RECURSO
Fácil ingestão de dados com o Snowflake
Movimente dados com facilidade e ajuste a escala com confiança para todas as suas necessidades de ingestão, em uma única plataforma.

Reduza a movimentação de dados
Obtenha interoperabilidade máxima com qualquer conector.
Prepare sua organização para a IA
Melhore a performance de pipelines de ETL, permitindo agentes de IA a tomar decisões em velocidade de máquina, sem deixar nenhum dado para trás.
Forneça escalabilidade para toda a empresa
Crie uma integração de nível empresarial, pronta para acompanhar o crescimento, com governança, observabilidade de dados e implementação flexível.
Casos de uso de ingestão de dados com o Snowflake
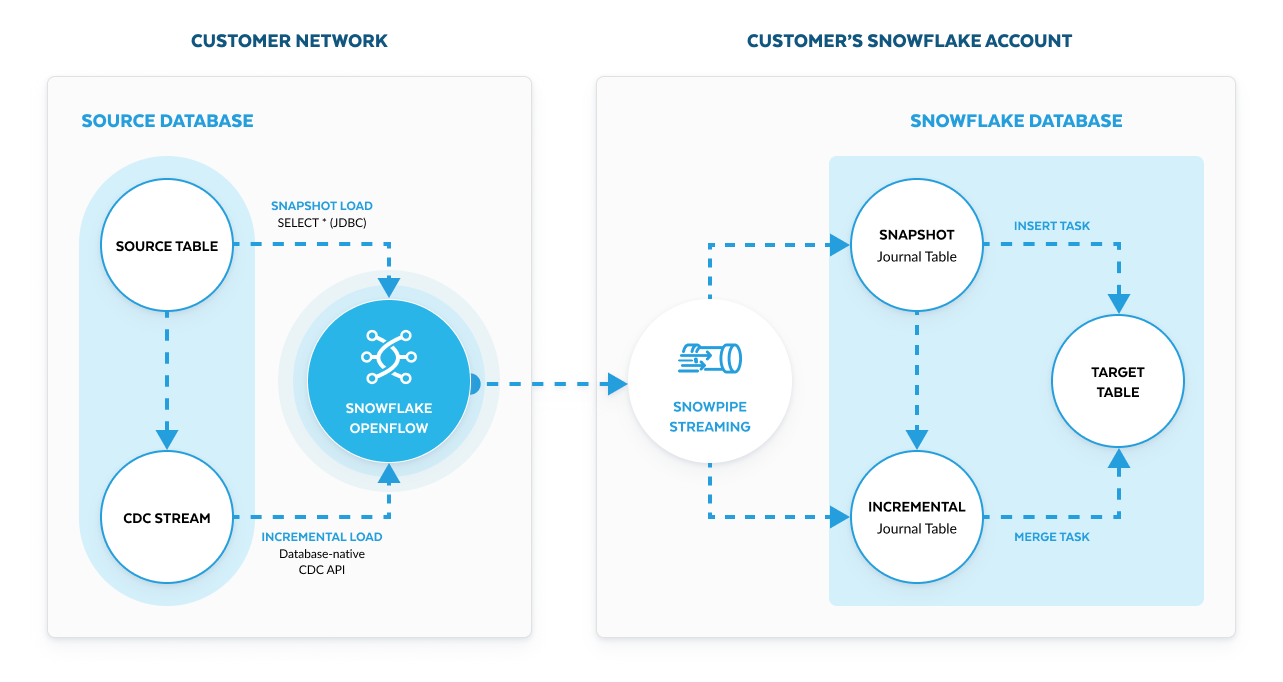
Captura de dados alterados com apenas alguns cliques
O processo de captura de dados alterados (change data capture, CDC) pode ser um desafio por causa da dificuldade de monitorar e sincronizar, com precisão, as alterações dos dados em sistemas diversos e distribuídos, praticamente em tempo real.
Com o Snowflake Openflow, o processo de CDC é muito mais fácil, com conectores prontos para uso que se conectam às principais fontes de dados e realizam a captura automática de qualquer exclusão, atualização e inserção de alterações.
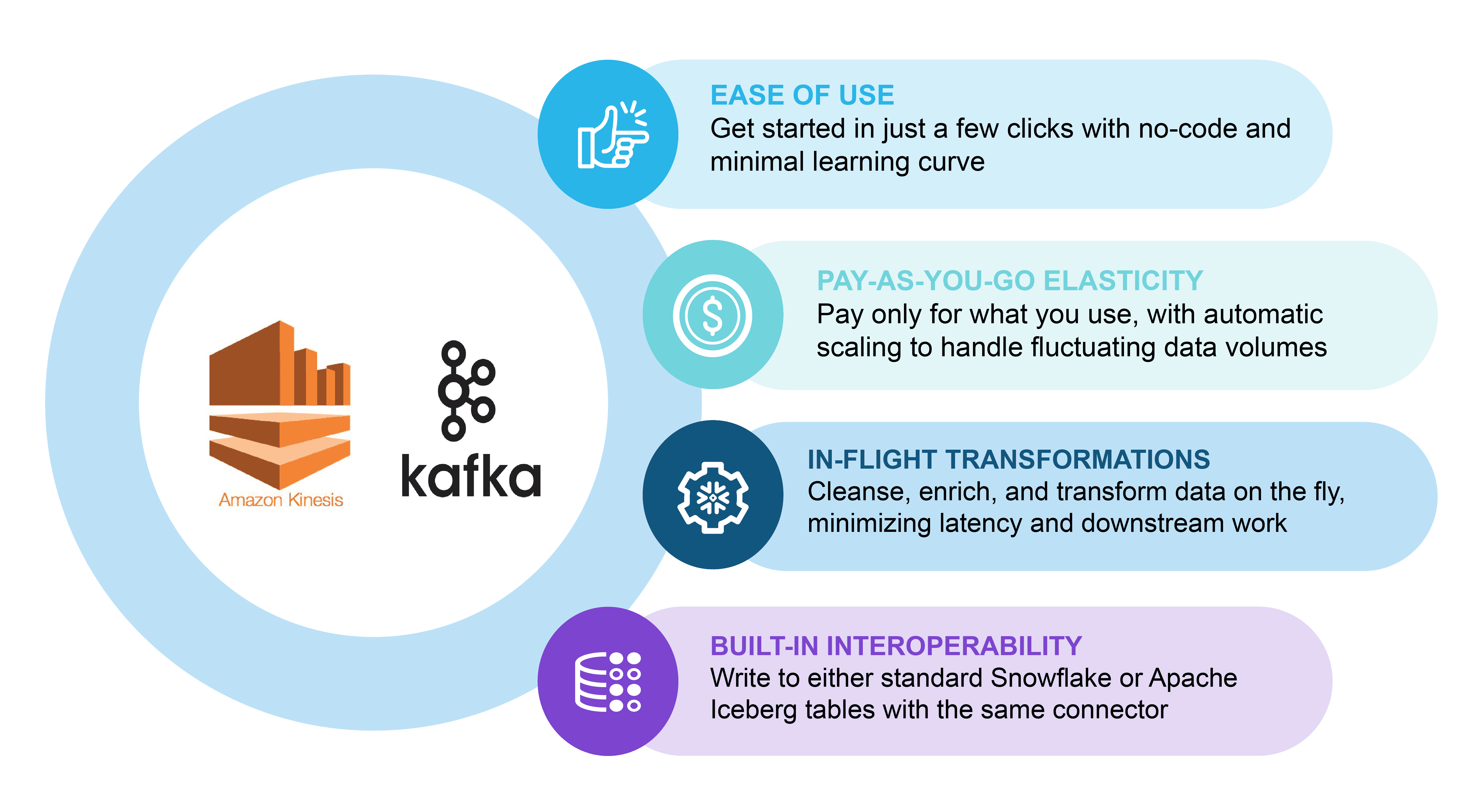
Obtenha alta taxa de transferência e baixa latência de dados de streaming
O Openflow conecta-se diretamente a fontes de streaming, incluindo Apache Kafka† e Amazon Kinesis†. Ele também pode enviar dados a partir do Snowflake para Kafka.* Assim, os dados de streaming podem passar para o Snowflake e voltar para os sistemas de streaming.
Graças à nova arquitetura de alta performance do Snowpipe Streaming e à integração com o Openflow†, agora, a ingestão de streaming atinge uma taxa de transferência de 10 GB por segundo com latência de cinco segundos para consulta e transformação em linha.
Turbine o ETL para IA
O Openflow conecta todos os dados corporativos à IA com fluxos de dados bidirecionais quase em tempo real, onde quer que um modelo ou agente esteja. Oferecendo suporte a diversas estruturas e requisitos de dados e mantendo permissões de usuário consistentes à medida que os dados migram da fonte para o destino, o Openflow segue as regras da lista de controle de acesso (access control list, ACL) do sistema de origem, mantendo permissões de usuário consistentes com a fonte.
Ele também possui recursos integrados do Snowflake Cortex AI para analisar e pré-processar arquivos não estruturados antes de gravá-los no Snowflake, tudo em uma única plataforma.


