Snowpark Offers Expanded Capabilities Including Fully Managed Containers, Native ML APIs, New Python Versions, External Access, Enhanced DevOps and More


Since its launch two years ago, Snowpark has been empowering data scientists, data engineers, and application developers to streamline their architectures, accelerate development, and boost the performance of data engineering and ML/AI workloads on Snowflake. At this year’s Summit, we are excited to announce a series of advancements to Snowpark runtimes and libraries, making the deployment and processing of non-SQL code in Snowflake even simpler, faster, and more secure.
Snowpark — Set of libraries and runtimes for secure deployment and processing of non-SQL code on the Snowflake Data Cloud.
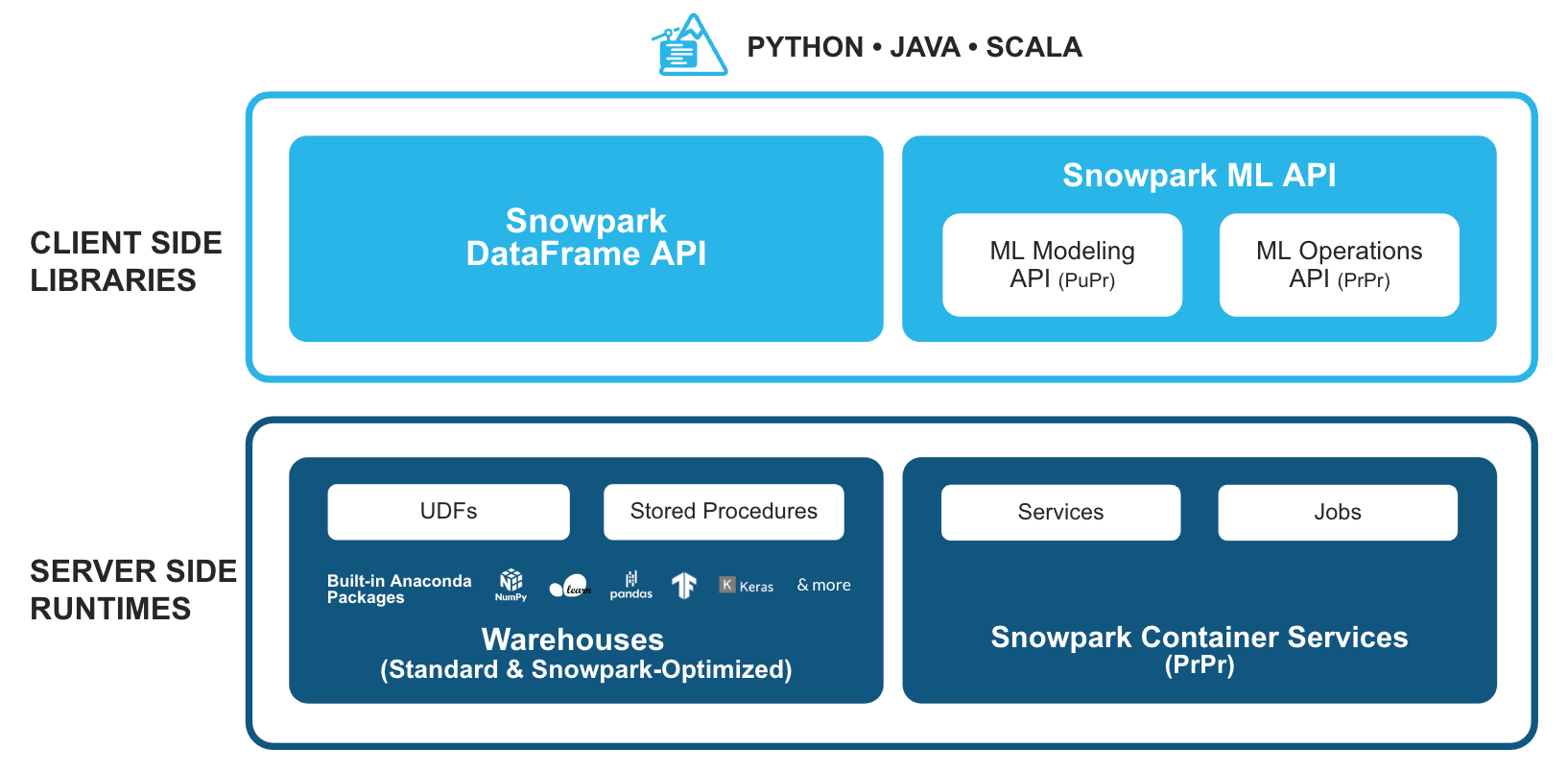
Familiar Client Side Libraries - Snowpark brings deeply integrated, DataFrame-style programming and OSS compatible APIs to the languages data practitioners like to use. It provides familiar APIs for various data centric tasks, including data preparation, cleansing, preprocessing, model training, and deployments tasks. Additionally, we’re excited to announce support for a set of new ML APIs for more efficient model development (public preview) and deployment (private preview).
