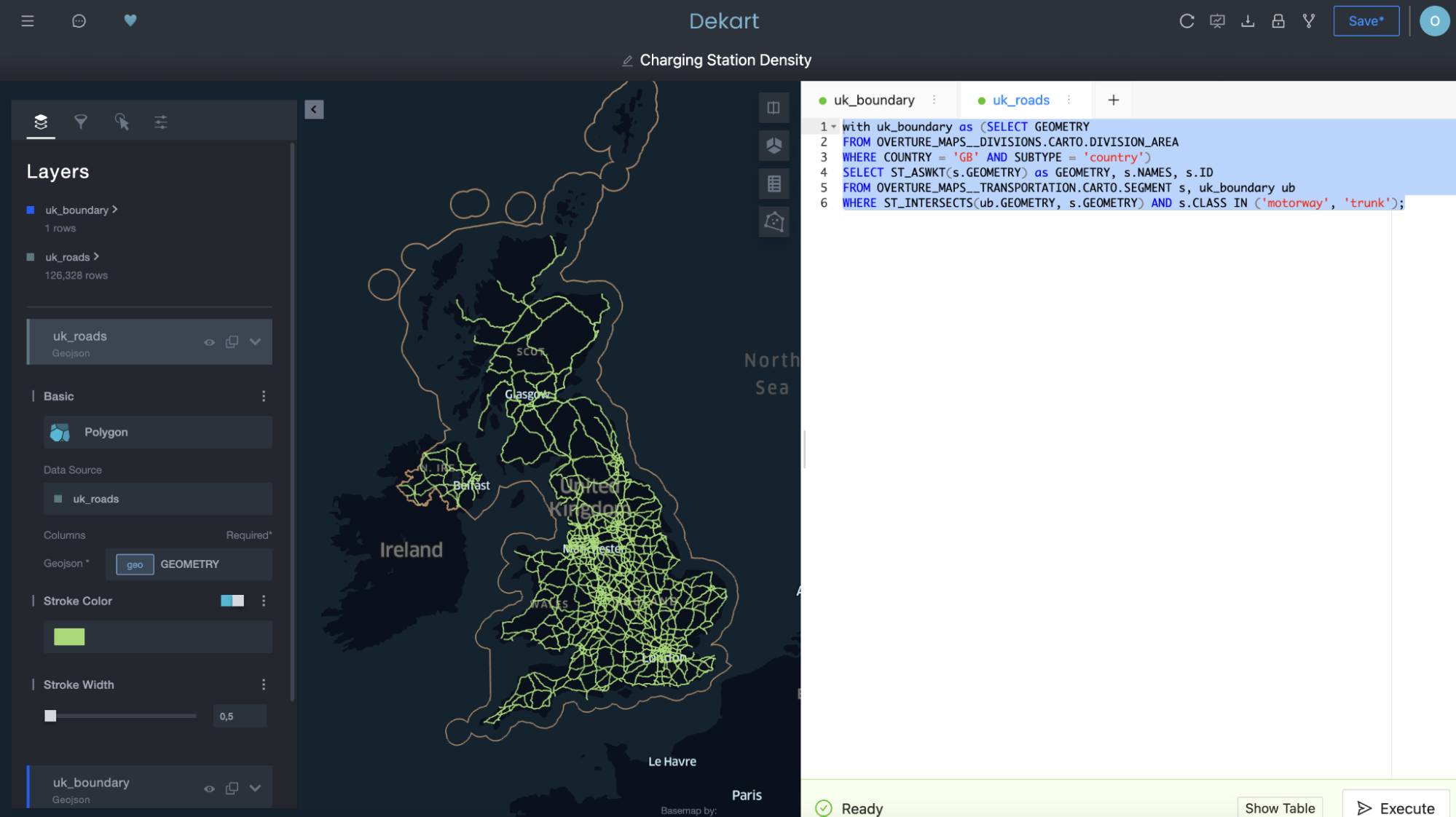
Note acima como “uk_roads” foi adicionado como uma camada no lado esquerdo da interface de usuário da Kepler.gl.