Implemente arquiteturas híbridas em todo o data estate
Não abra mão da facilidade de uso ou do controle. O Openflow oferece flexibilidade para implementar pipelines por meio da infraestrutura gerenciada do Snowflake, ou a opção de “bring your own cloud” (BYOC), dando aos clientes controle total sobre onde os pipelines são executados e reduzindo a carga operacional, pois são dois métodos de serviços totalmente gerenciados.
Transmita dados com eficiência em 5 segundos
O Snowflake traz opções, como COPY, Snowpipe e Snowpipe Streaming, para que você mesmo possa criar pipelines de ingestão. Use COPY para ingestão em lote. Snowpipe para ingerir arquivos de modo automático. Ou, use o Snowpipe Streaming para trazer dados de conjunto de linhas com latência de um único dígito.
Tanto o Snowpipe quanto o Snowpipe Streaming funcionam sem servidor para melhor escalabilidade e eficiência de custos. Com o novo modelo de preços e otimização do Snowpipe, os clientes notam mais de 50% de economia de custos.


Conecte o Snowflake a todos os seus sistemas de registro de forma nativa
Unifique as informações de bancos de dados transacionais, planejamento de recursos corporativos, gestão de relacionamento com o cliente da sua empresa, e outros principais sistemas, direto no Snowflake. Isso ajuda a eliminar silos e melhora as análises, deixando os dados prontos para IA em toda a empresa.
A arquitetura aberta e extensível do Openflow oferece suporte à implementação híbrida e a centenas de conectores prontos para uso. Dessa forma, você pode integrar novas fontes de dados, com rapidez, mantendo a flexibilidade de seu data stack mais amplo.