Flexible Runtime Constructs - Snowpark provides flexible compute and runtime constructs that allow users to bring in and run custom logic on warehouses or Snowpark Container Services (private preview). In the warehouse model, users can seamlessly run and operationalize data pipelines, ML models, and data applications with user-defined functions (UDFs) and stored procedures (sprocs). For workloads that require use of specialized hardware like GPUs, custom runtimes/libraries or hosting of long running full-stack applications, Snowpark Container Services offers the ideal solution.
Together, these capabilities offer powerful extensibility hooks tailored to the requirements and preferences of data engineers, data scientists, and developers. This empowers organizations to break free from the burdensome task of spinning up and managing complex standalone systems operating outside of Snowflake's governance boundary. By bringing compute closer to the data businesses can eliminate data silos, address security and governance challenges, and optimize operations, leading to enhanced efficiency, all while avoiding the management overhead associated with additional systems and infrastructure.
In this blog we’ll dive into the latest announcements on Snowpark client libraries and server side enhancements on warehouses. For additional details on Snowpark Container Services, refer to our launch blog available here.
What’s New: Snowpark for Python
Python's popularity continues to soar, making it the language of choice for data scientists and the third most popular language overall among developers. We’re on a mission to make Snowflake the best-in-class platform for Python practitioners and have launched a comprehensive set of enhancements and expanded set of capabilities for Snowpark for Python.
General platform updates
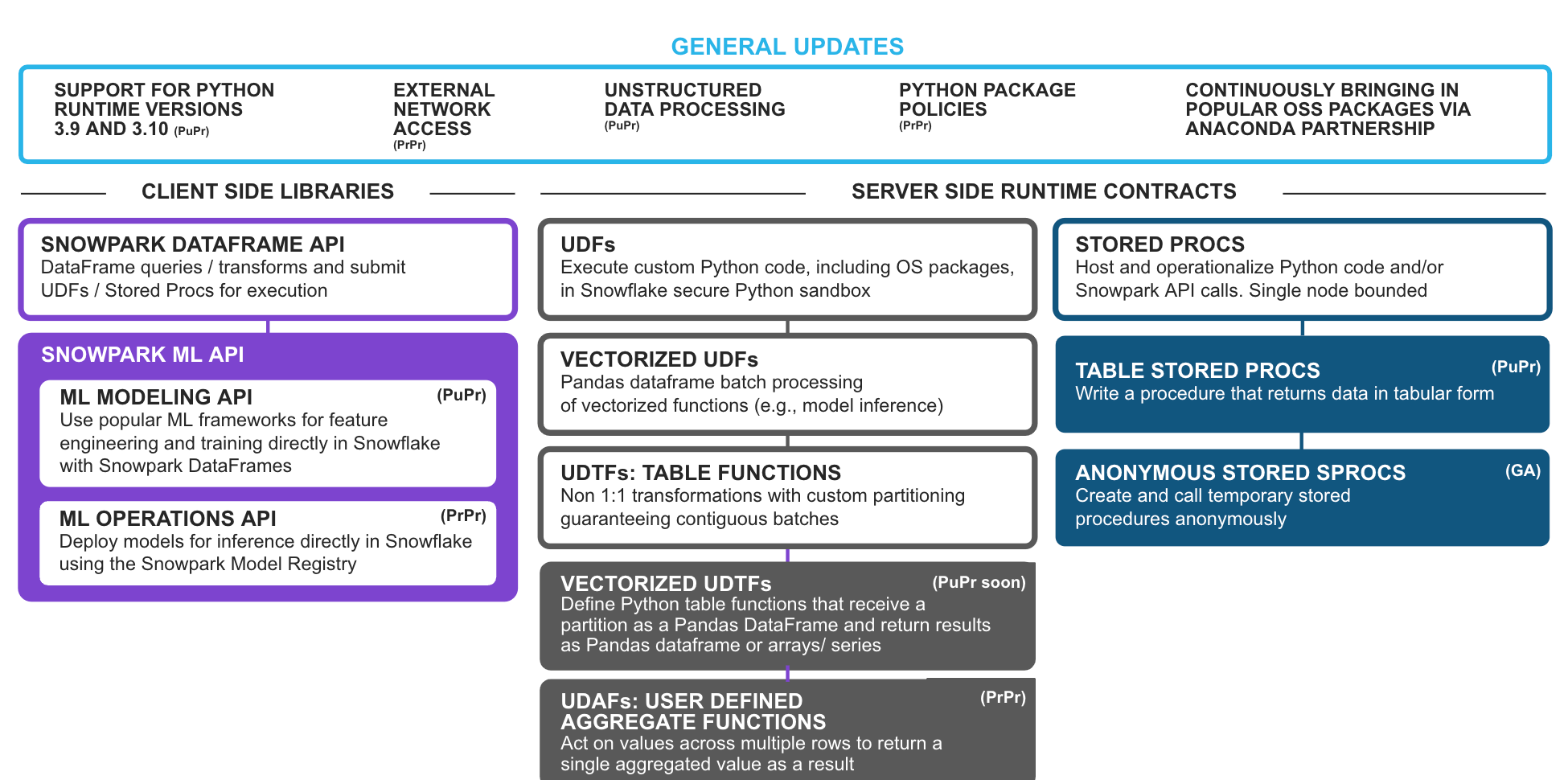
Multiple Python Version 3.9 & 3.10 Support (PuPr) - Users will have the option to upgrade to newer versions to take advantage of Python enhancements and compatible third party packages in Snowpark.
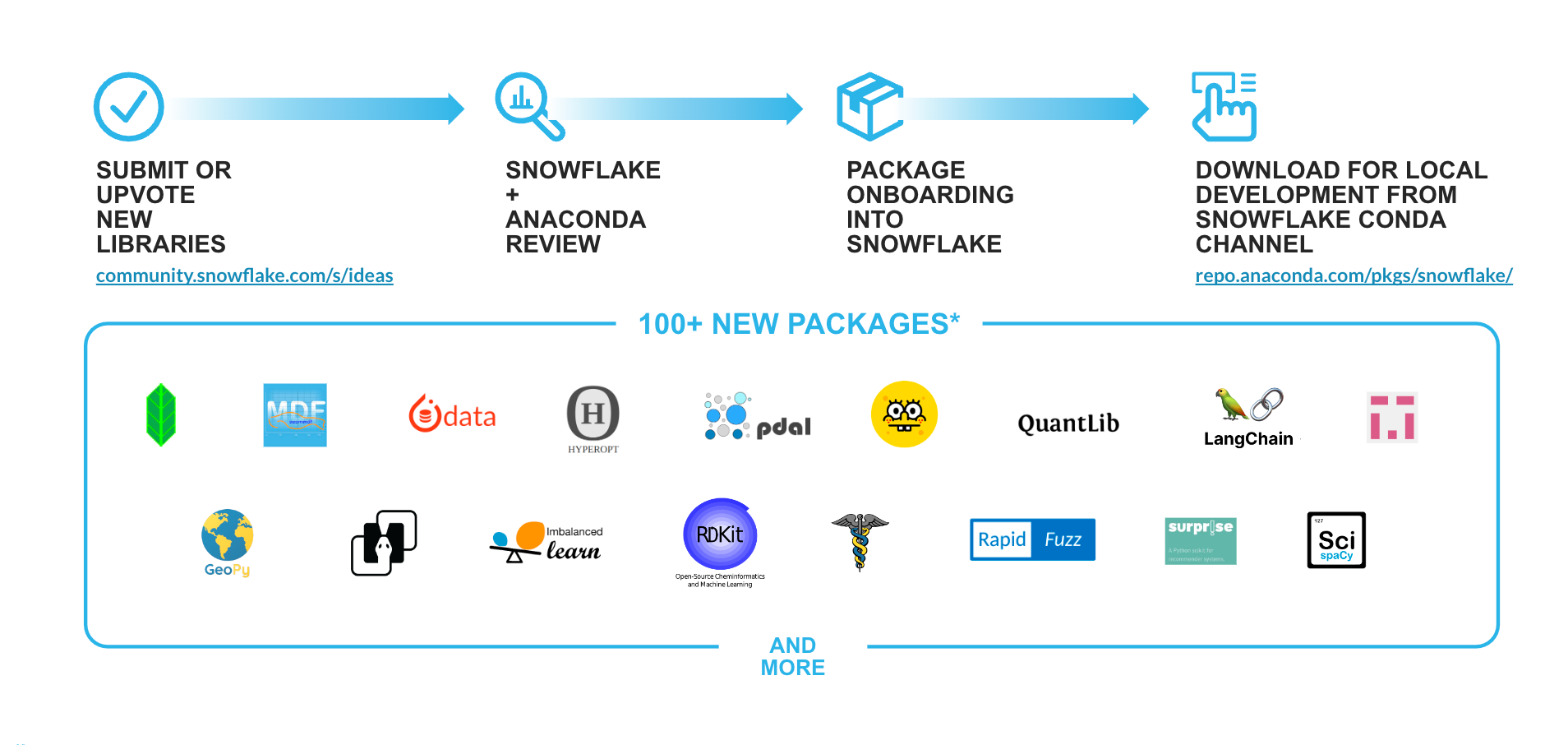
Support for new Python (Anaconda) libraries inside Snowflake - Since the power of Python lies in its rich ecosystem of open source packages, as part of the Snowpark for Python offering we bring seamless, enterprise-grade open source innovation to the Data Cloud via our Anaconda integration. Based on feedback from customers and the Snowflake ideas board we continue to add packages to the existing repository of more than 5,000+ packages available in the Snowflake channel. A few recent additions and libraries that will be landing soon include: langchain, implicit, imbalanced-learn, rapidfuzz, rdkit, mlforecast, statsforecast, scikit-optimize, scikit-surprise and more.
Python Unstructured Data Processing (PuPr) - Unstructured data processing is now natively supported with Python. Users can leverage Python UDFs, UDTFs and Stored Procedures to securely and dynamically read, process and drive insights from unstructured files (like images, video, audio, or custom formats) from internal/external stages or on-premises storage.
External Network Access (PrPr) - Allows users to seamlessly connect to external endpoints from their Snowpark code (UDFs/UDTFs and Stored procedures) while maintaining high security and governance.
Python Package Policies (PrPr) - Allows users with appropriate privileges to set allowlist and blocklists for enhanced governance of Anaconda packages utilized in their account. This capability enables customers with stricter auditing and/or security requirements to have finer command and governance over use of OSS python packages in their Snowflake environments.
Client libraries updates
Introducing Snowpark ML APIs - We’re excited to announce support for Snowpark ML APIs, composed of the ML Modeling API (PuPr) and ML Operations API (PrPr), that will enable easier end-to-end ML development in Snowflake.
Snowpark ML Modeling API (PuPr) - Scales out feature engineering and simplifies model training in Snowflake.