Em seguida, use uma terceira consulta para indicar as estações de carregamento de EV como outra camada:
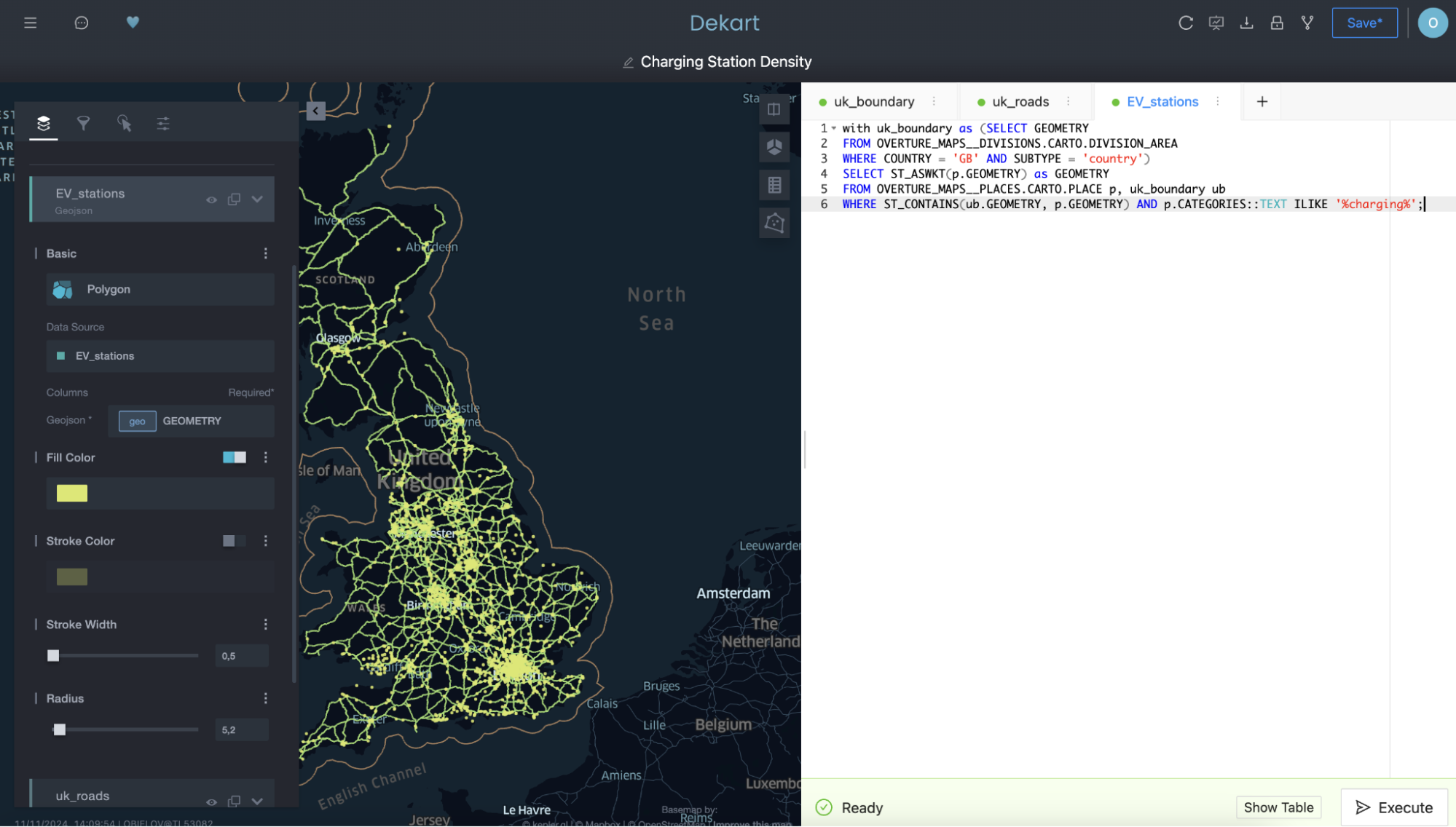
Note nas segundas e terceiras consultas como você está referenciando a consulta para a primeira camada por nome na cláusula FROM como um meio de filtrar as segundas e terceiras consultas, selecionando apenas as rotas e as estações de carregamento existentes dentro do limite da primeira delimitação.
Por fim, pode ser adicionada uma quarta consulta para calcular a densidade das estações de carregamento de EV, contando o número de carregadores de EV num raio de 50 quilômetros para cada segmento de estrada:
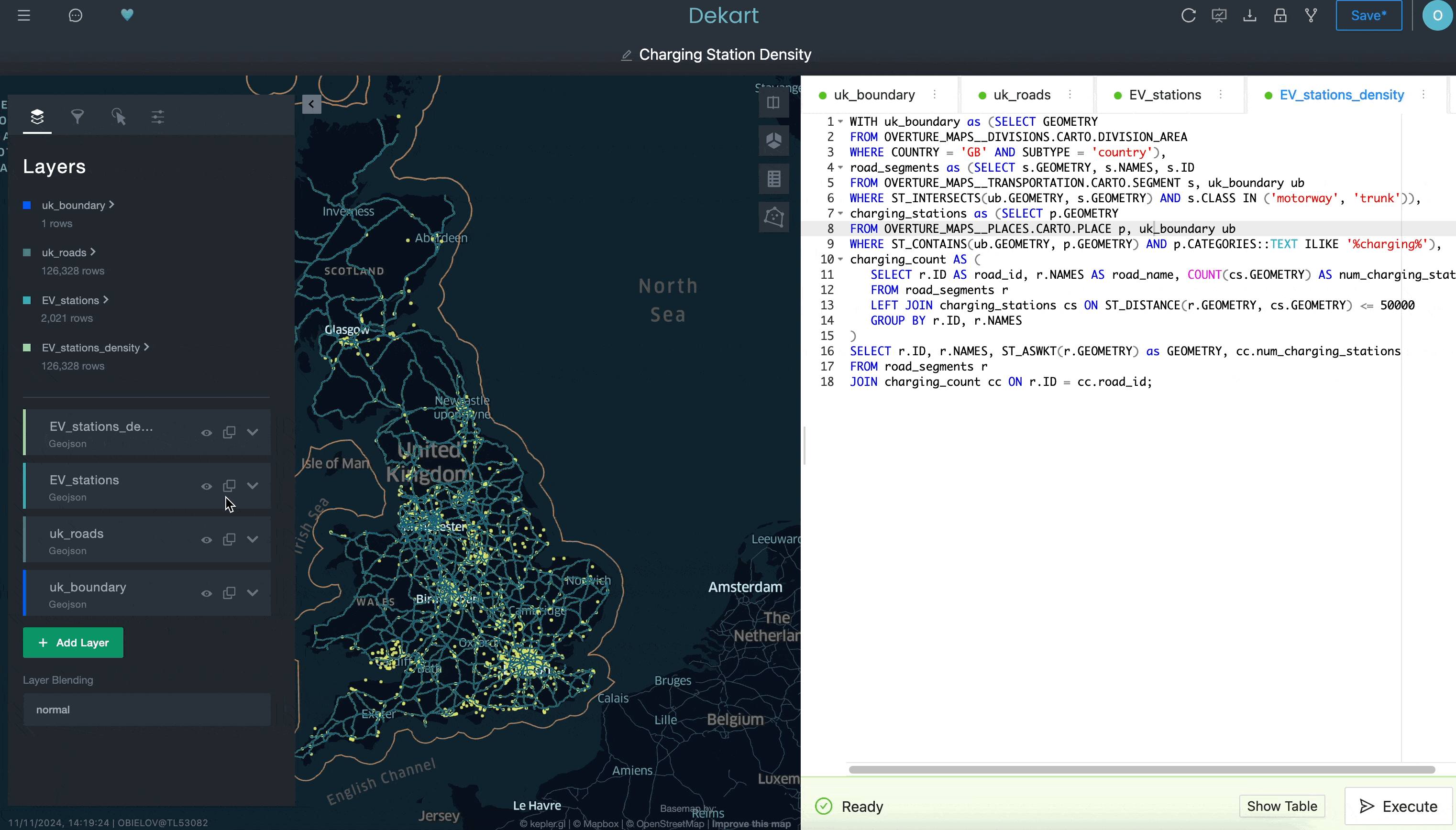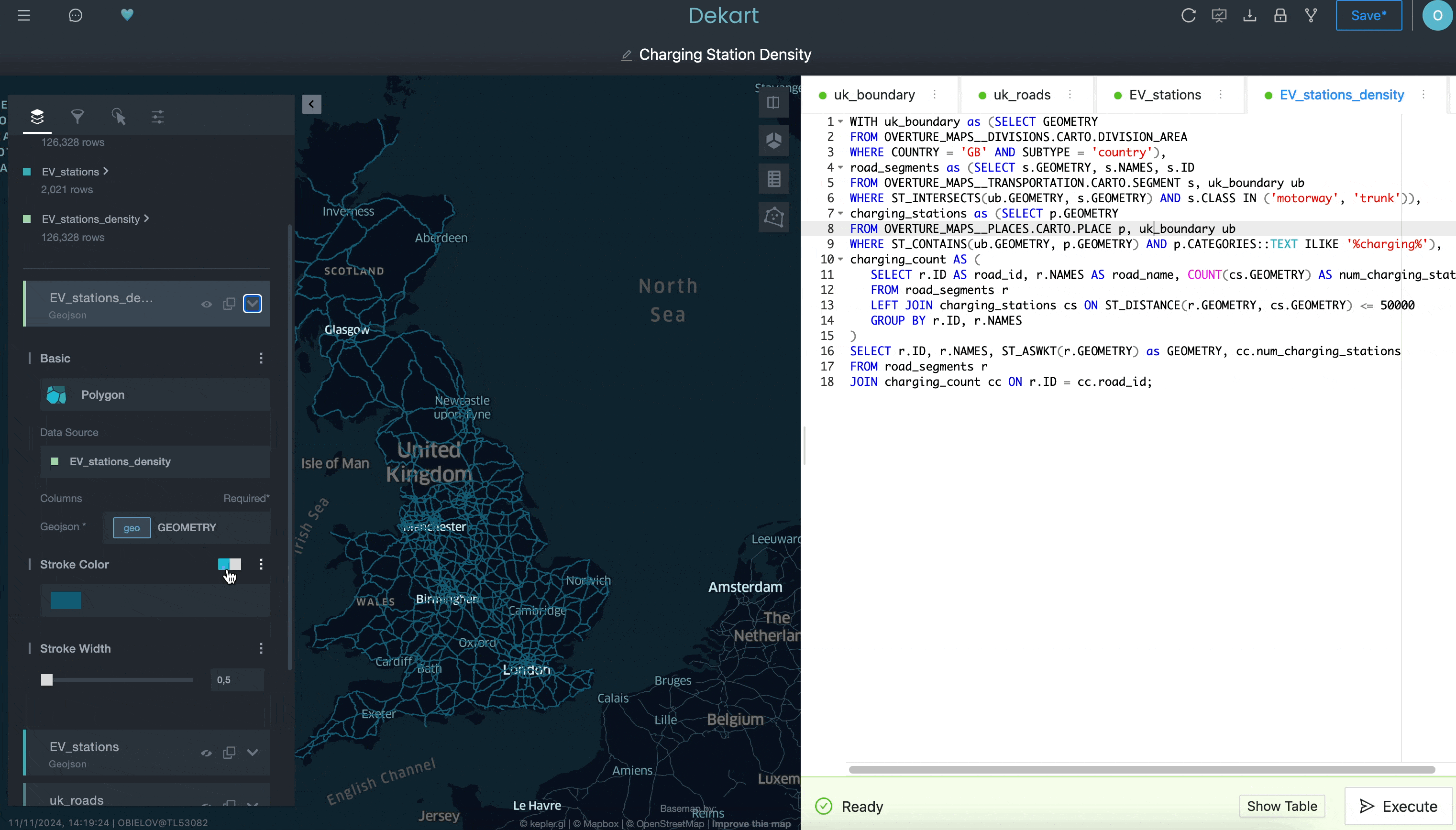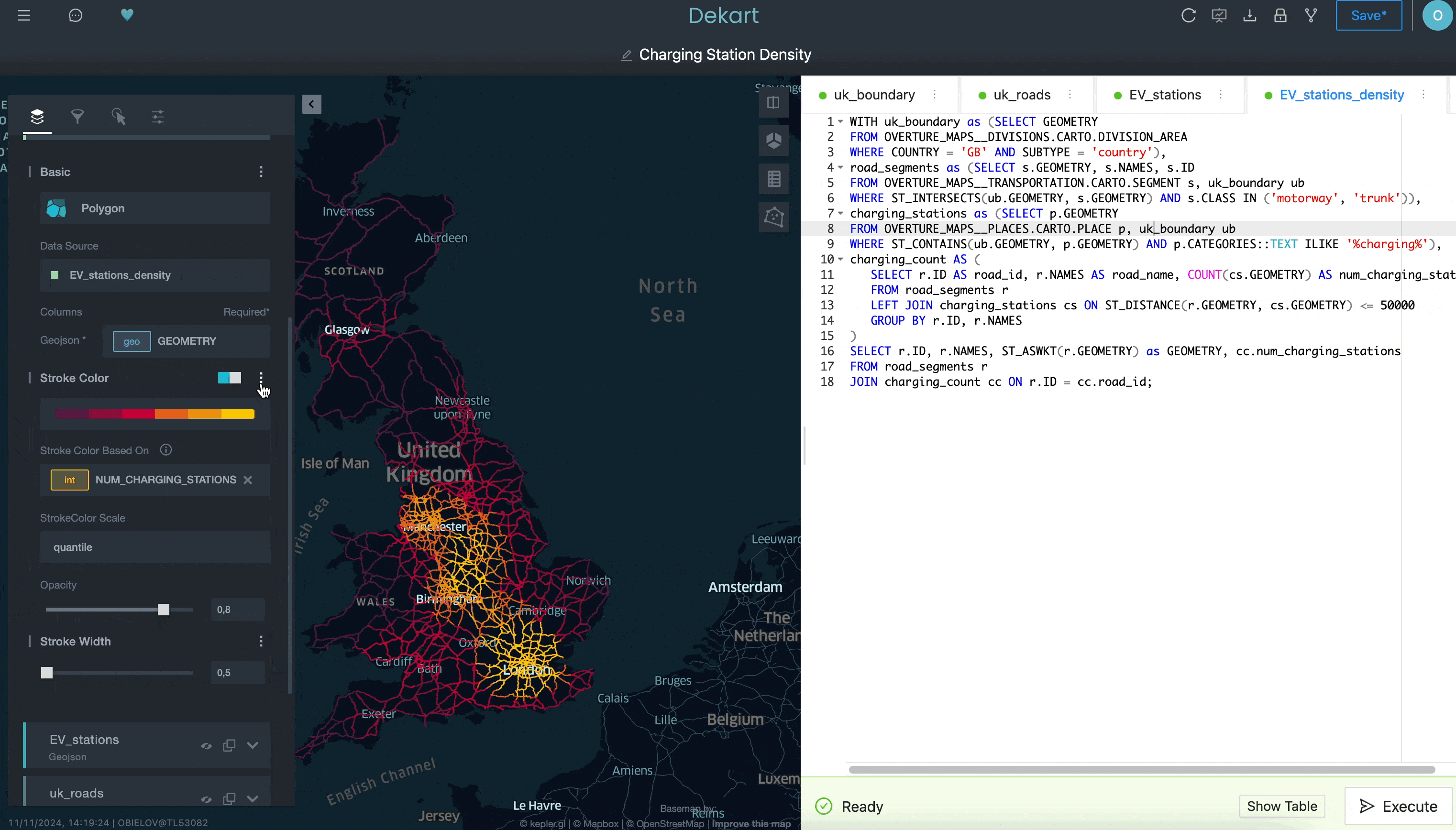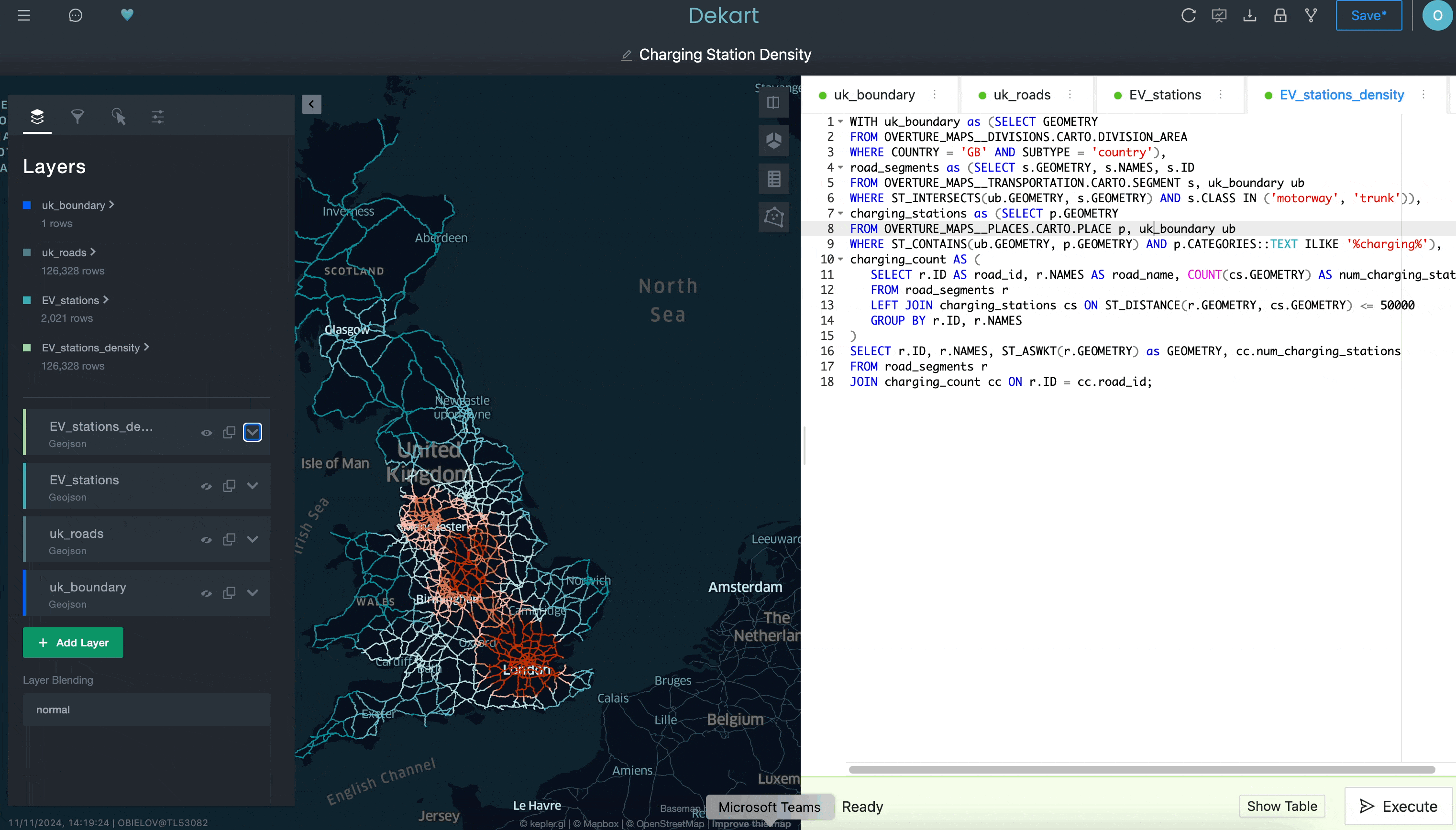
Embora esse exemplo não mostre tudo o que você pode fazer com Kepler.gl, espero que ele ilustre como é difícil fazer isso em uma ferramenta de BI tradicional. Graças ao acesso a uma interface mais sofisticada para criar visualizações de localização facilmente instalável no Snowflake Marketplace, você pode melhorar os recursos de análise de localização de modo mais fácil do que pensa.
Conclusão
Neste blog, discutimos as várias formas como você pode obter insights a partir de dados geoespaciais no Snowflake. Vimos seis recursos principais, que permitem:
Transformar dados de localização em dados GEOMETRY e GEOGRAPHY de modo a permitir mais análises e casos de uso, como geocodificação e geocodificação inversa.
Enriquecer conjuntos de dados de eventos e baseados no tempo.
Adotar modelos de aprendizado de máquina e funções SQL de aprendizado de máquina nativas para realizar previsões com base em dados geoespaciais.
Adicionar LLMs à análise de sentimentos baseada em locais.
Além de calcular distâncias e realizar análises de proximidade com funções nativas.
Visualizar mapas interativos com o Snowpark Container Services e nosso amplo ecossistema de parceiros.
Siga este quickstart para obter treinamento prático nesses cenários. Ele ajudará você a aprender a aplicar esses casos de uso mais sofisticados e a gerar mais valor dos seus dados de localização no Snowflake. Esperamos que você encontre todos os pontos que você está procurando!
Autoria:
