In this post, we change perspective and focus on performing some of the more resource-intensive processing in Snowflake instead of Spark, which results in significant performance improvements. As part of this, we walk you through the details of Snowflake’s ability to push query processing down from Spark into Snowflake. We also touch on how this pushdown can help you transition from a traditional ETL process to a more flexible and powerful ELT model.
Query pushdown is supported with v2.1 (and later) of the Snowflake Connector for Spark. As you explore the capabilities of the connector, make sure you are using the latest version, available from Spark Packages or Maven Central (source code in Github).
Overview of Querying in Spark with Snowflake
Before we get into the specifics of query pushdown, let’s review the basic query flow between Spark and Snowflake. The Spark driver sends the SQL query to Snowflake using a Snowflake JDBC connection.
- Snowflake uses a virtual warehouse to process the query and copies the query result into AWS S3.
- The connector retrieves the data from S3 and populates it into DataFrames in Spark.
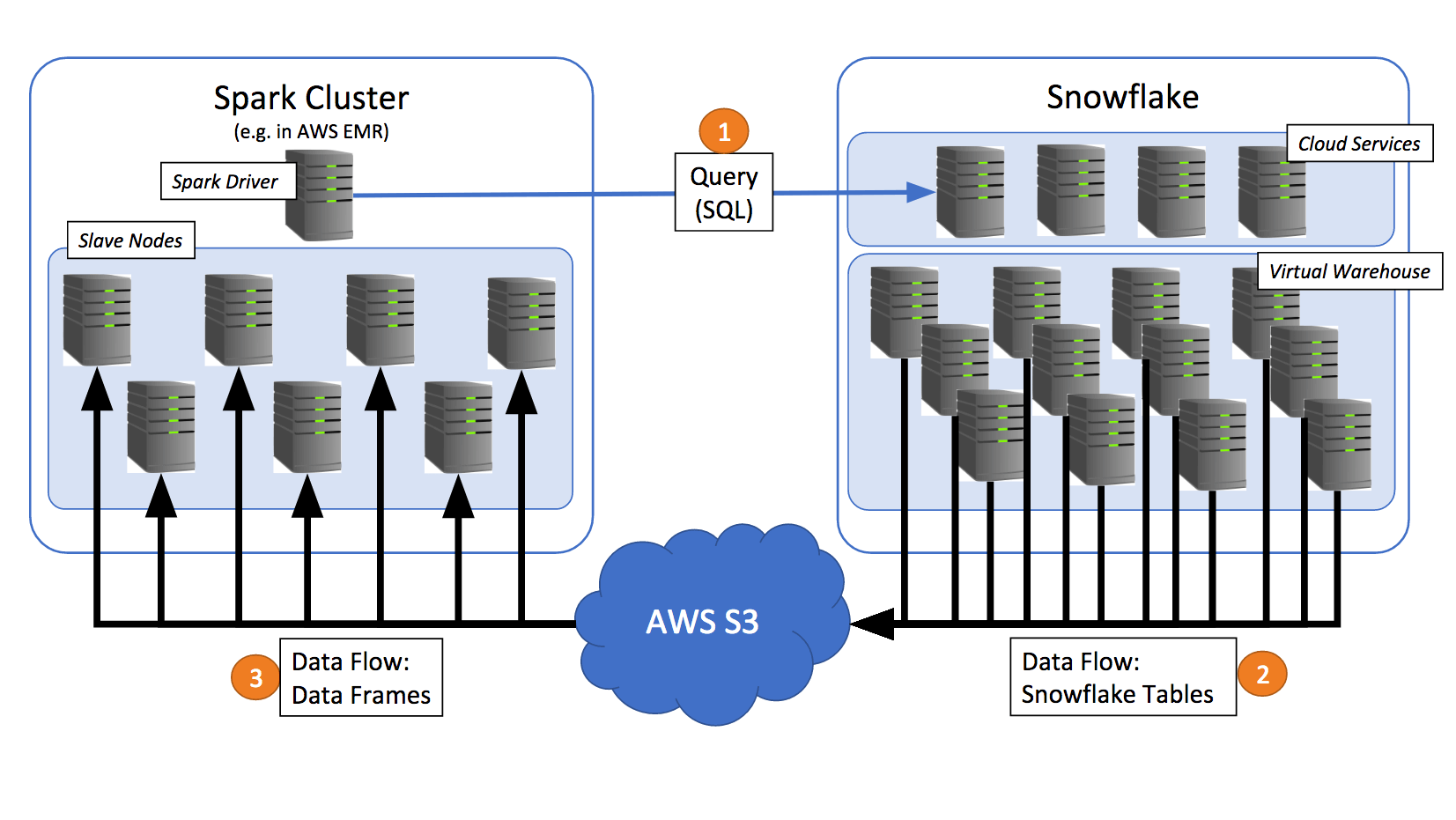
Note how the Snowflake worker nodes (i.e. servers in the virtual warehouse) perform all the heavy processing for the data egress, and the slave nodes in the Spark cluster perform the data ingress. This allows you to size your Snowflake virtual warehouse and Spark clusters to balance compute capacity and IO bandwidth against S3 for optimal performance. Assuming unbounded ingress and egress capacity on S3, this approach gives you virtually unlimited capacity for transferring data back and forth between Spark and Snowflake by simply scaling both clusters to the levels that your workload requires.
Highly Optimized Performance through Query Pushdown
In earlier versions of the Spark connector, Spark’s PrunedFilteredScan interface allowed simple projection and filter operations (e.g. .select(.) and .filter(.) in Scala) to be translated and pushed to Snowflake, instead of being processed in Spark. These Snowflake optimizations were helpful in many situations; however, other operations, such as joins, aggregations, and even scalar SQL functions, could only be performed in Spark. This approach is typically not ideal for more capable Spark data sources, such as Snowflake, which can perform these functions more efficiently.
Starting with v2.1, the connector introduces advanced optimization capabilities for better performance. At the heart of the performance optimizations is the ability to push down queries to Snowflake. With Snowflake as the data source for Spark, v2.1 of the connector can push large and complex Spark logical plans (in their entirety or in parts) to be processed in Snowflake, thus enabling Snowflake to do more of the work and leverage its performance efficiencies. This capability establishes a tight integration between the two systems and combines the powerful query-processing of Snowflake with the computational capabilities of Apache Spark and its ecosystem.
Enabling Query Pushdown
Enable the query pushdown feature for the connector using the following static method call:
SnowflakeConnectorUtils.enablePushdownSession(spark)
Why Pushdown?
Users of both Snowflake and Spark may find that a large amount of the data they would like to use resides in Snowflake. A federated setup exists when two or more interconnected systems can process all or parts of a particular data task flow, leading to the common question of where different parts of the computation should occur. A common concern with federated setups is performance for processing large data sets. For the best performance, you typically want to avoid reading lots of data or transferring large intermediate results between the interconnected systems. Ideally, most of the processing happens close to where the data is stored to leverage any capabilities of the participating stores to dynamically eliminate data that is not needed.
Spark already supports a good set of functionality for relational data processing, as well as connectivity with a variety of data sources, including the columnar Parquet format. Snowflake, however, can achieve much better query performance via efficient pruning of data enabled through our micro-partition metadata tracking and clustering optimizations (see the Snowflake documentation for more details). This metadata allows Snowflake to scan data more efficiently when given query predicates by using aggregate information on micro-partitions, such as min and max values, since data that is determined not to contain relevant values can be skipped entirely. Additionally, metadata such as cardinality of column values (number of distinct values), allows Snowflake to better optimize for operations such as join ordering.
Given that filter, projection, join, and aggregation operations on data all have the potential to significantly reduce the result set of a given query, the data pruning used by Snowflake can and should be leveraged. This also has the benefit of reducing data that has to be transferred to Spark via S3 and the network, which in turn improves response times.
To support pushing more work to Snowflake, the Snowflake connector integrates deeply with the query plan generation process in Spark.
Query Plan Generation
To understand how query pushdown works, let’s take a look at the typical process flow of a Spark DataFrame query. Spark contains its own optimizer, Catalyst, that performs a set of source-agnostic optimizations on the logical plan of a DataFrame (predicate pushdowns, constant folding, etc.). DataFrames are executed lazily. This means Spark can evaluate and optimize relational operators applied to a DataFrame and only execute the DataFrame when an action is invoked. Consider the following expansion on our zip code example:
val dfZipCodes = spark.read.format(...).option(...,...).load()
val dfFilteredZips = dfZipCodes.filter("zip_code < 98000")
val dfCities = dfFilteredZips.select(city)
The same example can also be expressed as:
dfZipCodes.createOrReplaceTempView("temp_zip_codes")
val dfSQLCities = spark.sql("SELECT city from temp_zip_codes WHERE zip_code < 98000")
In either case, Spark delays planning and executing the code until an action such as collect(), show(), or count() occurs.
When an action is required, Spark’s optimizer, Catalyst, first produces an optimized logical plan. The process then moves to the physical planning stage. This is where Spark determines whether to push down a query to Snowflake, as shown in the following diagram:
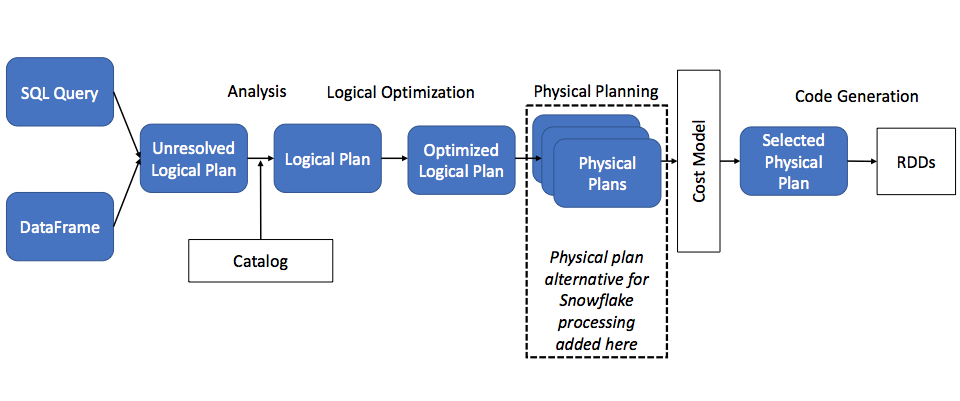
(based on an image originally published in this DataBricks blog post)
Structure of a Snowflake Plan
So, how does the connector allow query pushdown to happen? With query pushdown enabled, Catalyst inserts a Snowflake plan as one possible physical plan for Spark to choose based on cost, as illustrated in the diagram above.
Input: After passing through Catalyst, a DataFrame is represented as a logical plan tree, with nodes representing data sources and operators. For example, consider the following code:
val dfZips = spark.read.format("net.snowflake.spark.snowflake").option("dbtable","zip_codes").load()
val dfMayors = spark.read.format("net.snowflake.spark.snowflake").option("dbtable","city_mayors").load()
val dfResult = dfZips.filter("zip_code > 98000").join(dfMayors.select($"first",$"last",$"city",$"city_id"), dfZip("city_id") === dfMayors("city_id"), "inner")
DataFrame dfResult may be internally represented by Spark in a data structure similar to the following:
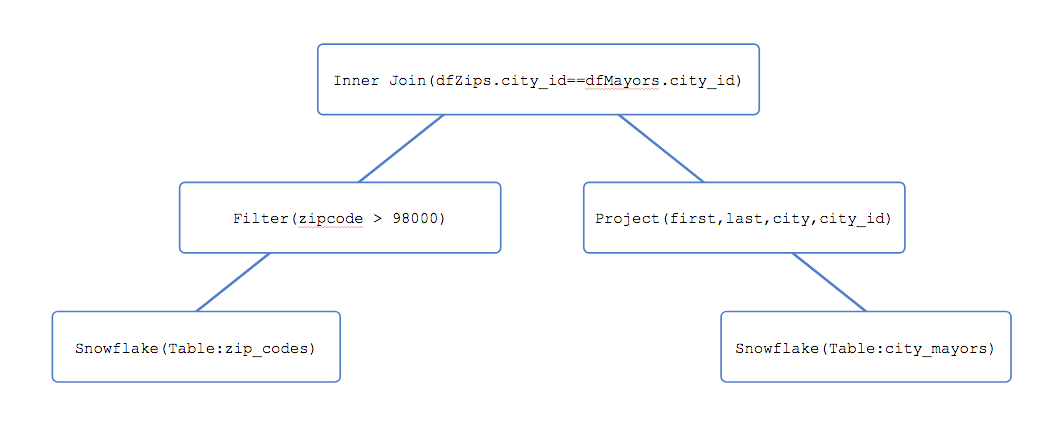
The tree represents a join of two Snowflake tables, after applying a filter on the left-side relation (zip_codes table) and a projection on the right-side relation (city_mayors table) .
Translation: The connector traverses the above data structure and procedurally generates a Snowflake plan to execute it. In previous iterations of our connector, Spark performed the join on zip_codes and city_mayors. With the new feature enabled, however, the connector is able to verify that zip_codes and city_mayors are joinable relations within Snowflake and thus recognize that the join can be performed completely in Snowflake.
This same process can also be applied to SORT, GROUP BY, and LIMIT operations, and more.
Performance Results
Pushing queries down to Snowflake can greatly improve end-to-end performance. To illustrate this, we ran a suite of TPC-DS queries that mirror three different workloads in Cloudera’s Impala benchmarks:
- Workload A (Interactive Queries)
- Workload B (Reporting)
- Workload C (Analytic Queries)
We compared the end-to-end performance between Snowflake and Spark using 10TB scale, with queries executed on a 3X-Large virtual warehouse (for Snowflake) and an equivalent 64-node C3.2XLarge EC2 cluster (for Spark). For each workload, we tested 3 different modes:
- Spark-Snowflake Integration with Full Query Pushdown: Spark using the Snowflake connector with the new pushdown feature enabled.
- Spark on S3 with Parquet Source (Snappy): Spark reading from S3 directly with data files formatted as Parquet and compressed with Snappy.
- Spark on S3 with CSV Source (gzip): Spark reading from S3 directly with data files formatted as CSV and compressed with gzip.
The following 3 charts show the performance comparison (in seconds) for the TPC-DS queries in each workload. Note that the numbers for Spark-Snowflake with Pushdown represent the full round-trip times for Spark to Snowflake and back to Spark (via S3), as described in Figure 1:
- Spark planning + query translation.
- Snowflake query processing + unload to S3.
- Spark read from S3.
The scale for the charts is logarithmic to make reading easier.
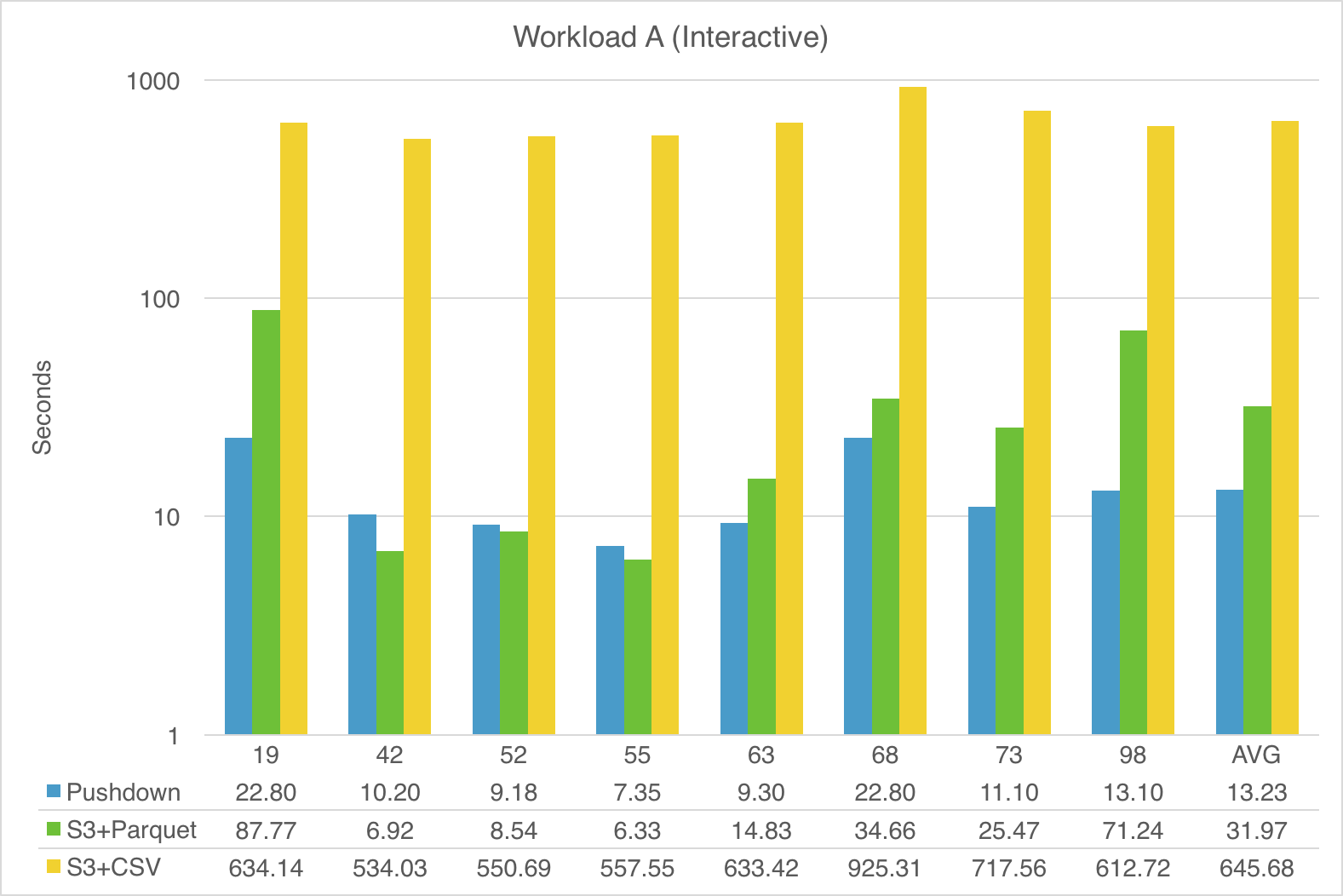
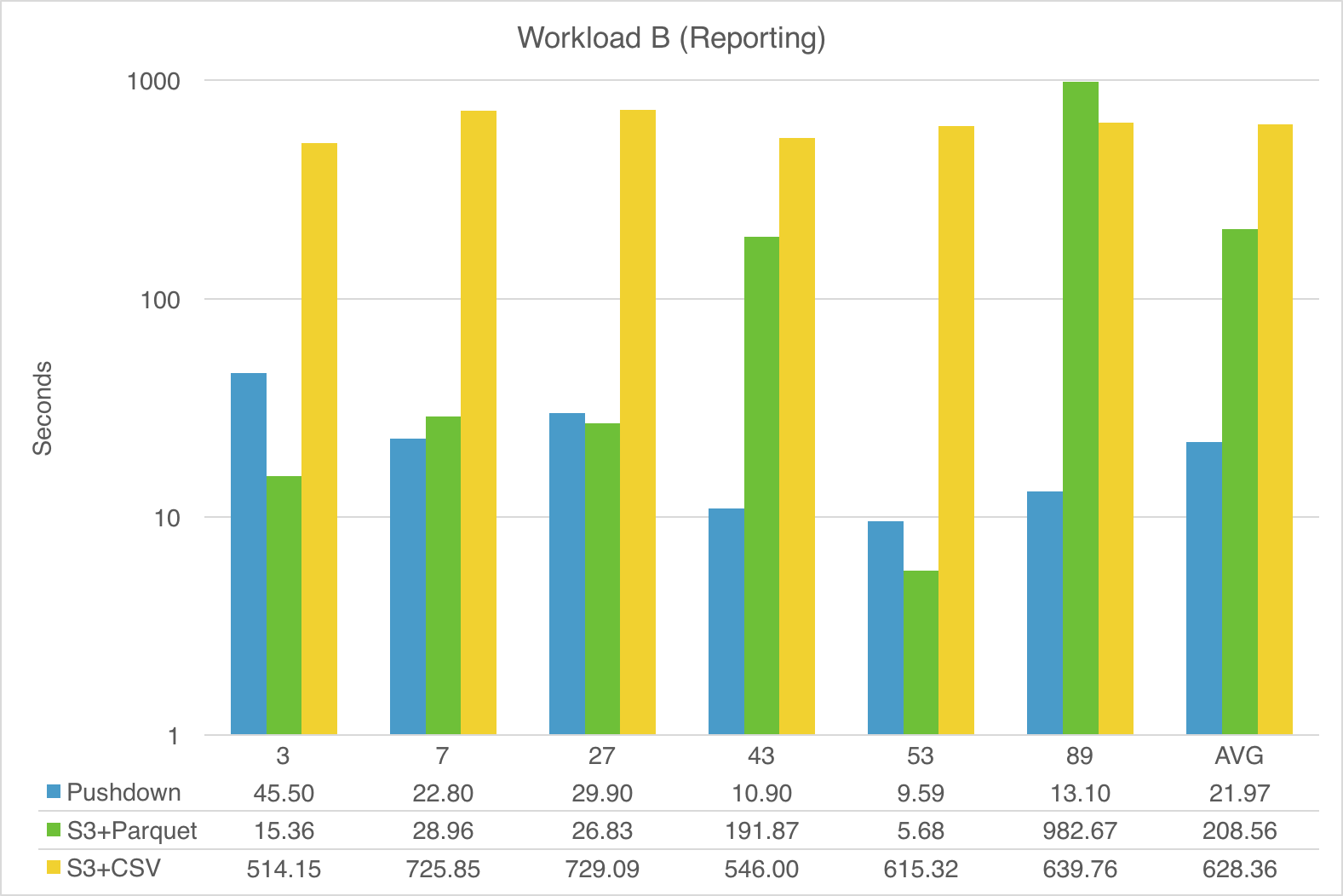
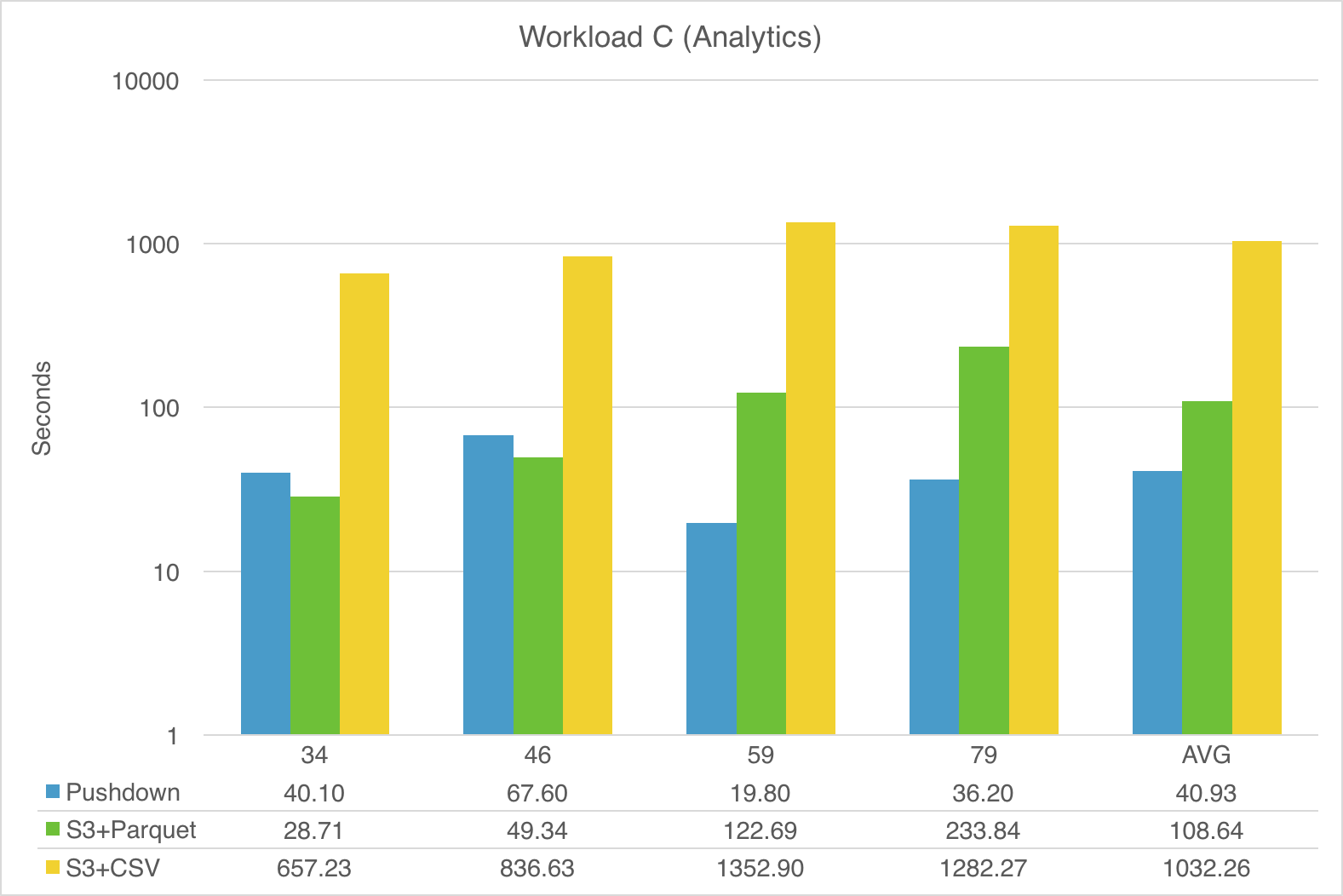
As demonstrated, fully pushing query processing to Snowflake provides the most consistent and overall best performance, with Snowflake on average doing better than even native Spark-with-Parquet.
Note that the columnar format of Parquet is sometimes leveraged by Spark for efficient pruning of unneeded data, but Snowflake answers many of the more complex queries significantly faster than Spark-with-Parquet, e.g. queries 59 and 79 in Workload C (Analytics).
ETL vs ELT
With traditional ETL, most data transformation (filtering, sorting, etc.) typically takes place before loading to limit the data size and ensure optimal querying performance. Snowflake, with its low storage costs and powerful SQL capabilities, combined with the significant performance improvements provided by query pushdown, enables transitioning to a more modern and effective ELT model, in which you load all your data into Snowflake and then perform any data transformations directly in Snowflake. And all of this is accomplished without any changes to your familiar Spark programming experience using Scala, Python, or SparkSQL.
Summary and Next Steps
This post about Spark and Snowflake showed how you can use the Snowflake Connector for Spark to realize significant performance improvements by pushing data processing from Spark into Snowflake. This makes Snowflake the data repository of choice for your ELT scenarios, even if you have existing code in Spark for your data ingress pipeline.
So what’s next? We are continuously looking for ways to improve the experience of working with both Spark and Snowflake. Currently, we are exploring removing the requirement for user-managed S3 buckets for data transfer between Spark and Snowflake, and using Snowflake internal stages instead. Keep an eye on this blog to learn more about our progress on this front.
In the meantime, we encourage you to try Snowflake integrated with Spark in your data processing solutions today:
- If you don’t have a Snowflake account, you can sign up for a free trial here.
- Check out the Snowflake Connector for Spark documentation.
- Tell us about your experience using Snowflake and Spark together. You can reach us through the Snowflake Community or [email protected].
Also, are you interested in helping design and build the next-generation Spark-Snowflake integration? If so, we invite you to take a look at the open Engineering positions on our careers page.
And, as always, you can follow us on Twitter (@snowflakedb) to keep up with all the latest news and happenings here at Snowflake Computing.