- Preprocessing: Perform common pre-processing and feature engineering tasks directly on data in Snowflake using already familiar sklearn-style APIs and benefit from improved performance and Snowflake’s parallelization for scaling to large datasets with distributed, multi-node execution.
- Modeling: Train models for popular scikit-learn and xgboost models directly on data in Snowflake. Provides familiar APIs to execute training in a turn-key fashion without the need for manual creation of Stored Procedures or UDFs.
Snowpark ML Operations API (PrPr) - Includes the Snowpark Model Registry (PrPr) to effortlessly deploy registered models for inference using scalable and reliable Snowflake infrastructure.
Warehouse runtime contract updates
User Defined Aggregate Functions (UDAFs) (PrPr) - Allows users to author functions that can act on values across multiple rows and return a single aggregated value as a result, enabling seamless, user-friendly custom aggregation scenarios in Snowpark.
Vectorized UDTFs (PuPr coming soon) - Allows users to author table functions that operate on partitions as pandas DataFrames and returns results as pandas Dataframe or lists of pandas Series/arrays. Vectorized UDTFs enable seamless partition-by-partition processing vs the row-by-row processing of scalar UDTFs. Given that it's faster to concat dataframes than collecting data row-by-row in the process-function, this will improve the performance of several use cases, such as distributed training of multiple, independent models (e.g. Hyper Parameter Tuning), distributed time series analysis / forecasting, model inference with multiple outputs etc.
Anonymous Stored Procedures (GA) - Create and call an anonymous procedure that is like a stored procedure but is not stored for later use. This is great for building Snowpark apps/integration that requires execution of Snowpark codes that does not have to be persisted. As an example, dbt Python models and Snowflake Python worksheets leverage anonymous sprocs behind the scenes.
