Guía avanzada para obtener información geoespacial en Snowflake

En las tres últimas entradas de blog centradas en el ámbito geoespacial, hemos tratado los conceptos básicos de lo que son los datos geoespaciales, cómo funcionan en el mundo general de los datos y cómo funcionan específicamente en Snowflake a partir de nuestra compatibilidad nativa con GEOGRAPHY, GEOMETRY y H3. Esos artículos son excelentes para dar los primeros pasos, tantear el terreno y quizás hasta para seguir investigando. Pero hay mucho más que puedes hacer con los datos geoespaciales en tu cuenta de Snowflake. Sí, ya sabemos que puede ser difícil pasar de “ahora entiendo los conceptos” a “¿cómo puedo abordar mis primeros casos de uso?”.
El mundo del procesamiento de datos geoespaciales es vasto y complejo, y estamos aquí para simplificarlo. Por eso hemos creado una Quickstart de Snowflake que te guiará por varios ejemplos de capacidades geoespaciales en contextos reales. Aunque estos ejemplos utilizan datos representativos de Snowflake Marketplace o datos que hemos puesto a tu disposición de forma gratuita en Amazon S3, se pueden aplicar a tu cuenta, datos y casos de uso de Snowflake para ofrecer información valiosa a tu comunidad de usuarios. En esta entrada de blog se explica cómo hacerlo, pero consulta la Quickstart para ver el código real.
Transformación de los datos de ubicación en tipos de datos geoespaciales
Empecemos con un breve resumen: los datos de ubicación están en todas partes. De la misma forma que tu cuenta de Snowflake tiene datos basados en el tiempo casi con total certeza, también es casi seguro que tenga datos basados en la ubicación, ya que la mayor parte de los datos transaccionales contienen algún elemento que informa de quién, qué, cuándo y dónde.
En su forma más simple, los datos de ubicación (o localización) se conocen generalmente como una variedad de campos de texto y numéricos que comprenden lo que llamamos “direcciones” e incluyen cosas como calles, ciudades, estados, condados, códigos postales y países. Los seres humanos podemos leer y comprender estas cadenas con bastante facilidad. Sin embargo, en forma de texto se trata en gran medida de valores informativos que buscamos cuando necesitamos conocerlos y nada más. A veces, estos campos de texto también pueden ir acompañados de campos de latitud y longitud. Estos campos son excelentes porque ahora podemos hacer más con los datos de ubicación y colocarlos en la Tierra como punto. Esto es útil porque podemos integrar todos estos puntos en la capacidad de asignación de una herramienta de inteligencia empresarial (business intelligence, BI) para mostrar a qué país o territorio pertenece el punto, o podemos integrar estos puntos en una cuadrícula espacial como H3. Aunque varios partners de BI de Snowflake trabajan con datos de latitud y longitud, Snowflake incorpora compatibilidad para transformar los datos de longitud y latitud en una cuadrícula espacial H3 para un cálculo y visualización rápidos (como veremos más adelante).
Sin embargo, podemos ir un paso más allá y transformar esos datos de latitud y longitud en datos de GEOGRAPHY o GEOMETRY. Podemos utilizar el primero cuando necesitamos una representación elipsoidal (globo terráqueo) de la Tierra, y el segundo cuando necesitamos una representación plana (mapa) de una ubicación más concreta. Además, podemos crear estos tipos de datos con diversas funciones.
Tal vez no parezcan gran cosa, pero con estos dos tipos de datos podemos empezar a incorporar una serie de puntos a una línea, conectar varias líneas en un polígono y representar ubicaciones complejas como una serie de líneas y polígonos. Podemos realizar cálculos complejos y asociaciones de relaciones entre objetos de estos tipos y empezar a obtener información que no sabíamos que estaba disponible solo con un simple campo “dirección”. Cabe plantarse la siguiente pregunta: “Pero ¿y si todo lo que tengo es el campo de dirección de texto?” Te damos la bienvenida a nuestra primera gran aventura: la geocodificación. “¿¿Geo-qué??”
Geocodificación y geocodificación inversa
La geocodificación es el acto de tomar los datos textuales de dirección y transformarlos en un tipo geoespacial para potenciar casos de uso que de otro modo no habrías podido ofrecer. Claro que también es posible ir en la otra dirección: puedes convertir tu tipo de datos geoespaciales menos legibles en un conjunto de campos de ubicación más legibles para las personas. Ambas transformaciones se pueden realizar con partners especializados de Snowflake, como Mapbox y TravelTime, que son Snowflake Native Apps disponibles a través de Snowflake Marketplace. Recomendamos estos proveedores para lograr la geocodificación y la geocodificación inversa más precisas. Sin embargo, a veces es necesario equilibrar la precisión con el coste o demostrar el ROI antes de poder gastar dinero, así que vamos a hablar de cómo empezar a utilizar la geocodificación y la geocodificación inversa directamente en Snowflake.
En este caso de uso, utilizaremos dos conjuntos de datos de Snowflake Marketplace: Worldwide Address Data, una colección gratuita y abierta de datos de dirección globales, y un conjunto de datos de nuestro partner CARTO para tutoriales, que tiene una mesa de restaurante con una sola columna street_address. Si siguieras este ejemplo para tus datos, tendrías que sustituir la tabla del restaurante para tutoriales por la tuya. Prepararás los datos de estas dos tablas, que puedes ver en la Quickstart.
La geocodificación autoservicio de Snowflake consta de tres pasos:
1. Usa un large language model (LLM) para transformar una cadena de dirección completa en un array JSON con sus partes como atributos. En este paso, utilizarás la función SNOWFLAKE.CORTEX.COMPLETE, que usa un modelo Mixtral-8x7B alojado en Snowflake, para realizar la conversión a través de un conjunto detallado de instrucciones que proporcionas como parte de la llamada funcional. Consulta las notas de la Quickstart para elegir el tamaño de almacén adecuado y ejecutarlo a escala.
2. Crea una columna geoespacial sencilla sobre la latitud y la longitud en Worldwide Address Data.
- ST_POINT se utiliza para crear la columna geoespacial a partir de la latitud y la longitud.
- Los datos innecesarios se eliminan de la tabla Worldwide Address Data en función de los valores no válidos de latitud y longitud.
3. Utiliza JAROWINKLER_SIMILARITY para establecer correspondencias entre direcciones. Tienes que unir las dos tablas en unas pocas columnas y aplicar la función JAROWINKLER_SIMILARITY a la columna del nombre de la calle, ya que no es raro que los nombres de calle tengan sutiles diferencias de cadena entre fuentes, de ahí el “95” como nuestro umbral de similitud en la llamada a la función.
Es importante señalar que este método no es totalmente preciso. La Quickstart muestra en más detalle el nivel de precisión logrado y algunos de los motivos por los que este método es imperfecto, pero es importante señalar la diferencia de coste entre este método y un servicio de geocodificación dedicado. Este método es una excelente forma de cumplir requisitos más simples o de justificar la necesidad de unos servicios de geocodificación más dedicados con requisitos más complicados.
Para llevar a cabo geocodificación inversa o generar una dirección a partir de un tipo de datos geoespaciales, vamos a crear un procedimiento almacenado que haga tres cosas: crear una tabla de resultados, seleccionar filas que no se han procesado y encontrar la coincidencia de direcciones más cercana mediante un bucle con una búsqueda de radio creciente hasta encontrar un resultado. Puedes llamar a este procedimiento como a todos los procedimientos de Snowflake e incorporar los argumentos adecuados definidos en la parte superior del código del procedimiento, que puedes ver en la Quickstart.
La geocodificación de los datos de direcciones permite utilizarlos de una forma más útil. Vamos a profundizar en una forma en que se pueden utilizar los datos geocodificados.
Previsiones basadas en datos geoespaciales
La previsión es una actividad habitual con datos de series temporales, ya que existen modelos sólidos de aprendizaje automático (machine learning, ML) diseñados para introducir datos históricos y predecir una ventana de datos futuros en función de las tendencias históricas. Snowflake incluye un modelo de previsión de ML integrado llamado SNOWFLAKE.ML.FORECAST que puedes utilizar fácilmente para esta actividad. Aunque puedes realizar previsiones de series temporales en cualquier dato basado en tiempo, enriquecer esa previsión con datos de ubicación proporciona otra dimensión de valor en el proceso de previsión.
En la Quickstart se utilizan dos conjunto de datos: datos sobre carreras de taxis de Nueva York facilitados por CARTO y datos de eventos proporcionados por PredictHQ. Puedes pensar en los dos conjuntos de datos de la siguiente forma: los datos sobre carreras son como los de cualquier otra serie temporal que tengas sobre algo que ocurre en un momento y lugar determinados. Es probable que tengas ese tipo de datos en tu organización. Los datos del evento añaden más contexto a un elemento basado en tiempo incluido en tus datos. En este ejemplo, los datos del evento pueden informar sobre cualquier aumento o disminución en carreras previstas en Nueva York. Otros tipos de datos contextuales que puedes tener incluyen periodos de apertura o cierre, periodos promocionales recurrentes, eventos públicos y más. Independientemente de lo que sean, los datos contextuales pueden ayudar a proporcionar una mayor precisión a una previsión, ya que mejoran cualquier día u hora con una expectativa creciente o decreciente.
La actividad de previsión consta de cuatro pasos:
1. Utiliza una cuadrícula espacial para calcular una serie temporal de recogidas de taxi para cada celda de la cuadrícula.
Usa la cuadrícula espacial H3 para dividir la ciudad de Nueva York en celdas según la ubicación de recogida.
Puedes identificar una recogida en una celda tomando la latitud y longitud y convirtiéndola en una celda H3.
A continuación, puedes agregar el número de recogidas en cada celda de Nueva York por horas del día mediante las funciones TIME_SLICE y H3_POINT_TO_CELL_STRING de Snowflake.
Por último, debes “rellenar” cualquier intervalo de horas en una ubicación con 0 (cero) registros de recogida. Esto es necesario para la previsión de series temporales.
2. Enriquece los datos de series temporales por hora con datos de eventos.
Esto añade columnas de “características” a los datos anteriores marcando cada fila como vacaciones escolares, festivo o evento deportivo en función de la unión de los datos de nuestro evento.
Ten en cuenta que puedes agregar cualquier “característica” que tenga sentido para los datos de tu evento. Las vacaciones escolares, los días festivos y los eventos deportivos son solo ejemplos realistas de este panorama.
3. Crea un modelo, un conjunto de datos de entrenamiento y un conjunto de datos de predicción.
El modelo SNOWFLAKE.ML.FORECAST requiere un paso de entrenamiento antes de realizar predicciones, por lo que los datos del paso 2 deben dividirse en dos tablas por periodo: una para el entrenamiento y otra para la predicción.
A partir de ahí, crea un modelo en el que una de las entradas es la tabla de datos de entrenamiento que estableciste anteriormente. También identifica las columnas clave, como la columna de tiempo, la métrica que se desea pronosticar y, en este caso, los datos de ubicación para la previsión.
4. Ejecuta el modelo y visualiza la precisión de las predicciones.
Una vez entrenado el modelo, se le puede llamar, apuntando a otro conjunto de datos para usarlo en la predicción.
La predicción se puede enviar a una tabla y, a continuación, comparar con los datos reales para evaluar la precisión. Existen varias formas de hacerlo, pero el Quickstart sugiere utilizar un error porcentual absoluto medio simétrico (SMAPE).
El siguiente gráfico muestra cómo puede ser el resultado de esta comparación para una celda H3; el modelo de previsión tiene una tasa de precisión bastante alta:
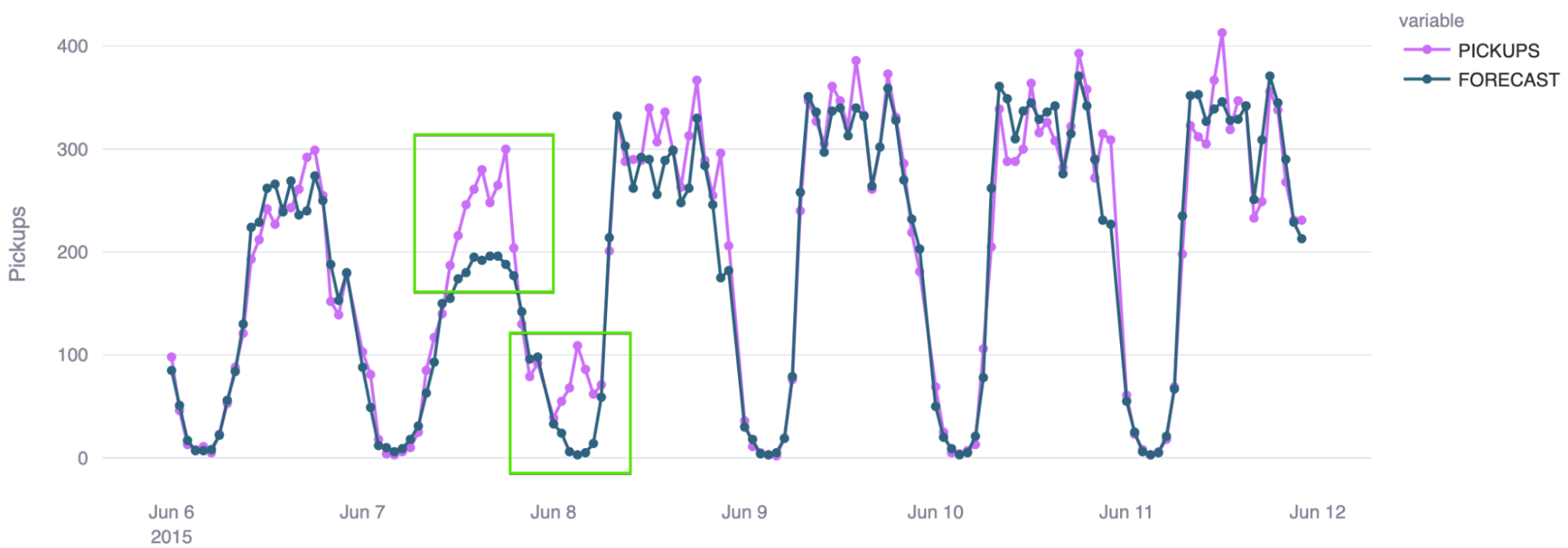
La previsión de series temporales en Snowflake puede ser una potente herramienta, y se puede aumentar aún más con la capacidad de agrupar ubicaciones en una celda determinada en una cuadrícula espacial y hacer una previsión de esa celda, en lugar de tratar de hacer una previsión de cada ubicación de forma individual, que es demasiado detallado.
Uso de H3 para visualizar el sentimiento por ubicación
Utilizaste un LLM en el ejemplo de geocodificación anterior para transformar los datos en un formato diferente, pero también puedes utilizarlo para puntuar los datos de texto en función de la positividad o negatividad del lenguaje utilizado en el texto. Esto es valioso para evaluar el sentimiento de las personas en una situación determinada, ya sea la opinión que proporcionan sobre los productos o servicios o lo favorablemente que ven tu marca. La clave aquí es que puedes convertir el texto sin procesar en una medición ordinal y, a continuación, analizar si la ubicación se incluye en esa medición. Veamos cómo podemos hacerlo en Snowflake.
Desde el punto de vista de los datos, son necesarias tres cosas:
Un evento o transacción de algún tipo
Comentario de texto sin procesar sobre el evento
La ubicación del evento
Todo esto podría estar en un sistema (por ejemplo, los clientes realizan un pedido en una aplicación y luego proporcionan comentarios sobre su nivel de satisfacción con el proceso de pedido), o podría estar en diferentes sistemas (por ejemplo, un cliente realiza un pedido de un producto, pero luego publica en las redes sociales un comentario sobre cuánto le gustó el producto que recibió). La Quickstart utiliza datos de entrega sintéticos, que incluyen los comentarios de los clientes sobre cómo fue la experiencia de entrega.
La visualización de esta información por ubicación consta de dos pasos:
1. Puntúa el sentimiento de los comentarios de cada entrega.
En primer lugar, usarás SNOWFLAKE.CORTEXT.COMPLETE como antes, pero esta vez la instrucción que le darás al LLM es evaluar el texto y asignarle una etiqueta de categoría de texto, como “Muy positivo”.
A continuación, convertirás esas etiquetas de categorías de texto en números que puedes agregar en varias entregas en un área común.
2. Visualiza el sentimiento agregado por ubicación con H3.
En lugar de precalcular las puntuaciones de ubicación como hicimos en la previsión de series temporales, crearemos una aplicación que agregará las puntuaciones de sentimiento en celdas H3 sobre la marcha.
La aplicación de Streamlit usará ST.PYDECK_CHART para trazar y colorear las celdas H3 en función de los cuantiles de sentimiento.
Este es un ejemplo de la visualización de análisis de sentimientos por ubicación de las tiendas:
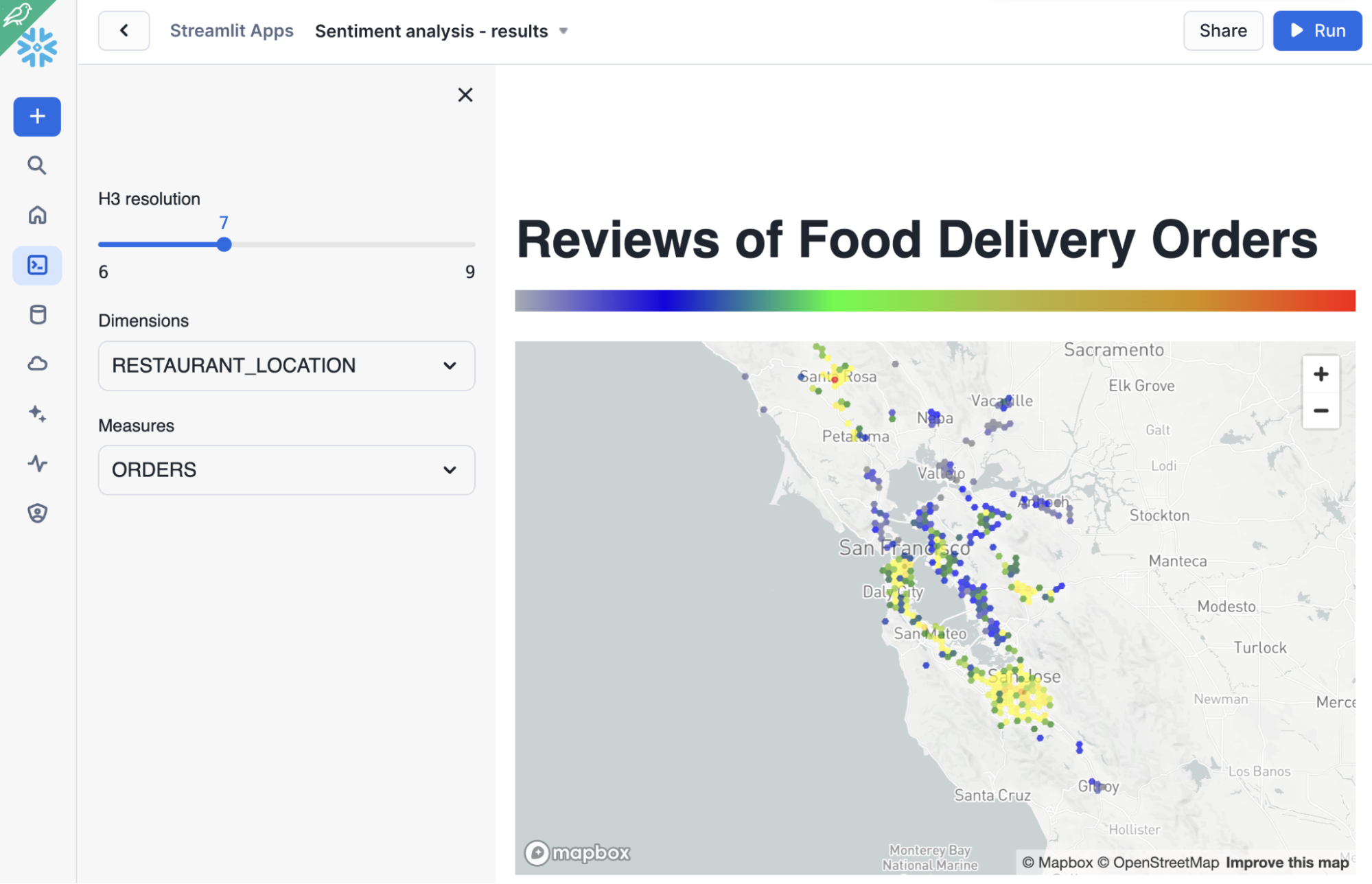
Pero lo más importante es que la aplicación permite explorar los datos con mayor libertad porque calculamos todo sobre la marcha. ¿Cómo funciona? Considera esta ampliación a continuación:
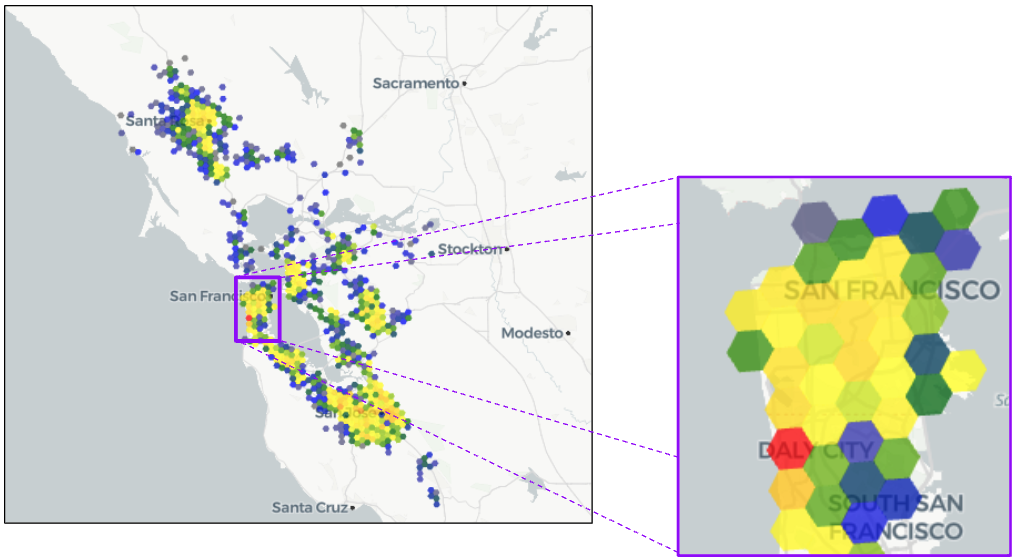
¿Y si queremos tener una visión más detallada de la península de San Francisco? El uso del deslizador de la aplicación para cambiar la resolución H3 de 7 a 8 nos da una imagen más clara:
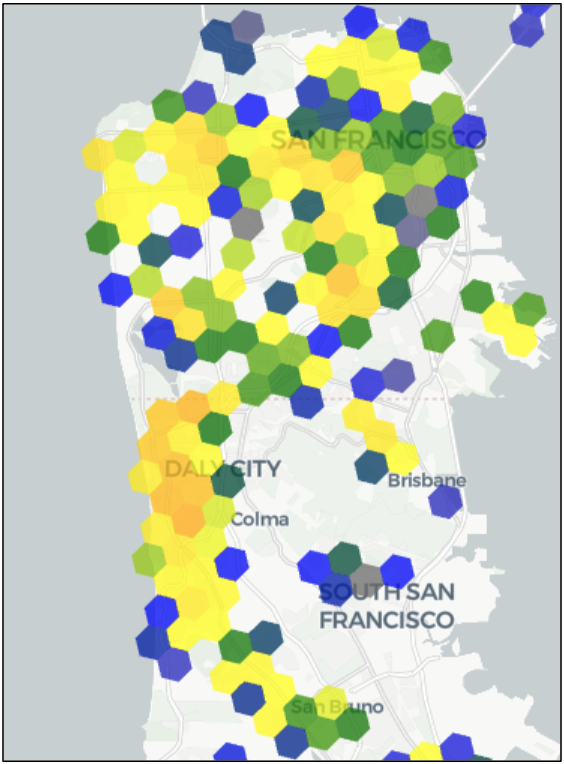
Ahora podemos ver más claramente dónde hay lagunas, puntos fuertes y puntos débiles. Esta capacidad inmediata para obtener una mayor resolución de ubicación es como pasar de un televisor SD a uno HD, de un televisor 4K a uno 8K, obtenemos una imagen más nítida de lo que estamos tratando de mirar.
H3 es una forma potente y rápida de obtener claridad sobre la ubicación en las métricas. Al combinarlo con un LLM, podemos convertir el texto sin procesar en un resultado medible. Es una función extremadamente potente que puedes aplicar de muchas formas dentro de tu organización.
Análisis de vecinos más cercanos con datos ráster y archivos de forma (shapefile)
Aunque muchas empresas obtienen los datos de ubicación de fuentes de datos estándar de las que también procede el resto de datos, quienes trabajan a fondo en datos geoespaciales saben que los datos también pueden proceder de formatos y archivos especializados. Para los no iniciados, el resumen rápido es que la mayoría de los datos geoespaciales cubiertos en esta y otras entradas de blog hasta ahora son datos vectoriales: puntos, líneas y polígonos. Un formato común utilizado para almacenar datos vectoriales en un archivo es un archivo de forma (shapefile), pero los archivos de forma generalmente se abren con aplicaciones SIG dedicadas, que no son leídas por las bases de datos. Los datos ráster difieren de los datos vectoriales en que los datos se representan como una cuadrícula de celdas, como una imagen pixelada. Los datos ráster se suelen almacenar en archivos GeoTIFF que tampoco suelen leer las bases de datos. Los datos vectoriales y datos ráster tienen cada uno sus casos de uso, y a veces es necesario acceder a ambos; la Quickstart aborda estos casos.
En este caso, utilizaremos dos fuentes de datos —un mapa de elevación almacenado como un GeoTIFF de ráster y datos de temperatura/precipitación almacenados en un archivo de forma— para usar ambos conjuntos de datos a fin de predecir la presencia de aguas subterráneas. Pero, en realidad, son solo archivos representativos para mostrar cómo podemos acceder a estos tipos de archivo en Snowflake y, en última instancia, utilizarlos en un análisis específico. Si tienes GeoTIFF o archivos de forma en tu organización, puedes utilizar estos métodos para introducir tus datos en Snowflake.
La combinación de estas dos fuentes de datos para hacer un análisis de vecinos más cercanos consta de tres pasos:
1. Carga el archivo GeoTIFF.
Utilizarás la biblioteca Rasterio Python para crear funciones que extraigan los metadatos de GeoTIFF, evalúen las bandas presentes en GeoTIFF y, en última instancia, lean y conviertan el centroide de cada píxel en datos (puntos) vectoriales.
A continuación, evalúa los metadatos y convierte los puntos en un tipo de datos en el SRID adecuado.
Por último, reducirás el volumen de píxeles a un tamaño más manejable al convertir los puntos en celdas H3.
2. Carga el archivo de forma.
Utilizarás la biblioteca Fiona Python y la capacidad de acceso dinámico a archivos de Snowflake para crear funciones que lean los metadatos y datos del archivo de forma.
A partir de ahí, evaluarás la naturaleza de los datos del archivo de forma y cómo se representan con el fin de que puedas diseñar una consulta para cargarlos en una tabla con las columnas y tipos de datos adecuados.
Al igual que en el paso 1, reducirás el número de filas a un tamaño más manejable al convertir los puntos en celdas H3.
La Quickstart muestra una forma alternativa de visualizar estos datos, pero es un paso opcional.
3. Calcula el punto meteorológico más cercano para cada punto de elevación utilizando uno de los dos métodos descritos en la Quickstart.
Nota: cada método implica filtrar ambas tablas hasta el área de enfoque, como se detalla en la Quickstart.
El primer método está autocontenido en Snowflake y te pide que uses una consulta que combine ST_DWITHIN y una función de ventana QUALIFY. Sin embargo, este método puede ser intensivo en cuanto a cómputo.
El segundo método consiste en utilizar la Snowflake Native App, SedonaSnow, que te da acceso a la función ST_VORONOIPOLYGONS. Los polígonos de Voronoi pueden ser una forma más eficiente de agrupar los puntos más cercanos a otro punto, pero para obtener acceso a dicha función, necesitarás instalar la aplicación SedonaSnow.
No es raro en el mundo de los datos geoespaciales tener que acceder a datos de archivos no tradicionales. Afortunadamente, la flexibilidad de Snowflake te permite trabajar con estos archivos y acceder a estos valiosos datos para tus análisis.
Mapas interactivos
También es habitual en el mundo del SIG interactuar con interfaces de usuario diseñadas para datos de ubicación. Estas aplicaciones van más allá de lo que normalmente es posible en una herramienta de BI para presentar más datos con capacidades de capa sofisticadas y otras interacciones específicas de la ubicación. Una herramienta de código abierto se llama Kepler.gl., pero en lugar de tener que implementar Kepler.gl por ti mismo, puedes instalar Dekart desde Snowflake Marketplace y tener acceso inmediato a Kepler.gl y sus funciones de visualización de ubicación más avanzadas. La ejecución de Kepler.gl en una Snowflake Native App con Snowpark Container Services también garantiza que tus datos nunca salgan de Snowflake. Veamos un ejemplo de la Quickstart.
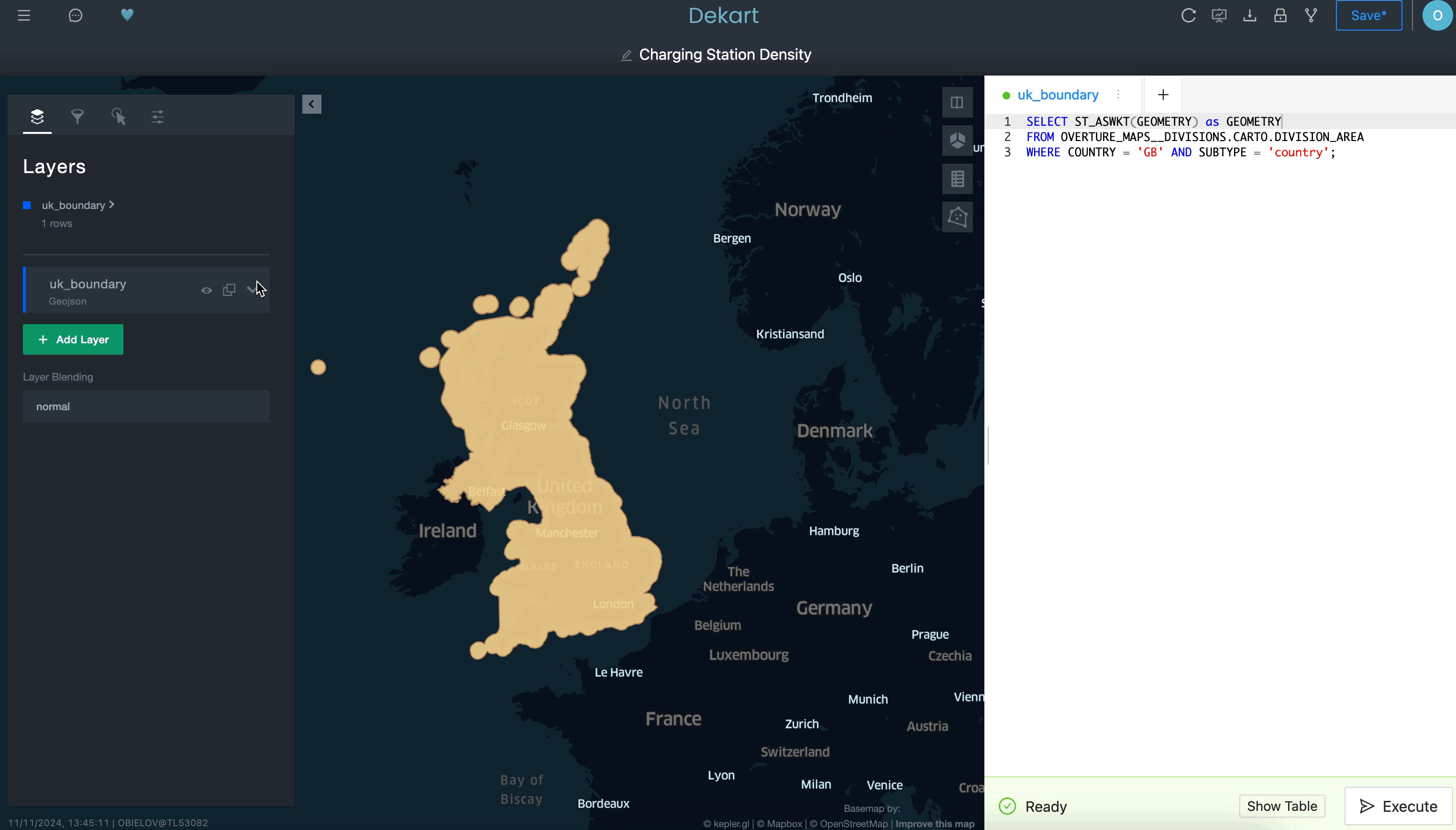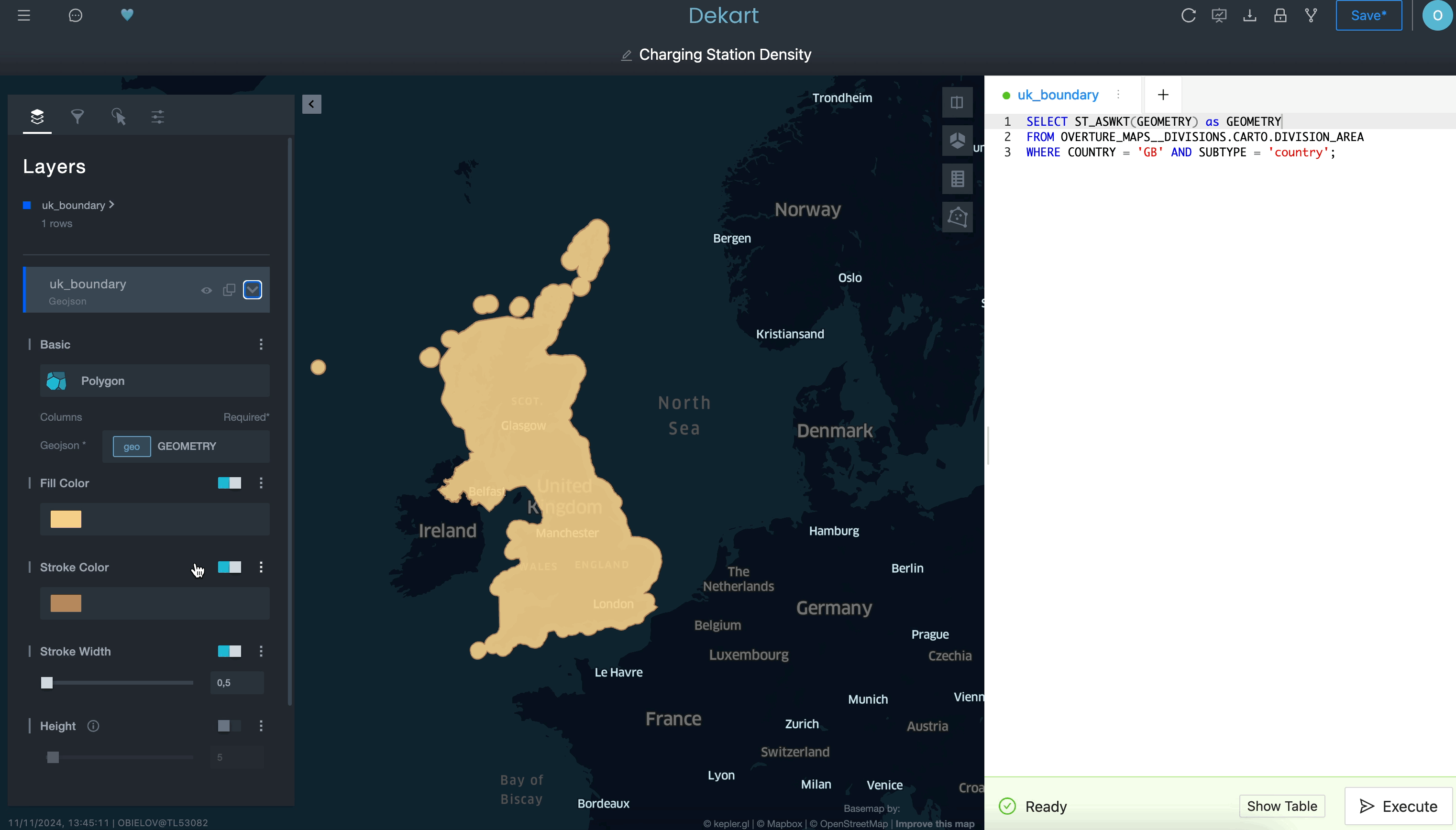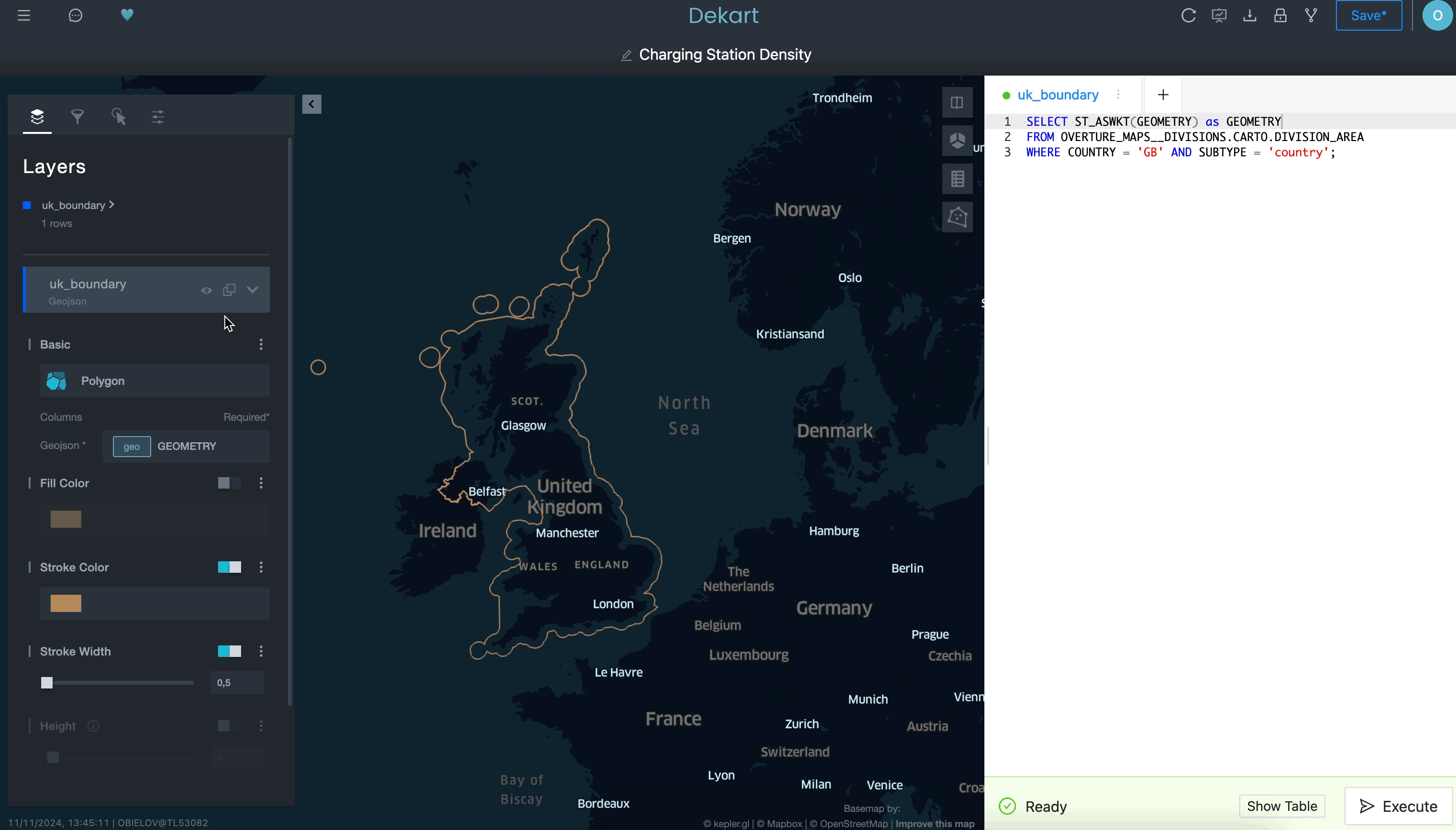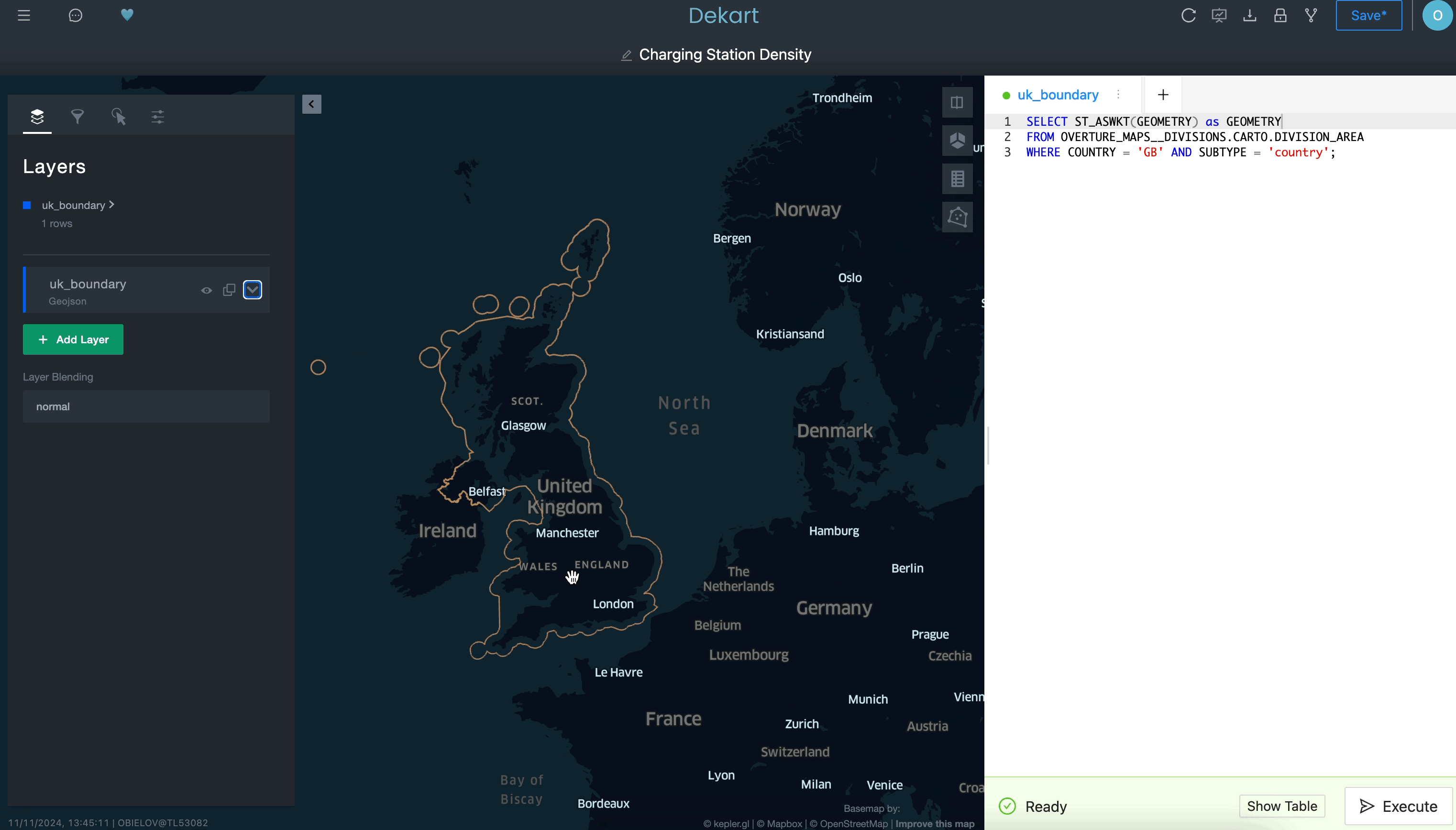
En este caso de uso, crearemos un mapa interactivo para ver la densidad de las estaciones de carga de vehículos eléctricos (EV), que identificará las áreas en las que podría merecer la pena agregar más estaciones. En este ejemplo es necesario que superpongas tres conjuntos de datos: límites de país, rutas de transporte y ubicaciones (cargadores de vehículos eléctricos en este ejemplo), pero podrías sustituir fácilmente las rutas de transporte y las ubicaciones de los cargadores de vehículos eléctricos por otros dos conjuntos de datos de ubicación en tu organización. Después de seguir las instrucciones de configuración de la Quickstart, harás las siguientes tres cosas.
Usa una consulta para definir una capa de límites:
Utiliza una segunda consulta para tomar las rutas de transporte como una segunda capa:
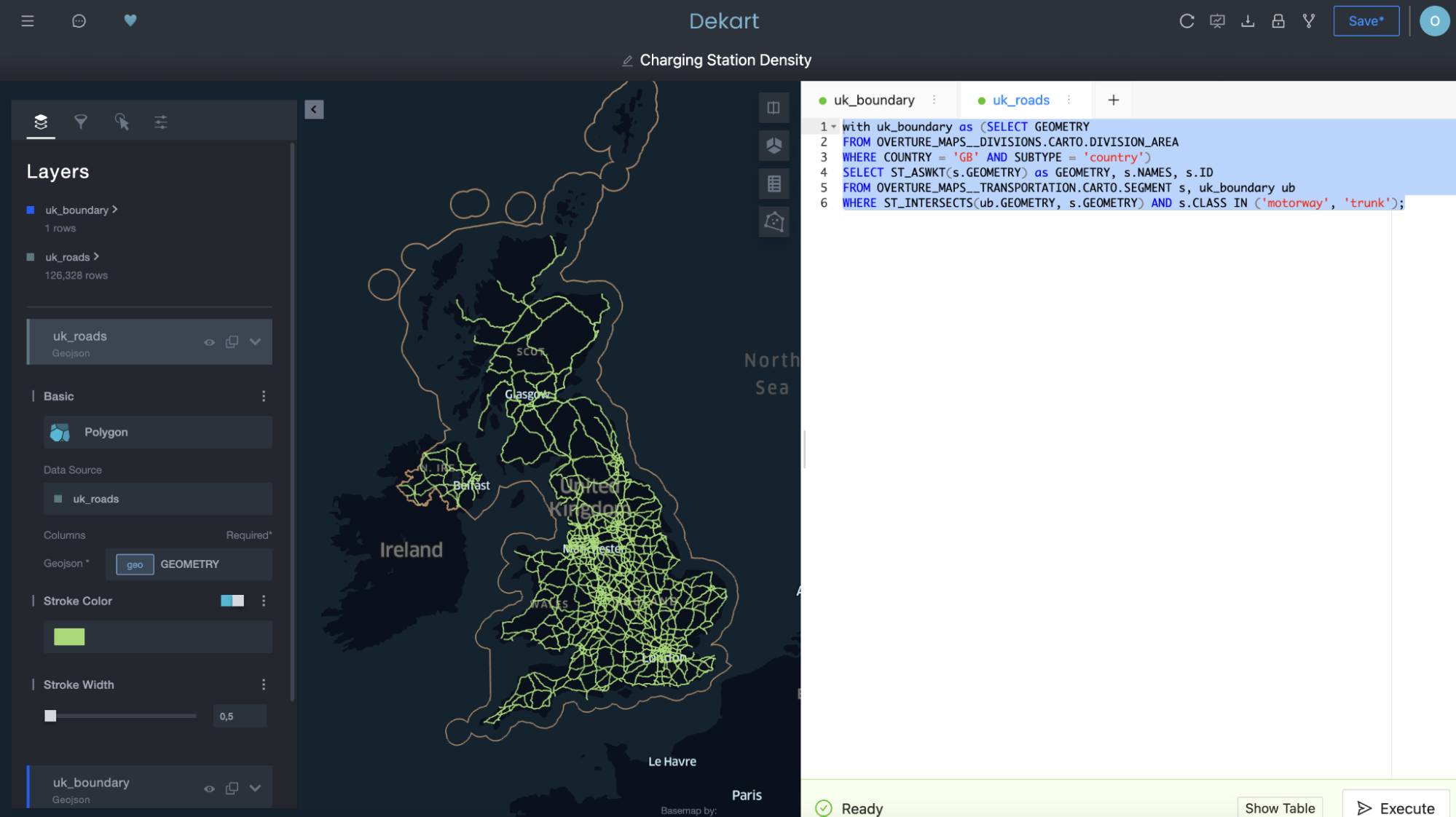
Observa arriba cómo “uk_roads” se agregó como una capa en el lado izquierdo de la interfaz de usuario de Kepler.gl.
A continuación, utiliza una tercera consulta para trazar las estaciones de carga de vehículos eléctricos como otra capa:
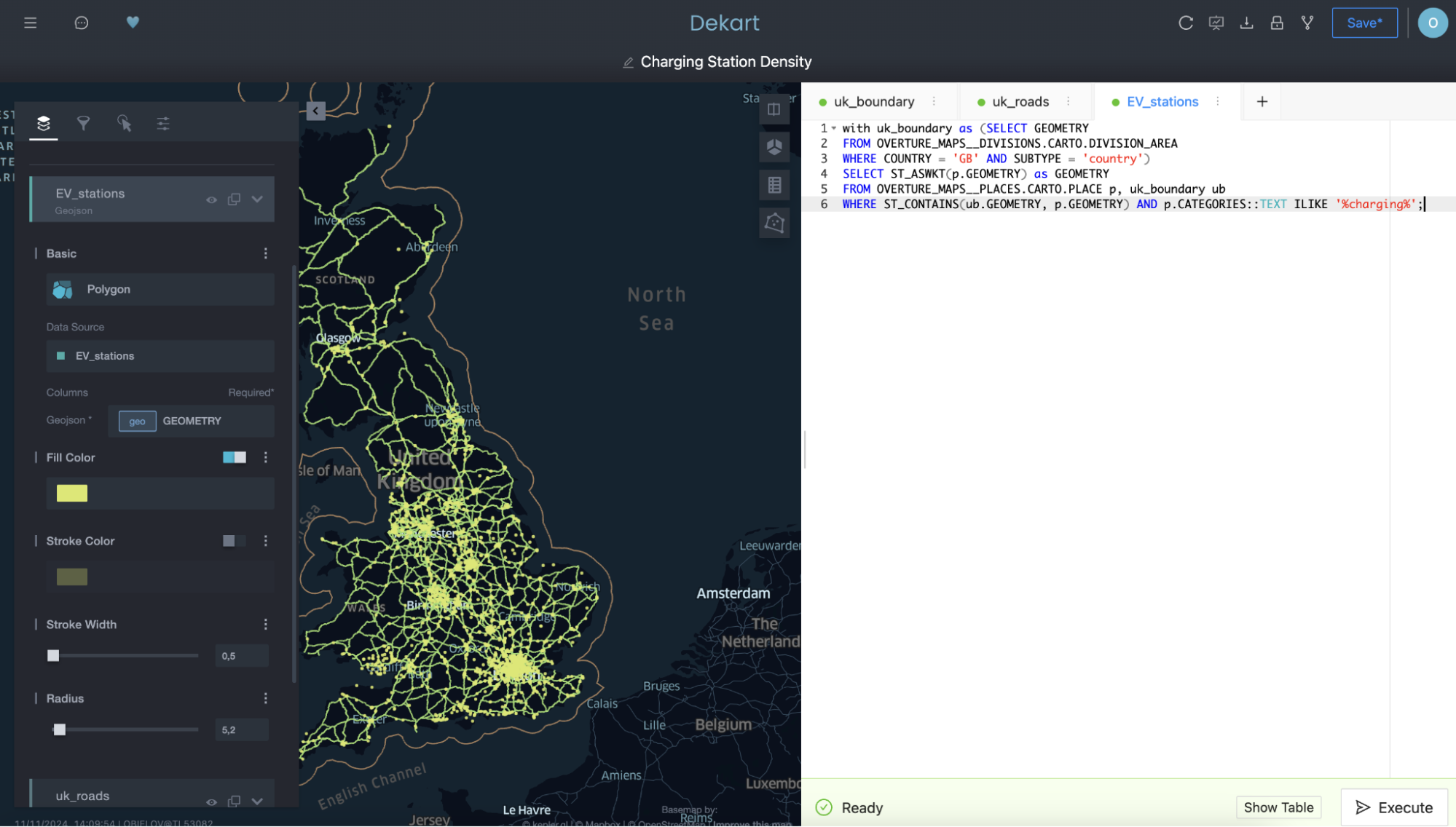
Observa en la segunda y tercera consultas cómo se hace referencia a la consulta de la primera capa por su nombre en la cláusula FROM como medio para filtrar la segunda y tercera consultas seleccionando solo las carreteras y cargadores contenidos dentro del límite de la primera capa.
Por último, puedes agregar una cuarta consulta para calcular la densidad de las ubicaciones de los cargadores de vehículos eléctricos contando el número de cargadores de vehículos eléctricos en un radio de 50 kilómetros por cada segmento de carretera:
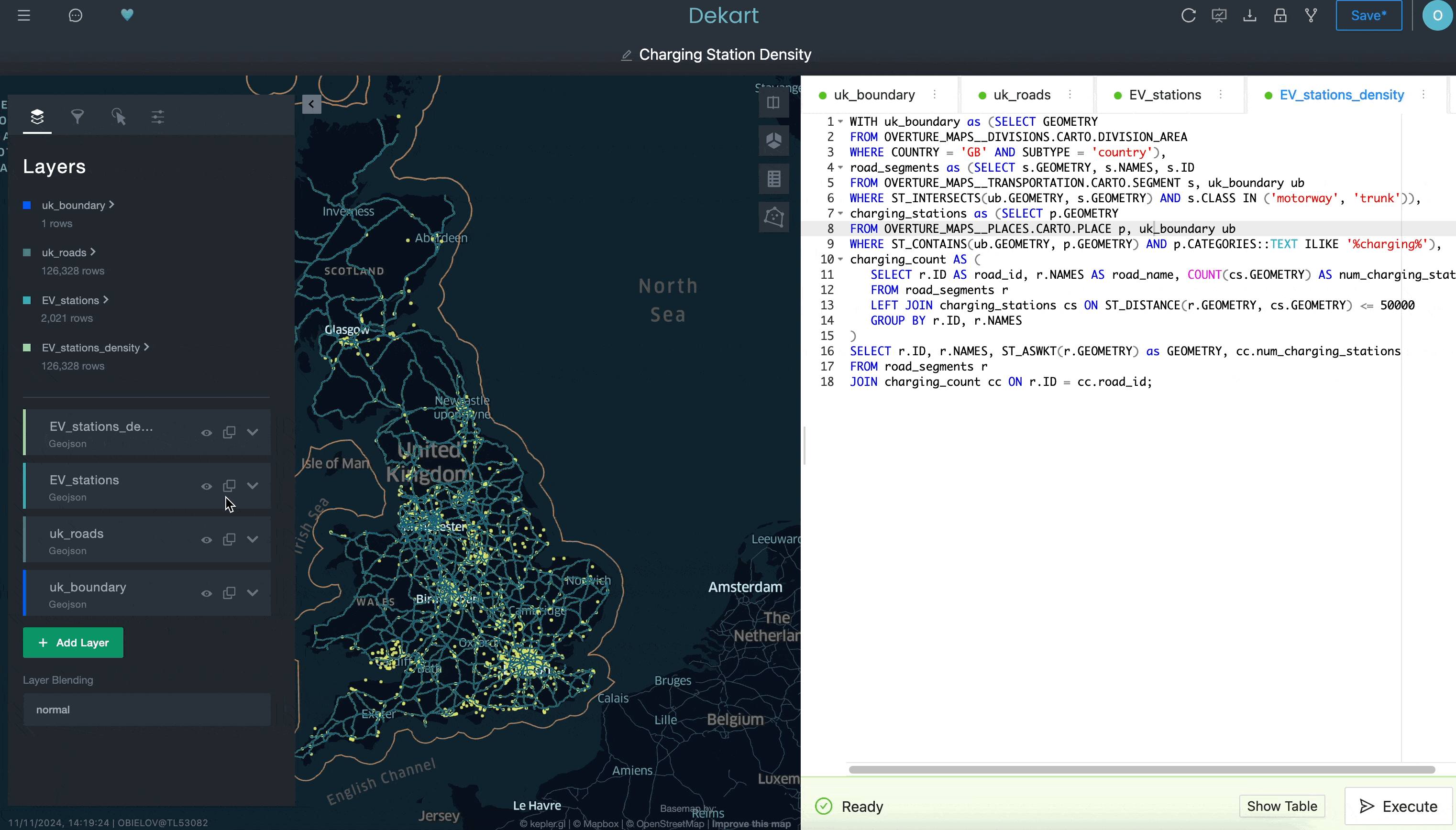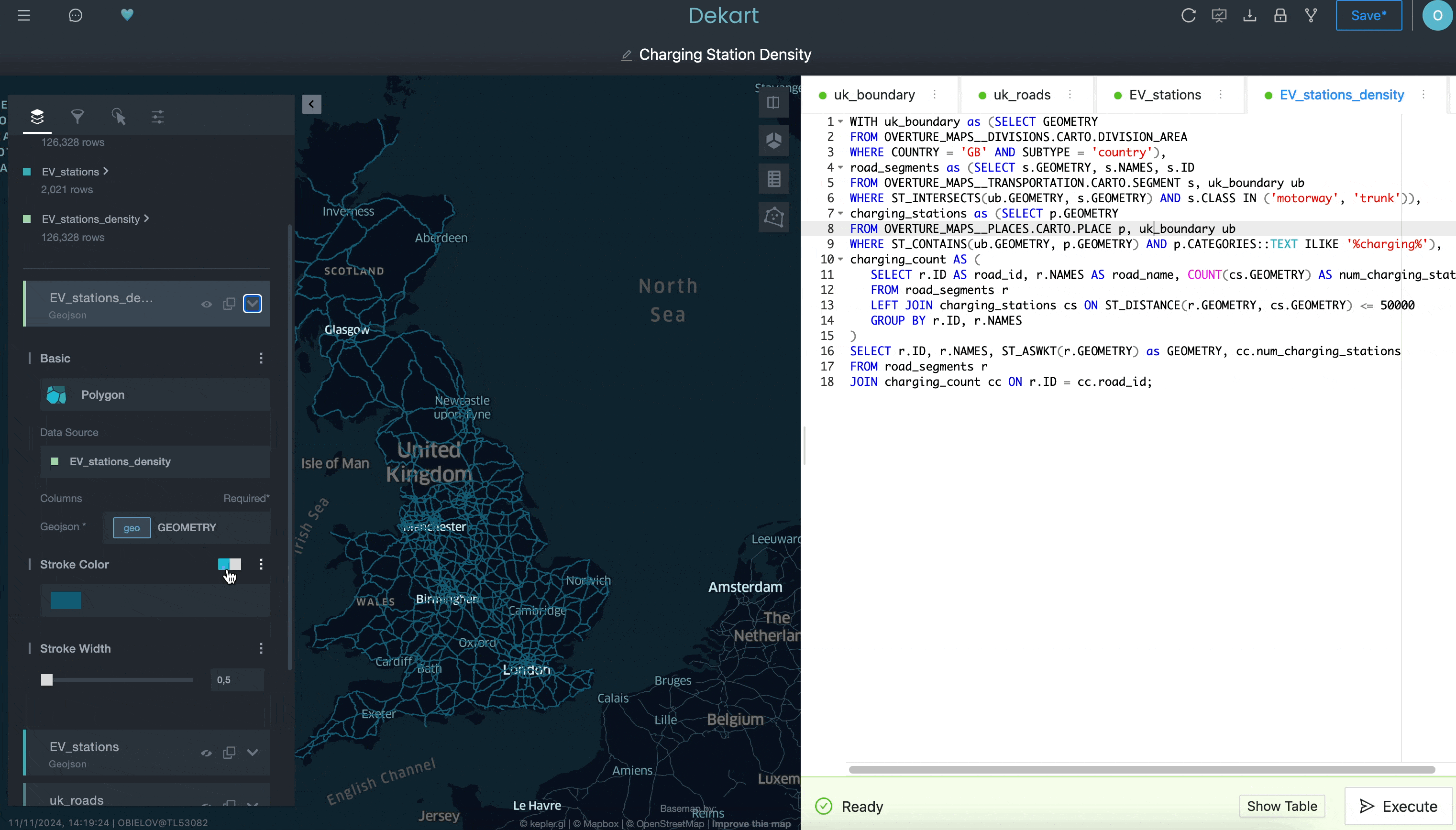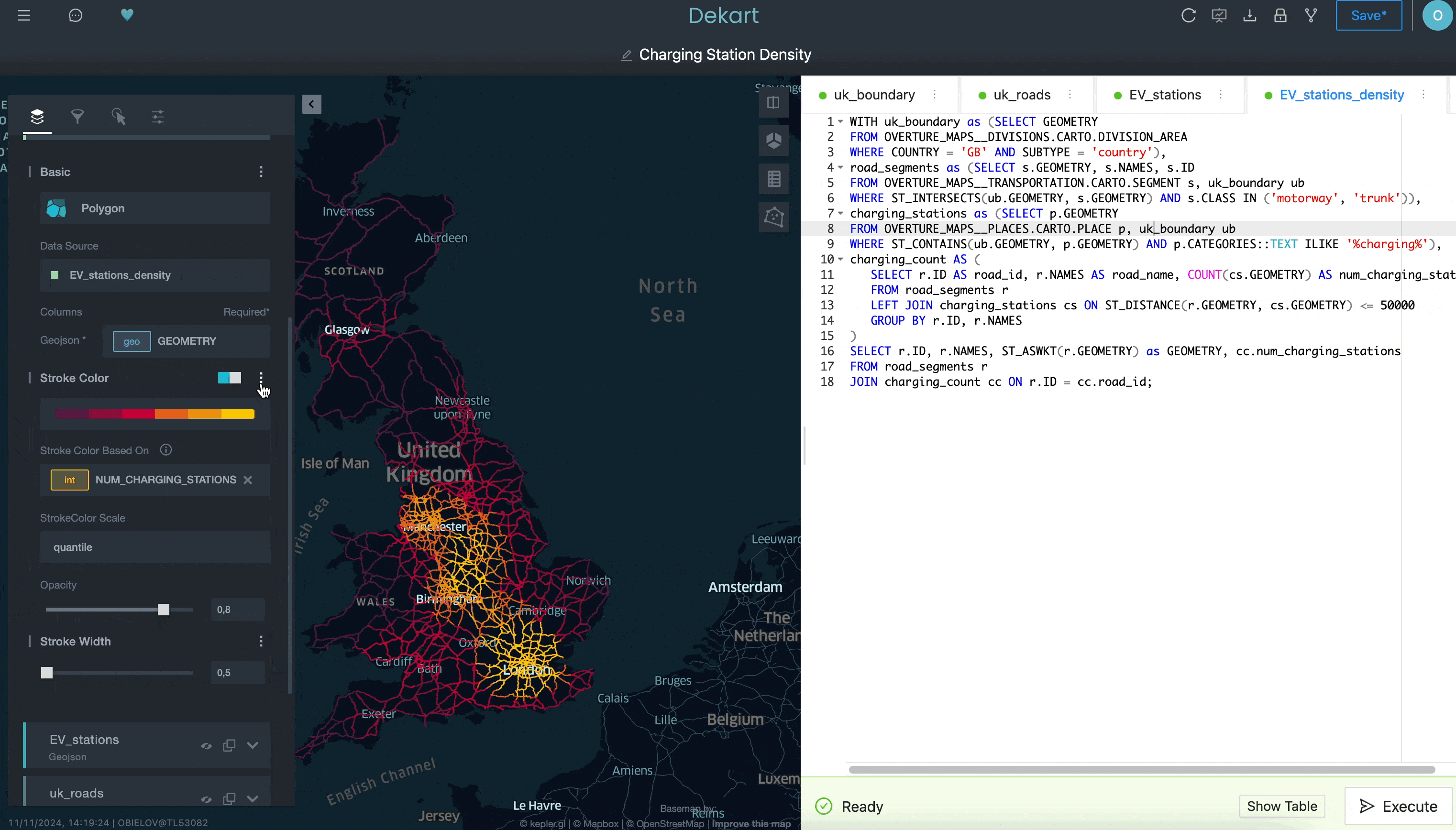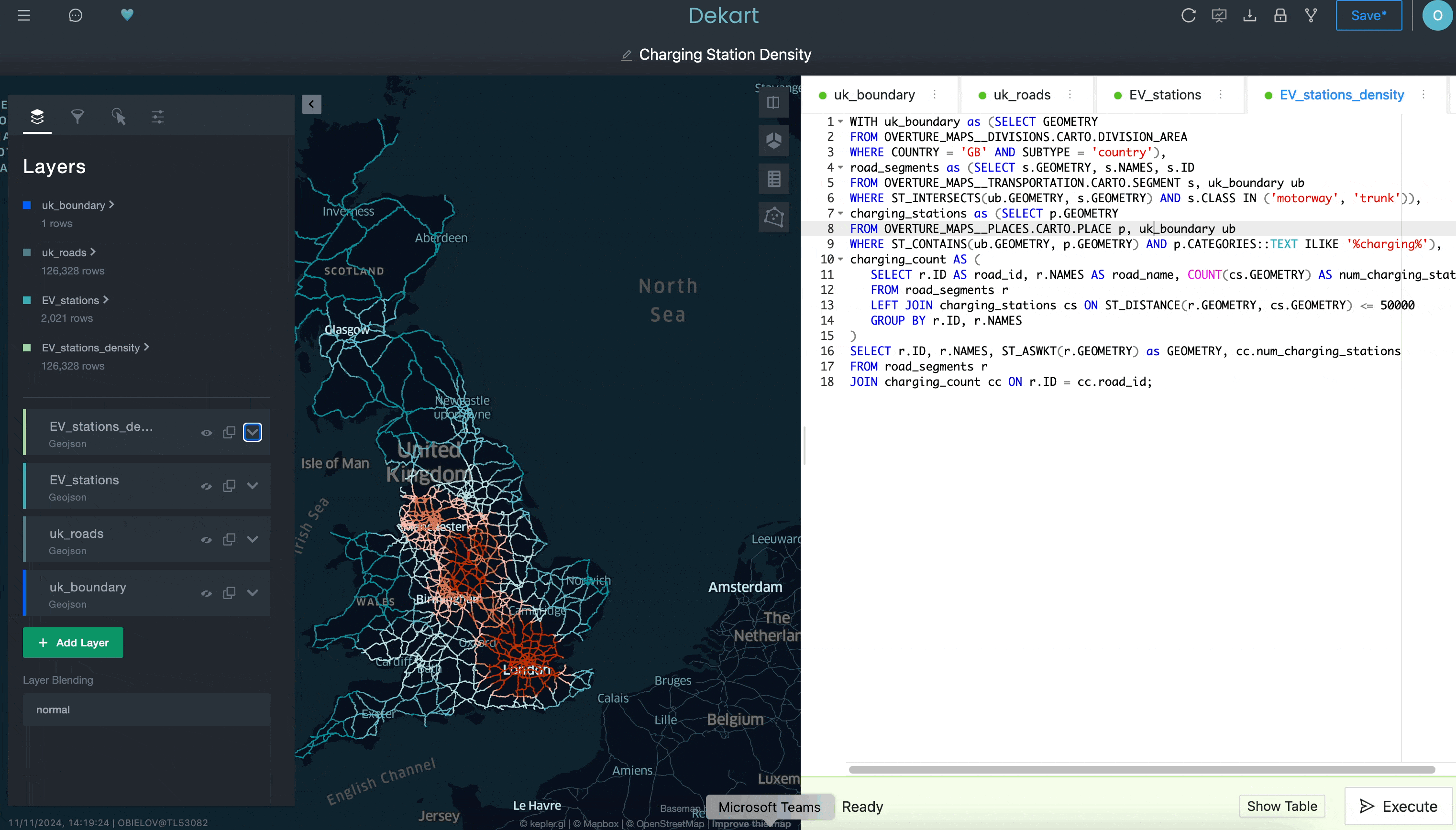
Aunque no mostramos todo lo que se puede hacer con Kepler.gl en este ejemplo, esperamos que ilustre la dificultad que tendría hacer esto con una herramienta de BI tradicional. Al tener acceso a una interfaz más sofisticada para crear visualizaciones de ubicación —y poder instalarla fácilmente desde Snowflake Marketplace—, puedes mejorar tus capacidades de análisis de ubicación de manera más sencilla de lo que crees.
Conclusión
En esta entrada de blog, hemos hablado de las diversas formas en que se puede obtener información de los datos geoespaciales en Snowflake. Hemos cubierto seis capacidades principales, que te permiten:
convertir los datos de ubicación en tipos de datos GEOMETRY y GEOGRAPHY para realizar análisis adicionales y nuevos casos de uso, como la geocodificación y la geocodificación inversa;
enriquecer los datos con conjuntos de datos de eventos y basados en tiempo;
aplicar modelos de aprendizaje automático y funciones SQL nativas de aprendizaje automático para la previsión de datos geoespaciales;
aplicar LLM para analizar sentimientos en función de la ubicación;
calcular también distancias y realizar análisis de vecinos más cercanos con funciones nativas;
visualizar mapas interactivos ampliando las capacidades nativas de Snowflake con Snowpark Container Services y nuestro amplio ecosistema de partners.
Sigue esta Quickstart para adquirir una experiencia práctica con estos escenarios. Te ayudará a aprender a aplicar estos casos de uso más sofisticados y a obtener más valor de tus datos de ubicación en Snowflake. ¡Te deseamos que puedas encontrar los puntos que buscas!