

AI 덕분에 무언가를 구축하는 일은 그 어느 때보다 쉬워졌습니다. 하지만 구축이 쉬워졌다고 해서 오래 지속될 수 있다는 의미는 아닙니다. 취약하고 불안정한 시스템이라면 AI는 상황을 개선하기보다 오히려 더 악화시킬 수 있습니다. 그래서 AI의 가치를 최대한 활용할 수 있도록 설계된 플랫폼이 필요합니다.
Snowflake Summit 2026에서 Snowflake는 오늘날 고객이 데이터 엔지니어링의 최전선에 설 수 있도록 지원하는 여러 새로운 기능을 발표했습니다. AI를 워크플로우에 직접 통합해 데이터 파이프라인 구축 과정을 엔드투엔드로 간소화했습니다. 이러한 기능들은 모든 유형의 데이터 엔지니어를 위해 설계되었으며, 데이터가 어디에 있든 작동합니다. Snowflake는 물론, 개방적이고 상호운용 가능한 레이크하우스 환경, 또는 두 환경을 함께 사용하는 경우에도 적용할 수 있습니다. SQL이나 Python으로 코드를 작성하든 ML 모델을 구축하든, 파이프라인 구축에 필요한 모든 것을 한곳에서 사용할 수 있습니다. Snowflake를 사용하면 규모에 따라 확장되는 탄력적인 컴퓨팅 성능, 데이터가 어디에 있든 원활하게 연결되는 데이터 연결성, 일관된 비즈니스 컨텍스트를 바탕으로 안전하고 신뢰할 수 있는 데이터를 제공하는 엔터프라이즈급 거버넌스 기능을 모두 확보할 수 있습니다.
AI로 앞당기는 프로덕션 전환
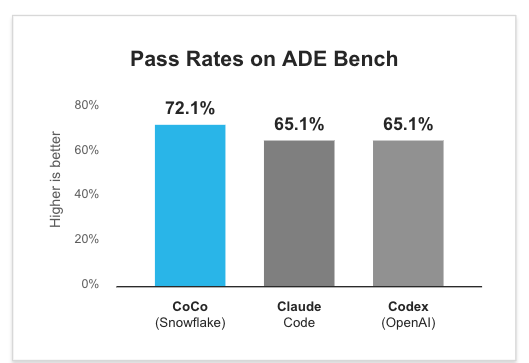
자료 1: 데이터 엔지니어링 작업에서 범용 코딩 에이전트보다 뛰어난 성능을 보이는 Snowflake CoCo1
새로운 에이전틱 워크플로우를 통해 AI는 로컬 환경 내에서 직접 작동하며 엔드투엔드 솔루션을 구축합니다. 실제 데이터 엔지니어링 작업에서 Snowflake CoCo는 선도적인 코딩 에이전트의 기준을 제시합니다. 예를 들어 Opus 4.7에서 실행되는 Claude Code와 비교한 벤치마크에 따르면, CoCo는 작업을 완료하는 데 토큰을 51% 더 적게 사용하고 단계 수를 8% 줄였습니다.2
CoCo는 Snowflake 데이터 엔지니어링 기능에 맞춘 컨텍스트 인식 지원과 목적 특화 스킬을 제공합니다. 조직의 보안 경계 안에서 작동할 뿐 아니라, 엔터프라이즈 데이터 컨텍스트까지 이해한다는 점이 핵심입니다. Claude Opus 4.8, Claude Sonnet 4.6, GPT 5.5 같은 최신 모델에 액세스할 수 있으므로 데이터 엔지니어는 Snowsight, CoCo CLI 또는 새 데스크톱 앱(퍼블릭 프리뷰)에서 CoCo를 사용할 수 있습니다. 사전 구축된 스킬이나 사용자 지정 스킬을 활용해 Spark 파이프라인 마이그레이션, Python 코드 배포, dbt 워크플로우 자동화, 성능 최적화 등 다양한 작업을 단 하나의 프롬프트로 수행할 수 있습니다.
신뢰할 수 있는 자율 파이프라인
모든 조직은 계속 늘어나는 소스에서 AI에 바로 활용할 수 있는 데이터를 낮은 지연 시간으로 지속적으로 제공받기를 원합니다. 수작업으로 만든 오케스트레이션 스크립트, 취약한 증분 처리 로직, 수동 배포에 의존하던 기존 방식은 확장하기 어렵습니다. 선언형 워크플로우에서는 원하는 결과만 정의하면, Snowflake가 실행 방식을 처리합니다.
DoorDash의 일부인 Wolt는 각 워크로드를 적합한 엔진에서 실행할 수 있는 유연성을 확보하기 위해 Apache Iceberg를 표준으로 채택했습니다. 저희는 Snowflake Dynamic Iceberg 테이블을 사용해 데이터 레이크의 데이터를 보강, 준비하고 자동으로 새로 고칩니다. 단일 쿼리와 목표 최신성을 정의하면 Snowflake가 증분 업데이트와 오케스트레이션을 관리합니다. Apache Iceberg 기반 Dynamic Table을 통해 파이프라인을 더 빠르게 출시하고, 유지 관리 시간을 줄였으며, 증분 파이프라인의 오버헤드도 낮출 수 있었습니다.
Raimund Kämmerer
더 빠르고 유연해진 Dynamic Table
Dynamic Table은 정의된 쿼리와 목표 데이터 최신성에 따라 데이터 새로 고침을 자동화해 수작업 시간을 크게 줄입니다. Dynamic Table은 증분 파이프라인에 선도적인 성능과 낮은 지연 시간을 제공합니다. Summit에서 Wind Creek Hospitality의 선임 데이터 엔지니어인 Sergey Labetsik은 팀이 자격 요건을 충족한 고객에게 1분 이내에 식사 바우처를 제공한 사례를 소개했습니다. dbt 배치 작업을 Dynamic Table 파이프라인으로 마이그레이션함으로써, 기존에 30분 주기로 실행되던 작업의 엔드투엔드 지연 시간을 1분 미만으로 단축했습니다.

Snowflake는 네이티브 선언형 워크플로우의 성능, 상호운용성, 표현력을 높이기 위한 일련의 업데이트를 발표했습니다. 주요 내용은 다음과 같습니다.
- 더 빨라진 Dynamic Table의 새로 고침 성능(GA): 집계 함수, qualify/rank(SCD-1), cluster-by 작업, 조인 등 여러 영역에서 워크로드를 최대 2.8배 가속합니다. 모두 Gen2 웨어하우스에서 측정한 결과입니다.
- 사용자 지정 증분 처리(퍼블릭 프리뷰): MERGE 또는 INSERT 문으로 자체 새로 고침 로직을 작성해 복잡한 변환의 성능을 최적화하면서, 자동 스케줄링, 종속성 추적, 복제 등 Dynamic Table의 모든 이점을 그대로 활용할 수 있습니다.
- 적응형 새로 고침(퍼블릭 프리뷰): 각 주기마다 가장 효율적인 새로 고침 방법을 자동으로 결정하며 별도의 튜닝이 필요하지 않습니다. Snowflake는 비용을 최적화하고, 복잡한 쿼리에서 실패를 방지하며, 수동 튜닝을 제거하기 위해 증분 처리와 재초기화 중 하나를 체계적으로 선택합니다.
- dbt의 Dynamic Table 구체화(어댑터 버전 1.11.5): dbt에서 구체화 유형만 변경하면 증분 처리를 최적화할 수 있습니다. 파이프라인의 다른 dbt 모델과 조합해 사용할 수 있습니다.
- DCM Projects(퍼블릭 프리뷰): Snowflake에서 다양한 변환 파이프라인의 버전 관리, 테스트, 배포를 지원하는 방식을 통해 인프라를 선언적으로 관리할 수 있습니다.
dbt를 Snowflake에 네이티브로 통합
dbt Projects on Snowflake를 사용하면 익숙한 Snowflake 기능으로 dbt Core 프로젝트를 생성, 편집, 테스트, 실행, 관리할 수 있습니다. dbt Project 오브젝트를 배포하면 기본 제공 옵저버빌리티와 CI/CD 통합을 활용할 수 있으며, 직접 관리해야 하는 인프라 오버헤드도 줄일 수 있습니다.
dbt Projects의 초기 도입 고객으로서, 저희는 팀이 실제로 구축하고 운영하는 방식이 로드맵에 반영될 수 있도록 Snowflake와 긴밀히 협력했습니다. 이를 통해 소규모 팀도 더 빠르게 움직일 수 있었습니다. 동시에 그룹 전반에서 분석과 AI 활용을 뒷받침할 수 있는, 모듈화되고 거버넌스가 적용된 확장 가능한 기반도 마련했습니다.
António Costa
Summit에서 발표된 업데이트를 통해 더 많은 고객이 dbt Projects를 표준으로 채택하고 있습니다. 이제 고객은 dbt Core 관리 방식을 대체하는 동시에 dbt Fusion과 더 많은 옵저버빌리티 기능을 사용할 수 있습니다.
- dbt Fusion(GA)은 이제 dbt Projects on Snowflake에서 지원되는 버전 중 하나로 포함됩니다. dbt Labs와의 파트너십을 통해 제공되는 Fusion은 모든 dbt Project에서 사용할 수 있으며, 복잡한 빌드의 컴파일 시간을 개선하도록 설계되었습니다.
- 컬럼 수준 계보를 지원하는 향상된 dbt DAG(GA)는 Snowflake Horizon Catalog를 사용해 Workspaces, 오브젝트 세부 정보, Query History 전반의 스키마 수준 정보를 방향성 비순환 그래프(DAG)에 직접 관리합니다. 이제 dbt Project 오브젝트를 실행할 때마다 통합된 데이터 파이프라인 계보 뷰를 확인할 수 있습니다.
규모에 맞게 확장되는 프로그래밍 방식 파이프라인
Pfizer는 Snowpark를 활용해 데이터 처리 속도를 4배 높이고 총소유비용(TCO)을 57% 절감했습니다.
모든 데이터 변환 작업이 선언형 모델에 적합한 것은 아닙니다. Python, Java, Scala, Apache Spark™를 사용해 프로그래밍 방식으로 개발하는 데이터 엔지니어와 데이터 사이언티스트는 복잡한 파일 구문 분석, 배치 규모의 ML 추론, 다단계 Python 워크플로우와 같은 변환 작업을 수행해야 합니다. 이러한 경우, 코드 작성보다 프로덕션 배포에 더 많은 시간이 걸립니다. 하지만 Snowpark와 Snowpark Connect for Apache Spark™는 프로토타입과 프로덕션 사이의 간극을 좁히도록 설계되었습니다.
Notebooks와 ML Jobs 구축 및 오케스트레이션
노트북에서 프로덕션 파이프라인으로 전환하는 과정은 항상 필요 이상으로 어려웠습니다. 새로운 Pipeline Builder(프라이빗 프리뷰)는 이러한 과정을 바꿉니다. 팀은 오케스트레이션 코드를 처음부터 작성하지 않고도 Notebooks와 ML Jobs를 시각적으로 연결해 완전한 엔드투엔드 파이프라인을 구성할 수 있습니다. 스케줄링, 인프라, 오브젝트 생성이 자동으로 처리되므로 데이터 사이언티스트와 엔지니어는 설정에 들이는 시간을 줄이고 실제 작업에 더 집중할 수 있습니다. 그 결과 반복 속도는 빨라지고 핸드오프는 줄어들며, Snowflake에서 쉽게 모니터링하고 재현할 수 있는 ML 파이프라인을 구축할 수 있습니다.
Snowpark로 대규모 파이프라인 구축
Snowpark는 Python, Java, Scala 개발 경험을 Snowflake에 네이티브로 통합합니다. 데이터 엔지니어와 데이터 사이언티스트는 Notebooks에서 코드를 작성하고 반복 개발하며, 익숙한 DataFrame API로 변환 로직을 구축할 수 있습니다. 이후 로직을 저장 프로시저와 사용자 정의 함수(UDF)로 패키징해 배포하고, Tasks로 전체 작업을 스케줄링할 수 있습니다. 코드의 첫 줄부터 프로덕션 파이프라인까지, Snowpark는 데이터가 있는 곳에서 코드가 직접 실행되는 완전한 엔드투엔드 워크플로우를 제공합니다. 거버넌스 기능은 기본으로 포함되며, 관리해야 할 외부 인프라는 필요하지 않습니다.
Snowpark는 개발자 생산성, 외부 연결성, ML 및 비정형 워크로드를 위한 업데이트라는 세 가지 핵심 영역으로 확장되었습니다. 향상된 기능은 다음과 같습니다.
- 데이터 통합 API: 외부 데이터베이스에서 프로그래밍 방식으로 데이터를 가져옵니다. DB-API(GA)는 Oracle, SQL Server, Postgres, MySQL용 Python 드라이버를 지원하며, JDBC-API(퍼블릭 프리뷰)는 모든 JDBC 소스에 서버 측 병렬 읽기를 추가합니다.
- 비정형 데이터 처리(GA):
session.read.file()을ai.extract(),ai.parse_document(),ai.transcribe()와 같은 AI 함수와 함께 사용해 웨어하우스 규모에서 파일(이미지, PDF, 오디오)을 읽고, 파싱하고, 보강할 수 있습니다. - Artifact Repository(퍼블릭 프리뷰 예정): UDF, 저장 프로시저, Notebooks를 위해 고객이 호스팅하는 리포지토리(Nexus, JFrog)에서 Python 패키지를 가져올 수 있습니다. Private Link도 지원합니다.
- 확장 가능한 ML 배치 추론(프라이빗 프리뷰):
@udf_init_once로 모델을 한 번만 로드하고 워커 간에 공유하여 표준 웨어하우스에서 메모리 사용량을 낮추고 성능을 높입니다. - Python 및 Java 배포용 Code Bundle(퍼블릭 프리뷰 예정): DCM Projects와 매끄럽게 연계해 Snowpark 및 Snowpark Connect 코드를 종속 인프라와 함께 패키징하고, 안정적인 자동 배포를 지원합니다. 이를 통해 데이터 엔지니어링 팀은 소프트웨어 팀이 오랫동안 유지해 온 수준의 배포 안정성을 확보할 수 있습니다.
Snowflake를 사용하면 팀은 로컬 Python 또는 Apache Spark 코드를 프로덕션 지원 워크플로우로 전환해 평균 5.1배 더 빠른 성능과 42% 낮은 비용을 달성할 수 있습니다. [3]
Snowpark Connect로 Apache Spark 파이프라인 현대화
데이터 플랫폼을 업그레이드한다고 해서 모든 것을 처음부터 다시 구축해야 하는 것은 아닙니다. Snowpark Connect는 실용적인 전환 경로를 제공합니다. 기존 Spark 기반 파이프라인을 전체적으로 재작성하지 않고도 Snowflake의 최신 관리형 인프라로 가져올 수 있습니다. 엔지니어는 노후화되고 비용 부담이 큰 Spark 클러스터에서 벗어나 오늘날의 데이터 규모에 맞게 설계된 플랫폼으로 전환할 수 있습니다. 이 플랫폼은 네이티브 거버넌스, 탄력적 컴퓨팅, Snowflake 전체 생태계에 대한 원활한 액세스를 제공합니다. 이는 팀의 기존 환경을 유지하면서 과거의 운영 오버헤드를 제거하는 현대화 방식입니다.
지난해 Snowpark Connect 출시 이후, Snowflake는 다음을 비롯한 여러 업데이트를 위해 노력해 왔습니다.
- Scala 2.12/2.13 및 Java 11/17용 Spark Scala 및 Java 클라이언트: 코드 변경 없는 프로덕션 배포를 위한
snowpark-submitCLI 포함 - Bronze 계층 파일 처리: permissive 모드, 복합 데이터 유형, 스키마 진화, 대용량 압축 파일 병렬 읽기 지원
- 통합 옵저버빌리티: Jupyter, Airflow 또는 외부 소스에서 제공되는 전체 세부 정보(상태, 지속 시간, 리소스, 쿼리, 로그)를 바탕으로 Spark 작업을 검색, 진단하고 사용자에게 경고할 수 있도록 지원
파이프라인에 시맨틱 컨텍스트 통합
지난 10년 동안 비즈니스 정의는 파이프라인 외부에 존재했습니다. 지표는 BI 도구에서, 피처는 ML 저장소에서 따로 정의되었고, 팀마다 기준과 정의가 달라 일관된 데이터 해석이 어려웠습니다. 시맨틱 뷰를 통해 이러한 방식은 변화하고 있습니다. 이제 데이터 엔지니어는 파이프라인 안에 의미를 직접 추가할 수 있습니다. Snowflake는 이러한 변화를 Snowflake Semantic View dbt Package를 통해 dbt 워크플로우로 확장하고 있습니다. 팀은 표준 DDL 구문을 사용해 dbt 모델 파일에서 시맨틱 계층을 직접 정의할 수 있으며, CoCo는 이 정의 작성을 지원합니다. dbt build를 실행하면 Snowflake에서 시맨틱 뷰가 구체화되거나 업데이트되어, 파이프라인의 나머지 구성 요소와 동기화됩니다. Horizon Context는 여기서 한 단계 더 나아가, 데이터에 접근하는 모든 AI 에이전트, BI 도구, 애플리케이션에서 이러한 정의를 자동으로 사용할 수 있도록 합니다.
데이터 엔지니어링의 새로운 시대
시스템 차원의 문제는 인력을 늘리는 것만으로는 해결할 수 없다는 사실을 우리는 오래전부터 알고 있었습니다. AI를 활용하는 경우에도 마찬가지입니다. 데이터 엔지니어가 취약한 레거시 플랫폼 위에서 AI를 활용해 솔루션을 출시하면, 기술 부채는 해소되지 않고 오히려 더 빠르게 누적됩니다. 그 결과 파이프라인은 쉽게 중단되고, 인프라는 유지 관리가 어려워지며, 데이터 제품은 비즈니스 속도를 따라가지 못하게 됩니다. 새로운 AI 시대에는 생성 속도가 기반의 품질을 앞질러 버릴 위험이 있습니다.
Snowflake는 데이터 엔지니어링에 특화된 에이전틱 코딩 경험과, AI 워크로드가 요구하는 거버넌스 기반 플랫폼을 함께 제공합니다. 개방형 레이크하우스 아키텍처 도입, Spark 워크로드 마이그레이션, 대규모 ML 추론 파이프라인 구축, 새로운 데이터 플랫폼 구축까지 Snowflake가 지원합니다. Snowflake는 모든 데이터 엔지니어링 역할에 필요한 도구를 제공해 팀이 더 빠르게 개발하고, 더 안정적으로 배포하며, 인프라 관리에 드는 시간을 줄일 수 있도록 돕습니다. 데이터 엔지니어링의 에이전틱 시대가 도래했습니다.
무료 eBook “Build Pipelines for AI: An Essential Guide to Smarter Data Engineering”을 다운로드하고, Snowflake Summit 2026의 주요 릴리스와 발표 내용을 자세히 확인하세요.