Python Table Stored Procedures (PuPr) - Stored procedures previously only returned scalar values. Now, they can return results in tables, which will allow users to conveniently return a table for downstream processing as part of their Snowpark code.
What’s new: Devops in Snowflake
In addition to the above Snowpark enhancements, at Summit we announced a series of Snowflake DevOps related improvements that make working with, managing, testing, and operationalizing Snowpark code easier. Some of the notable updates include:
Logging and tracing with Event Tables (PuPr) - Users can instrument logs and traces from their UDFs, UDTFs, Stored Procedures, and Snowpark containers, and they are seamlessly routed to a secure, customer-owned Event Table. Logging and trace event telemetry in Event Tables can be queries and analyzed by users to troubleshoot their applications or gain insights on performance and behavior of their code. In conjunction with other Telemetry features like Snowflake Alerts and Email Notifications, customers can be notified of new events and errors in their applications.
Python Tasks API (PrPr Soon) - Provides first class Python APIs for creating and managing Snowflake Tasks/DAGs.
Snowpark Local Testing (PrPr) - Allows users to create a Snowpark session and DataFrames without a live connection to Snowflake. Users can accelerate their Snowpark test suites and save credits using a local Session and seamlessly switch to a live connection with zero code changes.
Native Git Integration (PrPr Soon) - Snowflake now supports native integration with git repos! This integration allows users to securely connect to a git repo from a Snowflake account and access contents from any branch / tag / commit within Snowflake. After integrating users can create UDFs, stored procedures, Streamlit Apps, and other objects by simply referencing the repo and branch like they would a file on a stage.
Snowflake CLI (PrPr) - Open-source command line interface that enables developers to effortlessly create, manage, update, and view apps, along with build automation and CI/CD capabilities across app-centric workloads.
Triggered Tasks (PrPr) - This new task type allows users to more efficiently consume data on a Snowflake Stream. Previously, tasks could be executed as quickly as 1-minute. With Triggered Tasks, data can be consumed from a stream as it arrives, significantly reducing latency, optimizing resource utilization, and lowering costs.
These new Snowpark and DevOps updates streamline coding for all Python developers, allowing them to work in their familiar way, while enjoying the governance and performance benefits of Snowflake. These improvements will further enable data engineers to seamlessly migrate from Spark for ELT/ETL, data scientists to build and deploy ML models natively, and data developers to build applications using Snowpark.
Snowpark under the hood
Check out these great in-depth blogs and videos from the Snowpark Engineering team on how Snowpark was built, how it works, and how it makes it easy and secure to process Python/Java/Scala code in Snowflake.
Customer success stories
In the months since its GA announcement at Snowday in November 2022, Snowpark for Python has continued to see strong growth with 3x customer adoption. Thousands of customers are accelerating development and performance of their workloads with Snowpark for Python for data engineering and ML use cases.

OpenStore is an eCommerce company that switched from PySpark to Snowpark for large data transformations and saw an 87% decrease in end-to-end runtime, 25% increase in throughput, and 80% decrease in engineering maintenance hours.

Intercontinental Exchange, the parent company of NYSE, uses Snowpark to streamline data pipelines and save costs for mission critical applications used for regulatory reporting.

EDF Energy is a leading energy supplier in the UK that uses Snowpark to build an intelligent customer engine. “Being able to run data science tasks, such as feature engineering, directly where the data sits is massive. It’s made our work a lot more efficient and a lot more enjoyable” said Rebecca Vickery, Data Science Lead at EDF.

At Bridg, Snowpark provides a way to access data directly, train models, and execute actions all on a Snowflake cluster—making the process fully contained, automated, and efficient. “Together, Snowflake and Snowpark have allowed us to develop and automate proprietary machine learning models at a much faster pace,” said Dylan Sager, Lead Data Scientist at Bridg.
Snowpark Accelerated program
We’re also excited by the continued tremendous interest we’ve seen in our partner ecosystem, including new partnerships such as KX. As part of the Snowpark Accelerated program we have numerous partners build integrations that leverage Snowpark for Python to enhance the experiences they provide to their customers on top of Snowflake.

Work faster and smarter with Snowpark
Snowpark is all about making it easy for users to do super-impactful things with data, while retaining the simplicity, scalability, and security of Snowflake’s platform. With Snowpark for Python, we cannot wait to see what you will build.
To help you get started, check out these resources: